ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices的理解
2017-07-14 23:01
549 查看
前沿
加速方法
Channel Shuffle for Group Convolutions
ShuffleNet单元
网络结构
实验对比
Github实现
ShuffleNet主要是在计算方法上做了创新,提出了pointwise group convolution和channel shuffle两个操作来减少计算量,使得计算量在10~150 MFLOPS次操作。该文作者训练了ImageNet和MS COCO这两个训练集,说明该方法还不错,可以在大数据集上进行训练,有较高的可用性。相比于MobileNet在ImageNet top1上高了6.7%。然后在ARM平台上,计算性能上是AlexNet(5层卷机,3层全连接)的13倍,需要40 MFLOPS的计算量。看来该论文主要是做模型加速而不是走压缩的路线,毕竟BianryNet出来了,都是1bit了。再做压缩要么改网络要么做去除网络一部分,这些改进竞争也是极大的。之前不少人针对现成的网络已经做了很多优化,做模型参数的压缩、参数浮点量化、pruning(去掉一些不重要的activation,值为0。比如activation小于某个阈值就认为对整个网络没有印象。后来很多论文开始把bias去掉了)那我感觉这篇论文是在计算结构和内存设计上进行的优化,在这方面的设计,其实有很多人做了不少工作。后面找个时间我总结这方面的东西。这篇论文相比于ResNext和Xception的优势在于,ShuffleNet更适合在很小的卷积核的网络比如1x1这样的网络。总体上这篇论文还是有不少可圈可点的工作。
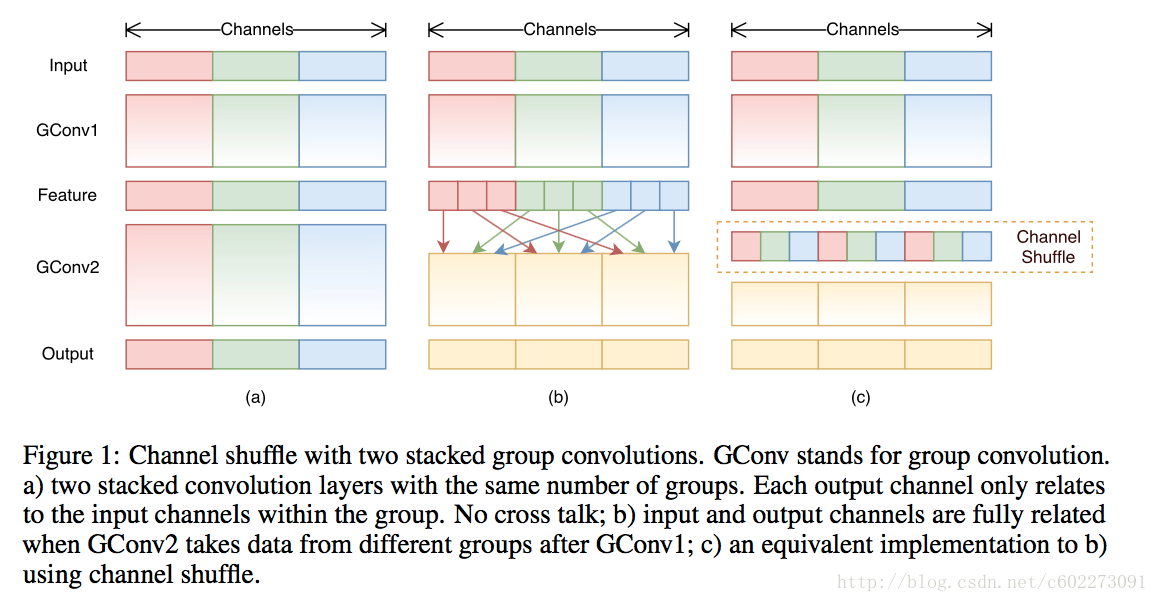
为了提高pointwise convolution的速度,最简单的方法就是在pointwise convolution采用group convolution,如下图中的一所示。但是这样会有问题,主要是pointwise convolution在进行group convolution以后,很容易出现欠拟合,导致精度下降。为了解决这个问题,采用了通道间混叠的方法,其实你看LeNet-5的做法就是这样的。采用的就是输入的feature map选取部分隐射到输出的feature map上。这样的通道交错的话,就可以使得输出的激励得到全局网络的影响而不是局部的影响。如下图中的b。但是这样会有问题,就是这么做的话,网络是全连接,就是我们计算输出的时候,我们要把整个input feature导入,这是很大的内存,频繁的内存交互,是很消耗时间的。为了解决这个全连接的问题,进行一个shuffle(借鉴了AlexNet训练时候的方法)把输入的feature map实现进行排列,然后计算输出的feature map的时候,只要导入需要的输入的feature map而不是进行全局索引。大大提高了cache hit率。速度大大提高。
