Deep Learning in NLP (一)词向量和语言模型
2017-07-23 08:07
441 查看
Deep Learning in NLP (一)词向量和语言模型
2013 年 7 月 29 日 BY LICSTAR·295条评论这篇博客是我看了半年的论文后,自己对 Deep Learning 在 NLP 领域中应用的理解和总结,在此分享。其中必然有局限性,欢迎各种交流,随便拍。
Deep Learning 算法已经在图像和音频领域取得了惊人的成果,但是在 NLP 领域中尚未见到如此激动人心的结果。关于这个原因,引一条我比较赞同的微博。
@王威廉:Steve Renals算了一下icassp录取文章题目中包含deep learning的数量,发现有44篇,而naacl则有0篇。有一种说法是,语言(词、句子、篇章等)属于人类认知过程中产生的高层认知抽象实体,而语音和图像属于较为底层的原始输入信号,所以后两者更适合做deep
learning来学习特征。
2013年3月4日 14:46
第一句就先不用管了,毕竟今年的 ACL 已经被灌了好多 Deep Learning 的论文了。第二句我很认同,不过我也有信心以后一定有人能挖掘出语言这种高层次抽象中的本质。不论最后这种方法是不是 Deep Learning,就目前而言,Deep Learning 在 NLP 领域中的研究已经将高深莫测的人类语言撕开了一层神秘的面纱。
我觉得其中最有趣也是最基本的,就是“词向量”了。
将词用“词向量”的方式表示可谓是将 Deep Learning 算法引入 NLP 领域的一个核心技术。大多数宣称用了 Deep Learning 的论文,其中往往也用了词向量。
本文目录:
0. 词向量是什么
1. 词向量的来历
2. 词向量的训练
2.0 语言模型简介
2.1 Bengio 的经典之作
2.2 C&W 的 SENNA
2.3 M&H 的 HLBL
2.4 Mikolov 的 RNNLM
2.5 Huang 的语义强化
2.999 总结
3. 词向量的评价
3.1 提升现有系统
3.2 语言学评价
参考文献
0. 词向量是什么
自然语言理解的问题要转化为机器学习的问题,第一步肯定是要找一种方法把这些符号数学化。NLP 中最直观,也是到目前为止最常用的词表示方法是 One-hot Representation,这种方法把每个词表示为一个很长的向量。这个向量的维度是词表大小,其中绝大多数元素为 0,只有一个维度的值为 1,这个维度就代表了当前的词。
举个栗子,
“话筒”表示为 [0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 …]
“麦克”表示为 [0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 …]
每个词都是茫茫 0 海中的一个 1。
这种 One-hot Representation 如果采用稀疏方式存储,会是非常的简洁:也就是给每个词分配一个数字 ID。比如刚才的例子中,话筒记为 3,麦克记为 8(假设从 0 开始记)。如果要编程实现的话,用 Hash 表给每个词分配一个编号就可以了。这么简洁的表示方法配合上最大熵、SVM、CRF 等等算法已经很好地完成了 NLP 领域的各种主流任务。
