【编译原理】(2)上下文无关文法
2017-07-23 11:31
288 查看
1.基本概念
1.文法是描述语言的语法结构的形式规则(文法规则)
2.上下文无关文法
这种问法所定义的语法2范畴(语法单位)是完全独立于这种范畴可能出现的环境
(1)不适合描述任何的自然语言
(2)对程序语言是足够描述的
例:
<句子>=><主语><谓语><间接宾语><直接宾语>
He gives me a book
生成的语法树如下
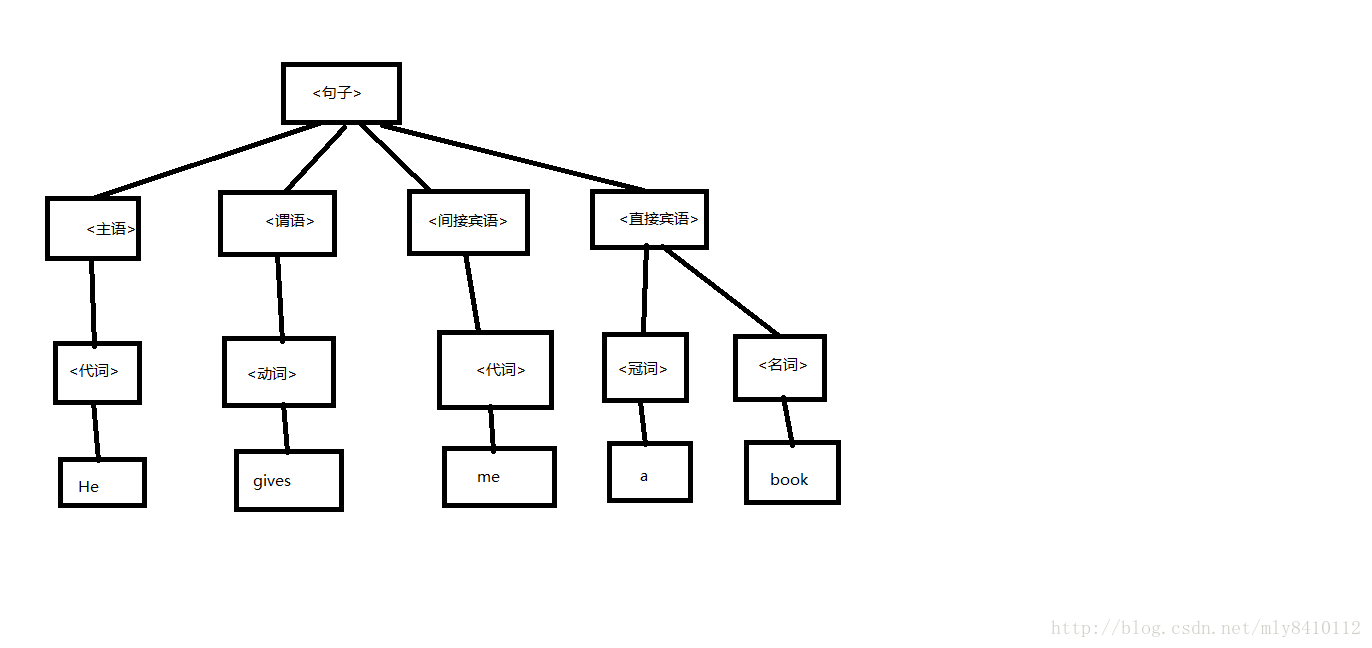
归纳:一个上下文无关文法的组成部分如下
(1).终结符:是语言的基本符号
1.在程序语言里,单词符号,基本字,标识符,常数,算符和界符等。
2.从语法分析的角度,终结符号是一个语言的不可再分的基本符号。
(2).非终结符:又称为语法变量,用来代表语法范畴
1.一个非终结符代表一个一定的语法概念
2.一个非终结符是一个类(或集合)的记号
3.一个非终结符表示一定符号串的集合,由终结符号和非终结符号组成的符号串
(3).开始符号:是一个特殊的非终结符号,它代表所定义的语言中我们最感兴趣的语法范畴这个语法范畴通常称为“句子”。
(4).文法规则(产生式):A→α
左部符号A:是一个非终结符号
右部符号α:是由终结符号或与非终结符号组成的一个符号串。
2.形式化描述上下文无关文法
上下文无关的文法是一个四元式:(VT,VN,S,P)其中:(1)VT 是一个非空有限集合,其中的每个元素称为终结符号。
(2)VN 是一个非空有限集合,其中的每个元素为非终结符号。
(3)S是一个非终结符号,称为开始符号。
(4)P是一个产生式的有限集合
P∈VN,α∈(VN∪VN),开始符号S必须在某个产生式的左边出现一次。
3.用上下文无关文法定义定义语言
基本思想:从文法的开始符号触发,反复连续使用产生式,对非终结符号进行替换和展开文法G: E→E+E | E * E | (E) | i
1.E→E+E
2.E→E*E
3.E→(E)
4.E→i
根据规则
E=>(E)
=>(E+E)
=>(i+E)
=>(i+i)
称这样一串替换序列是从E推出(i+i)的一个推导。
若G是一个文法,则α是它的一个句型,仅含有终结符号的句型是一个句子。
文法G产生句子的全体是一个语言,将它记为L(G):
L(G)={α|S=> * α&α∈VT * }
来一个例子吧:
已知有文法G[S]:S→bA; A→aA|a 确定文法所定义的语言
从符号S可以推出
S=>bA=>ba;
S=>bA=>baA=>baa;
S=>bA=>baaA=>baaa;
…
S=>bA=>baaA=>…=>ba…a
归纳出从S可以推导出所有以b开头的后面跟一个或任意多个a的字符串,即
L(G)={ban|n>=1}

相关文章推荐
- 编译原理学习周入门教程--(5)上下文无关文法,及其语法树
- [系列][编译原理]上下文无关文法及分析
- 编译原理-上下文无关文法
- 自然语言 和编译原理中的(1型文法)上下文有关文法和(2型文法)上下文无关文法CFG
- 编译原理:上下文无关语法简介
- 软件设计师必备——编译原理·文法
- 编译原理之文法一
- 编译原理学习笔记——第二章:语言及其文法
- 编译原理(2) 文法 有限自动机 正规式
- 编译原理之正规文法和正规式
- 编译原理之文法(一)
- 【软考】(一)编译原理-文法
- 自动机、正则式、正则文法和上下文无关文法
- 从上下文无关文法(CFG)到语法分析树——SLR(1)分析法
- 文法G[E]分析表分析字符串(i+)-编译原理
- 编译原理(三) 消除文法的左递归
- 编译原理——文法的化简与改造(附源代码)
- 自己动手开发编译器(六)上下文无关语言和文法
- 【软考】(一)编译原理-文法
- 文法系列之从上下文无关语法到转换语法