或许你不知道的10条SQL技巧
2017-07-17 18:10
344 查看
一、一些常见的SQL实践
(1)负向条件查询不能使用索引
select * from order where status!=0
and stauts!=1
not in/not exists都不是好习惯
可以优化为in查询:
select * from order where status in(2,3)
(2)前导模糊查询不能使用索引
select * from order where desc like '%XX'
而非前导模糊查询则可以:
select * from order where desc like 'XX%'
(3)数据区分度不大的字段不宜使用索引
select * from user where sex=1
原因:性别只有男,女,每次过滤掉的数据很少,不宜使用索引。
经验上,能过滤80%数据时就可以使用索引。对于订单状态,如果状态值很少,不宜使用索引,如果状态值很多,能够过滤大量数据,则应该建立索引。
(4)在属性上进行计算不能命中索引
select * from order where YEAR(date) <
= '2017'
即使date上建立了索引,也会全表扫描,可优化为值计算:
select * from order where date < = CURDATE()
或者:
select * from order where date < = '2017-01-01'
二、并非周知的SQL实践
(5)如果业务大部分是单条查询,使用Hash索引性能更好,例如用户中心
select * from user where uid=?
select * from user where login_name=?
原因:
B-Tree索引的时间复杂度是O(log(n))
Hash索引的时间复杂度是O(1)
(6)允许为null的列,查询有潜在大坑
单列索引不存null值,复合索引不存全为null的值,如果列允许为null,可能会得到“不符合预期”的结果集
select * from user where name != 'shenjian'
如果name允许为null,索引不存储null值,结果集中不会包含这些记录。
所以,请使用not null约束以及默认值。
(7)复合索引最左前缀,并不是值SQL语句的where顺序要和复合索引一致
用户中心建立了(login_name,
passwd)的复合索引
select * from user where login_name=?
and passwd=?
select * from user where passwd=?
and login_name=?
都能够命中索引
select * from user where login_name=?
也能命中索引,满足复合索引最左前缀
select * from user where passwd=?
不能命中索引,不满足复合索引最左前缀
(8)使用ENUM而不是字符串
ENUM保存的是TINYINT,别在枚举中搞一些“中国”“北京”“技术部”这样的字符串,字符串空间又大,效率又低。
三、小众但有用的SQL实践
(9)如果明确知道只有一条结果返回,limit
1能够提高效率
select * from user where login_name=?
可以优化为:
select * from user where login_name=? limit 1
原因:
你知道只有一条结果,但数据库并不知道,明确告诉它,让它主动停止游标移动
(10)把计算放到业务层而不是数据库层,除了节省数据的CPU,还有意想不到的查询缓存优化效果
select * from order where date < = CURDATE()
这不是一个好的SQL实践,应该优化为:
$curDate = date('Y-m-d');
$res = mysql_query(
'select * from order where date < = $curDate');
原因:
释放了数据库的CPU
多次调用,传入的SQL相同,才可以利用查询缓存
(11)强制类型转换会全表扫描
select * from user where phone=13800001234
你以为会命中phone索引么?大错特错了,这个语句究竟要怎么改?
末了,再加一条,不要使用select
*(潜台词,文章的SQL都不合格 =_=),只返回需要的列,能够大大的节省数据传输量,与数据库的内存使用量哟。
思路比结论重要,希望有收获,帮忙转一下。
假设订单业务表结构为:
order(oid, date, uid, status, money, time, …)
其中:
oid,订单ID,主键
date,下单日期,有普通索引,管理后台经常按照date查询
uid,用户ID,有普通索引,用户查询自己订单
status,订单状态,有普通索引,管理后台经常按照status查询
money/time,订单金额/时间,被查询字段,无索引
…
假设订单有三种状态:0已下单,1已支付,2已完成
业务需求,查询未完成的订单,哪个SQL更快呢?
select * from order where status!=2
select * from order where status=0 or status=1
select * from order where status IN (0,1)
select * from order where status=0
union all
select * from order where status=1
结论:方案1最慢,方案2,3,4都能命中索引
但是...