论文中提到了这种方法还适合group 不一样多的时候,并且shuffle是可微的,所以可以进行端到端的训练(具体怎么计算不太清楚了)
注:
group convolution:指的是计算feature map的时候,feature map分在不同的地方计算,比如两个GPU上。然后这两块GPU上的feature map分成支路做卷积,最后汇合(其实就是AlexNet的做法,AlexNet也是局限于GPU的性能)
Depthwise separable convolution:是在Inception层进行卷积分割。Xinception最早提出,然后MobileNet也采用了这种做法。
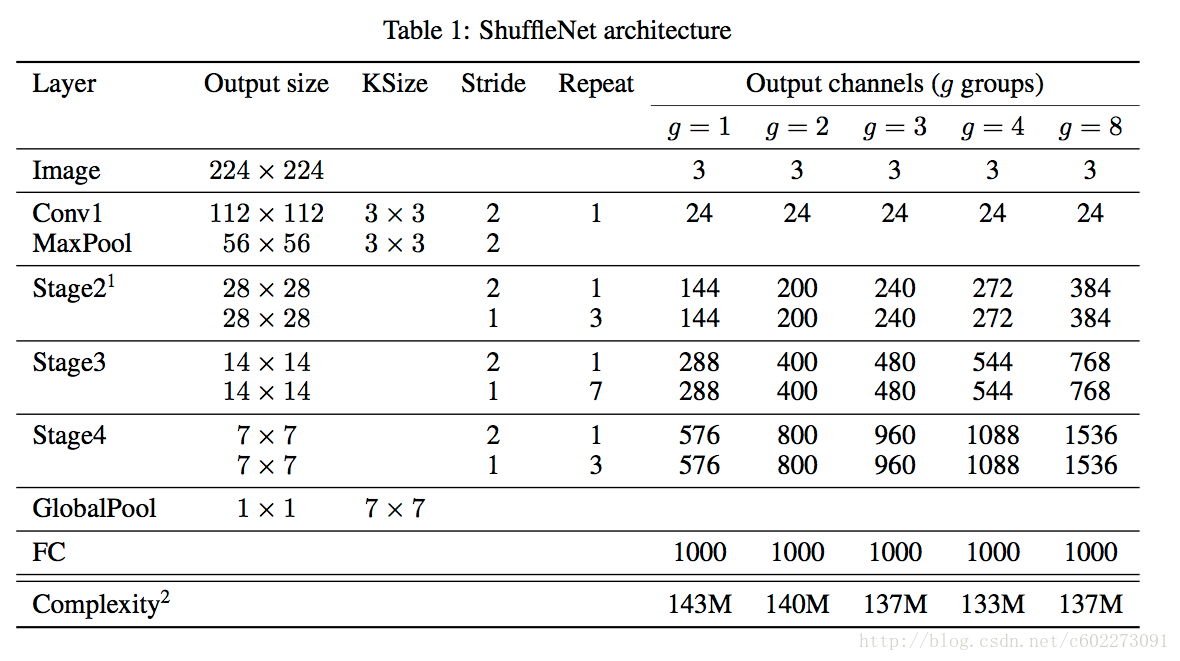
每个阶段开始的stride都是2,后面一个是1。输出的channel都是越来越大,其实整个网络感觉和ResNet差别不大。
另外为了比较不同的channel对accuracy的影响,这里又有一个scale factor,sx表示channel数目是1x的s倍。
所以理论上,sx的计算量是1x的s2。
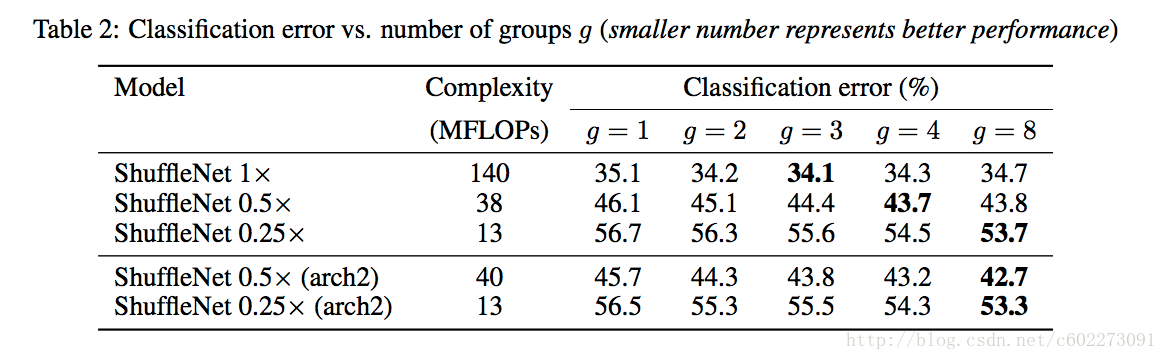
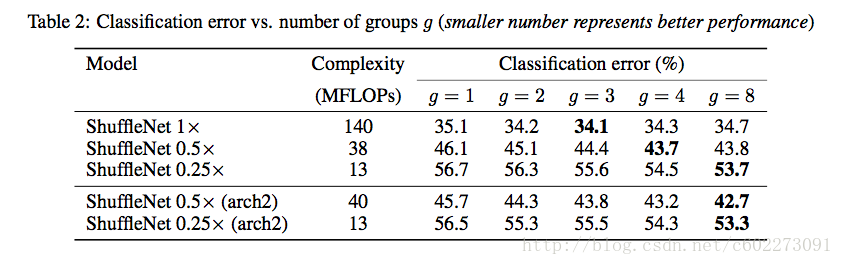
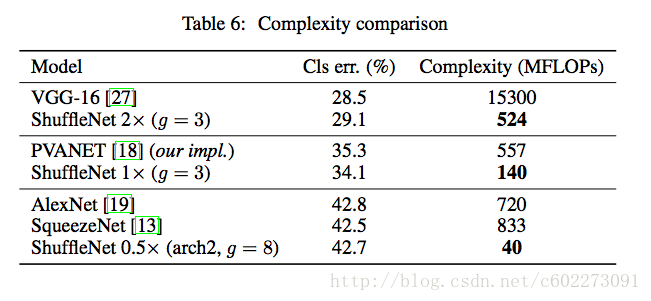
pointwise group convolution这部分对模型准确度的影响:主要是g和?x对其精度的影响。g越大,准确度先变大后减少。新的arch2对模型确实有提高精度。
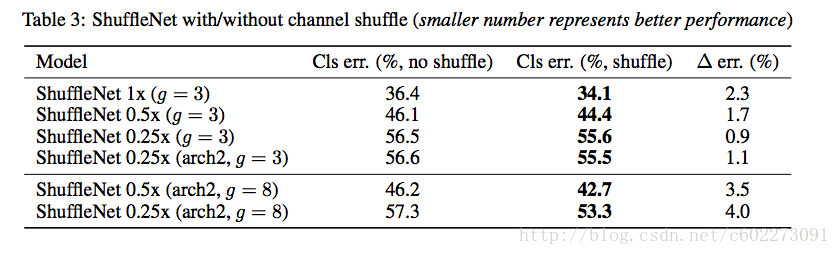
channel shuffle的作用:与没有shuffle的网络进行精读对比,发现进行shuffle的精度更高。
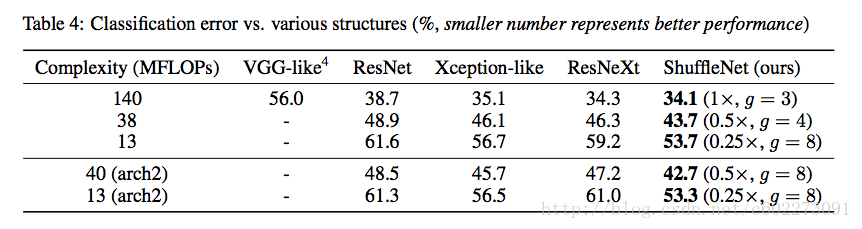
比较计算单元的对classification的准确度的影响:将ShuffleNet的Stage2~4换成别的计算单元再计算需要的计算量。在同样的计算量情况下,ShuffleNet有最高的准确度。
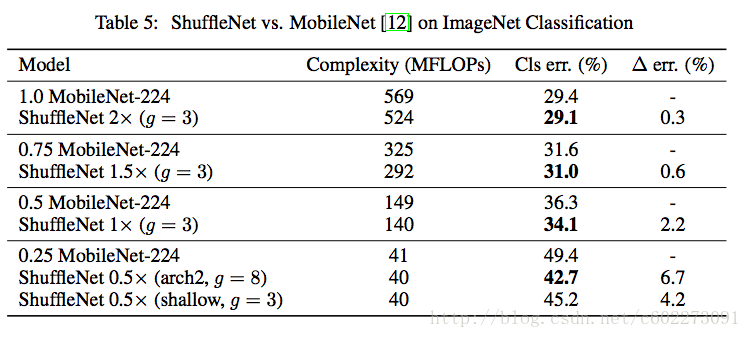
ShuffleNet和MobileNets、PVANET、SqueezeNet进行对比:
对于ShuffleNet在迁移学习方面的方面的性能,用的是MS COCO做训练和测试。做的是目标检测~ 测试指标是mAP,就是检测的重叠面积。ShuffleNet 2x更加高,和MobileNet接近的计算量。

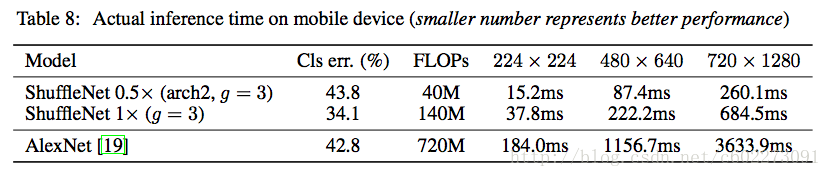
在ARM平台上,做的是classification,该论文对不同分辨率的图片、不同的模型进行测试所需的操作数量、时间和精度。处理224x224的图片只要15.2 ms,在嵌入式平台这个结果已经非常优秀。
