单向链表的基本操作
2017-08-02 16:53
155 查看
一、链表与数组:
首先,我们来看看为啥我们有了数组,还需要链表呢?那么我们来看看链表与数组的区别。二者都属于一种数据结构:
从逻辑结构来看:
1、 数组必须事先定义固定的长度(元素个数),不能适应数据动态地增减的情况。当数据增加时,可能超出原先定义的元素个数;当数据减少时,造成内存浪费;数组可以根据下标直接存取。
2、 链表动态地进行存储分配,可以适应数据动态地增减的情况,且可以方便地插入、删除数据项。(数组中插入、删除数据项时,需要移动其它数据项,非常繁琐)链表必须根据next指针找到下一个元素
从内存存储来看:
(静态)数组从栈中分配空间, 对于程序员方便快速,但是自由度小
链表从堆中分配空间, 自由度大但是申请管理比较麻烦
从上面的比较可以看出,如果需要快速访问数据,很少或不插入和删除元素,就应该用数组;相反, 如果需要经常插入和删除元素就需要用链表数据结构了。
二、单向链表的相关操作:
1、定义链表结构体:
这里没有使用头结点。struct Node
{
int num; //这里用来方便查找链表位置,可以省略
datatype data; //数据
struct Node *pNext; //指向下一个结点
};
typedef struct Node node; //定义一个node类型2、插入数据(后面):
void backadd(node **ppnode,int num, datatype data)
{
node *pNewnode = (node *)malloc (sizeof(node));
//creat a new node
pNewnode->num =num; //给新结点赋值
pNewnode->data=data;
if(*ppnode == NULL) //如果首元结点为空
{
*ppnode = pNewnode; //将新加入的结点作为首元结点
pNewnode->pNext = NULL;
}
else //the first node isn't empty
{
node *p = *ppnode; //head
while(p->pNext != NULL)
{
p=p->pNext;
}
p->pNext = pNewnode; //Insert
}
}这里用到了二级指针,用于保存头结点指针的地址。如果不用二级指针则需要一个node *的返回值,才能改变结点的地址。
调用:
node *pNode = NULL; //定义头结点 backadd(&pNode,1,11); //出入的是地址
2、结点查找:
因为我们在结构体中每个结点我们能设置了一个num,现在我们就可以通过匹配这个num来查找某个结点。node *search(node *pNode,int num)
{
node *p=pNode;
for(;p!=NULL; p=p->pNext) //遍历整个链表,知道为空
{
if(num == p->num) //通过设定数字查找
{
return p;
break;
}
}
return NULL;
}3、替换结点内容:
这里与查找有些类似,需要先查找到对于结点,然后再对其内容进行替换。int change(node *pNode,int oldnum,int newnum,datatype newdata)
