Lucene5学习之FunctionQuery功能查询
2017-07-21 00:00
267 查看
我猜,大家最大的疑问就是:不是已经有那么多Query实现类吗,为什么又设计一个FunctionQuery,它的设计初衷是什么,或者说它是用来解决什么问题的?我们还是来看看源码里是怎么解释FunctionQuery的:
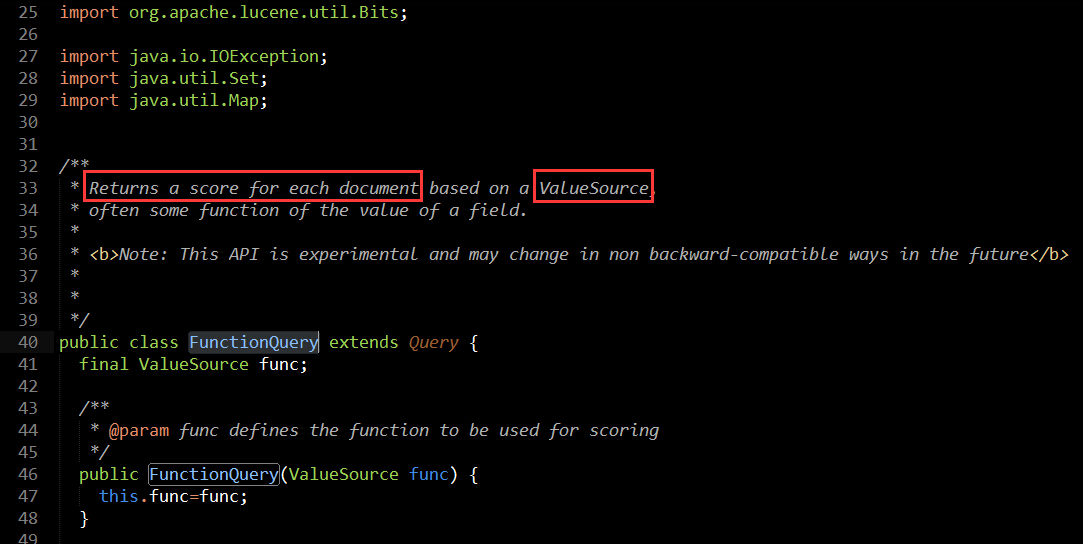
意思就是基于ValueSource来返回每个文档的评分即valueSourceScore,那ValueSource又是怎么东东?接着看看ValueSource源码里的注释说明:
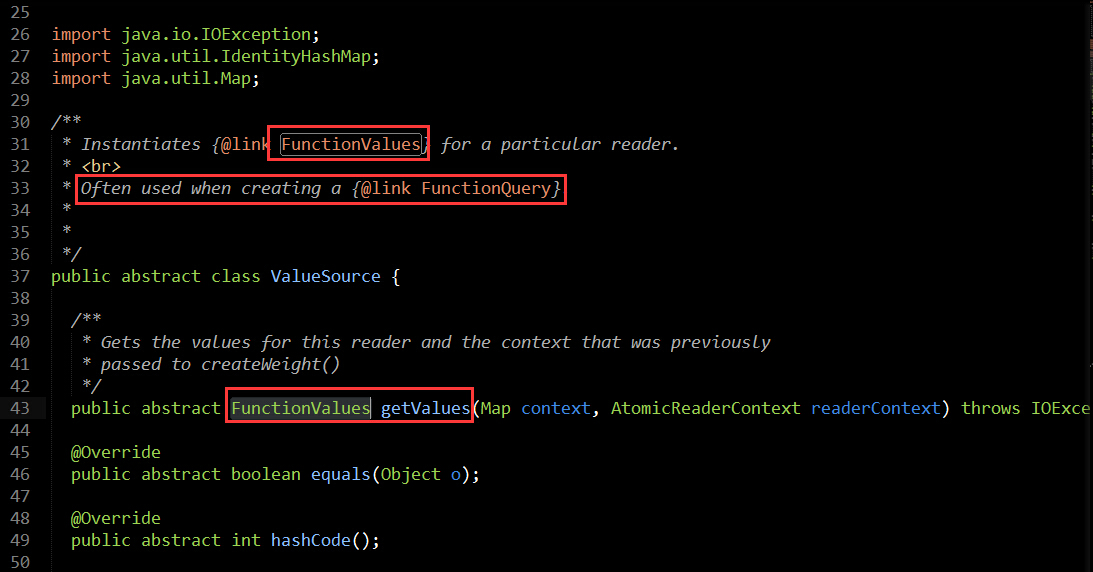
ValueSource是用来根据指定的IndexReader来实例化FunctionValues的,那FunctionValues又是啥?