【1】实现一:https://github.com/HolmesShuan/ShuffleNet-An-Extremely-Efficient-CNN-for-Mobile-Devices-Caffe-Reimplementation
【2】实现二:https://github.com/camel007/Caffe-ShuffleNet
论文下载:https://arxiv.org/pdf/1707.01083.pdf
额外的解说资料:
【3】http://baijiahao.baidu.com/s?id=1572512027246277
【4】https://www.zhihu.com/question/62243686
转载请注明出处:http://blog.csdn.net/c602273091/article/details/75137878
加速方法
Channel Shuffle for Group Convolutions
ShuffleNet单元
网络结构
实验对比
Github实现
前沿
随着近几年AI算法爆发式的发展,越来越多的运用场景出现了。为了让更多的算法落地,如何做移动端的模型加速和模型压缩成了近期的一个热点。比如前一段做参数量化的BinaryNet、Google出的GoogleNet,到现在Face++出的ShuffleNet。这个趋势应该还会继续。模型压缩,一方面需要保证模型的精度、另外一方面需要减少模型的存储量。这次我就主要解释一下ShuffleNet,它的网络结构以及它的实验结果。ShuffleNet主要是在计算方法上做了创新,提出了pointwise group convolution和channel shuffle两个操作来减少计算量,使得计算量在10~150 MFLOPS次操作。该文作者训练了ImageNet和MS COCO这两个训练集,说明该方法还不错,可以在大数据集上进行训练,有较高的可用性。相比于MobileNet在ImageNet top1上高了6.7%。然后在ARM平台上,计算性能上是AlexNet(5层卷机,3层全连接)的13倍,需要40 MFLOPS的计算量。看来该论文主要是做模型加速而不是走压缩的路线,毕竟BianryNet出来了,都是1bit了。再做压缩要么改网络要么做去除网络一部分,这些改进竞争也是极大的。之前不少人针对现成的网络已经做了很多优化,做模型参数的压缩、参数浮点量化、pruning(去掉一些不重要的activation,值为0。比如activation小于某个阈值就认为对整个网络没有印象。后来很多论文开始把bias去掉了)那我感觉这篇论文是在计算结构和内存设计上进行的优化,在这方面的设计,其实有很多人做了不少工作。后面找个时间我总结这方面的东西。这篇论文相比于ResNext和Xception的优势在于,ShuffleNet更适合在很小的卷积核的网络比如1x1这样的网络。总体上这篇论文还是有不少可圈可点的工作。
加速方法
Channel Shuffle for Group Convolutions