{
while(pNode->pNext != NULL) //终止条件
{
if(pNode != NULL)
{
if(oldnum == pNode->num)
{
pNode->num=newnum; //赋值
pNode->data=newdata;
return 1;
}
pNode = pNode->pNext; //遍历整个链表,一直到最后pNode->pNext = NULL
}
}
printf("can't find the node,modify failed!");
return 0;
}4、删除结点
让上一个结点直接跳过要删除的结点,指向要删除结点的下一个结点。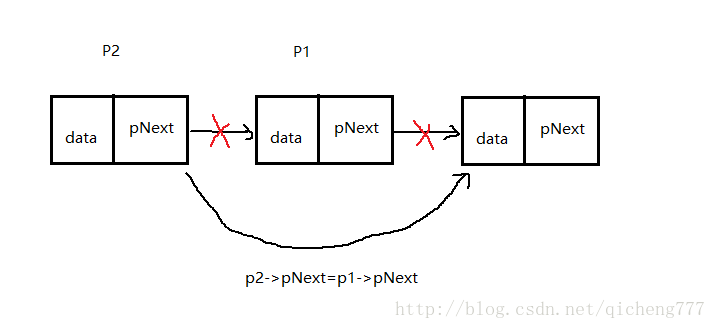
node *delete(node *pNode,int num)
{
node *p1 = NULL;
node *p2 = NULL;
p1=pNode; //Save the infomation of the linklist
while(p1 != NULL)
{
if(p1->num == num) //查找结点
{
break;
}
else
{
//p2指向前一个结点
p2=p1; //Save the previous node
p1=p1->pNext;
}
}
if(p1 == pNode) //要删除的点是第一个结点
{
pNode=p1->pNext; //把第一个结点地址变为下一个结点地址
free(p1);
}
else
{
p2->pNext=p1->pNext; //ignore p1(delete it)
free(p1);
}
return pNode;
}这里也可以用for循环来实现,传入一个n值来控制要删除具体那个结点。用for循环控制p要移动的次数。接下来,我们在数据的插入中将会用到。
5、数据插入(中间,前面)
和删除类似,需要找到前后两个结点并用p1,p2来保存。再进行相关操作。是删除结点的反操作。在中间插入图解:
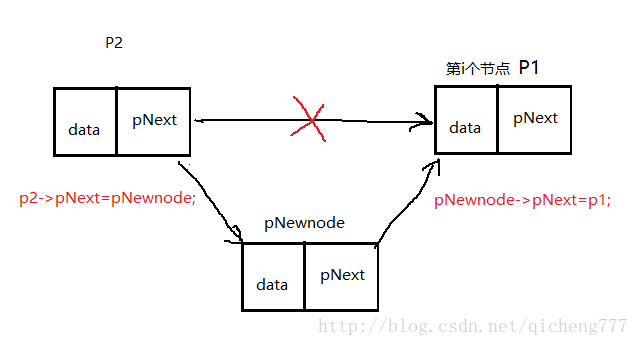
void insert(node **pNode,int n,int newnum,datatype newdata)
{
node *p1,*p2;
p1=p2=NULL;
p1=*pNode;
int i=0;
while(p1 != NULL)
{
for(i=1;i<n;i++) //用for循环找出要在第几个结点前面插入
{
p2=p1;
p1=p1->pNext;
}
break;
}
node *pNewnode=(node *)malloc(sizeof(node));
pNewnode->num=newnum;
pNewnode->data=newdata;
printf("%p",pNewnode);
if(pNode == p1) //insert it on the head
{
pNewnode->pNext = *pNode;
*pNode=pNewnode;
}
else //中间
{
pNewnode->pNext=p1;
p2->pNext=pNewnode;
}
}6、链表逆序:
