谢烟客---------Linux之文本处理三剑客之grep
2017-07-31 20:12
465 查看
Linux之文本处理三剑客介绍
awk 名称得自于它的创始人阿尔佛雷德·艾侯、彼得·温伯格和布莱恩·柯林汉姓氏的首个字母,它具备了一个完整的语言所应具有的几乎所有精美特性,AWK是一个解释器,三位创建者已将它正式定义为“样式扫描和处理语言”。它允许您创建简短的程序,这些程序读取输入文件、为数据排序、处理数据、对输入执行计算以及生成报表,还有无数其他的功能。Linux使用的是Gnu版本的AWK,gawk
grep 全称"Global search REgular expression and Print out the line,以正规表示法进行全域查找以及打印" 由肯·汤普逊所写,在大段文本中,按指定的过滤条件或过滤模式, 根据用户指定的"模式对目标文本逐行进行匹配检查",把匹配到的行打印到屏幕上。
sed sream eidtor 行编辑器,也能实现文本过滤功能
grep
通配原理:grep程序依据,用户给出的模式对标准输入输入的数据流逐个匹配检测,并将匹配到的字符串以行的方式显示到标准输出
模式:PATTERN,由正则表达式字符或纯文本字符所编写的过滤条件,注意纯文本字符用grep匹配也会调用正则表达式引擎,不如直接用fgrep
正则表达式字符:Regular Expression,简写regex,regexp,RE表示,由不表示字面意义的特殊字符表示,有“基本正则表达式字符”“扩展正则表达式字符”
与grep相关的工具:
grep,支持基本正则表达式 BRE,Basic Regular Expression
egrep,支持扩展正则表达式 ERE,Extension Regular Expression
fgrep,不支持正则表达式 FRE Fast Regular Expression ,最为高效的精确匹配算法实现字符匹配
能够调用正则表达式的工具:
grep,egrep,sed,awk,perl
1)正则表达式的元字符不同
2)各自调用不同的正则表达式引擎
3)各自实现的算法不一样
4)perl支持较为强大的正则表达式引擎,一般写程序需要用到正则表达式,都会调用perl的正则表达式,如果需要使用perl的正则表达式,需要在编译时指明 --pcre,就能实现正则表达式解析和匹配检查。
正则表达式引擎:把模式套到文本,检查表达式匹配与否
grep命令
grep选项注释
--colour=auto #将匹配到的文本高亮显示
1、自动高亮显示文本
2、Rehl7系统自动添加别名,Rehl 6需要定义‘grep别名’方能简化grep匹配时高亮显示的过程
-v 不显示被PATTERN匹配到的字符串所在的行,只显示其他行

2、显示模式不能匹配的行
- q,quit 匹配到的内容不显示到标准输出,一般用于使用"命令的执行状态结果"
1、如果gentoo用户存在就显示OK
-i 忽略PATTERN中特殊字符的大小写

-C,context 显示匹配到的行及前后各NUM行
-A,after 显示匹配到的行及后NUM行
-B,before 显示匹配到的行及前NUM行
-o,only-match 仅显示匹配到的字符串
-n,number 显示匹配到的行的行号
-c,count 显示匹配到的行的行数,相当于, COMMAND | wc -l
基本正则表达式字符
字符匹配
匹配次数
位置锚定
字符匹配
1) . 匹配任意单个字符, .. 匹配两个字符
2)[] 匹配指定范围内的任意单个字符 (同glob)
3)[^] 匹配范围之外的任意单个字符 (同glob)
使用示例


.. 匹配两个字符

[] 匹配指定范围内的任意单个字符
1)匹配任意单个小写字母


2)匹配单个大写字母


3)匹配aeioU范围内任意单个字符
[^] 匹配范围之外的任意单个字符
匹配任意3个字符后跟t

匹配任意3个字母后跟t

匹配次数 '前面的单个字符出现的次数'
1)* 匹配前面单个字符出现0、1或多次
2)\? 匹配前面单个字符出现0次或1次
3)\+ 匹配前面的字符'至少1次',>=1次
4) \{m\} 精确匹配前面单个字符m次
5)\{m,n\} 匹配前面单个字符至少m次,至多n次
使用示例
3) \+匹配前面单个字符'至少1次'

