【大数据系列】windows下连接Linux环境开发
2017-07-31 18:33
281 查看
一、配置文件
1.core-site.xml
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://www.node1.com:9000</value> </property> </configuration>
2、hdfs-site.xml
<configuration> <property> <name>dfs.replication</name> <value>2</value> </property> </configuration>
3、yarn-site.xml
<property> <name>yarn.resourcemanager.hostname</name> <value>www.node1.com</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>
4、slaves
www.node2.com www.node3.com
二、建立本地连接
三、创建MapReduceProject
1、File -- new - Other --MapReduceProject
2、建立测试文件
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println(otherArgs.length);
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
}
System.out.println(otherArgs[0]);
System.out.println(otherArgs[1]);
Job job = new Job(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}3、run configuration
hdfs://www.node1.com:9000/usr/wc hdfs://www.node1.com:9000/usr/wc/output
4、run
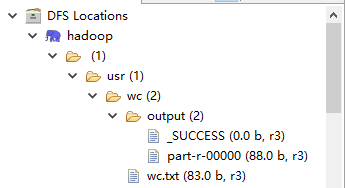
5、part-r-00000
apple 2 banana 1 cat 1 dog 1 hadoop 1 hadpp 1 hello 1 mapreduce 1 name 1 world 1 yarn 2
6、wc.txt
hadoop hello hadpp world apple dog banana cat mapreduce name yarn apple yarn

相关文章推荐
- 【大数据系列】在windows下连接linux 下的hadoop环境进行开发
- windows环境下java开发连接linux环境的hbase数据获取CURD
- linux开发环境搭建-----虚拟机和windows的网络连接原理+具体配置。
- 【大数据系列】windows环境下搭建hadoop开发环境使用api进行基本操作
- 【大数据系列】windows搭建hadoop开发环境
- 连接远程linux spark 配置windows 下pycharm开发环境
- 【嵌入式Linux学习七步曲之第二篇 交叉开发环境】U-boot和Windows TFTP server交互,socket recv error 10060
- windows下搭建Linux开发环境
- 在Linux下和windows下配置apache+php+mysql 开发环境和Zend Studio+Aptana Studio 的IDE
- 跨平台wxWidgets在windows及linux上的开发环境搭建
- Silverlight for Windows Phone 7开发系列(1):环境搭建
- 【Android开发学习系列】(1)——Windows下Android开发环境配置
- 【转】Silverlight for Windows Phone 7开发系列(1):环境搭建
- 开发环境搭建4:linux下tuxedo与oracle连接
- Windows下的linux开发环境Cygwin的安装配置
- GTK+学习:概述 、搭建环境(Windows,Linux)、开发
- 【嵌入式Linux学习七步曲之第一篇 Linux主机开发环境】虚拟机下Linux和windows的文件共享――mount方式
- datastage server job开发之在windows环境下模拟linux的运行
- Windows下的linux开发环境Cygwin的安装配置
- 【嵌入式Linux学习七步曲之第一篇 Linux主机开发环境】虚拟机下Linux和windows的文件共享――共享方式