逆序:数据颠倒,但是地址不变。也就是说要把链表的指向颠倒过来。需要三个变量,p1,p2用来遍历整个链表,p3类似于一个临时变量,方便p1,p2进行数据交换。最后p2==NULL时退出,p1地址作为头结点的值,并且把原来头结点的下一个地址置空。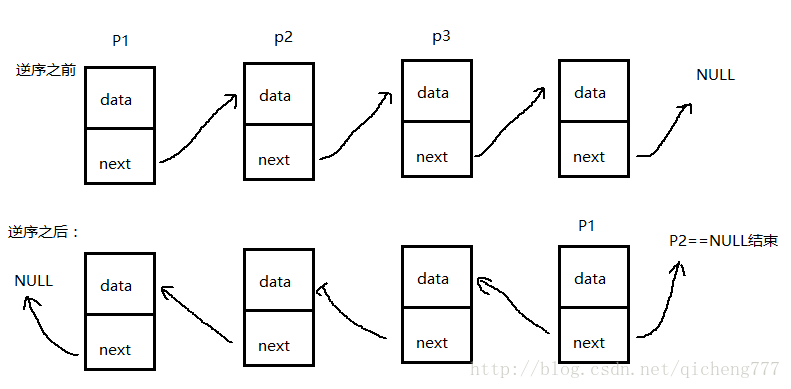
node *inverted(node *pNode)
{
node *p1,*p2,*p3;
p1=p2=p3=NULL;
p1=pNode;
if(pNode == NULL || pNode->pNext ==NULL)
{
return pNode;
}
else
{
p1=pNode;
p2=pNode->pNext;
}
while(p2 != NULL)
{
p3 = p2->pNext;
p2->pNext=p1;
p1=p2;
p2=p3;
}
pNode->pNext = NULL; //首元结点变最后一个结点,所以指向空
pNode=p1; //p1移动到最后,把p1地址赋给首元结点。
return pNode;
}7、链表摧毁:
移动一次后,把前面的结点free并置空。void link_destory(node *pNode)
{
node *p1;
while( pNode != NULL)
{
p1=pNode->pNext;
pNode=p1;
free(p1);
p1=NULL;
}
}总结:
关于free()与野指针:链表的操作关键在与操作指针,所以经常出现段错误。为了避免这种情况,我们定义指针后一定要对它进行初始化,而且操作之前要判断是否为NULL,这很重要,经常容易出错。还有就是,在用完要记得free,那么之后,free之后,指针就变成了野指针,一定要把指针赋值为NULL。
比如,在这个例子中,我们可以看到,指针free之后地址依旧不变,只不过它的值变了,变成了一个野指针。
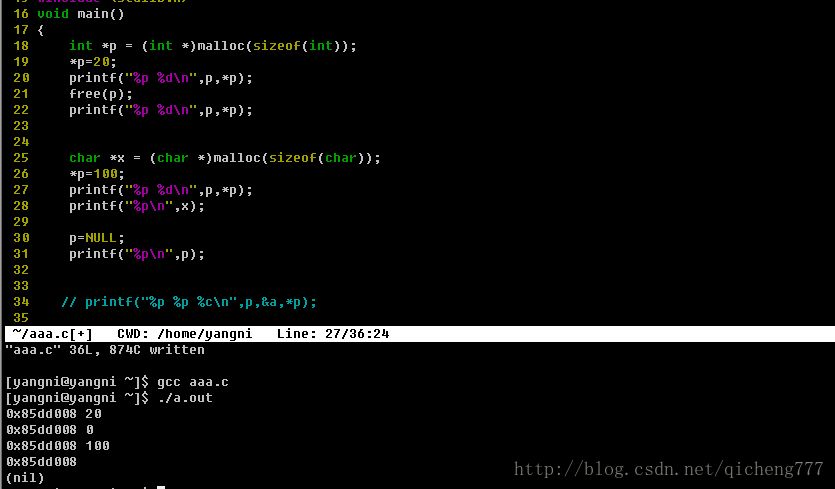
形象点来说就是:
你大学的宿舍,入学后就申请,大学四年一直是你在用,别人不能用;大学毕业后,还给了学校,学校究竟有没有分配给别人你就不清楚了,反正你再也不能使用; 分配给你的寝室号一直在那,你的心也一直记得那个号码
关于二级指针
指针的指针就是二级指针。指针用来存放地址,那么二级指针就是用来存放指针的地址。所以当程序中操作链表结点的地址时候,比如,要更改头结点的时候,就需要通过二级指针来实现,我们传入的头结点是一个,node**类型这时候不需要返回值。我们如果不想用二级指针,也可以通过通过返回 node * 的头结点来实现。

相关文章推荐
- 基本单向链表的操作
- 单向链表的基本操作及逆序实现
- java 单向链表的基本操作
- 单向循环链表的基本操作
- 单向链表的基本操作
- 数据结构学习之单向链表的基本操作(非递归实现)
- 单向链表,单向循环链表的基本操作
- 单向链表的基本操作-创建、插入、删除
- 单向链表的基本操作
- 单向链表的基本操作
- 名单(两)——基本操作单向链表(创、删、印、节点统计数)
- 单向链表的C语言实现与基本操作
- 算法与数据结构-单向链表的基本操作C语言实现
- java版的单向链表的基本操作
- 单向链表基本操作
- 单向链表的基本操作
- c++之链表篇1:单向链表的创建,打印,删除,插入,销毁等基本操作
- 单向链表的定义及基本操作
- 单向链表的基本操作
- 单向链表的基本操作