针对ResneXt和Xception的不足,ShuffleNet在pointwise convolution(也就是1x1的kernel的卷积)进行了优化。ResneXt和Xception是在3x3的kernel上做了group convolution,但是没有在1x1的网络做,结果大部分的乘法就出现在了1x1(占93.4%)同时大量的运算导致计算受局限,进而精度会损失。为了提高pointwise convolution的速度,最简单的方法就是在pointwise convolution采用group convolution,如下图中的一所示。但是这样会有问题,主要是pointwise convolution在进行group convolution以后,很容易出现欠拟合,导致精度下降。为了解决这个问题,采用了通道间混叠的方法,其实你看LeNet-5的做法就是这样的。采用的就是输入的feature map选取部分隐射到输出的feature map上。这样的通道交错的话,就可以使得输出的激励得到全局网络的影响而不是局部的影响。如下图中的b。但是这样会有问题,就是这么做的话,网络是全连接,就是我们计算输出的时候,我们要把整个input feature导入,这是很大的内存,频繁的内存交互,是很消耗时间的。为了解决这个全连接的问题,进行一个shuffle(借鉴了AlexNet训练时候的方法)把输入的feature map实现进行排列,然后计算输出的feature map的时候,只要导入需要的输入的feature map而不是进行全局索引。大大提高了cache hit率。速度大大提高。
论文中提到了这种方法还适合group 不一样多的时候,并且shuffle是可微的,所以可以进行端到端的训练(具体怎么计算不太清楚了)
ShuffleNet单元
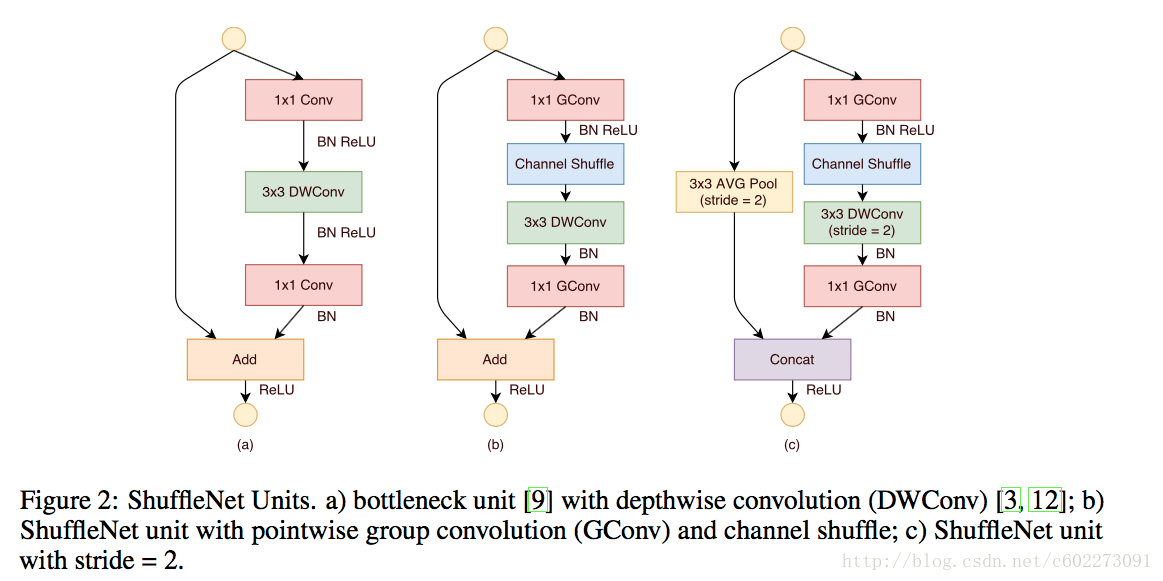
这个单元设计大的基础还是ResNet-18的,下图中的a。ShuffleNet的改进就是在做完第一个1x1的Group Convolution以后,增加了一个shuffle单元。接着是3x3的depthwise convolution的算法。后面还有一个1x1的卷积是为了把feature map size从3x3恢复为1x1。接着是在BN和ReLU方面也如下图做了改进。如果是stride大于1的话,那么增加了一个average pooling和改变了element wise add为通道连接(concatenation我理解的是两个数字连在一起)注:
group convolution:指的是计算feature map的时候,feature map分在不同的地方计算,比如两个GPU上。然后这两块GPU上的feature map分成支路做卷积,最后汇合(其实就是AlexNet的做法,AlexNet也是局限于GPU的性能)
Depthwise separable convolution:是在Inception层进行卷积分割。Xinception最早提出,然后MobileNet也采用了这种做法。
