数据结构及算法知识(一)
2017-07-16 15:00
357 查看
一、有序表的归并算法
思想:(在不破坏原有表的情况下)将两个有序表合并成一个有序表可以采用二路归并算法。
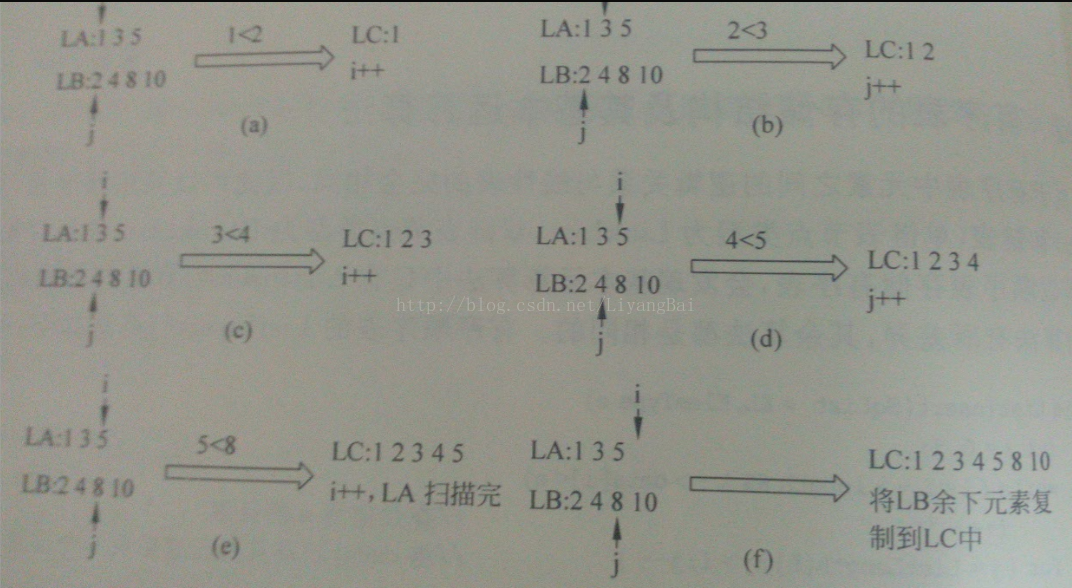
分别扫描LA和LB两个有序表,当两个有序表都没有扫描完时循环:比较LA、LB的当前元素,将其中较小的元素放入LC中,再从较小元素所在的有序表中取出下一个元素。重复这一过程直到LA或LB比较完毕,最后将为比较完的有序表中余下元素放入LC中。
假设表的长度分别为M、N,则时间复杂度为O(M+N),最好情况下比较次数为M/N,最坏情况下为M+N-1
例如:LA={1,3,5};LB={2,4,8,10},其二路归并过程如图所示:
二、双端队列
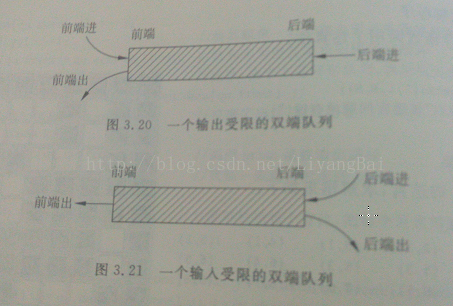
即两端都可以进队和出队操作的队列。

补充:环形队列中,队头指针front指向队列中队首元素的前一个位置,队尾指针rear指向队列中的队尾元素
三、串
#概念:串(字符串),由零个或多个字符组成的有限序列。
空串:不包含任何字符的串,长度为0。空串是任何串的子串。
串中所含字符的个数是该串的长度。通常表示为“a1a2...an”
当且仅当两个串的长度相等并且各个对应位置上的字符都相同时,这两个串才相等。
一个串中任意个连续字符组成的序列称为该串的子串。
在串中空格字符用□表示
#存储结构:顺序存储结构(顺序串)和链式存储结构(链串)
%顺序串的两种存储方法:
①非紧缩格式(存储密度小):每个单元只存一个字符。
②紧缩格式(存储密度大):每个单元存放多个字符。