一:union
all 肯定是能够命中索引的
select * from order where status=0
union all
select * from order where status=1
说明:
直接告诉MySQL怎么做,MySQL耗费的CPU最少
程序员并不经常这么写SQL(union
all)
二:简单的in能够命中索引
select * from order where status in (0,1)
说明:
让MySQL思考,查询优化耗费的cpu比union
all多,但可以忽略不计
程序员最常这么写SQL(in),这个例子,最建议这么写
三:对于or,新版的MySQL能够命中索引
select * from order where status=0 or status=1
说明:
让MySQL思考,查询优化耗费的cpu比in多,别把负担交给MySQL
不建议程序员频繁用or,不是所有的or都命中索引
对于老版本的MySQL,建议查询分析下
四、对于!=,负向查询肯定不能命中索引
select * from order where status!=2
说明:
全表扫描,效率最低,所有方案中最慢
禁止使用负向查询
五、其他方案
select * from order where status < 2
这个具体的例子中,确实快,但是:
这个例子只举了3个状态,实际业务不止这3个状态,并且状态的“值”正好满足偏序关系,万一是查其他状态呢,SQL不宜依赖于枚举的值,方案不通用
这个SQL可读性差,可理解性差,可维护性差,强烈不推荐
六、作业
这样的查询能够命中索引么?
select * from order where uid in (
select uid from order where status=0
)
select * from order where status in (0, 1) order by date desc
select * from order where status=0 or date <= CURDATE()
注:此为示例,别较真SQL对应业务的合理性。
索引创建:
花1分钟时间,了解聚集索引,非聚集索引,联合索引,索引覆盖。
举例,业务场景,用户表,表结构为:
t_user(
uid primary key,
login_name unique,
passwd,
login_time,
age,
…
);
聚集索引(clustered
index):聚集索引决定数据在磁盘上的物理排序,一个表只能有一个聚集索引,一般用primary
key来约束。
举例:t_user场景中,uid上的索引。
非聚集索引(non-clustered
index):它并不决定数据在磁盘上的物理排序,索引上只包含被建立索引的数据,以及一个行定位符row-locator,这个行定位符,可以理解为一个聚集索引物理排序的指针,通过这个指针,可以找到行数据。
举例,查找年轻MM的业务需求:
select uid from t_user where age > 18 and age < 26;
age上建立的索引,就是非聚集索引。
联合索引:多个字段上建立的索引,能够加速复核查询条件的检索
举例,登录业务需求:
select uid, login_time from t_user where
login_name=? and passwd=?
可以建立(login_name, passwd)的联合索引。
联合索引能够满足最左侧查询需求,例如(a,
b, c)三列的联合索引,能够加速a | (a, b) | (a, b, c) 三组查询需求。
这也就是为何不建立(passwd,
login_name)这样联合索引的原因,业务上几乎没有passwd的单条件查询需求,而有很多login_name的单条件查询需求。
提问:
select uid, login_time from t_user where
passwd=? and login_name=?
能否命中(login_name,
passwd)这个联合索引?
回答:可以,最左侧查询需求,并不是指SQL语句的写法必须满足索引的顺序(这是很多朋友的误解)
索引覆盖:被查询的列,数据能从索引中取得,而不用通过行定位符row-locator再到row上获取,即“被查询列要被所建的索引覆盖”,这能够加速查询速度。
举例,登录业务需求:
select uid, login_time from t_user where
login_name=? and passwd=?
可以建立(login_name,
passwd, login_time)的联合索引,由于login_time已经建立在索引中了,被查询的uid和login_time就不用去row上获取数据了,从而加速查询。
末了多说一句,登录这个业务场景,login_name具备唯一性,建这个单列索引就好。
作业:
假设订单有三种状态:0已下单,1已支付,2已完成
业务需求,查询未完成的订单,哪个SQL更快呢?