4)\{m\} 精确匹配前面单个字符m次

5)\{m,n\} 匹配前面单个字符至少m次,至多n次;

5.1)m=0时,匹配前面的单个字符至多n次
5.2)n=时,匹配前面的单个字符至少m次
位置锚定 ‘期望匹配的字符必须出现在某个位置’
1)^ 行首锚定,用于模式最左侧。由正则表达式所匹配到的字串符必须出现在行首
2)$ 行尾锚定,用于模式最右侧。由正则表达式所匹配到的字串符必须出现在行尾
3)^pattern$: 整行只能匹配此模式
4)匹配空白行: ^[[:space:]]*$ 空白可有任意次数
5)\< 或 \b 词首锚定,用于单词模式的左侧
6)\> 或 \b 词尾锚定,用于单词模式的右侧
7) \<PATTERN\> 或 \bPATTERN\b 匹配整个单词,用于单词左右两侧
8)分组
使用示例
1)^ 行首锚定,用于模式最左侧。由正则表达式所匹配到的字串符必须出现在行首

2)$ 行尾锚定,用于模式最右侧。由正则表达式所匹配到的字串符必须出现在行尾
3)^pattern$: 整行只能匹配此模式
6)\> 或 \b 词尾锚定,用于单词模式的右侧
7) \<PATTERN\> 或 \bPATTERN\b 匹配整个单词,用于单词左右两侧
8)分组: \(\) 将任意个字符当前同一个组件

9)后向引用:分组括号中的模式匹配到的内容会被正则表达式引擎记录于内部的变量中,这些变量的命名方式为:\1,\2,\3
\1:从PATTERN左侧起,第一个左括号与与之对应的右括号之间的模式匹配到的字符
\(ab+\(xy\)*\)
\1: ab+\(xy\)* 模式所匹配到的内容
\2: xy 模式所匹配到的内容

