关于“熵”家族的那些事
2017-07-19 22:40
183 查看
关于"熵"家族的那些事
在信息论与概率统计学中,熵(entropy)是一个很重要的概念。在机器学习与特征工程中,熵的概念也用得很多。这里简单总结,权当笔记。0.熵
熵和概率十分相近,但又不同。概率是真实反映变化到某状态的确信度。而熵反映的是从某时刻到另一时刻的状态有多难以确定。阻碍生命的不是概率,而是熵。生命活着就是在减熵。
生命要在这个变化的世界中生存,它就需要知道如何根据环境变化做出相应的行动来避免毁灭。把不确定的环境转换成确定的行动。会将无序的事物重新整理到有序的状态。生物仅仅活着就需要减熵,否则就会被不确定性会消灭。熵增意味着信息量越来越巨大,生物必须能够压缩这些不确定的信息并记住信息是如何被压缩的。
压缩信息的方法就是知识。
实例:病毒会利用宿主的细胞系统进行自我复制将微粒重组为有序的状态。
实例:工蜂用自身的蜡腺所分泌的蜂蜡修筑蜂巢。
此种知识是仅当环境发生时才会采取对应行动,并不会改变太多环境。但有第二种知识。像人类这样的动物同时还可以学习改变环境的原因以此来预测未来。
实例:由于动物会运动,环境会根据它的运动和它对环境的影响造成改变。动物需要可以利用记忆力从过去推测未来事件的能力。
实例:物理学家穷其一生寻找可以解释一切的公式(像
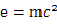
弦理论)。这种能力存
在于拥有时间观念的生命之中。人类更是其中的王者。
1.信息熵
熵是神马?信息论的开山祖师爷Shannon明确告诉我们,信息的不确定性可以用熵来表示:对于一个取有限个值的随机变量X,如果其概率分布为:
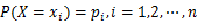
。
那么随机变量X的熵可以用以下公式描述:
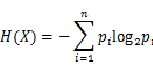
每次看到这个式子,都会从心底里感叹数学的伟大与奇妙。在这之前,信息这东东对于人们来说,是个看着好像挺清晰实际还是很模糊的概念。Shannon用最简洁美妙的方式,告诉了整个世界信息到底应该怎么去衡量去计算。今天每个互联网人都知道,这个衡量的标准就是bit。正是由于bit的出现,才引领了我们今天信息时代的到来。所以即使把Shannon跟世界上最伟大的那些科学家相提并论,我觉得也丝毫不为过。
举个例子,如果一个分类系统中,类别的标识是c 取值情况是
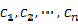
,n为类别的总数。那么此分类系统的熵为:
更特别一点,如果是个二分类系统,那么此系统的熵为:
其中
、
分别为正负样本出现的概率。
2.条件熵(Conditional Entropy)与信息增益(Information Gain)
前面我们谈到,信息的不确定性我们用熵来进行描述。很多时候,我们渴望不确定性,渴望明天又是新的一天,希望寻找新的刺激与冒险,所谓的七年之庠就是最好的例子。但是又有很多时候,我们也讨厌不确定性,我们又要竭力去消除系统的不确定性。那怎么样去消除系统的不确定性呢?当我们知道的信息越多的时候,自然随机事件的不确定性就越小。举个简单的例子:
如果投掷一枚均匀的筛子,那么筛子出现1-6的概率是相等的,此时,整个系统的熵可以表述为:
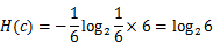
如果我们加一个特征,告诉你掷筛子的结果出来是偶数,因为掷筛子出来为偶数的结果只可能为2,4,6,那么此时系统的熵为:
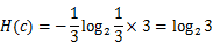
因为我们加了一个特征x:结果为偶数,所以整个系统的熵减小,不确定性降低。
来看下条件熵的表达式:
1. 当特征x被固定为值
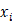
时,条件熵为:
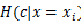
2. 当特征X的整体分布情况被固定时,条件熵为:
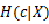
应该不难看出:
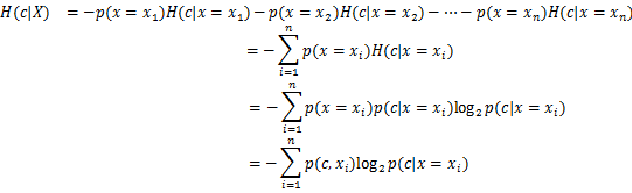
其中,n为特征X所出现所有种类的数量。
那么因为特征X被固定以后,给系统带来的增益(或者说为系统减小的不确定度)为:
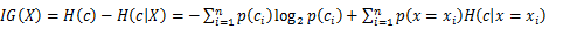
举个别人文章中例子:文本分类系统中的特征X, 那么X有几个可能的值呢?注意X是一个固定的特征,比如关键词"经济",当我们说特征"经济"可能的取值时,实际上只有两个,要么出现,要么不出现。假设x代表x出现,而