当然这种表示方法也存在一个重要的问题就是“词汇鸿沟”现象:任意两个词之间都是孤立的。光从这两个向量中看不出两个词是否有关系,哪怕是话筒和麦克这样的同义词也不能幸免于难。
Deep Learning 中一般用到的词向量并不是刚才提到的用 One-hot Representation 表示的那种很长很长的词向量,而是用 Distributed Representation(不知道这个应该怎么翻译,因为还存在一种叫“Distributional Representation”的表示方法,又是另一个不同的概念)表示的一种低维实数向量。这种向量一般长成这个样子:[0.792,
−0.177, −0.107, 0.109, −0.542, …]。维度以 50 维和 100 维比较常见。这种向量的表示不是唯一的,后文会提到目前计算出这种向量的主流方法。
(个人认为)Distributed representation 最大的贡献就是让相关或者相似的词,在距离上更接近了。向量的距离可以用最传统的欧氏距离来衡量,也可以用 cos 夹角来衡量。用这种方式表示的向量,“麦克”和“话筒”的距离会远远小于“麦克”和“天气”。可能理想情况下“麦克”和“话筒”的表示应该是完全一样的,但是由于有些人会把英文名“迈克”也写成“麦克”,导致“麦克”一词带上了一些人名的语义,因此不会和“话筒”完全一致。
1. 词向量的来历
Distributed representation 最早是 Hinton 在 1986 年的论文《Learning distributed representations of concepts》中提出的。虽然这篇文章没有说要将词做 Distributed representation,(甚至我很无厘头地猜想那篇文章是为了给他刚提出的 BP 网络打广告,)但至少这种先进的思想在那个时候就在人们的心中埋下了火种,到2000 年之后开始逐渐被人重视。
Distributed representation 用来表示词,通常被称为“Word Representation”或“Word Embedding”,中文俗称“词向量”。真的只能叫“俗称”,算不上翻译。半年前我本想翻译的,但是硬是想不出 Embedding 应该怎么翻译的,后来就这么叫习惯了-_-||| 如果有好的翻译欢迎提出。(更新:@南大周志华 在这篇微博中给了一个合适的翻译:词嵌入)Embedding
一词的意义可以参考维基百科的相应页面(链接)。后文提到的所有“词向量”都是指用 Distributed Representation 表示的词向量。
如果用传统的稀疏表示法表示词,在解决某些任务的时候(比如构建语言模型)会造成维数灾难[Bengio 2003]。使用低维的词向量就没这样的问题。同时从实践上看,高维的特征如果要套用 Deep Learning,其复杂度几乎是难以接受的,因此低维的词向量在这里也饱受追捧。
同时如上一节提到的,相似词的词向量距离相近,这就让基于词向量设计的一些模型自带平滑功能,让模型看起来非常的漂亮。
2. 词向量的训练