awk 名称得自于它的创始人阿尔佛雷德·艾侯、彼得·温伯格和布莱恩·柯林汉姓氏的首个字母,它具备了一个完整的语言所应具有的几乎所有精美特性,AWK是一个解释器,三位创建者已将它正式定义为“样式扫描和处理语言”。它允许您创建简短的程序,这些程序读取输入文件、为数据排序、处理数据、对输入执行计算以及生成报表,还有无数其他的功能。Linux使用的是Gnu版本的AWK,gawk
grep 全称"Global search REgular expression and Print out the line,以正规表示法进行全域查找以及打印" 由肯·汤普逊所写,在大段文本中,按指定的过滤条件或过滤模式, 根据用户指定的"模式对目标文本逐行进行匹配检查",把匹配到的行打印到屏幕上。
sed sream eidtor 行编辑器,也能实现文本过滤功能
grep
通配原理:grep程序依据,用户给出的模式对标准输入输入的数据流逐个匹配检测,并将匹配到的字符串以行的方式显示到标准输出
模式:PATTERN,由正则表达式字符或纯文本字符所编写的过滤条件,注意纯文本字符用grep匹配也会调用正则表达式引擎,不如直接用fgrep
正则表达式字符:Regular Expression,简写regex,regexp,RE表示,由不表示字面意义的特殊字符表示,有“基本正则表达式字符”“扩展正则表达式字符”
与grep相关的工具:
grep,支持基本正则表达式 BRE,Basic Regular Expression
egrep,支持扩展正则表达式 ERE,Extension Regular Expression
fgrep,不支持正则表达式 FRE Fast Regular Expression ,最为高效的精确匹配算法实现字符匹配
能够调用正则表达式的工具:
grep,egrep,sed,awk,perl
1)正则表达式的元字符不同
2)各自调用不同的正则表达式引擎
3)各自实现的算法不一样
4)perl支持较为强大的正则表达式引擎,一般写程序需要用到正则表达式,都会调用perl的正则表达式,如果需要使用perl的正则表达式,需要在编译时指明 --pcre,就能实现正则表达式解析和匹配检查。
正则表达式引擎:把模式套到文本,检查表达式匹配与否
grep命令
1、第一步,获取命令的类型 [root@izpo45bh60h6bsz ~]# type grep grep is aliased to `grep --color=auto' [root@izpo45bh60h6bsz ~]# which --skip-alias grep /usr/bin/grep 2、用外部命令获取帮助的方法,获取grep命令的帮助 [root@izpo45bh60h6bsz ~]# grep --help Usage: grep [OPTION]... PATTERN [FILE]... 通过模式搜索每一个文本或标准输入的数据,显示由PATTERN匹配到的字串所在的行。 默认使用BRE匹配 Regexp selection and interpretation: -E, --extended-regexp #ERE -F, --fixed-strings #FRE -G, --basic-regexp #BRE -P, --perl-regexp #PRE -i, --ignore-case #匹配时忽略PATTERN中字符大小写 Miscellaneous: -v, --invert-match #仅显示不能够PATTERN匹配到的行 Output control: -n,--number #显示匹配到的行的行号 -c, --count #显示匹配到的行的行数 -o, --only-matching #仅显示匹配到的字符串 -q, --quiet, --silent #静默模式 Context control: -B, --before-context=NUM #显示匹配到的行及行前的NUM行 -A, --after-context=NUM #显示匹配到的行及行后的NUM行 -C, --context=NUM #显示匹配到的行及行前后各NUM行 --colour=auto #将匹配到的文本高亮显示
grep选项注释
--colour=auto #将匹配到的文本高亮显示
1、自动高亮显示文本
2、Rehl7系统自动添加别名,Rehl 6需要定义‘grep别名’方能简化grep匹配时高亮显示的过程
[root@izpo45bh60h6bsz ~]# alias alias egrep='egrep --color=auto' alias fgrep='fgrep --color=auto' alias grep='grep --color=auto'