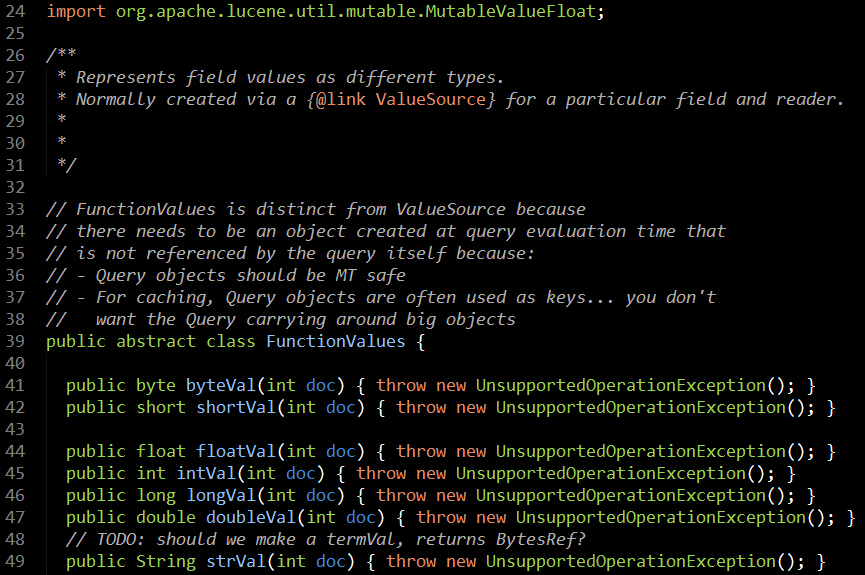
从接口中定义的函数可以了解到,FunctionValues提供了根据文档ID获取各种类型的DocValuesField域的值的方法,那这些接口返回的域值用来干嘛的,翻看FunctionQuery源码,你会发现:
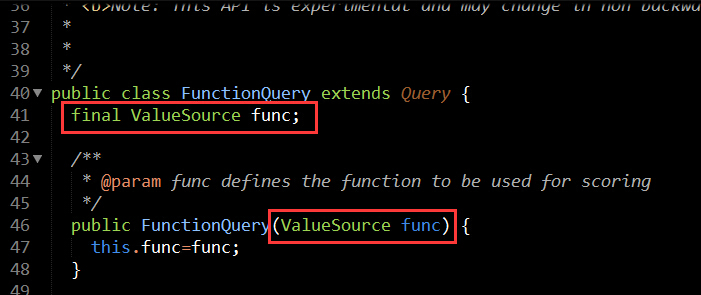
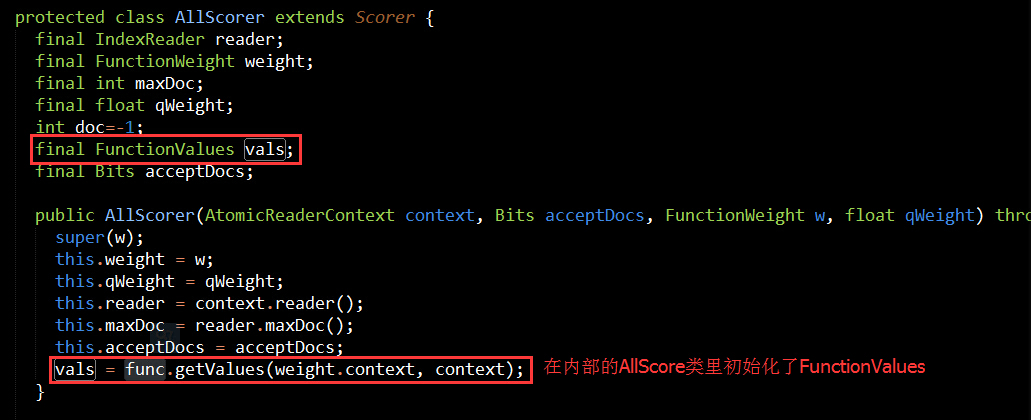
从上面几张图,我们会发现,FunctionQuery构造的时候需要提供一个ValueSource,然后在FunctionQuery的内部类AllScorer中通过valueSource实例化了FunctionValues,然后在计算FunctionQuery评分的时候通过FunctionValues获取DocValuesField的域值,域值和FunctionQuery的权重值相乘得到FunctionQuery的评分。
那这里ValueSource又起什么作用呢,为什么不直接让FunctionQuery来构建FunctionValues,而是要引入一个中间角色ValueSource呢?