select * from order where status!=2
select * from order where status=0 or status=1
select * from order where status IN (0,1)
select * from order where status=0
union
select * from order where stauts=1
一,为什么要冗余数据
互联网数据量很大的业务场景,往往数据库需要进行水平切分来降低单库数据量。
水平切分会有一个patition key,通过patition
key的查询能够直接定位到库,但是非patition key上的查询可能就需要扫描多个库了。
此时常见的架构设计方案,是使用数据冗余这种反范式设计来满足分库后不同维度的查询需求。
例如:订单业务,对用户和商家都有订单查询需求:
Order(oid, info_detail);
T(buyer_id, seller_id, oid);
如果用buyer_id来分库,seller_id的查询就需要扫描多库。
如果用seller_id来分库,buyer_id的查询就需要扫描多库。
此时可以使用数据冗余来分别满足buyer_id和seller_id上的查询需求:
T1(buyer_id, seller_id, oid)
T2(seller_id, buyer_id, oid)
同一个数据,冗余两份,一份以buyer_id来分库,满足买家的查询需求;一份以seller_id来分库,满足卖家的查询需求。
如何实施数据的冗余,是今天将要讨论的内容。
二,服务同步双写
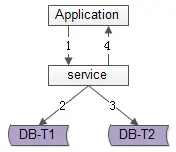
顾名思义,由服务层同步写冗余数据,如上图1-4流程:
业务方调用服务,新增数据
服务先插入T1数据
服务再插入T2数据
服务返回业务方新增数据成功
优点:
不复杂,服务层由单次写,变两次写
数据一致性相对较高(因为双写成功才返回)
缺点:
请求的处理时间增加(要插入两次,时间加倍)
数据仍可能不一致,例如第二步写入T1完成后服务重启,则数据不会写入T2
如果系统对处理时间比较敏感,引出常用的第二种方案。
三,服务异步双写
数据的双写并不再由服务来完成,服务层异步发出一个消息,通过消息总线发送给一个专门的数据复制服务来写入冗余数据,如上图1-6流程:
业务方调用服务,新增数据
服务先插入T1数据
服务向消息总线发送一个异步消息(发出即可,不用等返回,通常很快就能完成)
服务返回业务方新增数据成功
消息总线将消息投递给数据同步中心
数据同步中心插入T2数据
优点:
请求处理时间短(只插入1次)
缺点:
系统的复杂性增加了,多引入了一个组件(消息总线)和一个服务(专用的数据复制服务)
因为返回业务线数据插入成功时,数据还不一定插入到T2中,因此数据有一个不一致时间窗口(这个窗口很短,最终是一致的)
在消息总线丢失消息时,冗余表数据会不一致
不管是服务同步双写,还是服务异步双写,服务都需要关注“冗余数据”带来的复杂性。如果想解除“数据冗余”对系统的耦合,引出常用的第三种方案。
四,线下异步双写
为了屏蔽“冗余数据”对服务带来的复杂性,数据的双写不再由服务层来完成,而是由线下的一个服务或者任务来完成,如上图1-6流程:
业务方调用服务,新增数据
服务先插入T1数据
服务返回业务方新增数据成功
数据会被写入到数据库的log中
线下服务或者任务读取数据库的log
线下服务或者任务插入T2数据
优点:
数据双写与业务完全解耦
请求处理时间短(只插入1次)
缺点:
返回业务线数据插入成功时,数据还不一定插入到T2中,因此数据有一个不一致时间窗口(这个窗口很短,最终是一致的)
数据的一致性依赖于线下服务或者任务的可靠性
五,总结
互联网数据量大的业务场景,常常:
使用水平切分来降低单库数据量
使用数据冗余的反范式设计来满足不同维度的查询需求
使用服务同步双写法能够很容易的实现数据冗余
为了降低时延,可以优化为服务异步双写法
为了屏蔽“冗余数据”对服务带来的复杂性,可以优化为线下异步双写法
(1)负向条件查询不能使用索引
select * from order where status!=0
and stauts!=1
not in/not exists都不是好习惯
可以优化为in查询:
select * from order where status in(2,3)
(2)前导模糊查询不能使用索引
select * from order where desc like '%XX'
而非前导模糊查询则可以:
select * from order where desc like 'XX%'
(3)数据区分度不大的字段不宜使用索引
select * from user where sex=1
原因:性别只有男,女,每次过滤掉的数据很少,不宜使用索引。
经验上,能过滤80%数据时就可以使用索引。对于订单状态,如果状态值很少,不宜使用索引,如果状态值很多,能够过滤大量数据,则应该建立索引。
(4)在属性上进行计算不能命中索引
select * from order where YEAR(date) <
= '2017'
即使date上建立了索引,也会全表扫描,可优化为值计算:
select * from order where date < = CURDATE()
或者:
select * from order where date < = '2017-01-01'
二、并非周知的SQL实践
(5)如果业务大部分是单条查询,使用Hash索引性能更好,例如用户中心
select * from user where uid=?
select * from user where login_name=?
