Linux 安装配置 tomcat
2017-07-23 17:38
323 查看
MapReduce实战WordCount
MapReduce是Hadoop中的核心,我们通过十分经典的WordCount程序来实战MapReduce.
一个完整的mapreduce程序在分布式运行时有三类实例进程:
MRAppMaster:负责整个程序的过程调度及状态协调mapTask:负责map阶段的整个数据处理流程
ReduceTask:负责reduce阶段的整个数据处理流程
我们要对应写的MapReduce程序主要也分为三部分:Mapper,Reducer,Runner
Mapper主要负责将数据进行初步的处理,接收的数据是Key,Value键值对的形式,处理后输出的数据格式也同样为key,Value的格式(key,Value的类型可自定义)
Mapper通过继承对应的父类Mapper,将主要的业务逻辑写在map()方法中
贴上WordCountMapper代码import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class WordCountMapper extends Mapper<LongWritable,Text,Text,IntWritable> {
//map方法的生命周期: 框架每传一行数据就被调用一次
//key : 这一行的起始点在文件中的偏移量
//value: 这一行的内容
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//拿到一行数据转换为string
String line = value.toString();
//将这一行切分出各个单词
String[] words = line.split(" ");
//遍历数组,输出<单词,1>
for (String word : words) {
context.write(new Text(word), new IntWritable(1));
}
}
}Reducer也是继承对应的父类Reducer,业务逻辑主要写在reduce()方法中
贴上WordCountReducer代码import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class WordCountMapper extends Mapper<LongWritable,Text,Text,IntWritable> {
//map方法的生命周期: 框架每传一行数据就被调用一次
//key : 这一行的起始点在文件中的偏移量
//value: 这一行的内容
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//拿到一行数据转换为string
String line = value.toString();
//将这一行切分出各个单词
String[] words = line.split(" ");
//遍历数组,输出<单词,1>
for (String word : words) {
context.write(new Text(word), new IntWritable(1));
}
}
}Runner是用来进行提交的,提交的是一个描述了各种必要信息的job对象
贴上WordCountRunner的代码import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.Job;