因为FunctionQuery应该线程安全的,即允许多次查询共用同一个FunctionQuery实例,如果让FunctionValues直接依赖FunctionQuery,那可能会导致某个线程通过FunctionValues得到的docValuesField域值被另一个线程修改了,所以引入了一个ValuesSource,让每个FunctionQuery对应一个ValueSource,再让ValueSource去生成FunctionValues,因为docValuesField域值的正确性会影响到最后的评分。另外出于缓存原因,因为每次通过FunctionValues去加载docValuesField的域值,其实还是通过IndexReader去读取的,这就意味着有磁盘IO行为,磁盘IO次数可是程序性能杀手哦,所以设计CachingDoubleValueSource来包装ValueSource.不过CachingDoubleValueSource貌似还处在捐献模块,不知道下个版本是否会考虑为ValueSource添加Cache功能。
ValueSource构造很简单:
你只需要提供一个域的名称即可,不过要注意,这里的域必须是DocValuesField,不能是普通的StringField,TextField,IntField,FloatField,LongField。
那FunctionQuery可以用来解决什么问题?举个例子:比如你索引了N件商品,你希望通过某个关键字搜索时,出来的结果优先按最近上架的商品显示,再按商品和搜索关键字匹配度高低降序显示,即你希望最近上架的优先靠前显示,评分高的靠前显示。
下面是一个FunctionQuery使用示例,模拟类似这样的场景:
书籍的出版日期越久远,其权重因子会按天数一天天衰减,从而实现让新书自动靠前显示
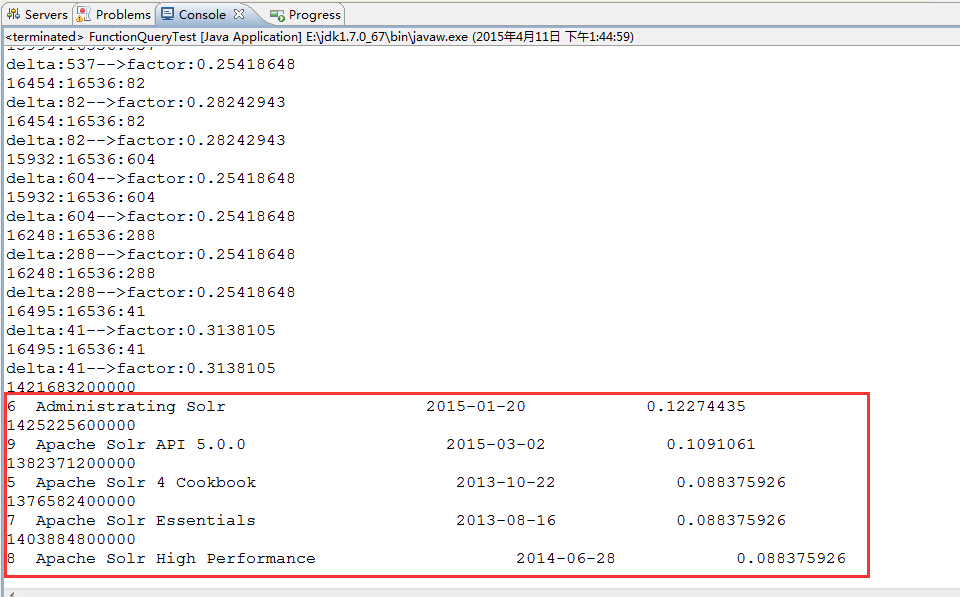
运行测试结果如图:
意思就是基于ValueSource来返回每个文档的评分即valueSourceScore,那ValueSource又是怎么东东?接着看看ValueSource源码里的注释说明:
ValueSource是用来根据指定的IndexReader来实例化FunctionValues的,那FunctionValues又是啥?