原因:
B-Tree索引的时间复杂度是O(log(n))
Hash索引的时间复杂度是O(1)
(6)允许为null的列,查询有潜在大坑
单列索引不存null值,复合索引不存全为null的值,如果列允许为null,可能会得到“不符合预期”的结果集
select * from user where name != 'shenjian'
如果name允许为null,索引不存储null值,结果集中不会包含这些记录。
所以,请使用not null约束以及默认值。
(7)复合索引最左前缀,并不是值SQL语句的where顺序要和复合索引一致
用户中心建立了(login_name,
passwd)的复合索引
select * from user where login_name=?
and passwd=?
select * from user where passwd=?
and login_name=?
都能够命中索引
select * from user where login_name=?
也能命中索引,满足复合索引最左前缀
select * from user where passwd=?
不能命中索引,不满足复合索引最左前缀
(8)使用ENUM而不是字符串
ENUM保存的是TINYINT,别在枚举中搞一些“中国”“北京”“技术部”这样的字符串,字符串空间又大,效率又低。
三、小众但有用的SQL实践
(9)如果明确知道只有一条结果返回,limit
1能够提高效率
select * from user where login_name=?
可以优化为:
select * from user where login_name=? limit 1
原因:
你知道只有一条结果,但数据库并不知道,明确告诉它,让它主动停止游标移动
(10)把计算放到业务层而不是数据库层,除了节省数据的CPU,还有意想不到的查询缓存优化效果
select * from order where date < = CURDATE()
这不是一个好的SQL实践,应该优化为:
$curDate = date('Y-m-d');
$res = mysql_query(
'select * from order where date < = $curDate');
原因:
释放了数据库的CPU
多次调用,传入的SQL相同,才可以利用查询缓存
(11)强制类型转换会全表扫描
select * from user where phone=13800001234
你以为会命中phone索引么?大错特错了,这个语句究竟要怎么改?
末了,再加一条,不要使用select
*(潜台词,文章的SQL都不合格 =_=),只返回需要的列,能够大大的节省数据传输量,与数据库的内存使用量哟。
思路比结论重要,希望有收获,帮忙转一下。
假设订单业务表结构为:
order(oid, date, uid, status, money, time, …)
其中:
oid,订单ID,主键
date,下单日期,有普通索引,管理后台经常按照date查询
uid,用户ID,有普通索引,用户查询自己订单
status,订单状态,有普通索引,管理后台经常按照status查询
money/time,订单金额/时间,被查询字段,无索引
…
假设订单有三种状态:0已下单,1已支付,2已完成
业务需求,查询未完成的订单,哪个SQL更快呢?
select * from order where status!=2
select * from order where status=0 or status=1
select * from order where status IN (0,1)
select * from order where status=0
union all
select * from order where status=1
结论:方案1最慢,方案2,3,4都能命中索引
但是...
一:union
all 肯定是能够命中索引的
select * from order where status=0
union all
select * from order where status=1
说明:
直接告诉MySQL怎么做,MySQL耗费的CPU最少
程序员并不经常这么写SQL(union
all)
二:简单的in能够命中索引
select * from order where status in (0,1)
说明:
让MySQL思考,查询优化耗费的cpu比union
all多,但可以忽略不计
程序员最常这么写SQL(in),这个例子,最建议这么写
三:对于or,新版的MySQL能够命中索引
select * from order where status=0 or status=1
说明:
让MySQL思考,查询优化耗费的cpu比in多,别把负担交给MySQL
不建议程序员频繁用or,不是所有的or都命中索引
对于老版本的MySQL,建议查询分析下
四、对于!=,负向查询肯定不能命中索引
select * from order where status!=2
说明:
全表扫描,效率最低,所有方案中最慢
禁止使用负向查询
五、其他方案
select * from order where status < 2
这个具体的例子中,确实快,但是:
这个例子只举了3个状态,实际业务不止这3个状态,并且状态的“值”正好满足偏序关系,万一是查其他状态呢,SQL不宜依赖于枚举的值,方案不通用
这个SQL可读性差,可理解性差,可维护性差,强烈不推荐
六、作业
这样的查询能够命中索引么?