public class WordCountRunner {
//把业务逻辑相关的信息(哪个是mapper,哪个是reducer,要处理的数据在哪里,输出的结果放哪里……)描述成一个job对象
//把这个描述好的job提交给集群去运行
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job wcjob = Job.getInstance(conf);
wcjob.setJarByClass(WordCountRunner.class);
wcjob.setMapperClass(WordCountMapper.class);
wcjob.setReducerClass(WordCountReducer.class);
//设置我们的业务逻辑Mapper类的输出key和value的数据类型
wcjob.setMapOutputKeyClass(Text.class);
wcjob.setMapOutputValueClass(IntWritable.class);
//设置Reducer类的输出key和value的数据类型
wcjob.setOutputKeyClass(Text.class);
wcjob.setOutputValueClass(IntWritable.class);
//指定要处理的数据所在的位置
FileInputFormat.setInputPaths(wcjob, "/wordcount/data/big.txt");
//指定处理完成之后的结果所保存的位置
FileOutputFormat.setOutputPath(wcjob, new Path("/wordcount/output/"));
//向yarn集群提交这个job
boolean res = wcjob.waitForCompletion(true);
System.exit(res?0:1);
}
}接下来说明怎么通过hadoop集群运行这个WordCount程序
首先将程序打包成一个jar包,可以通过idea/myeclipse/eclipse的maven工具打包(idea打包方式)
然后开启虚拟机,保证hadoop集群是处于运行状态的
通过SecureCRT上传刚刚打包好的WordCount.jar文件

接着通过hdfs 创建文件夹(对应WordCountRunner中配置的路径)

然后通过hdfs命令运行上传的WordCount.jar
# hadoop jar wordcount.jar WordCountRunner inputpath outputpath
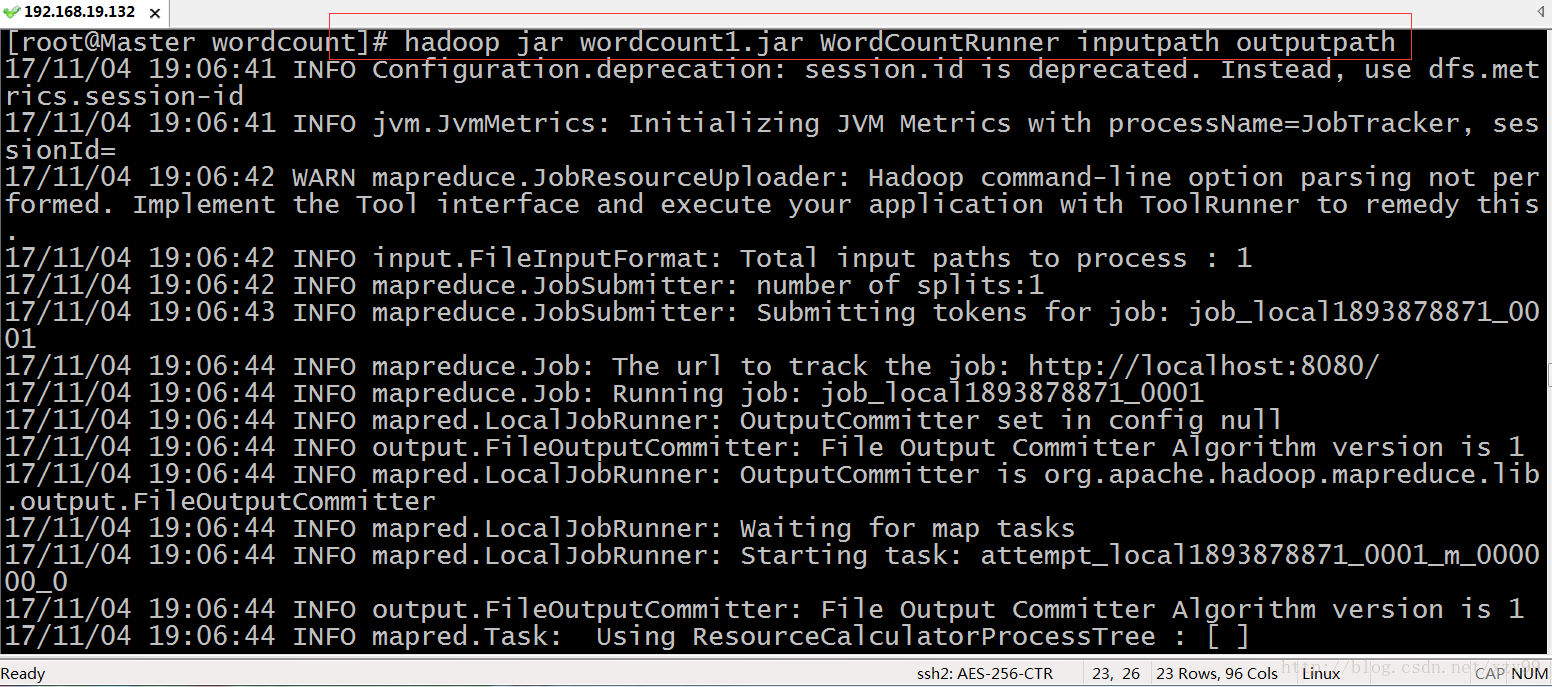
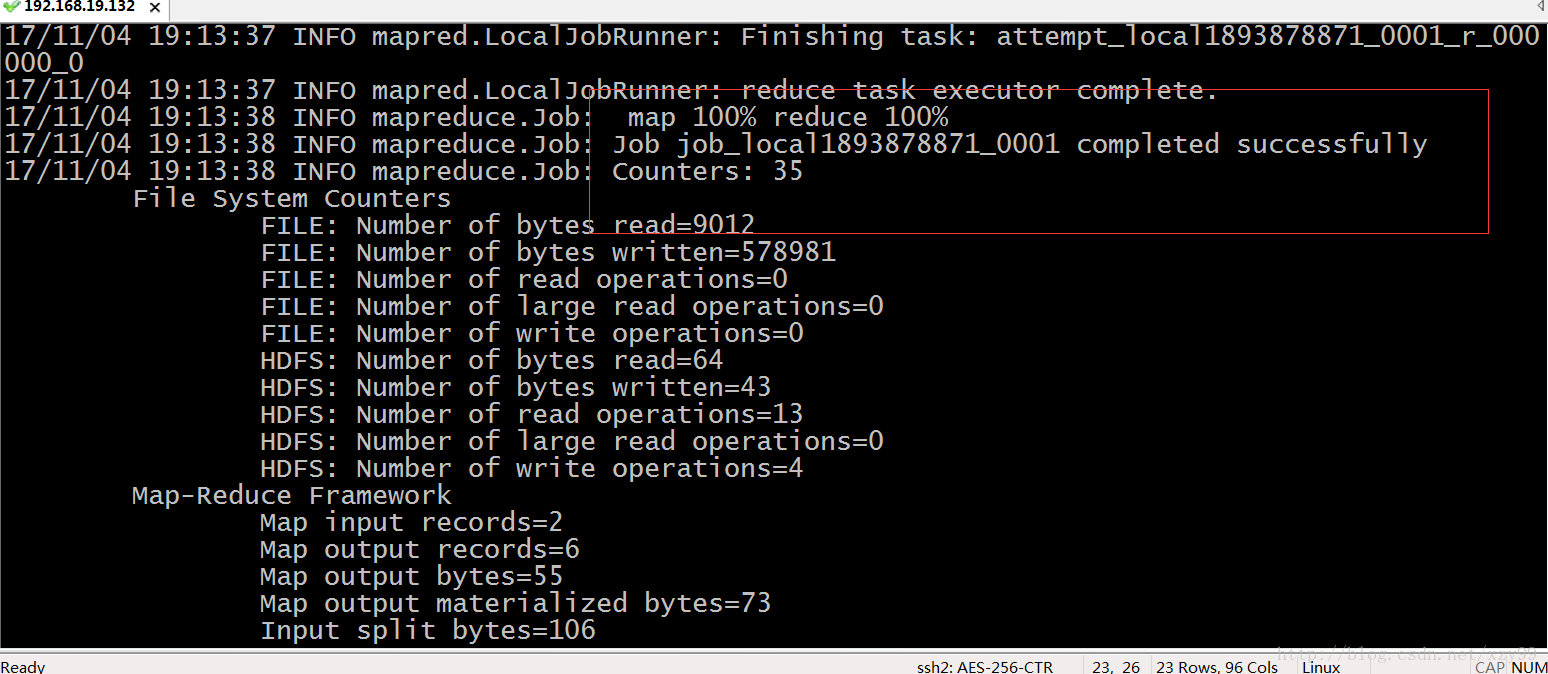
6.运行成功后,查看对应的文件目录下的文件(也可以通过访问http://Master:50070 ,跳转到hadoop的管理页面查看)

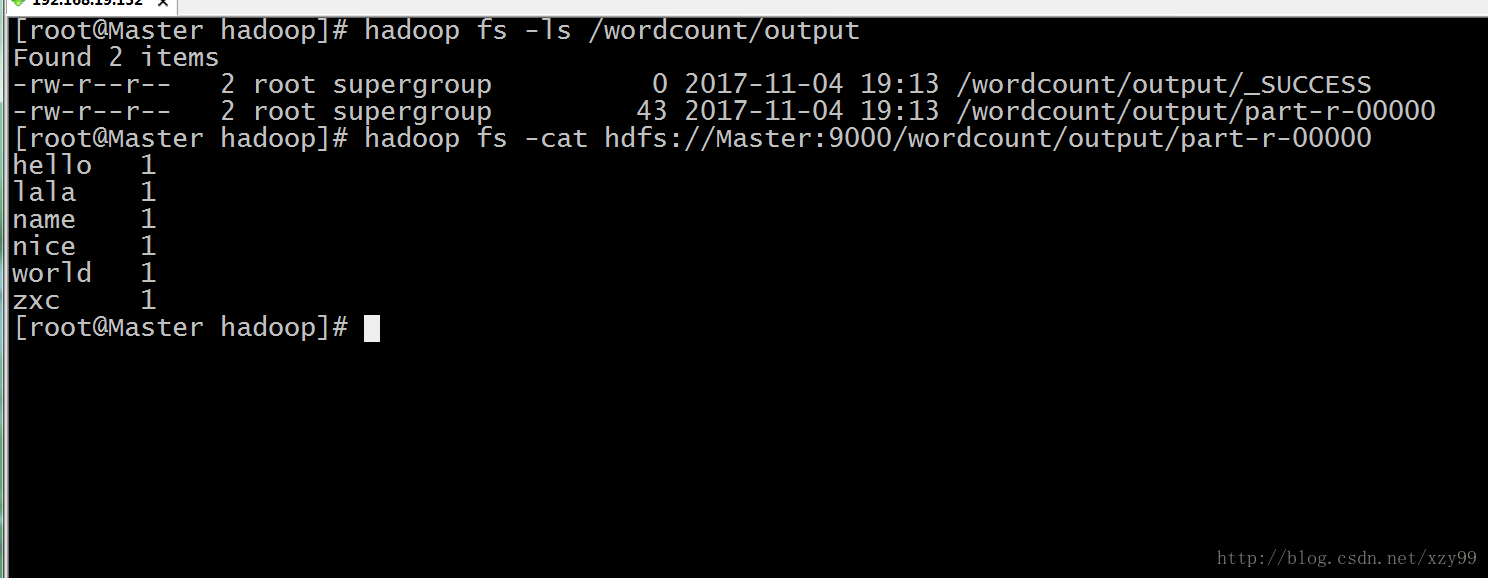
1. 通过hdfs命令查看
# hadoop fs -ls /wordcount/output # hadoop fs -cat hdfs://Master:9000/wordcount/output/part-r-00000
2. 通过网页下载查看