从接口中定义的函数可以了解到,FunctionValues提供了根据文档ID获取各种类型的DocValuesField域的值的方法,那这些接口返回的域值用来干嘛的,翻看FunctionQuery源码,你会发现:
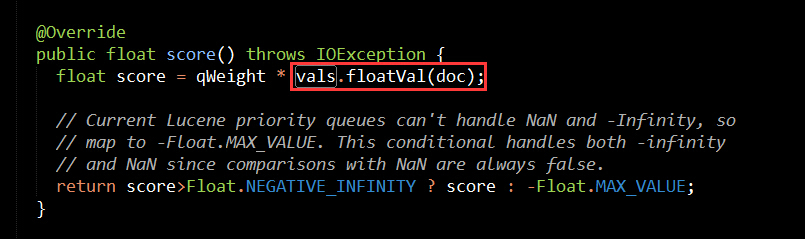
从上面几张图,我们会发现,FunctionQuery构造的时候需要提供一个ValueSource,然后在FunctionQuery的内部类AllScorer中通过valueSource实例化了FunctionValues,然后在计算FunctionQuery评分的时候通过FunctionValues获取DocValuesField的域值,域值和FunctionQuery的权重值相乘得到FunctionQuery的评分。
float score = qWeight * vals.floatVal(doc);
那这里ValueSource又起什么作用呢,为什么不直接让FunctionQuery来构建FunctionValues,而是要引入一个中间角色ValueSource呢?
因为FunctionQuery应该线程安全的,即允许多次查询共用同一个FunctionQuery实例,如果让FunctionValues直接依赖FunctionQuery,那可能会导致某个线程通过FunctionValues得到的docValuesField域值被另一个线程修改了,所以引入了一个ValuesSource,让每个FunctionQuery对应一个ValueSource,再让ValueSource去生成FunctionValues,因为docValuesField域值的正确性会影响到最后的评分。另外出于缓存原因,因为每次通过FunctionValues去加载docValuesField的域值,其实还是通过IndexReader去读取的,这就意味着有磁盘IO行为,磁盘IO次数可是程序性能杀手哦,所以设计CachingDoubleValueSource来包装ValueSource.不过CachingDoubleValueSource貌似还处在捐献模块,不知道下个版本是否会考虑为ValueSource添加Cache功能。
ValueSource构造很简单:
public DoubleFieldSource(String field) {
super(field);
}你只需要提供一个域的名称即可,不过要注意,这里的域必须是DocValuesField,不能是普通的StringField,TextField,IntField,FloatField,LongField。
那FunctionQuery可以用来解决什么问题?举个例子:比如你索引了N件商品,你希望通过某个关键字搜索时,出来的结果优先按最近上架的商品显示,再按商品和搜索关键字匹配度高低降序显示,即你希望最近上架的优先靠前显示,评分高的靠前显示。
下面是一个FunctionQuery使用示例,模拟类似这样的场景:
书籍的出版日期越久远,其权重因子会按天数一天天衰减,从而实现让新书自动靠前显示
import java.io.IOException;
import java.util.Map;
import org.apache.lucene.index.DocValues;
import org.apache.lucene.index.LeafReaderContext;
import org.apache.lucene.index.NumericDocValues;
import org.apache.lucene.queries.function.FunctionValues;
import org.apache.lucene.queries.function.valuesource.FieldCacheSource;
import com.yida.framework.lucene5.util.score.ScoreUtils;
/**
* 自定义ValueSource[计算日期递减时的权重因子,日期越近权重值越高]
* @author Lanxiaowei
*
*/
public class DateDampingValueSouce extends FieldCacheSource {
//当前时间
private static long now;
public DateDampingValueSouce(String field) {
super(field);
//初始化当前时间
now = System.currentTimeMillis();
}
/**
* 这里Map里存的是IndexSeacher,context.get("searcher");获取
*/
@Override
public FunctionValues getValues(Map context, LeafReaderContext leafReaderContext)
throws IOException {
final NumericDocValues numericDocValues = DocValues.getNumeric(leafReaderContext.reader(), field);
return new FunctionValues() {
@Override
public float floatVal(int doc) {
return ScoreUtils.getNewsScoreFactor(now, numericDocValues,doc);
}
@Override
public int intVal(int doc) {
return (int) ScoreUtils.getNewsScoreFactor(now, numericDocValues,doc);
}
@Override
public String toString(int doc) {
return description() + '=' + intVal(doc);
}
};
}
}import org.apache.lucene.index.NumericDocValues;
import com.yida.framework.lucene5.util.Constans;
/**
* 计算衰减因子[按天为单位]
* @author Lanxiaowei
*
*/
public class ScoreUtils {
/**存储衰减因子-按天为单位*/
private static float[] daysDampingFactor = new float[120];
/**降级阀值*/
private static float demoteboost = 0.9f;
static {
daysDampingFactor[0] = 1;
//第一周时权重降级处理
for (int i = 1; i < 7; i++) {
daysDampingFactor[i] = daysDampingFactor[i - 1] * demoteboost;
}
//第二周
for (int i = 7; i < 31; i++) {
daysDampingFactor[i] = daysDampingFactor[i / 7 * 7 - 1]
* demoteboost;
}
//第三周以后
for (int i = 31; i < daysDampingFactor.length; i++) {
daysDampingFactor[i] = daysDampingFactor[i / 31 * 31 - 1]
* demoteboost;
}
}
//根据相差天数获取当前的权重衰减因子
private static float dayDamping(int delta) {
