训练集和测试集的产生方法
2017-08-03 20:26
225 查看
最近,重新再学习一下机器学习的理论内容,学习书籍为周志华《机器学习》,为了帮助自己记忆和理解,把一些东西归纳总结。
当存在一个包含m个样例的数据集
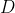
,既要需要,又要测试,怎样才能做到呢? 答案是:同过对
进行适当的处理,从中产生出训练集
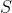
和测试集
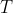
。下边是几种常用的方法。
按照一定的比例(通常训练集

)划分为两个互斥的集合,其中一个集合作为训练集
,另一个作为测试集
。
单次使用留出法得到的估计结果往往不够稳定可靠,在使用留出法时,一般要采用若干次随机划分、重复进行实验评估后取平均值作为留出法的评估结果。
划分为
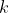
个大小相似的互斥自己,即

,


,然后用
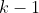
个子集的并集作为训练集,余下的那个子集作为测试集;这样就可以得到
组训练集/测试集,从而进行了
次训练和测试,最终返回的是这
个测试结果的均值。这种方法也叫做“
折交叉验证”(k-fold
cross validation)。
与留出法相似,将数据集
划分为
个数据子集同样存在多种划分方式。为减小因样本引入的不同而引入的差别,
折交叉验证通常要随机使用不同的划分重复
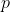
次,最终的结果就是这
次
折交叉验证结果的均值。例如,常见的有“10次10折交叉验证”。
采样产生数据集

:每次随机从
挑选一个样本,将其拷贝放入
,然后再将该样本放回初始数据集
中,使得该样本在下次采样时仍有可能被采到;这个过程重复执行
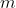
次后,就得到了包含
个样本的数据集
,将
作为训练集,
\
作为测试集。
该方法在数据集较小、难以有效划分训练/测试集时很有用;此外,自助法能从初始数据集中产生多个不同的训练集,这对集成学习等方法很有好处。
缺点:自助法产生的数据集改变了初始数据集的分布,这会引入估计偏差。
1 需要测试集的原因
通常,我们可通过实验测试来对学习器的泛化能力进行评估并进而做出选择。为此,需使用一个“测试集”(testing set)来测试学习器对新样本的判别能力,然后以测试集上的“测试误差”(testing error)作为泛化误差的近似。当存在一个包含m个样例的数据集
,既要需要,又要测试,怎样才能做到呢? 答案是:同过对
进行适当的处理,从中产生出训练集
和测试集
。下边是几种常用的方法。
2 留出法(hold-out)
直接将数据集按照一定的比例(通常训练集
)划分为两个互斥的集合,其中一个集合作为训练集
,另一个作为测试集
。
单次使用留出法得到的估计结果往往不够稳定可靠,在使用留出法时,一般要采用若干次随机划分、重复进行实验评估后取平均值作为留出法的评估结果。
3 交叉验证(cross validation)
该方法先将数据集划分为
个大小相似的互斥自己,即
,
,然后用
个子集的并集作为训练集,余下的那个子集作为测试集;这样就可以得到
组训练集/测试集,从而进行了
次训练和测试,最终返回的是这
个测试结果的均值。这种方法也叫做“
折交叉验证”(k-fold
cross validation)。
与留出法相似,将数据集
划分为
个数据子集同样存在多种划分方式。为减小因样本引入的不同而引入的差别,
折交叉验证通常要随机使用不同的划分重复
次,最终的结果就是这
次
折交叉验证结果的均值。例如,常见的有“10次10折交叉验证”。
4 自助法(bootstrapping)
该方法直接以自助采用(bootstrapping sampling)为基础。我们对数据集采样产生数据集
:每次随机从
挑选一个样本,将其拷贝放入
,然后再将该样本放回初始数据集
中,使得该样本在下次采样时仍有可能被采到;这个过程重复执行
次后,就得到了包含
个样本的数据集
,将
作为训练集,
\
作为测试集。
该方法在数据集较小、难以有效划分训练/测试集时很有用;此外,自助法能从初始数据集中产生多个不同的训练集,这对集成学习等方法很有好处。
缺点:自助法产生的数据集改变了初始数据集的分布,这会引入估计偏差。

相关文章推荐
- [机器学习]划分训练集和测试集的方法
- Linux环境下段错误的产生原因及调试方法小结
- Linux环境下段错误的产生原因及调试方法小结
- ConcurrentModificationExeception :并发修改异常产生原因及解决方法
- springAOP——代理对象的产生及方法调用
- Linux下的段错误产生的原因及调试方法
- php产生随机数的两种方法实例代码 输出随机IP
- C++编译器会为类产生哪些默认的成员方法?---聊聊C++的Big Three
- Linux环境下段错误的产生原因及调试方法小结
- JAVA/SERVLET 以UTF-8导出CSV文件时产生乱码的解决方法
- objective-c 中三种产生随机数的方法
- 恢复桌面上的IE的方法(不是产生一个捷径)
- PHP产生不重复随机数的5个方法总结
- 机器学习中的训练集,验证集及测试集的关系
- 使用匿名方法产生的一个难发现问题
- Linux下的段错误产生的原因及调试方法(Zz)
- Linux系统内存错误产生的原因及调试方法(段错误|core dumped) 谢谢这篇文章的作者
- 网页自动刷新,不产生嗒嗒声的一个解决方法
- Linux系统内存错误产生的原因及调试方法(段错误|core dumped)
- linux 内核空间和用户空间 产生随机数的方法