[置顶] flume高并发优化——(14)解决空行停止收集数据问题,及offsets变小问题
2017-07-21 15:42
246 查看
日志平台运行一段时间,发现日志有部分丢失,通过检查日志,发现有两个问题导致数据丢失,一个是遇到空行后,日志停止收集,还有就是kafka监控offsets时变小,通过分析代码,找到如下方法:
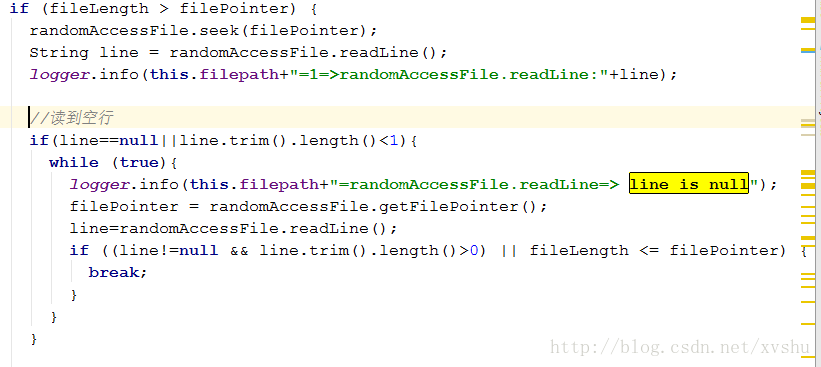
空行问题:
在系统稳定运行一段时间之后,发现了一个致命性的bug就是在遇到空行时,无法自动跳过,导致识别为文件结束,再次读取还是空行,跳入了死循环解决办法:
解决的办法也非常简单,就是增加对文件大小与当前行数的比较,两者相等则是到达文件末尾,否则继续读取下一行,直到文件末尾源码:
offsets变小问题:
我们发现,在大数据量的并发前提下,通过监控kafka,发现数据有重复收入的现象,而且非常严重解决办法:
观察一段时间,发现可能是flume-kafka-channel管理offsets的问题,果断进行源码分析,加入相关配置后,情况有所改善, 但是由于offsets是由flume管理,彻底解决这个问题,需要进一步修正代码。配置:
agent1.channels.c2.migrateZookeeperOffsets=true agent1.channels.c2.kafka.consumer.session.timeout.ms=100000 agent1.channels.c2.kafka.consumer.request.timeout.ms=110000 agent1.channels.c2.kafka.consumer.fetch.max.wait.ms=1000 agent1.channels.c2.zookeeperConnect=10.1.115.181:2181,10.1.114.221:2181,10.1.114.231:2181/kafka
总结:
flume在业界,是一款不错的管道工具,高并发下问题解决也比较迅速,源码结构简单,逻辑清晰,扩展和维护方便推荐各大公司使用。
相关文章推荐
- flume高并发优化——(14)解决空行停止收集数据问题,及offsets变小问题
- [置顶] flume高并发优化——(16)解决offsets变小问题
- [置顶] Win8.1慎用360优化,可能导致安装驱动出现数据无效的问题。附解决方法
- 设计模式的实际应用——在C#中解决单客户端窗口数据并发问题(2010-08-04)
- 收集数据能帮我们解决未来的问题,才叫大数据
- Asp.net MVC 2 中解决页面提交数据并发问题
- Win8.1慎用优化,可能导致安装驱动出现数据无效的问题。附解决方法
- 当web应用中面临大数据量同时并发量比较大的情况下性能是一个尤为重要的问题,面对性能优化我们应从何做起,在哪些方面做优化呢?
- 解决asp.net MVC 的数据访问并发问题。(已有打开的与此 Command 相关联的 Dat)
- 优化策略(并发、数据量大的问题)
- mysql性能优化(五) mysql中SELECT+UPDATE处理并发更新问题解决方案
- [置顶] flume高并发优化——(11)排除json转换及中文乱码
- 总结概括对于大数据、高并发的网站如何进行优化的问题
- [置顶] flume高并发优化——(10)消灭elasticsearch sink多次插入
- [置顶] 粒子群算法解决函数优化问题
- 设计模式的实际应用——在C#中解决单客户端窗口数据并发问题
- 设计模式的实际应用――在C#中解决单客户端窗口数据并发问题
- [置顶] 射频技术(串口+网口),解决:多串口,多设备,多指令,数据错包问题
- mysql 并发下数据不一致的问题分析及解决
- 设计模式的实际应用——在C#中解决单客户端窗口数据并发问题(2010-08-04)