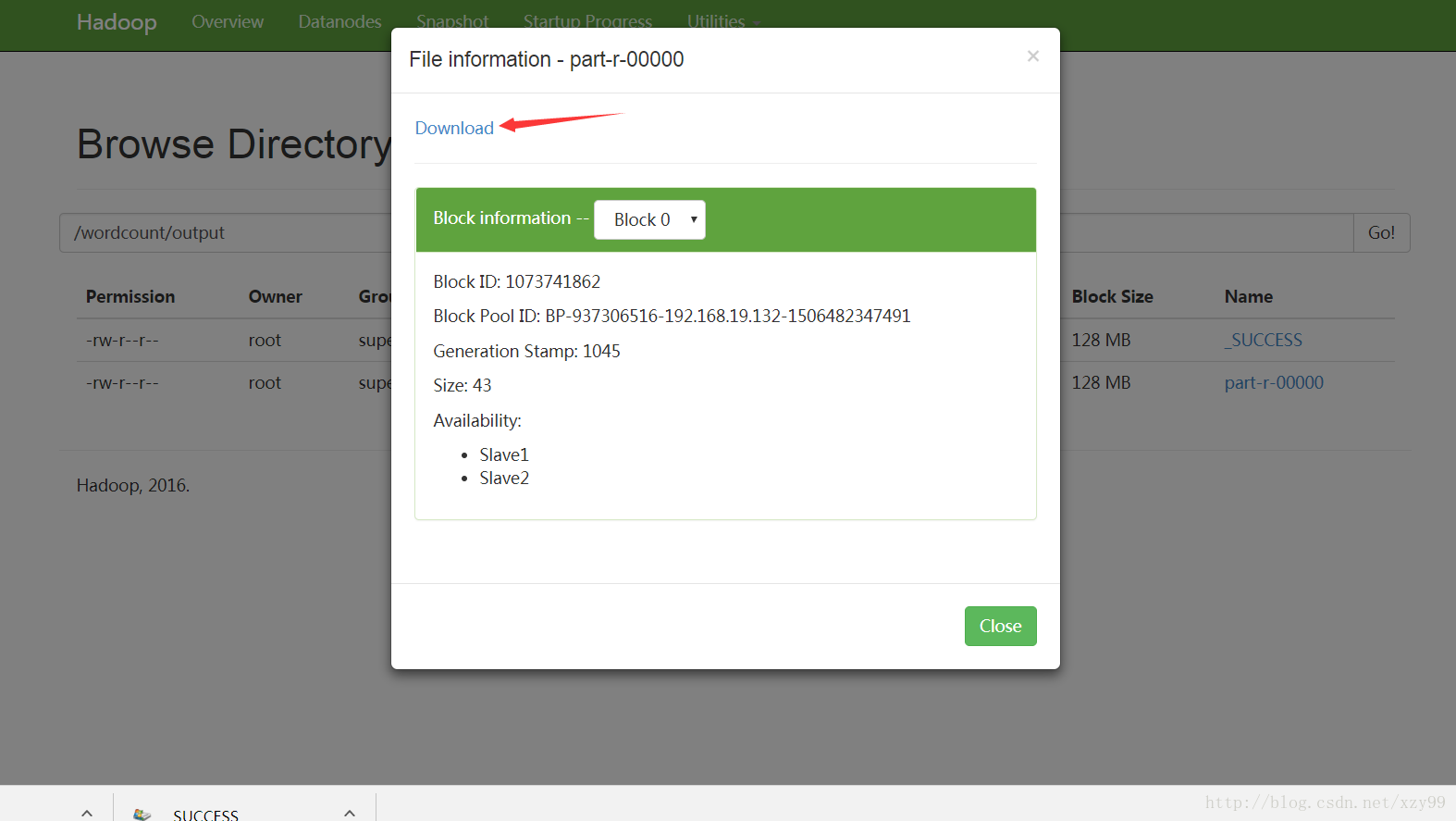
到此,我们的WordCount程序就成功完成了

相关文章推荐
- 1Linux下jdk、tomcat和apache2的安装配置
- linux 下安装配置TOMCAT
- linux安装配置jdk1.5、tomcat5.5、eclipse3.2
- linux下jdk安装和tomcat的自启动配置
- linux下的tomcat+jdk的安装配置
- linux 配置tomcat 5.5.20 日志(1)-admin包安装
- Linux上安装配置使用Tomcat说明文档和JDK环境变量配置
- linux jdk eclipse tomcat 安装及配置 (需要重新修改下此文章)
- linux 下jdk、tomcat的安装与配置
- Linux下Tomcat的安装配置
- CentOS Linux下安装和配置JDK与Tomcat
- linux下Nginx+tomcat整合的安装与配置
- Linux上java环境的搭建,JDK和TOMCAT的安装和配置
- Linux下配置Java环境及Tomcat安装(图文)
- linux安装配置jdk1.5、tomcat5.5、eclipse3.2详解
- linux安装配置jdk1.5、tomcat5.5、eclipse3.2详解
- linux下jdk,tomcat的安装和配置
- Linux环境下Eclipse和Tomcat的安装和配置
- linux下jdk的安装及环境变量的配置和tomcat的安装和配置步骤
- Redhat Enterprise Linux 5 实战系列(三)为RHEL5安装JDK和配置tomcat