float factor = delta < daysDampingFactor.length ? daysDampingFactor[delta]
: daysDampingFactor[daysDampingFactor.length - 1];
System.out.println("delta:" + delta + "-->" + "factor:" + factor);
return factor;
}
public static float getNewsScoreFactor(long now, NumericDocValues numericDocValues, int docId) {
long time = numericDocValues.get(docId);
float factor = 1;
int day = (int) (time / Constans.DAY_MILLIS);
int nowDay = (int) (now / Constans.DAY_MILLIS);
System.out.println(day + ":" + nowDay + ":" + (nowDay - day));
// 如果提供的日期比当前日期小,则计算相差天数,传入dayDamping计算日期衰减因子
if (day < nowDay) {
factor = dayDamping(nowDay - day);
} else if (day > nowDay) {
//如果提供的日期比当前日期还大即提供的是未来的日期
factor = Float.MIN_VALUE;
} else if (now - time <= Constans.HALF_HOUR_MILLIS && now >= time) {
//如果两者是同一天且提供的日期是过去半小时之内的,则权重因子乘以2
factor = 2;
}
return factor;
}
public static float getNewsScoreFactor(long now, long time) {
float factor = 1;
int day = (int) (time / Constans.DAY_MILLIS);
int nowDay = (int) (now / Constans.DAY_MILLIS);
// 如果提供的日期比当前日期小,则计算相差天数,传入dayDamping计算日期衰减因子
if (day < nowDay) {
factor = dayDamping(nowDay - day);
} else if (day > nowDay) {
//如果提供的日期比当前日期还大即提供的是未来的日期
factor = Float.MIN_VALUE;
} else if (now - time <= Constans.HALF_HOUR_MILLIS && now >= time) {
//如果两者是同一天且提供的日期是过去半小时之内的,则权重因子乘以2
factor = 2;
}
return factor;
}
public static float getNewsScoreFactor(long time) {
long now = System.currentTimeMillis();
return getNewsScoreFactor(now, time);
}
}import java.io.IOException;
import java.nio.file.Paths;
import java.text.DateFormat;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Date;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.Field.Store;
import org.apache.lucene.document.LongField;
import org.apache.lucene.document.NumericDocValuesField;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.IndexWriterConfig.OpenMode;
import org.apache.lucene.index.Term;
import org.apache.lucene.queries.CustomScoreQuery;
import org.apache.lucene.queries.function.FunctionQuery;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.Sort;
import org.apache.lucene.search.SortField;
import org.apache.lucene.search.TermQuery;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
/**
* FunctionQuery测试
* @author Lanxiaowei
*
*/
public class FunctionQueryTest {
private static final DateFormat formate = new SimpleDateFormat("yyyy-MM-dd");
public static void main(String[] args) throws Exception {
String indexDir = "C:/lucenedir-functionquery";
Directory directory = FSDirectory.open(Paths.get(indexDir));
//System.out.println(0.001953125f * 100000000 * 0.001953125f / 100000000);
//创建测试索引[注意:只用创建一次,第二次运行前请注释掉这行代码]
//createIndex(directory);
IndexReader reader = DirectoryReader.open(directory);
IndexSearcher searcher = new IndexSearcher(reader);
//创建一个普通的TermQuery
TermQuery termQuery = new TermQuery(new Term("title", "solr"));
//根据可以计算日期衰减因子的自定义ValueSource来创建FunctionQuery
FunctionQuery functionQuery = new FunctionQuery(new DateDampingValueSouce("publishDate"));
//自定义评分查询[CustomScoreQuery将普通Query和FunctionQuery组合在一起,至于两者的Query评分按什么算法计算得到最后得分,由用户自己去重写来干预评分]
//默认实现是把普通查询评分和FunctionQuery高级查询评分相乘求积得到最终得分,你可以自己重写默认的实现
CustomScoreQuery customScoreQuery = new CustomScoreQuery(termQuery, functionQuery);
//创建排序器[按评分降序排序]
Sort sort = new Sort(new SortField[] {SortField.FIELD_SCORE});