要介绍词向量是怎么训练得到的,就不得不提到语言模型。到目前为止我了解到的所有训练方法都是在训练语言模型的同时,顺便得到词向量的。这也比较容易理解,要从一段无标注的自然文本中学习出一些东西,无非就是统计出词频、词的共现、词的搭配之类的信息。而要从自然文本中统计并建立一个语言模型,无疑是要求最为精确的一个任务(也不排除以后有人创造出更好更有用的方法)。既然构建语言模型这一任务要求这么高,其中必然也需要对语言进行更精细的统计和分析,同时也会需要更好的模型,更大的数据来支撑。目前最好的词向量都来自于此,也就不难理解了。
这里介绍的工作均为从大量未标注的普通文本数据中无监督地学习出词向量(语言模型本来就是基于这个想法而来的),可以猜测,如果用上了有标注的语料,训练词向量的方法肯定会更多。不过视目前的语料规模,还是使用未标注语料的方法靠谱一些。
词向量的训练最经典的有 3 个工作,C&W 2008、M&H 2008、Mikolov 2010。当然在说这些工作之前,不得不介绍一下这一系列中 Bengio 的经典之作。
2.0 语言模型简介
插段广告,简单介绍一下语言模型,知道的可以无视这节。语言模型其实就是看一句话是不是正常人说出来的。这玩意很有用,比如机器翻译、语音识别得到若干候选之后,可以利用语言模型挑一个尽量靠谱的结果。在 NLP 的其它任务里也都能用到。
语言模型形式化的描述就是给定一个字符串,看它是自然语言的概率 P(w1,w2,…,wt)P(w1,w2,…,wt)。w1w1 到 wtwt 依次表示这句话中的各个词。有个很简单的推论是:
P(w1,w2,…,wt)=P(w1)×P(w2|w1)×P(w3|w1,w2)×…×P(wt|w1,w2,…,wt−1)P(w1,w2,…,wt)=P(w1)×P(w2|w1)×P(w3|w1,w2)×…×P(wt|w1,w2,…,wt−1)
常用的语言模型都是在近似地求 P(wt|w1,w2,…,wt−1)P(wt|w1,w2,…,wt−1)。比如
n-gram 模型就是用 P(wt|wt−n+1,…,wt−1)P(wt|wt−n+1,…,wt−1) 近似表示前者。
顺便提一句,由于后面要介绍的每篇论文使用的符号差异太大,本博文里尝试统一使用 Bengio 2003 的符号系统(略做简化),以便在各方法之间做对比和分析。
2.1 Bengio 的经典之作
用神经网络训练语言模型的思想最早由百度 IDL 的徐伟于 2000 提出。(感谢 @余凯_西二旗民工 博士指出。)其论文《CanArtificial Neural Networks Learn Language Models?》提出一种用神经网络构建二元语言模型(即 P(wt|wt−1)P(wt|wt−1))的方法。文中的基本思路与后续的语言模型的差别已经不大了。
训练语言模型的最经典之作,要数 Bengio 等人在 2001 年发表在 NIPS 上的文章《A Neural Probabilistic Language Model》。当然现在看的话,肯定是要看他在 2003 年投到 JMLR 上的同名论文了。
Bengio 用了一个三层的神经网络来构建语言模型,同样也是 n-gram 模型。如图1。
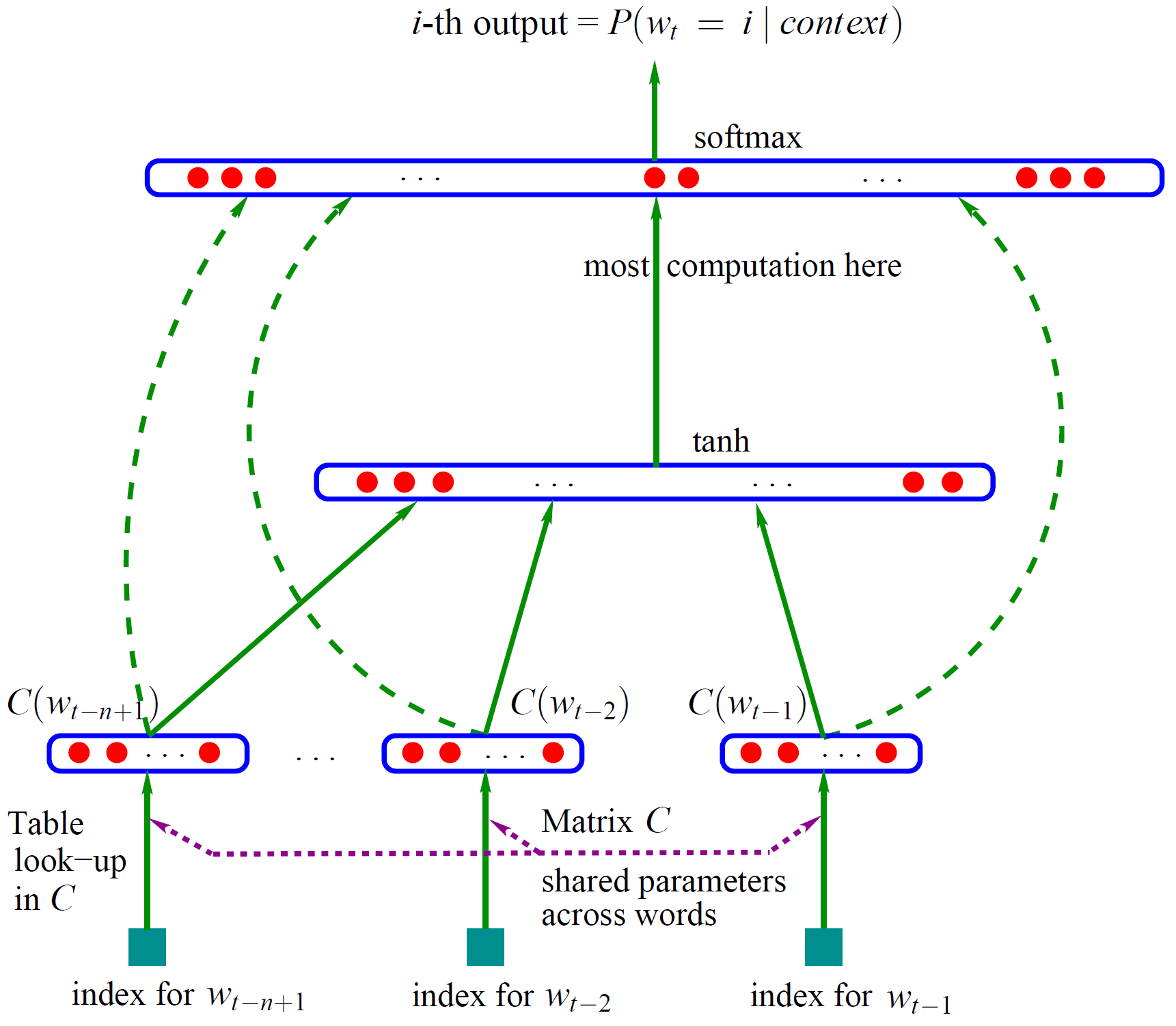
图1(点击查看大图)