-v 不显示被PATTERN匹配到的字符串所在的行,只显示其他行
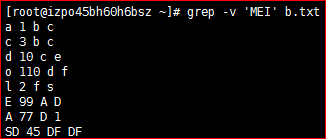
[root@izpo45bh60h6bsz ~]# vim b.txt a 1 b c c 3 b c d 10 c e o 110 d f l 2 f s E 99 A D A 77 D 1 SD 45 DF DF MEI 66 AD OOO1、显示被PATTERN匹配到的字符串所在的行
2、显示模式不能匹配的行
- q,quit 匹配到的内容不显示到标准输出,一般用于使用"命令的执行状态结果"
1、如果gentoo用户存在就显示OK
[root@izpo45bh60h6bsz ~]# who | grep -q '^gentoo\b' && echo 'OK'*逻辑运算中:与运算:左侧为真,才会继续向后执行
-i 忽略PATTERN中特殊字符的大小写
grep -i 'how' a.txt
-C,context 显示匹配到的行及前后各NUM行
[root@izpo45bh60h6bsz ~]# grep -C 2 -i 'ipvs' /boot/config-3.10.0-514.6.2.el7.x86_64 CONFIG_NETFILTER_XT_MATCH_HL=m CONFIG_NETFILTER_XT_MATCH_IPRANGE=m CONFIG_NETFILTER_XT_MATCH_IPVS=m CONFIG_NETFILTER_XT_MATCH_LENGTH=m CONFIG_NETFILTER_XT_MATCH_LIMIT=m
-A,after 显示匹配到的行及后NUM行
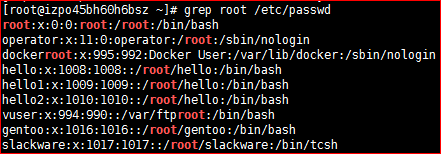
[root@izpo45bh60h6bsz ~]# grep -A 2 'root' /etc/passwd root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin ....
-B,before 显示匹配到的行及前NUM行
[root@izpo45bh60h6bsz ~]# grep -B 2 'root' /etc/passwd root:x:0:0:root:/root:/bin/bash #此处为首行,之前没有,所以显示不出来 -- halt:x:7:0:halt:/sbin:/sbin/halt mail:x:8:12:mail:/var/spool/mail:/sbin/nologin operator:x:11:0:operator:/root:/sbin/nologin
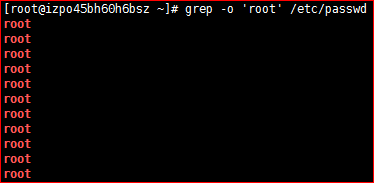
-o,only-match 仅显示匹配到的字符串
# grep -o 'root' /etc/passwd
-n,number 显示匹配到的行的行号
[root@izpo45bh60h6bsz ~]# grep -n 'root' /etc/passwd
1:root:x:0:0:root:/root:/bin/bash
10:operator:x:11:0:operator:/root:/sbin/nologin
29:dockerroot:x:995:992:Docker User:/var/lib/docker:/sbin/nologin
41:hello:x:1008:1008::/root/hello:/bin/bash
42:hello1:x:1009:1009::/root/hello:/bin/bash
43:hello2:x:1010:1010::/root/hello:/bin/bash
47:vuser:x:994:990::/var/ftproot:/bin/bash
48:gentoo:x:1016:1016::/root/gentoo:/bin/bash
49:slackware:x:1017:1017::/root/slackware:/bin/tcsh
[root@izpo45bh60h6bsz ~]# awk '/root/{print NR,$0}' /etc/passwd
1 root:x:0:0:root:/root:/bin/bash
10 operator:x:11:0:operator:/root:/sbin/nologin
29 dockerroot:x:995:992:Docker User:/var/lib/docker:/sbin/nologin
41 hello:x:1008:1008::/root/hello:/bin/bash
