MySQL数据存储结构
2017-07-15 17:36
106 查看
第一部分:存储引擎及存储结构
记住:每个索引就是一个B-treeMysql最重要的两个存储引擎是:
MyISAM:
1、不支持事物:无法回滚
因此,无法在崩溃后安全恢复
2、不支持聚簇索引(数据存储方式不同):数据不能保存在索引中,单独存储
3、不支持行锁:
4、select count(*),不需要扫描整个表,数值直接获取
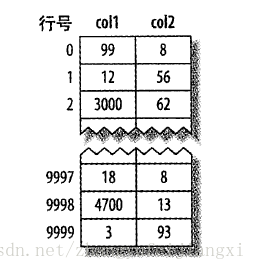
存储结构:
数据保存在连续的内存中,如果没有行号,还会隐式加上行号,结构如下图:
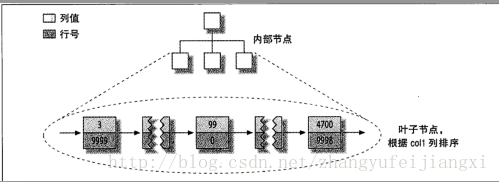
主键索引:主键列值+行号
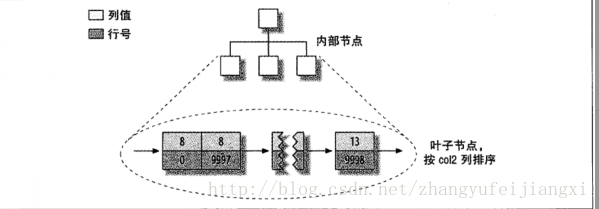
二次索引:索引列值+行号,和主键索引没多大区别
Inodb:
1、支持事物:崩溃后可以安全恢复
2、支持聚簇,只能有一个聚簇索引,一般是主键
3、支持行锁
4、select count(*) 要扫描整个表
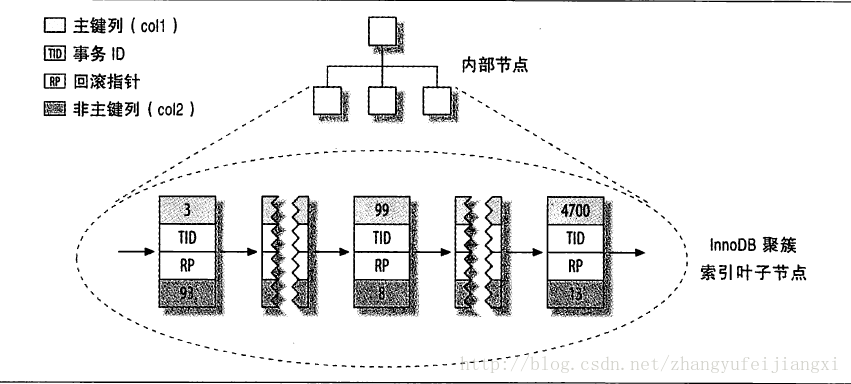
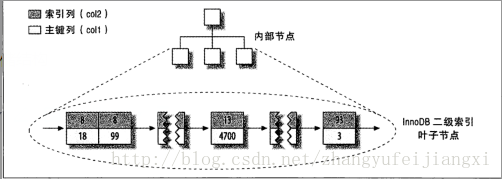
存储结构:
数据是存储在主键索引里面的,记住,每个索引就是一个B-tree
主键列值
事物ID
回滚指针
其他列值(所以查到主键索引就能找到整行的数据)
二次索引:
索引列值+主键列值
所以按照索引查找可以先找到主键列,再去回表找到主键索引,返回整行数据
第二部分:B-tree与哈希索引的区别
B-tree的索引是按照顺序存储的,所以,如果按照B-tree索引,可以直接返回,带顺序的数据,但这个数据只是该索引列含有的信息。因此是顺序I/O适用于:
精确匹配
范围匹配
最左匹配
Hash索引:
索引列值的哈希值+数据行指针:因此找到后还需要根据指针去找数据,造成随机I/O
适合:
精确匹配
不适合:
模糊匹配
范围匹配
不能排序
摘抄其他人的的总结:
1、hash索引仅满足“=”、“IN”和“<=>”查询,不能使用范围查询
因为hash索引比较的是经常hash运算之后的hash值,因此只能进行等值的过滤,不能基于范围的查找,因为经过hash算法处理后的hash值的大小关系,并不能保证与处理前的hash大小关系对应。
2、hash索引无法被用来进行数据的排序操作
由于hash索引中存放的都是经过hash计算之后的值,而hash值的大小关系不一定与hash计算之前的值一样,所以数据库无法利用hash索引中的值进行排序操作。
3、对于组合索引,Hash 索引在计算 Hash 值的时候是组合索引键合并后再一起计算 Hash 值,而不是单独计算 Hash 值,所以通过组合索引的前面一个或几个索引键进行查询的时候,Hash 索引也无法被利用。
4、Hash 索引遇到大量Hash值相等的情况后性能并不一定就会比B-Tree索引高。
对于选择性比较低的索引键,如果创建 Hash 索引,那么将会存在大量记录指针信息存于同一个 Hash 值相关联。这样要定位某一条记录时就会非常麻烦,会浪费多次表数据的访问,而造成整体性能低下。
总结:哈希适用在小范围的精确查找,在列数据很大,又不需要排序,不需要模糊查询,范围查询时有用

相关文章推荐
- Mysql MYISAM存储引擎 数据存储结构
- mysql 利用mysqldump 导入导出表结构、数据、存储过程及函数
- mysql字段存储json结构数据,按照某个属性排序
- MySql的sql语句中添加存储过程或者存储函数来实现Oracle中的start with ……connect by prior……递归(树形结构数据)查询
- 关于mysql中数据存储复合树形结构,查询时结果按树形结构输出
- mysql存储树形结构的数据
- 一个MySQL清除数据库所有表数据保留表结构的存储过程
- Mac下MySQL的位置和内容结构,存储数据的目录
- ubuntu-16.04更改mysql默认数据存储目录
- 数据结构——线性表之链表存储学习
- 数据结构之线性表的几种主要存储
- (大数据之hive)hive利用mysql存储metastore
- 哈希表存储数据结构原理
- Mysql inndodb 存储引擎的简单总结(组成结构,锁,事务,备份,优化)
- 数据库学习篇之数据存储引擎(mysql)
- 关于删除mysql大表数据并释放存储空间的两种方式
- Mysql 切换数据存储目录
- mysql mysqldump只导出表结构或只导出数据的实现方法
- MySQL存储引擎和数据类型
- Mysql通过Adjacency List(邻接表)存储树形结构