Python爬虫框架Scrapy学习一记——认识Scrapy
2017-07-23 12:17
423 查看
Preface
(Preface不知道啥意思?!总认识里面那张脸吧,前+脸,恩,没错,前脸的意思)
同志既然你能找到这里说明你起码知道Python,知道Python的Scrapy框架,但是你是否了解,并且知道用法呢?如果不了解,我带着你咱们走!申明:本系列博客成份包含官网重要且常用部分的翻译、本人的实践示例与戳图、还有就是李白的唐诗三百首。好了,我们真的要走了!

1. Scrapy简介(Scrapy at a glance)
相关可参考文档github文档
scrapy org文档
[github代码仓库地址](https://github.com/scrapy/scrapy)
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的开源应用框架。 其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。 Scrapy吸引人的地方在于它是一个框架,任何人都可以根据需求方便的修改。它也提供了多种类型爬虫的基类,如BaseSpider、sitemap爬虫等,最新版本又提供了web2.0爬虫的支持。
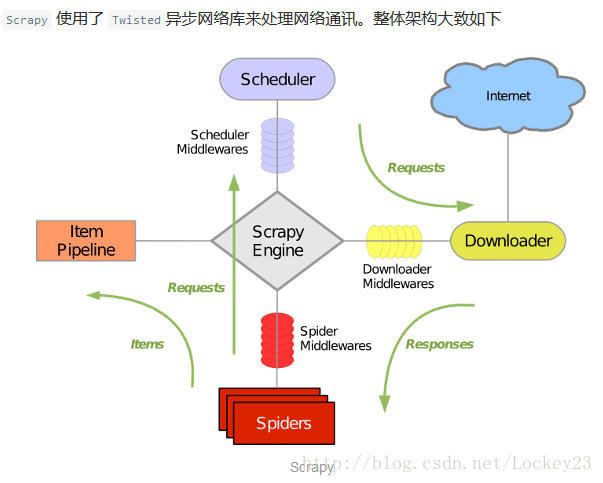
2.Scrapy主要组件:
引擎(Scrapy): 用来处理整个系统的数据流处理, 触发事务(框架核心)调度器(Scheduler): 用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址
下载器(Downloader): 用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的)
爬虫(Spiders): 爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面
项目管道(Pipeline): 负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
下载器中间件(Downloader Middlewares): 位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。
爬虫中间件(Spider Middlewares): 介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出。
调度中间件(Scheduler Middewares): 介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
3.Scrapy运行流程大概如下:
首先,引擎从调度器中取出一个链接(URL)用于接下来的抓取引擎把URL封装成一个请求(Request)传给下载器,下载器把资源下载下来,并封装成应答包(Response)
然后,爬虫解析Response
若是解析出实体(Item),则交给实体管道进行进一步的处理。
若是解析出的是链接(URL),则把URL交给Scheduler等待抓取
4. Scrapy提供的特性
HTML, XML源数据 选择及提取 的内置支持提供了一系列在spider之间共享的可复用的过滤器(即 Item Loaders),对智能处理爬取数据提供了内置支持。
通过 feed导出 提供了多格式(JSON、CSV、XML),多存储后端(FTP、S3、本地文件系统)的内置支持
提供了media pipeline,可以 自动下载 爬取到的数据中的图片(或者其他资源)。
高扩展性。您可以通过使用 signals ,设计好的API(中间件, extensions, pipelines)来定制实现您的功能。
内置的中间件及扩展为下列功能提供了支持:
cookies and session 处理
HTTP 压缩
HTTP 认证
HTTP 缓存
user-agent模拟
robots.txt
爬取深度限制
。。。
针对非英语语系中不标准或者错误的编码声明, 提供了自动检测以及健壮的编码支持。
支持根据模板生成爬虫。在加速爬虫创建的同时,保持在大型项目中的代码更为一致。详细内容请参阅 genspider 命令。
针对多爬虫下性能评估、失败检测,提供了可扩展的 状态收集工具 。
提供 交互式shell终端 , 为您测试XPath表达式,编写和调试爬虫提供了极大的方便
提供 System service, 简化在生产环境的部署及运行
内置 Web service, 使您可以监视及控制您的机器
内置 Telnet终端 ,通过在Scrapy进程中钩入Python终端,使您可以查看并且调试爬虫
Logging 为您在爬取过程中捕捉错误提供了方便
支持 Sitemaps 爬取
具有缓存的DNS解析器
the end
什么?这就完了?!
要想和我没完那你先回答4个问题
1.Scrapy是什么? 2.Scrapy主要组件包含哪些,各自有什么功能? 3.Scrapy运行流程是什么样的? 4.Scrapy提供了哪些特性?
好好思考一下我们进入下一节的环境安装配置
注:本文内容不完全为原创,如有雷同,算我抄你的

相关文章推荐
- Python爬虫框架Scrapy 学习笔记 10.2 -------【实战】 抓取天猫某网店所有宝贝详情
- Python的爬虫程序编写框架Scrapy入门学习教程
- python爬虫框架scrapy学习笔记
- python爬虫框架scrapy学习笔记
- 学习python 中的scrapy爬虫框架艰辛路,不推荐看,主要纪录自己学习笔记的
- Python爬虫框架Scrapy 学习笔记 4 ------- 第二个Scrapy项目
- Python爬虫框架Scrapy 学习笔记 10.2 -------【实战】 抓取天猫某网店所有宝贝详情
- Python爬虫框架Scrapy 学习笔记 10.3 -------【实战】 抓取天猫某网店所有宝贝详情
- Python学习(8)---Scrapy框架下的网络爬虫
- Python爬虫框架Scrapy 学习笔记 5 ------- 使用pipelines过滤敏感词
- Python爬虫框架Scrapy 学习笔记 10.1 -------【实战】 抓取天猫某网店所有宝贝详情
- Python网络爬虫框架scrapy的学习
- 小猪的Python学习之旅 —— 4.Scrapy爬虫框架初体验
- Python的Scrapy爬虫框架简单学习笔记
- 【Python学习系列五】Python网络爬虫框架Scrapy环境搭建
- python爬虫框架scrapy学习图片下载
- python 爬虫 学习笔记(一)Scrapy框架入门
- python爬虫 scrapy框架学习
- Python爬虫框架Scrapy学习二记——Scrapy开发环境配置
- python爬虫框架scrapy学习之CrawlSpider