网络结构
整个网络结构如下:每个阶段开始的stride都是2,后面一个是1。输出的channel都是越来越大,其实整个网络感觉和ResNet差别不大。
另外为了比较不同的channel对accuracy的影响,这里又有一个scale factor,sx表示channel数目是1x的s倍。
所以理论上,sx的计算量是1x的s2。
实验对比
参数设置上weight decay是4e-5;另外由于小网络容易欠拟合,所以做了微小的图片augmentation工作。图片的输入是256x256中的224x224的中间区域。pointwise group convolution这部分对模型准确度的影响:主要是g和?x对其精度的影响。g越大,准确度先变大后减少。新的arch2对模型确实有提高精度。
channel shuffle的作用:与没有shuffle的网络进行精读对比,发现进行shuffle的精度更高。
比较计算单元的对classification的准确度的影响:将ShuffleNet的Stage2~4换成别的计算单元再计算需要的计算量。在同样的计算量情况下,ShuffleNet有最高的准确度。
ShuffleNet和MobileNets、PVANET、SqueezeNet进行对比:
对于ShuffleNet在迁移学习方面的方面的性能,用的是MS COCO做训练和测试。做的是目标检测~ 测试指标是mAP,就是检测的重叠面积。ShuffleNet 2x更加高,和MobileNet接近的计算量。
在ARM平台上,做的是classification,该论文对不同分辨率的图片、不同的模型进行测试所需的操作数量、时间和精度。处理224x224的图片只要15.2 ms,在嵌入式平台这个结果已经非常优秀。
Github实现
可以跑一跑,在自己的平台做些测试,能够得到更加准确的数据。【1】实现一:https://github.com/HolmesShuan/ShuffleNet-An-Extremely-Efficient-CNN-for-Mobile-Devices-Caffe-Reimplementation
【2】实现二:https://github.com/camel007/Caffe-ShuffleNet
论文下载:https://arxiv.org/pdf/1707.01083.pdf
额外的解说资料:
【3】http://baijiahao.baidu.com/s?id=1572512027246277
【4】https://www.zhihu.com/question/62243686
转载请注明出处:http://blog.csdn.net/c602273091/article/details/75137878

相关文章推荐
- Reading Note: ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
- 论文阅读笔记:ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
- ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
- ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
- [论文解读] ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
- MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications个人理解
- Reading Note: MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
- MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
- MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
- 【论文学习】MobileNets:Efficient Convolutional Neural Networks for Mobile Vision Applications
- [论文解读] MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
- MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
- [论文阅读]MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
- DeepID-Net:multi-stage and deformable deep convolutional neural network for object detection
- 使用TrustZone技术的移动终端匿名认证协议论文PPT:DAA-TZ: An Efficient DAA Scheme for Mobile Devices using ARM TrustZone
- 网络量化——Quantized Convolutional Neural Networks for Mobile Devices
- 深度学习研究理解4:ImageNet Classification with Deep Convolutional Neural Network
- 论文记录_MobileNets Efficient Convolutional Neural Networks for Mobile Vision Application
- ABC-CNN: An Attention Based Convolutional Neural Network for Visual Question Answering
- MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications