深度学习优化函数详解(4)-- momentum 动量法
2017-07-28 17:36
369 查看
深度学习优化函数详解系列目录
深度学习优化函数详解(0)– 线性回归问题
深度学习优化函数详解(1)– Gradient Descent 梯度下降法
深度学习优化函数详解(2)– SGD 随机梯度下降
深度学习优化函数详解(3)– mini-batch SGD 小批量随机梯度下降
深度学习优化函数详解(4)– momentum 动量法
深度学习优化函数详解(5)– Nesterov accelerated gradient (NAG)
深度学习优化函数详解(6)– adagrad
本文延续该系列的上一篇 深度学习优化函数详解(3)– mini-batch SGD 小批量随机梯度下降
如果把梯度下降法想象成一个小球从山坡到山谷的过程,那么前面几篇文章的小球是这样移动的:从A点开始,计算当前A点的坡度,沿着坡度最大的方向走一段路,停下到B。在B点再看一看周围坡度最大的地方,沿着这个坡度方向走一段路,再停下。确切的来说,这并不像一个球,更像是一个正在下山的盲人,每走一步都要停下来,用拐杖来来探探四周的路,再走一步停下来,周而复始,直到走到山谷。而一个真正的小球要比这聪明多了,从A点滚动到B点的时候,小球带有一定的初速度,在当前初速度下继续加速下降,小球会越滚越快,更快的奔向谷底。momentum 动量法就是模拟这一过程来加速神经网络的优化的。
后文的公式推导不加特别说明都是基于 mini-batch SGD 的,请注意。

上图直观的解释了动量法的全部内容。
A为起始点,首先计算A点的梯度∇a∇a ,然后下降到B点,
θnew=θ−α∇aθnew=θ−α∇a
θθ 为参数αα 为学习率。
到了B点需要加上A点的梯度,这里梯度需要有一个衰减值γγ ,推荐取0.9。这样的做法可以让早期的梯度对当前梯度的影响越来越小,如果没有衰减值,模型往往会震荡难以收敛,甚至发散。所以B点的参数更新公式是这样的:
vt=γvt−1+α∇bvt=γvt−1+α∇b
θnew=θ−vtθnew=θ−vt
其中vt−1vt−1 表示之前所有步骤所累积的动量和。
这样一步一步下去,带着初速度的小球就会极速的奔向谷底。
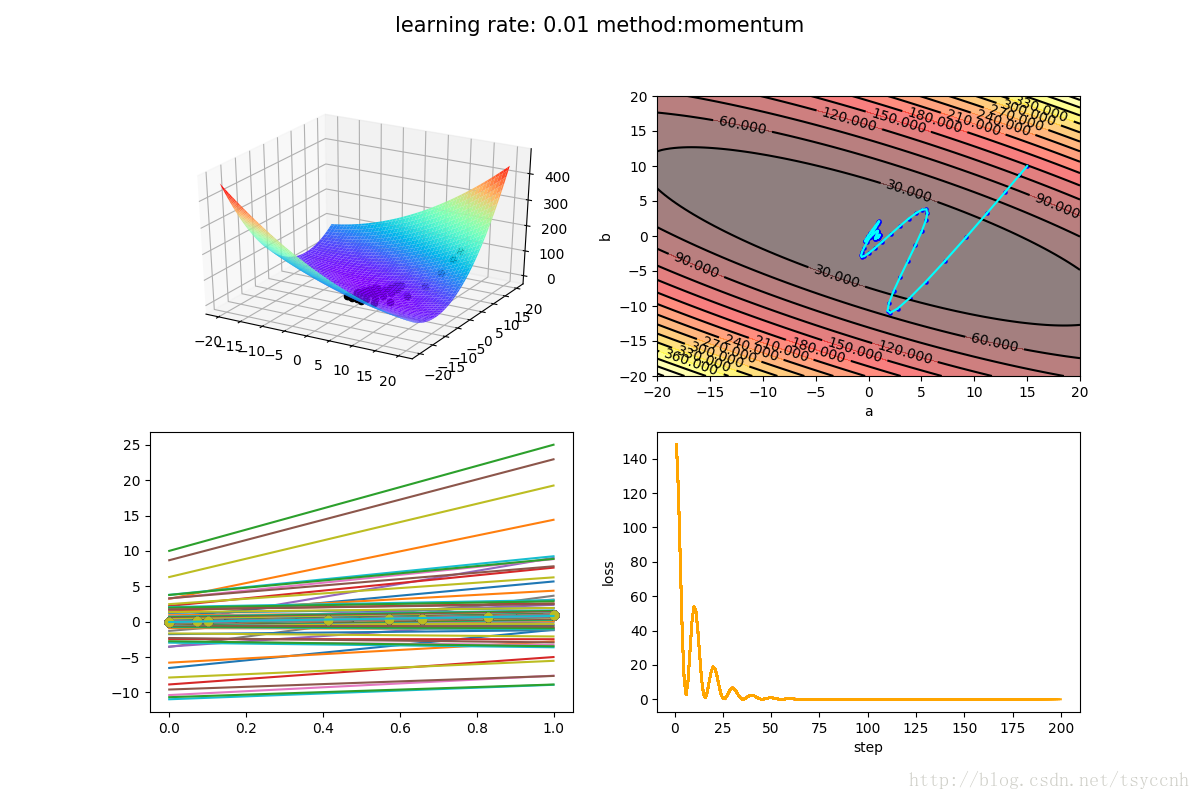
学习率 α=0.01α=0.01,衰减率 γ=0.9γ=0.9
对比Gradient Descent