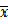
表示
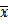
不出现。注意系统包含x但x不出现与系统根本不包含x可是两回事。
因此固定X时系统的条件熵为:
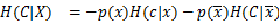
特征X给系统带来的信息增益(IG)为:
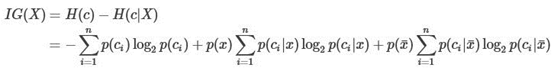
式子看上去很长,其实计算起来很简单,都是一些count的操作。

这一项不用多说,就是统计各个类别的概率,将每个类别的样本数量除以总样本量即可。
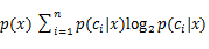
这一项,
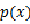
表示特征在样本中出现的概率,将特征出现的次数除以样本总量即可。
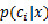
表示特征出现的情况下,每个类别的概率分别为多少,也全是count操作。
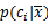
操作以此类推。
3.信息增益做特征选择的优缺点
先说说优点:1.信息增益考虑了特征出现与不出现的两种情况,比较全面,一般而言效果不错。
2.使用了所有样例的统计属性,减小了对噪声的敏感度。
3.容易理解,计算简单。
主要的缺陷:
1.信息增益考察的是特征对整个系统的贡献,没有到具体的类别上,所以一般只能用来做全局的特征选择,而没法针对单个类别做特征选择。
2.只能处理连续型的属性值,没法处理连续值的特征。
3.算法天生偏向选择分支多的属性,容易导致overfitting。
4.信息增益比(Infomation Gain Ratio)
前面提到,信息增益的一个大问题就是偏向选择分支多的属性导致overfitting,那么我们能想到的解决办法自然就是对分支过多的情况进行惩罚(penalty)了。于是我们有了信息增益比,或者说信息增益率:特征X的熵:
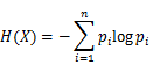
特征X的信息增益 :
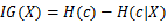
那么信息增益比为:
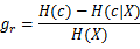
在决策树算法中,ID3使用信息增益,c4.5使用信息增益比。
5.Gini系数
Gini系数是一种与信息熵类似的做特征选择的方式,可以用来数据的不纯度。在CART(Classification and Regression Tree)算法中利用基尼指数构造二叉决策树。Gini系数的计算方式如下:
在分类问题中,假设有i个类,样本点属于第i类的概率是
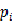
,则概率分布的基尼系数定义为:
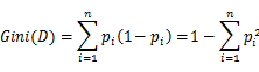
其中,D表示数据集全体样本,
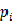
表示每种类别出现的概率。取个极端情况,如果数据集中所有的样本都为同一类,那么有
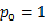
,
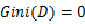
,显然此时数据的不纯度最低。
与信息增益类似,我们可以计算如下表达式:
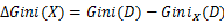
上面式子表述的意思就是,加入特征X以后,数据不纯度减小的程度。很明显,在做特征选择的时候,我们可以取
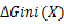
最大的那个。
6.信息熵与Gini指数的关系
信息熵在x=1处一阶泰勒展开就是基尼指数,泰勒公式如下: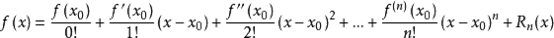
f(x)=-lnx在x=1处一阶泰勒展开,忽略掉高次项,可以得到f(x)≈1-x。这样
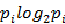
≈
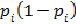
。
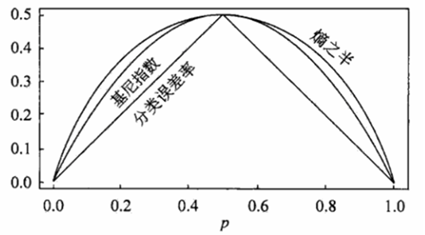
基尼系数和熵之半(也就是熵的一半值)的曲线比较近似。