select * from order where uid in (
select uid from order where status=0
)
select * from order where status in (0, 1) order by date desc
select * from order where status=0 or date <= CURDATE()
注:此为示例,别较真SQL对应业务的合理性。
索引创建:
花1分钟时间,了解聚集索引,非聚集索引,联合索引,索引覆盖。
举例,业务场景,用户表,表结构为:
t_user(
uid primary key,
login_name unique,
passwd,
login_time,
age,
…
);
聚集索引(clustered
index):聚集索引决定数据在磁盘上的物理排序,一个表只能有一个聚集索引,一般用primary
key来约束。
举例:t_user场景中,uid上的索引。
非聚集索引(non-clustered
index):它并不决定数据在磁盘上的物理排序,索引上只包含被建立索引的数据,以及一个行定位符row-locator,这个行定位符,可以理解为一个聚集索引物理排序的指针,通过这个指针,可以找到行数据。
举例,查找年轻MM的业务需求:
select uid from t_user where age > 18 and age < 26;
age上建立的索引,就是非聚集索引。
联合索引:多个字段上建立的索引,能够加速复核查询条件的检索
举例,登录业务需求:
select uid, login_time from t_user where
login_name=? and passwd=?
可以建立(login_name, passwd)的联合索引。
联合索引能够满足最左侧查询需求,例如(a,
b, c)三列的联合索引,能够加速a | (a, b) | (a, b, c) 三组查询需求。
这也就是为何不建立(passwd,
login_name)这样联合索引的原因,业务上几乎没有passwd的单条件查询需求,而有很多login_name的单条件查询需求。
提问:
select uid, login_time from t_user where
passwd=? and login_name=?
能否命中(login_name,
passwd)这个联合索引?
回答:可以,最左侧查询需求,并不是指SQL语句的写法必须满足索引的顺序(这是很多朋友的误解)
索引覆盖:被查询的列,数据能从索引中取得,而不用通过行定位符row-locator再到row上获取,即“被查询列要被所建的索引覆盖”,这能够加速查询速度。
举例,登录业务需求:
select uid, login_time from t_user where
login_name=? and passwd=?
可以建立(login_name,
passwd, login_time)的联合索引,由于login_time已经建立在索引中了,被查询的uid和login_time就不用去row上获取数据了,从而加速查询。
末了多说一句,登录这个业务场景,login_name具备唯一性,建这个单列索引就好。
作业:
假设订单有三种状态:0已下单,1已支付,2已完成
业务需求,查询未完成的订单,哪个SQL更快呢?