仔细看右上角的等高线图就可以看见,momentum方法每一步走的都要更远一些。由于累加了动量,会带着之前的速度向前方冲去。比如一开始loss冲入了山谷,由于有之前的动量,继续朝着对面的山坡冲了上去。随着动量的更新,慢慢地最终收敛到了最小值。
注:对比图可能看起来GD算法要好于momentum方法,这仅仅是由于数据集比较简单。本文旨在从理论和实际实验中去学习momentum方法,不对结果对比做太多讨论。实验的结果往往和数据集、参数选择有很大关系。
本文实验代码:https://github.com/tsycnh/mlbasic/blob/master/p4%20momentum.py
深度学习优化函数详解(0)– 线性回归问题
深度学习优化函数详解(1)– Gradient Descent 梯度下降法
深度学习优化函数详解(2)– SGD 随机梯度下降
深度学习优化函数详解(3)– mini-batch SGD 小批量随机梯度下降
深度学习优化函数详解(4)– momentum 动量法
深度学习优化函数详解(5)– Nesterov accelerated gradient (NAG)
深度学习优化函数详解(6)– adagrad
本文延续该系列的上一篇 深度学习优化函数详解(3)– mini-batch SGD 小批量随机梯度下降
如果把梯度下降法想象成一个小球从山坡到山谷的过程,那么前面几篇文章的小球是这样移动的:从A点开始,计算当前A点的坡度,沿着坡度最大的方向走一段路,停下到B。在B点再看一看周围坡度最大的地方,沿着这个坡度方向走一段路,再停下。确切的来说,这并不像一个球,更像是一个正在下山的盲人,每走一步都要停下来,用拐杖来来探探四周的路,再走一步停下来,周而复始,直到走到山谷。而一个真正的小球要比这聪明多了,从A点滚动到B点的时候,小球带有一定的初速度,在当前初速度下继续加速下降,小球会越滚越快,更快的奔向谷底。momentum 动量法就是模拟这一过程来加速神经网络的优化的。
后文的公式推导不加特别说明都是基于 mini-batch SGD 的,请注意。
公式推导
更多实验数据背景及模型定义请参看该系列的前几篇文章。上图直观的解释了动量法的全部内容。
A为起始点,首先计算A点的梯度∇a∇a ,然后下降到B点,
θnew=θ−α∇aθnew=θ−α∇a
θθ 为参数αα 为学习率。
到了B点需要加上A点的梯度,这里梯度需要有一个衰减值γγ ,推荐取0.9。这样的做法可以让早期的梯度对当前梯度的影响越来越小,如果没有衰减值,模型往往会震荡难以收敛,甚至发散。所以B点的参数更新公式是这样的:
vt=γvt−1+α∇bvt=γvt−1+α∇b
θnew=θ−vtθnew=θ−vt
其中vt−1vt−1 表示之前所有步骤所累积的动量和。
这样一步一步下去,带着初速度的小球就会极速的奔向谷底。
实验
由于样本数量较少,动量的实验未使用SGD,每一次更新loss使用全部数据学习率 α=0.01α=0.01,衰减率 γ=0.9γ=0.9
对比Gradient Descent
仔细看右上角的等高线图就可以看见,momentum方法每一步走的都要更远一些。由于累加了动量,会带着之前的速度向前方冲去。比如一开始loss冲入了山谷,由于有之前的动量,继续朝着对面的山坡冲了上去。随着动量的更新,慢慢地最终收敛到了最小值。
注:对比图可能看起来GD算法要好于momentum方法,这仅仅是由于数据集比较简单。本文旨在从理论和实际实验中去学习momentum方法,不对结果对比做太多讨论。实验的结果往往和数据集、参数选择有很大关系。
本文实验代码:https://github.com/tsycnh/mlbasic/blob/master/p4%20momentum.py

相关文章推荐
- 深度学习优化函数详解(4)-- momentum 动量法
- 深度学习优化函数详解(3)-- mini-batch SGD 小批量随机梯度下降
- 深度学习优化函数详解(5)-- Nesterov accelerated gradient (NAG)
- 深度学习优化函数详解(6)-- adagrad
- 深度学习优化函数详解(6)-- adagrad
- 深度学习优化函数详解(0)-- 线性回归问题
- 深度学习优化函数详解(1)-- Gradient Descent 梯度下降法
- 深度学习优化函数详解(3)-- mini-batch SGD 小批量随机梯度下降
- 深度学习优化函数详解(1)-- Gradient Descent 梯度下降法
- 深度学习优化函数详解(0)-- 线性回归问题
- 深度学习优化函数详解(2)-- SGD 随机梯度下降
- 深度学习优化函数详解
- 深度学习优化函数详解(5)-- Nesterov accelerated gradient (NAG)
- 深度学习优化函数详解(2)-- SGD 随机梯度下降
- 深度学习各种优化函数详解
- 深度学习之momentum,RMSprop,Adam优化算法
- 深度学习——优化器算法Optimizer详解(BGD、SGD、MBGD、Momentum、NAG、Adagrad、Adadelta、RMSprop、Adam)
- 深度学习笔记:优化方法总结(BGD,SGD,Momentum,AdaGrad,RMSProp,Adam)
- 深度学习与计算机视觉[CS231N] 学习笔记(3.3):函数优化(梯度下降法)
- 深度学习笔记:优化方法总结(BGD,SGD,Momentum,AdaGrad,RMSProp,Adam)