图中最下方的 wt−n+1,…,wt−2,wt−1wt−n+1,…,wt−2,wt−1 就是前 n−1n−1 个词。现在需要根据这已知的 n−1n−1 个词预测下一个词 wtwt。C(w)C(w) 表示词 ww 所对应的词向量,整个模型中使用的是一套唯一的词向量,存在矩阵 CC(一个 |V|×m|V|×m 的矩阵)中。其中 |V||V| 表示词表的大小(语料中的总词数),mm 表示词向量的维度。ww 到 C(w)C(w) 的转化就是从矩阵中取出一行。
网络的第一层(输入层)是将 C(wt−n+1),…,C(wt−2),C(wt−1)C(wt−n+1),…,C(wt−2),C(wt−1) 这 n−1n−1 个向量首尾相接拼起来,形成一个 (n−1)m(n−1)m 维的向量,下面记为 xx。
网络的第二层(隐藏层)就如同普通的神经网络,直接使用 d+Hxd+Hx 计算得到。dd 是一个偏置项。在此之后,使用 tanhtanh 作为激活函数。
网络的第三层(输出层)一共有 |V||V| 个节点,每个节点 yiyi 表示
下一个词为 ii 的未归一化
log 概率。最后使用 softmax 激活函数将输出值 yy 归一化成概率。最终,yy 的计算公式为:
y=b+Wx+Utanh(d+Hx)y=b+Wx+Utanh(d+Hx)
式子中的 UU(一个 |V|×h|V|×h 的矩阵)是隐藏层到输出层的参数,整个模型的多数计算集中在 UU 和隐藏层的矩阵乘法中。后文的提到的
3 个工作,都有对这一环节的简化,提升计算的速度。
式子中还有一个矩阵 WW(|V|×(n−1)m|V|×(n−1)m),这个矩阵包含了从输入层到输出层的直连边。直连边就是从输入层直接到输出层的一个线性变换,好像也是神经网络中的一种常用技巧(没有仔细考察过)。如果不需要直连边的话,将 WW 置为
0 就可以了。在最后的实验中,Bengio 发现直连边虽然不能提升模型效果,但是可以少一半的迭代次数。同时他也猜想如果没有直连边,可能可以生成更好的词向量。
现在万事俱备,用随机梯度下降法把这个模型优化出来就可以了。需要注意的是,一般神经网络的输入层只是一个输入值,而在这里,输入层 xx 也是参数(存在 CC 中),也是需要优化的。优化结束之后,词向量有了,语言模型也有了。
这样得到的语言模型自带平滑,无需传统 n-gram 模型中那些复杂的平滑算法。Bengio 在 APNews 数据集上做的对比实验也表明他的模型效果比精心设计平滑算法的普通 n-gram 算法要好 10% 到 20%。
在结束介绍 Bengio 大牛的经典作品之前再插一段八卦。在其 JMLR 论文中的未来工作一段,他提了一个能量函数,把输入向量和输出向量统一考虑,并以最小化能量函数为目标进行优化。后来 M&H 工作就是以此为基础展开的。
他提到一词多义有待解决,9 年之后 Huang 提出了一种解决方案。他还在论文中随口(不是在 Future Work 中写的)提到:可以使用一些方法降低参数个数,比如用循环神经网络。后来 Mikolov 就顺着这个方向发表了一大堆论文,直到博士毕业。
大牛就是大牛。
2.2 C&W 的 SENNA