42 hello1:x:1009:1009::/root/hello:/bin/bash
43 hello2:x:1010:1010::/root/hello:/bin/bash
47 vuser:x:994:990::/var/ftproot:/bin/bash
48 gentoo:x:1016:1016::/root/gentoo:/bin/bash
49 slackware:x:1017:1017::/root/slackware:/bin/tcsh-c,count 显示匹配到的行的行数,相当于, COMMAND | wc -l
[root@izpo45bh60h6bsz ~]# grep -c 'root' /etc/passwd 9 [root@izpo45bh60h6bsz ~]# grep 'root' /etc/passwd | wc -l 9
基本正则表达式字符
字符匹配
匹配次数
位置锚定
字符匹配
1) . 匹配任意单个字符, .. 匹配两个字符
2)[] 匹配指定范围内的任意单个字符 (同glob)
3)[^] 匹配范围之外的任意单个字符 (同glob)
使用示例
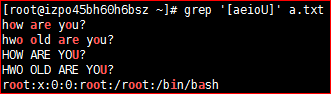
[root@izpo45bh60h6bsz ~]# vim a.txt #vim是一个文本编辑命令,进入后按i键,才可编写文本,编写完毕后。按esc键,再按shift 加 : 键,输入wq加Enter键即可。 how are you? hwo old are you? HOW ARE YOU? HWO OLD ARE YOU? root:x:0:0:root:/root:/bin/bash. 匹配任意单个字符
# grep 'h.w' a.txt # grep -i 'h.w' a.txt #匹配时,不区分字符大小写
.. 匹配两个字符
# grep 'r..t' a.txt
[] 匹配指定范围内的任意单个字符
1)匹配任意单个小写字母
# grep 'h[a-z]' a.txt #glob通配时,为所有的字母 # grep 'h[[:lower:]]' a.txt
2)匹配单个大写字母
# grep '[A-Z]W' a.txt # grep '[[:upper:]]W' a.txt
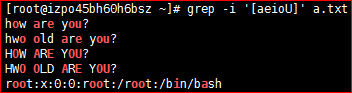
3)匹配aeioU范围内任意单个字符
# grep '[aeioU]' a.txt # grep -i '[aeioU]' a.txt
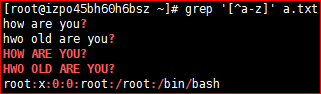
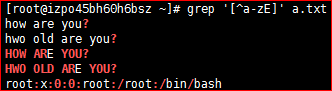
[^] 匹配范围之外的任意单个字符
# grep '[^a-z]' a.txt # grep '[^a-zE]' a.txt
匹配任意3个字符后跟t
# grep '...t' a.txt
匹配任意3个字母后跟t
# grep '[[:alpha:]][[:alpha:]][[:alpha:]]t' a.txt # grep '[a-zA-Z]' a.txt
匹配次数 '前面的单个字符出现的次数'
1)* 匹配前面单个字符出现0、1或多次
2)\? 匹配前面单个字符出现0次或1次
3)\+ 匹配前面的字符'至少1次',>=1次
4) \{m\} 精确匹配前面单个字符m次
5)\{m,n\} 匹配前面单个字符至少m次,至多n次
使用示例
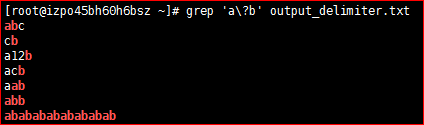
[root@izpo45bh60h6bsz ~]# vim output_delimiter.txt ab cb a12b aab abb abababababababab1)* 匹配前面单个字符出现0、1或多次
# grep 'a*b' output_delimiter.txt #你说:“cb能匹配到吗?”2)\? 匹配前面单个字符出现0次或1次
# grep 'a\?b' output_delimiter.txt
3) \+匹配前面单个字符'至少1次'
# grep 'a\+b' output_delimiter.txt
4)\{m\} 精确匹配前面单个字符m次
# grep 'a\{2\}b' output_delimiter.txt5)\{m,n\} 匹配前面单个字符至少m次,至多n次;
# grep 'a\{1,2\}b' output_delimiter.txt5.1)m=0时,匹配前面的单个字符至多n次
# echo -e 'aaaaaaaaaaaab\naaab\naaab' >> output_delimiter.txt
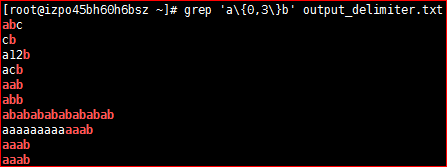