TopDocs topDocs = searcher.search(customScoreQuery, null, Integer.MAX_VALUE, sort,true,false);
ScoreDoc[] docs = topDocs.scoreDocs;
for (ScoreDoc scoreDoc : docs) {
int docID = scoreDoc.doc;
Document document = searcher.doc(docID);
String title = document.get("title");
String publishDateString = document.get("publishDate");
System.out.println(publishDateString);
long publishMills = Long.valueOf(publishDateString);
Date date = new Date(publishMills);
publishDateString = formate.format(date);
float score = scoreDoc.score;
System.out.println(docID + " " + title + " " +
publishDateString + " " + score);
}
reader.close();
directory.close();
}
/**
* 创建Document对象
* @param title 书名
* @param publishDateString 书籍出版日期
* @return
* @throws ParseException
*/
public static Document createDocument(String title,String publishDateString) throws ParseException {
Date publishDate = formate.parse(publishDateString);
Document doc = new Document();
doc.add(new TextField("title",title,Field.Store.YES));
doc.add(new LongField("publishDate", publishDate.getTime(),Store.YES));
doc.add(new NumericDocValuesField("publishDate", publishDate.getTime()));
return doc;
}
//创建测试索引
public static void createIndex(Directory directory) throws ParseException, IOException {
Analyzer analyzer = new StandardAnalyzer();
IndexWriterConfig indexWriterConfig = new IndexWriterConfig(analyzer);
indexWriterConfig.setOpenMode(OpenMode.CREATE_OR_APPEND);
IndexWriter writer = new IndexWriter(directory, indexWriterConfig);
//创建测试索引
Document doc1 = createDocument("Lucene in action 2th edition", "2010-05-05");
Document doc2 = createDocument("Lucene Progamming", "2008-07-11");
Document doc3 = createDocument("Lucene User Guide", "2014-11-24");
Document doc4 = createDocument("Lucene5 Cookbook", "2015-01-09");
Document doc5 = createDocument("Apache Lucene API 5.0.0", "2015-02-25");
Document doc6 = createDocument("Apache Solr 4 Cookbook", "2013-10-22");
Document doc7 = createDocument("Administrating Solr", "2015-01-20");
Document doc8 = createDocument("Apache Solr Essentials", "2013-08-16");
Document doc9 = createDocument("Apache Solr High Performance", "2014-06-28");
Document doc10 = createDocument("Apache Solr API 5.0.0", "2015-03-02");
writer.addDocument(doc1);
writer.addDocument(doc2);
writer.addDocument(doc3);
writer.addDocument(doc4);
writer.addDocument(doc5);
writer.addDocument(doc6);
writer.addDocument(doc7);
writer.addDocument(doc8);
writer.addDocument(doc9);
writer.addDocument(doc10);
writer.close();
}
}运行测试结果如图:

相关文章推荐
- mysql dba系统学习(9)slow query log慢查询日志功能
- 【lucene系列学习一】实现Lucene索引,查询以及中文分词功能
- 一步一步跟我学习lucene(19)---lucene增量更新和NRT(near-real-time)Query近实时查询
- 一步一步跟我学习lucene(19)---lucene增量更新和NRT(near-real-time)Query近实时查询
- mysql dba系统学习(8)查询日志文件功能 mysql dba系统学习(9)slow query log慢查询日志功能
- lucene-查询query->PhraseQuery多关键字的搜索
- lucene学习6-各种查询
- lucene利用BooleanQuery进行多个Query组合查询
- 学习python(4) 练习词典功能 查询增加删除更新
- lucene学习六:lucene全文检索与数据库查询的比较
- Lucene学习(四):查询语法详解
- 使用MySQL数据库的查询功能时,如何解决Invalid use of group function的问题
- 学习ASP.NET Core Razor 编程系列九——增加查询功能
- 一步一步跟我学习lucene(18)---lucene索引时join和查询时join使用示例
- Lucene5 学习笔记(2) —— 简单介绍 Lucene 搜索功能和索引的修改、删除
- CUBRID学习笔记 42 Hierarchical QuerySQL层级查询
- Lucene 查询(Query)子类
- Lucene学习总结之九:Lucene的查询对象(3)
- Spring Boot 整合 Elasticsearch,实现 function score query 权重分查询
- 菜鸟学习OGRE和天龙八部之十六: 网游视角跑图功能基本实现,包括人物,射线查询,鼠标decal等等