Python3 爬虫实战(一)——爬取one每日一句,并保存到本地
2017-07-19 22:39
375 查看
前言
ONE是韩寒的一个团队,主要内容是每日一句话、一幅图片、一篇文章、一个问题。我们此次爬虫的目标就是爬取ONE往期所有的每日一句,并保存下来。每日一句的页面如下图所示。
大致可以按照以下的思路进行:
1.由于是所有的往期,所以要先确定每期页面的url的规律
2.查看页面源代码,确定要爬取内容的位置
3.写爬虫程序,爬取内容并保存
1.确定URL规律
下图是我们要爬取的页面中的三个关键部分:URL、期次、每日一句。
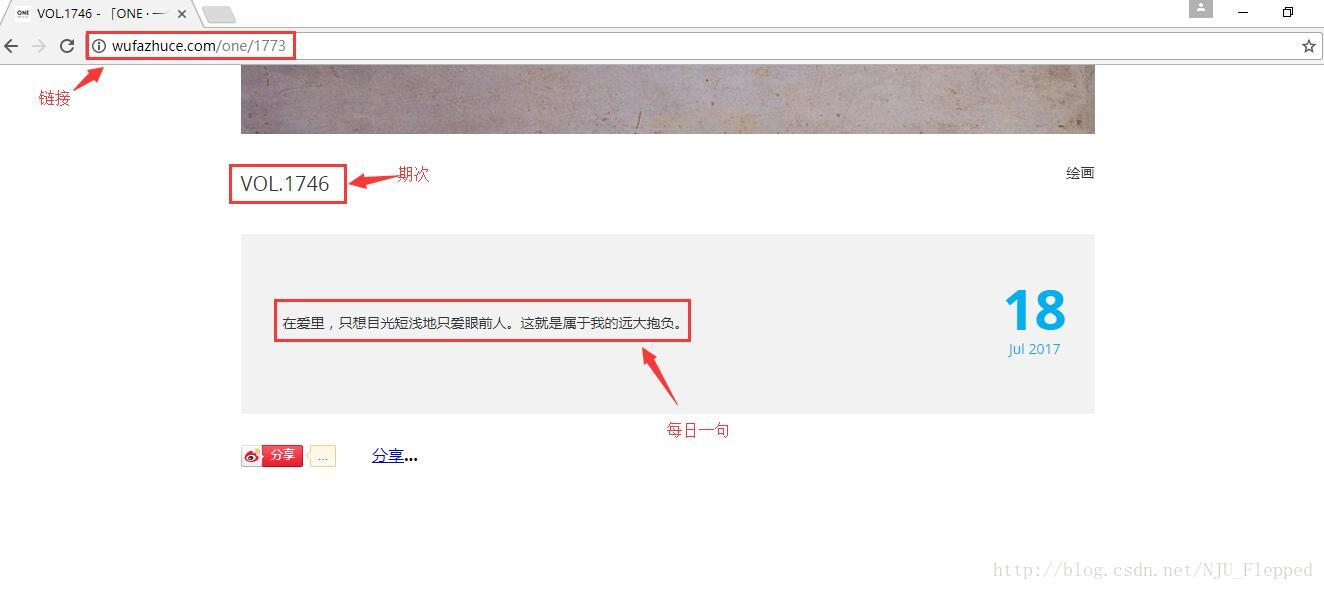
观察URL我们可以看出,每一期的URL公共部分是http://wufazhuce.com/one/,然后后面加上不同的数字,但是期次和这个数字又不相同。经过简单尝试,得出这个数字的范围大概是14-1773(2017年7月18日为终点)。这样所有的URL就是:http://wufazhuce.com/one/+num(num范围是14-1773)
2.分析源代码,定位目标
打开Chrome开发者模式(其他浏览器也有类似的查看源代码的功能),可以看到如下图所示的源代码:
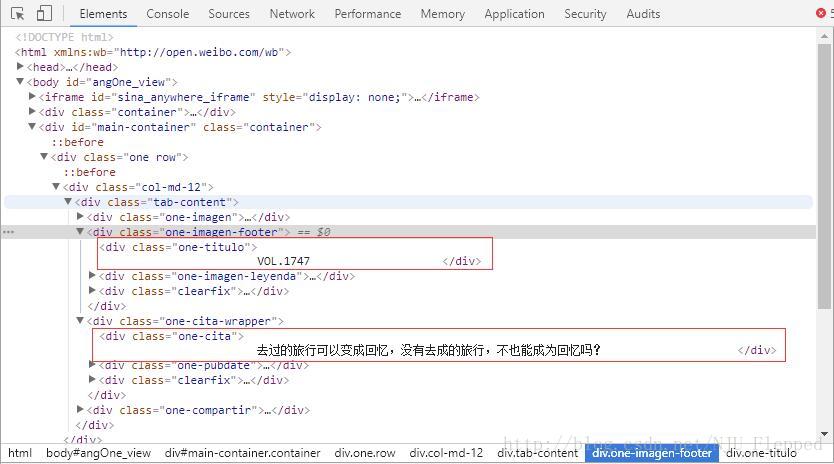
从图中我们可以看出,期次和每日一句所在的标签分别是****class属性为“one-titulo”和”one-cita”的div
3.写爬虫程序
开发工具和开发环境:Windows+Python3;IDE使用的是Spyder,可以先下载Anaconda,下载之后就包含了Spyder,并且包含了几乎所有用的到的第三方库,就不用再次下载了。
本程序主要用到的库是requests和Beautiful Soup两个。代码如下,有详细的注释。
4.执行结果:

大功告成了!下次博文更新ONE的图片爬虫
ONE是韩寒的一个团队,主要内容是每日一句话、一幅图片、一篇文章、一个问题。我们此次爬虫的目标就是爬取ONE往期所有的每日一句,并保存下来。每日一句的页面如下图所示。
大致可以按照以下的思路进行:
1.由于是所有的往期,所以要先确定每期页面的url的规律
2.查看页面源代码,确定要爬取内容的位置
3.写爬虫程序,爬取内容并保存
1.确定URL规律
下图是我们要爬取的页面中的三个关键部分:URL、期次、每日一句。
观察URL我们可以看出,每一期的URL公共部分是http://wufazhuce.com/one/,然后后面加上不同的数字,但是期次和这个数字又不相同。经过简单尝试,得出这个数字的范围大概是14-1773(2017年7月18日为终点)。这样所有的URL就是:http://wufazhuce.com/one/+num(num范围是14-1773)
2.分析源代码,定位目标
打开Chrome开发者模式(其他浏览器也有类似的查看源代码的功能),可以看到如下图所示的源代码:
从图中我们可以看出,期次和每日一句所在的标签分别是****class属性为“one-titulo”和”one-cita”的div
3.写爬虫程序
开发工具和开发环境:Windows+Python3;IDE使用的是Spyder,可以先下载Anaconda,下载之后就包含了Spyder,并且包含了几乎所有用的到的第三方库,就不用再次下载了。
本程序主要用到的库是requests和Beautiful Soup两个。代码如下,有详细的注释。
import requests
import re
from bs4 import BeautifulSoup