7.交叉熵
7.1 从方差代价函数说起
代价函数经常用方差代价函数(即采用均方误差MSE),比如对于一个神经元(单输入单输出,sigmoid函数),定义其代价函数为: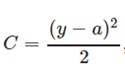
其中y是我们期望的输出,a为神经元的实际输出【 a=σ(z), where z=wx+b 】。
在训练神经网络过程中,我们通过梯度下降算法来更新w和b,因此需要计算代价函数对w和b的导数:
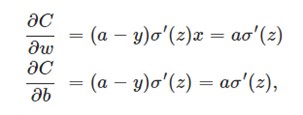
然后更新w、b:
w <—— w - η* ∂C/∂w = w - η * a *σ′(z)
b <—— b - η* ∂C/∂b = b - η * a * σ′(z)
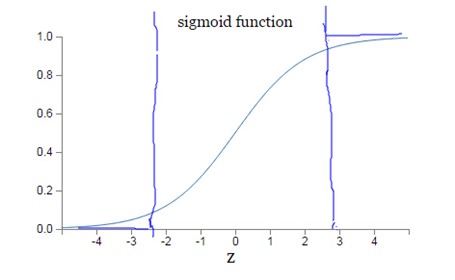
因为sigmoid函数的性质,导致σ′(z)在z取大部分值时会很小(如下图标出来的两端,几近于平坦),这样会使得w和b更新非常慢(因为η * a * σ′(z)这一项接近于0)。
7.2 交叉熵代价函数(cross-entropy cost function)
为了克服这个缺点,引入了交叉熵代价函数(下面的公式对应一个神经元,多输入单输出):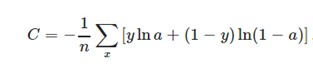
其中y为期望的输出,a为神经元实际输出【a=σ(z), where z=∑Wj*Xj+b】
与方差代价函数一样,交叉熵代价函数同样有两个性质:
非负性。(所以我们的目标就是最小化代价函数)
当真实输出a与期望输出y接近的时候,代价函数接近于0.(比如y=0,a~0;y=1,a~1时,代价函数都接近0)。
另外,它可以克服方差代价函数更新权重过慢的问题。我们同样看看它的导数:
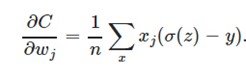
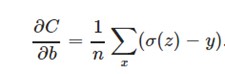
可以看到,导数中没有σ′(z)这一项,权重的更新是受σ(z)−y这一项影响,即受误差的影响。所以当误差大的时候,权重更新就快,当误差小的时候,权重的更新就慢。这是一个很好的性质。
8.总结
ID3算法:信息增益C4.5算法:信息增益率
CART算法:基尼指数
对数似然函数也常用来作为softmax回归的代价函数,在上面的讨论中,我们最后一层(也就是输出)是通过sigmoid函数,因此采用了交叉熵代价函数。而深度学习中更普遍的做法是将softmax作为最后一层,此时常用的是代价函数是log-likelihood cost。
其实这两者是一致的,logistic回归用的就是sigmoid函数,softmax回归是logistic回归的多类别推广。log-likelihood代价函数在二类别时就可以化简为交叉熵代价函数的形式。具体可以参考UFLDL教程。
参考:http://blog.csdn.net/bitcarmanlee/article/details/51488204
http://www.jianshu.com/p/3ef0d7fa92a5?from=jiantop.com
http://blog.csdn.net/u012162613/article/details/44239919/
《超能智体》

相关文章推荐
- 关于配置的那些事
- 关于国产项目Apache Kylin 发展历程及背后的那些事
- 关于“弹出框居中、angular mouse事件、JS类切换”的那些事
- 关于JavaScript的那些话
- 关于cordova的那些神坑(二) 莫名其妙闪退原因-集成xwalkview竟然和百度地图冲突
- 关于DNA分子替换模型的简明介绍(原来都属于GTR模型家族呀)
- 关于BUG的那些误解
- 关于Android stdio android plug 和Grande那些隔阂
- 关于Javascript回调函数的那些事
- 关于Android RecyclerView的那些开源LayoutManager
- 《Visual C++ 2010入门教程》系列一:关于Visual Studio、VC和C++的那些事
- 关于NHibernate实体和hbm.xml的那些错误
- 关于指纹解锁那些事
- 那些关于java.lang.NoSuchMethodException:
- 关于加班的那些事
- 关于以w3school为首的那些网址,很迷
- 关于CPU Cache——程序猿需要知道的那些事
- 关于那些常见的坑爹的小bug(会持续更新)
- 关于那些“睡后收入”
- 关于JS那些容易被你忽略的那些点(3)