说明:图中有阴影的字节为空闲部分。
%链串:链串中的一个节点可以存储多个字符。通常将链串中每个节点存储的字符个数称为节点大小。
主要有节点大一1和节点等于1两种。

优缺点:节点越大,存储密度越大,但运算处理不方便;
节点越小,运算处理越方便,但存储密度下降。
#串的模式匹配
模式匹配(定位):即在主串s(目标串)中找到一个与子串t(模式串)相等的子串。
此处假设串采用顺序存储结构;
%BF(简单匹配)算法:
思路:从目标串s="s0s1...sn-1"的第一个字符开始和模式串t="t0t1...tm-1"中的第一个字符比较,若相等,则继续逐个比较后序字符;否则从目标串s的第二个字符开始重新与模式串t的第一个字符进行比较。以此类推
afff
,若从模式串s的第i个字符开始,每个字符依旧与目标串t中的对应字符相等,则匹配成功;否则,匹配失败,返回-1;
例如:目标串s="aaaaab",模式串t="aaab",s长度n=6,m长度m=4

总结:
①第k(k>=1)次比较是从s中字符sk-1开始与t中的第一个字符t0比较。
②设某一次匹配有si不等于tj,其中0<=i<=n,0<=j<m,i>=j,则应有si-1=tj-1,...,si-j+1=t1,si-j=t0;
(此时k=i-j)下一次比较目标串的字符si-j+1和模式串的字符t0;一般过程如下:

也就是说,某次匹配不成功时,下一次目标串S从Si-j+1开始,t从t0开始比较。成功时返回匹配的第一个字符的下标;
缺点:效率不高,原因:主串指针回溯(i=i-j+1);
最好情况下时间复杂度O(m);最坏情况下时间复杂度O(mn);
%KMP算法:
KMP算法主要消除BF算法中主串指针回溯的问题,从而提高算法效率。
KMP算法思想:设s为目标串,t为模式串,并设i指针和j指针分别指示目标串和模式串中正在比较的字符,令i和j的初始值均为0;若有si=tj,则i和j分别增1,否则,i不变,j退回到j=next[j]的位置(即模式串右滑),比较si和tj,若相等,则指针各增1,否则j再退回到下一个j=next[j]的位置(即模式串继续右滑),再比较si和tj。以此类推,知道出现以下两种情况之一:一是j退回到某个j=next[j]位置时有si=tj,则指针各增1后继续匹配;二是j退回到j=-1,此时令i、j指针各增1,即从si+1和t0开始继续匹配。

next数组的解释如下:

KMP算法匹配过程如下:

复杂度分析:
设主串s的长度为n,子串t的长度为m,在KMP算法中求next数组的时间复杂度为O(n),在之后的匹配中主串s的下标i不回溯,比较次数为n,所以KMP算法的时间复杂度为O(n+m)。
思想:(在不破坏原有表的情况下)将两个有序表合并成一个有序表可以采用二路归并算法。
分别扫描LA和LB两个有序表,当两个有序表都没有扫描完时循环:比较LA、LB的当前元素,将其中较小的元素放入LC中,再从较小元素所在的有序表中取出下一个元素。重复这一过程直到LA或LB比较完毕,最后将为比较完的有序表中余下元素放入LC中。
假设表的长度分别为M、N,则时间复杂度为O(M+N),最好情况下比较次数为M/N,最坏情况下为M+N-1
例如:LA={1,3,5};LB={2,4,8,10},其二路归并过程如图所示:
二、双端队列
即两端都可以进队和出队操作的队列。
补充:环形队列中,队头指针front指向队列中队首元素的前一个位置,队尾指针rear指向队列中的队尾元素
三、串
#概念:串(字符串),由零个或多个字符组成的有限序列。
空串:不包含任何字符的串,长度为0。空串是任何串的子串。
串中所含字符的个数是该串的长度。通常表示为“a1a2...an”
当且仅当两个串的长度相等并且各个对应位置上的字符都相同时,这两个串才相等。
一个串中任意个连续字符组成的序列称为该串的子串。
在串中空格字符用□表示
#存储结构:顺序存储结构(顺序串)和链式存储结构(链串)
%顺序串的两种存储方法:
①非紧缩格式(存储密度小):每个单元只存一个字符。
②紧缩格式(存储密度大):每个单元存放多个字符。
说明:图中有阴影的字节为空闲部分。
%链串:链串中的一个节点可以存储多个字符。通常将链串中每个节点存储的字符个数称为节点大小。
主要有节点大一1和节点等于1两种。
优缺点:节点越大,存储密度越大,但运算处理不方便;
节点越小,运算处理越方便,但存储密度下降。
#串的模式匹配
模式匹配(定位):即在主串s(目标串)中找到一个与子串t(模式串)相等的子串。
此处假设串采用顺序存储结构;
%BF(简单匹配)算法:
思路:从目标串s="s0s1...sn-1"的第一个字符开始和模式串t="t0t1...tm-1"中的第一个字符比较,若相等,则继续逐个比较后序字符;否则从目标串s的第二个字符开始重新与模式串t的第一个字符进行比较。以此类推
afff
,若从模式串s的第i个字符开始,每个字符依旧与目标串t中的对应字符相等,则匹配成功;否则,匹配失败,返回-1;
例如:目标串s="aaaaab",模式串t="aaab",s长度n=6,m长度m=4
总结:
①第k(k>=1)次比较是从s中字符sk-1开始与t中的第一个字符t0比较。
②设某一次匹配有si不等于tj,其中0<=i<=n,0<=j<m,i>=j,则应有si-1=tj-1,...,si-j+1=t1,si-j=t0;
(此时k=i-j)下一次比较目标串的字符si-j+1和模式串的字符t0;一般过程如下:
也就是说,某次匹配不成功时,下一次目标串S从Si-j+1开始,t从t0开始比较。成功时返回匹配的第一个字符的下标;
缺点:效率不高,原因:主串指针回溯(i=i-j+1);
最好情况下时间复杂度O(m);最坏情况下时间复杂度O(mn);
%KMP算法:
KMP算法主要消除BF算法中主串指针回溯的问题,从而提高算法效率。
KMP算法思想:设s为目标串,t为模式串,并设i指针和j指针分别指示目标串和模式串中正在比较的字符,令i和j的初始值均为0;若有si=tj,则i和j分别增1,否则,i不变,j退回到j=next[j]的位置(即模式串右滑),比较si和tj,若相等,则指针各增1,否则j再退回到下一个j=next[j]的位置(即模式串继续右滑),再比较si和tj。以此类推,知道出现以下两种情况之一:一是j退回到某个j=next[j]位置时有si=tj,则指针各增1后继续匹配;二是j退回到j=-1,此时令i、j指针各增1,即从si+1和t0开始继续匹配。
next数组的解释如下:
KMP算法匹配过程如下:
复杂度分析:
设主串s的长度为n,子串t的长度为m,在KMP算法中求next数组的时间复杂度为O(n),在之后的匹配中主串s的下标i不回溯,比较次数为n,所以KMP算法的时间复杂度为O(n+m)。

相关文章推荐
- [经典]技术面试宝典: 很全面的算法和数据结构知识(含代码)
- 算法与数据结构之树形结构的相关知识,简单易懂。
- 全面的算法和数据结构知识(含代码实现)
- 各种数据结构与算法知识入门经典
- 数据结构和算法学习——1 预备知识
- 算法和数据结构知识
- 数据结构和算法学习第2天:栈的相关知识
- 数据结构--读书笔记一(算法和数据结构的大纲性知识)
- Android各种知识图(6):算法和数据结构
- [经典]技术面试宝典: 很全面的算法和数据结构知识(含代码)
- 很全面的算法和数据结构知识(含代码实现)
- 数据结构和算法学习第3天:队列的相关知识
- C语言数据结构----算法基本知识和静态表
- 数据结构&&算法基础知识
- 算法和数据结构常考知识汇总--链接
- [心得]算法和数据结构Ellis Horowitz大神知识整理
- (一)算法与数据结构的准备知识
- 算法与数据结构之堆的相关知识,简单易懂。
- 数据结构的基本知识、算法
- 技术面试宝典: 很全面的算法和数据结构知识(含代码)