select * from order where status!=2
select * from order where status=0 or status=1
select * from order where status IN (0,1)
select * from order where status=0
union
select * from order where stauts=1
一,为什么要冗余数据
互联网数据量很大的业务场景,往往数据库需要进行水平切分来降低单库数据量。
水平切分会有一个patition key,通过patition
key的查询能够直接定位到库,但是非patition key上的查询可能就需要扫描多个库了。
此时常见的架构设计方案,是使用数据冗余这种反范式设计来满足分库后不同维度的查询需求。
例如:订单业务,对用户和商家都有订单查询需求:
Order(oid, info_detail);
T(buyer_id, seller_id, oid);
如果用buyer_id来分库,seller_id的查询就需要扫描多库。
如果用seller_id来分库,buyer_id的查询就需要扫描多库。
此时可以使用数据冗余来分别满足buyer_id和seller_id上的查询需求:
T1(buyer_id, seller_id, oid)
T2(seller_id, buyer_id, oid)
同一个数据,冗余两份,一份以buyer_id来分库,满足买家的查询需求;一份以seller_id来分库,满足卖家的查询需求。
如何实施数据的冗余,是今天将要讨论的内容。
二,服务同步双写
顾名思义,由服务层同步写冗余数据,如上图1-4流程:
业务方调用服务,新增数据
服务先插入T1数据
服务再插入T2数据
服务返回业务方新增数据成功
优点:
不复杂,服务层由单次写,变两次写
数据一致性相对较高(因为双写成功才返回)
缺点:
请求的处理时间增加(要插入两次,时间加倍)
数据仍可能不一致,例如第二步写入T1完成后服务重启,则数据不会写入T2
如果系统对处理时间比较敏感,引出常用的第二种方案。
三,服务异步双写
数据的双写并不再由服务来完成,服务层异步发出一个消息,通过消息总线发送给一个专门的数据复制服务来写入冗余数据,如上图1-6流程:
业务方调用服务,新增数据
服务先插入T1数据
服务向消息总线发送一个异步消息(发出即可,不用等返回,通常很快就能完成)
服务返回业务方新增数据成功
消息总线将消息投递给数据同步中心
数据同步中心插入T2数据
优点:
请求处理时间短(只插入1次)
缺点:
系统的复杂性增加了,多引入了一个组件(消息总线)和一个服务(专用的数据复制服务)
因为返回业务线数据插入成功时,数据还不一定插入到T2中,因此数据有一个不一致时间窗口(这个窗口很短,最终是一致的)
在消息总线丢失消息时,冗余表数据会不一致
不管是服务同步双写,还是服务异步双写,服务都需要关注“冗余数据”带来的复杂性。如果想解除“数据冗余”对系统的耦合,引出常用的第三种方案。
四,线下异步双写
为了屏蔽“冗余数据”对服务带来的复杂性,数据的双写不再由服务层来完成,而是由线下的一个服务或者任务来完成,如上图1-6流程:
业务方调用服务,新增数据
服务先插入T1数据
服务返回业务方新增数据成功
数据会被写入到数据库的log中
线下服务或者任务读取数据库的log
线下服务或者任务插入T2数据
优点:
数据双写与业务完全解耦
请求处理时间短(只插入1次)
缺点:
返回业务线数据插入成功时,数据还不一定插入到T2中,因此数据有一个不一致时间窗口(这个窗口很短,最终是一致的)
数据的一致性依赖于线下服务或者任务的可靠性
五,总结
互联网数据量大的业务场景,常常:
使用水平切分来降低单库数据量
使用数据冗余的反范式设计来满足不同维度的查询需求
使用服务同步双写法能够很容易的实现数据冗余
为了降低时延,可以优化为服务异步双写法
为了屏蔽“冗余数据”对服务带来的复杂性,可以优化为线下异步双写法

相关文章推荐
- 或许你不知道的10条SQL技巧
- SQL优化之道 - 或许你不知道的10条SQL技巧
- 或许你不知道的10条SQL技巧
- 或许你不知道的10条SQL技巧 原创 2017-07-16 58沈剑 架构师之路 这几天在写索引,想到一些有意思的TIPS,希望大家有收获。 一、一些常见的SQL实践 (1)负向条件查询不能使用索
- 或许你不知道的10条sql技巧
- 或许你不知道的10条SQL技巧
- 或许你不知道的10条SQL技巧
- 或许你不知道的10条SQL技巧
- 或许你不知道的10条SQL技巧((sql 优化 sql索引优化))
- 或许你不知道的10条SQL
- SQL索引优化3(10条SQL技巧)
- 关于 MySQL 你可能不知道的 SQL 使用技巧
- 或许你不知道的10条SQL技巧
- 10条SQL技巧
- 关于 MySQL 你可能不知道的 SQL 使用技巧
- AspNet中你或许不知道的技巧(转)
- 你可能不知道的 10 条 SQL 技巧,涨知识了!
- 你可能不知道的 10 条 SQL 技巧,涨知识了!
- AspNet十个你或许不知道的技巧,十分管用
- pl/sql 快捷键技巧