Ronan Collobert 和 Jason Weston 在 2008 年的 ICML 上发表的《A Unified Architecture for Natural Language Processing: Deep Neural Networks with Multitask Learning》里面首次介绍了他们提出的词向量的计算方法。和上一篇牛文类似,如果现在要看的话,应该去看他们在 2011 年投到 JMLR上的论文《Natural Language Processing (Almost) from Scratch》。文中总结了他们的多项工作,非常有系统性。这篇 JMLR 的论文题目也很霸气啊:从头开始搞 NLP。他们还把论文所写的系统开源了,叫做 SENNA(主页链接),3500
多行纯 C 代码也是写得非常清晰。我就是靠着这份代码才慢慢看懂这篇论文的。可惜的是,代码只有测试部分,没有训练部分。
实际上 C&W 这篇论文主要目的并不是在于生成一份好的词向量,甚至不想训练语言模型,而是要用这份词向量去完成 NLP 里面的各种任务,比如词性标注、命名实体识别、短语识别、语义角色标注等等。
由于目的的不同,C&W 的词向量训练方法在我看来也是最特别的。他们没有去近似地求 P(wt|w1,w2,…,wt−1)P(wt|w1,w2,…,wt−1),而是直接去尝试近似 P(w1,w2,…,wt)P(w1,w2,…,wt)。在实际操作中,他们并没有去求一个字符串的概率,而是求窗口连续 nn 个词的打分 f(wt−n+1,…,wt−1,wt)f(wt−n+1,…,wt−1,wt)。打分 ff 越高的说明这句话越是正常的话;打分低的说明这句话不是太合理;如果是随机把几个词堆积在一起,那肯定是负分(差评)。打分只有相对高低之分,并没有概率的特性。
有了这个对 ff 的假设,C&W
就直接使用 pair-wise 的方法训练词向量。具体的来说,就是最小化下面的目标函数。
∑x∈

相关文章推荐
- Deep Learning in NLP (一)词向量和语言模型
- Deep Learning in NLP (一)词向量和语言模型
- Deep Learning in NLP (一)词向量和语言模型
- 【转载】Deep Learning in NLP (一)词向量和语言模型
- 词向量和语言模型 deep learning in NLP
- Deep Learning in NLP (一)词向量和语言模型
- Deep Learning in NLP (一)词向量和语言模型
- Deep Learning in NLP (一)词向量和语言模型
- Deep Learning in NLP (一)词向量和语言模型
- Deep Learning in NLP (一)词向量和语言模型
- Deep Learning in NLP (一)词向量和语言模型
- Deep Learning in NLP (一)词向量和语言模型
- Deep Learning in NLP (一)词向量和语言模型
- Deep Learning in NLP (一)词向量和语言模型
- Deep Learning in NLP (一)词向量和语言模型
- Deep Learning in NLP (一)词向量和语言模型
- Deep Learning in NLP (一)词向量和语言模型
- Deep Learning in NLP (一)词向量和语言模型
- Deep Learning in NLP (一)词向量和语言模型
- Deep Learning in NLP (一)词向量和语言模型