# grep 'a\{0,3\}b' output_delimiter.txt5.2)n=时,匹配前面的单个字符至少m次
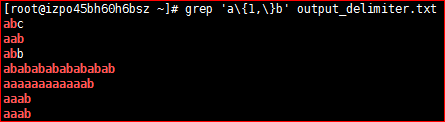
# grep 'a\{1,\}b' output_delimiter.txt位置锚定 ‘期望匹配的字符必须出现在某个位置’
1)^ 行首锚定,用于模式最左侧。由正则表达式所匹配到的字串符必须出现在行首
2)$ 行尾锚定,用于模式最右侧。由正则表达式所匹配到的字串符必须出现在行尾
3)^pattern$: 整行只能匹配此模式
4)匹配空白行: ^[[:space:]]*$ 空白可有任意次数
5)\< 或 \b 词首锚定,用于单词模式的左侧
6)\> 或 \b 词尾锚定,用于单词模式的右侧
7) \<PATTERN\> 或 \bPATTERN\b 匹配整个单词,用于单词左右两侧
8)分组
使用示例
# useradd rooter # useradd rootor
1)^ 行首锚定,用于模式最左侧。由正则表达式所匹配到的字串符必须出现在行首
# grep '^root' /etc/passwd
2)$ 行尾锚定,用于模式最右侧。由正则表达式所匹配到的字串符必须出现在行尾
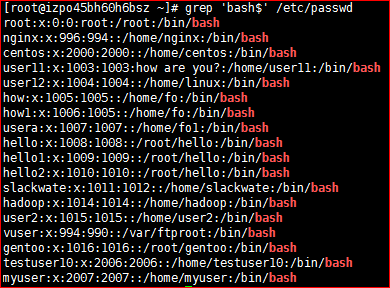
# grep 'bash$' /etc/passwd
3)^pattern$: 整行只能匹配此模式
# vim c.txt
[root@izpo45bh60h6bsz ~]# cat -n c.txt 1 2 3 4 5
[root@izpo45bh60h6bsz ~]# grep -n '^$' c.txt 1: 2: 3:4)匹配空白行: ^[[:space:]]*$ 空白可有任意次数
[root@izpo45bh60h6bsz ~]# grep -n '^[[:space:]]*' c.txt 1: 2: 3: 4: 5: [root@izpo45bh60h6bsz ~]# grep -c '^[[:space:]]*' c.txt 55)\< 或 \b 词首锚定,用于单词模式的左侧
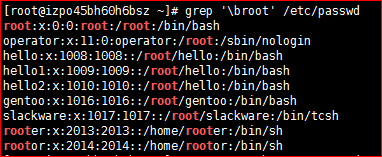
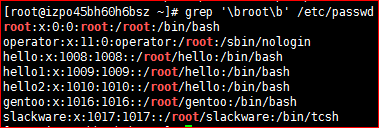
# grep '\broot' /etc/passwd
6)\> 或 \b 词尾锚定,用于单词模式的右侧
# grep 'root\b' /etc/passwd
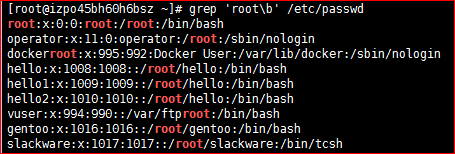
7) \<PATTERN\> 或 \bPATTERN\b 匹配整个单词,用于单词左右两侧
# grep '\broot\b' /etc/passwd
8)分组: \(\) 将任意个字符当前同一个组件
# cat grep.txt abxy xxxxxxy xyxyxyxyabcxy
# grep '\(xy\)\+' grep.txt
9)后向引用:分组括号中的模式匹配到的内容会被正则表达式引擎记录于内部的变量中,这些变量的命名方式为:\1,\2,\3
\1:从PATTERN左侧起,第一个左括号与与之对应的右括号之间的模式匹配到的字符
\(ab+\(xy\)*\)
\1: ab+\(xy\)* 模式所匹配到的内容
\2: xy 模式所匹配到的内容
# grep '^\([[:alnum:]]\+\>\).*\1$' /etc/passwd

相关文章推荐
- 谢烟客---------Linux之文本处理三剑客之egre、fgrep
- Linux文本处理三剑客之grep一族与正则表达式
- Linux文本处理三剑客(grep)
- Linux 文本处理剑客grep
- Linux文本处理三剑客之grep
- Linux文本处理“三剑客”之grep
- Linux文本处理三剑客之grep命令
- Linux文本处理三剑客之grep
- linux文本处理三剑客之grep
- Linux_ 文本处理三剑客中的“大宝剑“―Grep家族
- Linux文本处理三剑客之grep和sed
- Linux 基础命令(五)—— 文本处理三剑客之grep
- Linux文本处理三剑客之grep
- linux文本处理三剑客之grep
- Linux文本处理三剑客之grep
- linux文本处理三剑客之grep
- grep--Linux文本处理三剑客之一
- linux文本处理三剑客之grep家族及其相应的正则表达式使用详解
- Linux文本处理三剑客之grep
- Linux文本处理三剑客之grep