过拟合,预防过拟合。
博客摘自:
http://blog.csdn.net/heyongluoyao8/article/details/49429629
http://lbingkuai.iteye.com/blog/1666181
使用数据挖掘或者机器学习建立模型的目的:使用已经产生的(假设的独立同分布的)数据去训练,然后使用训练好的模型去拟合未来的数据分布。然而现实生活中的数据独立同分布的假设往往不成立。并且在数据量少的情况下,不足以对整个数据集的分布进行估计。因此,在实际应用中,通常会加入一些手段,防止训练模型过拟合,提高模型的泛化能力。
过拟合: 为了得到一致假设而使假设变得过度复杂称为过拟合。
图像表示:
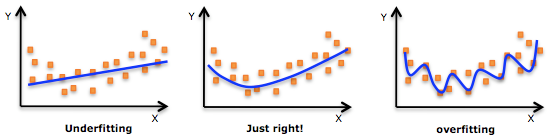
原因:一个过拟合的模型试图连误差(噪音)都去解释(而实际上噪音又是不需要解释的),导致泛化能力比较差,显然就过犹不及了。
另是一种解释:
在对模型进行训练时,有可能遇到训练数据不够,即训练数据无法对整个数据的分布进行估计的时候,或者在对模型进行过度训练(overtraining)时,常 常会导致模型的过拟合(overfitting)。如下图所示:

通过上图可以看出,随着模型训练的进行,(polynomial: 多项式) 模型的复杂度会增加,此时模型在训练数据集上的训练误差会逐渐减小,但是在模型的复杂度达到一定程度时,模型在验证集上的误差反而随着模型的复杂度增加而增大。此时便发生了过拟合,即模型的复杂度升高,但是该模型在除训练集之外的数据集上却不work。
手段:
-
Early stopping (适当的stopping criterion)
对模型进行训练的过程即是对模型的参数进行学习更新的过程,这个参数学习的过程往往会用到一些迭代方法,如梯度下降(Gradient descent)学习算法。Early stopping便是一种迭代次数截断的方法来防止过拟合的方法,即在模型对训练数据集迭代收敛之前停止迭代来防止过拟合。
Early
stopping方法的具体做法是,在每一个Epoch结束时(一个Epoch集为对所有的训练数据的一轮遍历)计算validation
data的accuracy,当accuracy不再提高时,就停止训练。这种做法很符合直观感受,因为accurary都不再提高了,在继续训练也是无益的,只会提高训练的时间。那么该做法的一个重点便是怎样才认为validation
accurary不再提高了呢?并不是说validation
accuracy一降下来便认为不再提高了,因为可能经过这个Epoch后,accuracy降低了,但是随后的Epoch又让accuracy又上去了,所以不能根据一两次的连续降低就判断不再提高。
一般的做法是,在训练的过程中,记录到目前为止最好的validation accuracy,当连续10次Epoch(或者更多次)没达到最佳accuracy时,则可以认为accuracy不再提高了。此时便可以停止迭代了(Early Stopping)。这种策略也称为“No-improvement-in-n”,n即Epoch的次数,可以根据实际情况取,如10、20、30……
-
数据集扩增
在数据挖掘领域流行着这样的一句话,“有时候往往拥有更多的数据胜过一个好的模型”。因为我们在使用训练数据训练模型,通过这个模型对将来的数据进行拟合,而在这之间又一个假设便是,训练数据与将来的数据是独立同分布的。即是使用当前的训练数据来对将来的数据进行估计与模拟,而更多的数据往往估计与模拟地更准确。
因此,更多的数据有时候更优秀。但是往往条件有限,如人力物力财力的不足,而不能收集到更多的数据,如在进行分类的任务中,需要对数据进行打标,并且很多情况下都是人工得进行打标,因此一旦需要打标的数据量过多,就会导致效率低下以及可能出错的情况。所以,往往在这时候,需要采取一些计算的方式与策略在已有的数据集上进行手脚,以得到更多的数据。
通俗得讲,数据机扩增即需要得到更多的符合要求的数据,即和已有的数据是独立同分布的,或者近似独立同分布的。一般有以下方法:
- 从数据源头采集更多数据
- 复制原有数据并加上随机噪声
- 重采样
- 根据当前数据集估计数据分布参数,使用该分布产生更多数据等
-
正则化方法
正则化方法是指在进行目标函数或代价函数优化时,在目标函数或代价函数后面加上一个正则项,一般有L1正则与L2正则等。
具体的可以参考:
http://blog.csdn.net/heyongluoyao8/article/details/49429629
-
Dropout
正则是通过在代价函数后面加上正则项来防止模型过拟合的。而在神经网络中,有一种方法是通过修改神经网络本身结构来实现的,其名为Dropout。该方法是在对网络进行训练时用一种技巧(trick),对于如下所示的三层人工神经网络:

对于上图所示的网络,在训练开始时,随机得删除一些(可以设定为一半,也可以为1/3,1/4等)隐藏层神经元,即认为这些神经元不存在,同时保持输入层与输出层神经元的个数不变,这样便得到如下的ANN:

然后按照BP学习算法对ANN中的参数进行学习更新(虚线连接的单元不更新,因为认为这些神经元被临时删除了)。这样一次迭代更新便完成了。下一次迭代中,同样随机删除一些神经元,与上次不一样,做随机选择。这样一直进行瑕疵,直至训练结束。

- 激活引入非线性,池化预防过拟合
- 过拟合产生的原因和预防
- 激活引入非线性,池化预防过拟合(深度学习入门系列之十二)
- 激活引入非线性_池化预防过拟合(深度学习入门系列之十二)
- 为什么会产生过拟合,有哪些方法可以预防或克服过拟合
- 为什么会产生过拟合,有哪些方法可以预防或克服过拟合
- 预防过拟合
- 正规化--预防过拟合
- 预防口腔疾病最经济的方法
- [转]预防SQL注入漏洞函数
- Vbs脚本病毒生产机的原理介绍及如何预防和解除?
- 论广播风暴的成因、预防及排障
- 预防流感小手册
- 预防SQL注入漏洞函数
- 瑞星发布诺顿安全事故的预防和解决方法
- Windows操作系统常遇***预防技巧
- 黑客通过IP欺骗进行攻击的原理及预防
- Bug分析:为bug预防奠定基础
- 饮食误区:多喝茶可以预防心脑血管疾病?
- bp网络算法对y=0.4sin(2*PI*x)+0.5的拟合