url='http://wufazhuce.com/one/'#每一期的链接共同的部分
words=['0']*1800#定义一个长度为1800的列表,用来保存每一句话,并初始化为全‘0’
for i in range(14,1774):
s=str(i)#数字类型转为字符串类型
currenturl=url+s#当前期的链接
try:
res=requests.get(currenturl)
res.raise_for_status()
except requests.RequestException as e:#处理异常
print(e)
else:
html=res.text#页面内容
soup = BeautifulSoup(html,'html.parser')
a=soup.select('.one-titulo')#查找期次所在的标签
b=soup.select('.one-cita')#查找“每日一句”所在的标签
index=re.sub("\D","",a[0].string.split()[0])#从“vol.xxx”提取期次数值作为下标
if(index==''):
continue
words[int(index)]=b[0].string.split()#将该期“每日一句”存入列表
f=open("one2.txt","a",encoding='utf-8')#将每句话写入这个txt文件中,先打开
for i in range(1,1774):
if(words[i]=='0'):
continue
else:
f.writelines('VOL.'+str(i)+'\n')#写入期次和换行
f.writelines(' ')#每句话开始空四格
f.writelines(words[i])#写入该句话
f.writelines('\n\n')#换行,并空一行写入下一句
f.close()#关闭文件4.执行结果:
大功告成了!下次博文更新ONE的图片爬虫

相关文章推荐
- python爬虫抓取51cto博客大牛的文章保存到本地excel文件
- Python爬虫(四):爬取136书屋小说,并保存至本地文本文件中,单进程多进程对比效率(以三生三世十里桃花为例)
- 芝麻HTTP:Python爬虫实战之抓取爱问知识人问题并保存至数据库
- Python爬虫实战(1)——百度贴吧抓取帖子并保存内容和图片
- python爬虫由浅入深1-从网页中爬取文件并保存至本地
- Python爬虫获取图片并下载保存至本地的实例
- Python 爬虫多线程爬取美女图片保存到本地
- Python爬虫实战六之抓取爱问知识人问题并保存至数据库
- python爬虫实战笔记---selenium爬取QQ空间说说并存至本地
- python第一个爬虫小程序以及遇到问题解决(中文乱码)+批量爬取网页并保存至本地
- python爬虫简单的抓页面图片并保存到本地
- python爬虫实战笔记---selenium爬取QQ空间说说并存至本地(上)
- [PYTHON]-用Scrapy爬虫遍历百度贴吧,本地保存文字版【PART 1】
- python爬虫数据保存到本地各种格式的方法
- Python爬虫: 抓取One网页上的每日一话和图
- python爬虫实战--selenium验证码保存+多线程多标签+自动点击+完整代码
- python爬虫由浅入深9---定向爬取股票数据信息并保存至本地文件
- [PYTHON]-用Scrapy爬虫遍历百度贴吧,本地保存文字版【PART 2】
- Python 爬虫抓取美女图片保存到本地
- Python爬虫实战六之抓取爱问知识人问题并保存至数据库