【OpenStack源码分析之一】初探OpenStack
2017-07-12 20:52
323 查看
打算开始写一个Openstack的分析系列,其实接触Openstack也比较久了,但是一直没有深入了解,而且因为本人对Python知之甚少,用之甚少,所以想研究Openstack的代码上手就会比较困难,再加上代码量也比较大。
不过还是打算下定决心做一个系列的分析,不会全部看,大概只看NOVA和Neutron两个模块,而且按照我的认知习惯,还是先要了解全局再去深入细节,所以头几篇分析都会集中在What, Why以及How上来看,重点是怎么用,解决方案是什么。
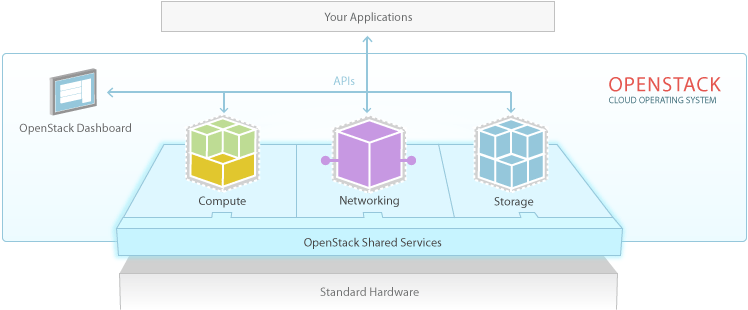
在Openstack的官方网站上对这一点说的非常简单,而且非常好,我先把原文附上:
说Openstack是一个云操作系统,这里我们不免要和Linux做对比,同样作为操作系统,Linux需要做如下几件事情:
资源管理:这里的资源包括CPU,网卡,显卡,内存,硬盘等
进程管理:本质上就是任务的调度,在合适的时间分配合适的资源来执行任务
存储管理:包括文件系统,内存管理等
网络通讯:包括主机协议栈的实现以及虚拟设备的支持
安全问题 …
其实从以上几点我们已经看出同为操作系统,大家都大同小异,都要解决资源的抽象和管理问题,资源的分配和调度问题,和用户的人机交互问题,应用的生命周期管理问题,以及系统的管理维护问题。 不同点在于,OpenStack需要管理更多的资源,它管理的CPU已经不仅仅局限于一台服务器内部的CPU而是整个数据中心的资源;另外作为云服务,很重要的一点就是业务上要支持多租户,虽然Linux是支持多核,多任务的操作系统,可以在一定程度上支持资源隔离。但是在云操作系统这个层面才是真正实现多租户的业务场景。

OpenStack在整个云解决方案中是一个什么样的角色呢?OpenStack在云平台这个大的系统里面也只是一个部件,这个部件的定位就是前面所说的操作系统,以OpenStack为框架,将计算、存储、网络、管理、运营、运维等多个领域的软硬件产品组件整合在一起,共同组成面向业务场景的整体解决方案。OpenStack优先关注控制面:OpenStack优先考虑如何将计算、存储、网络领域的各类资源抽象为资源池。在此基础上,对资源池内的各类逻辑对象实施控制操作,并将控制操作包装成服务。数据面、运维面、管理面目前不是OpenStack的重点关注内容。

鉴于OpenStack的定位,OpenStack社区的核心项目主要都是提供IAAS的服务,也有提供PAAS服务和SAAS服务的项目,但是应用度并不广。
开放性
源代码开放,设计与开发流程开放
“不重复发明轮子”,“站在巨人的肩膀上”,大量使用其他开源软件
不使用任何不可替代的商业产品
灵活
架构可裁减,可以根据实际需要决定选取的组件范围
大量采用驱动与插件机制
通过配置项控制对系统功能特性进行便捷配置
可扩展
松耦合架构,组件间RESTful API通信,组件内消息总线通信
无中心架构,核心组件无中心节点,有效避免单点故障
无状态架构,各组件无本地持久化数据,所有持久化数据保存在数据库中
理想情况下,我们当然希望云计算能够彻底消除地域的影响,就像我们用电的时候不用关心发电厂在哪里一样。但现实显然没有那么美好,不同地域的机房之间的网络还做不到像电网一样透明。所以在云计算产品的最底层,首先需要考虑不同地域的影响。不同地域之间,一般只能通过公网连通,内部之间网络是不通的。当然,对于云计算服务商来说,为管理需要,一般还是会通过有限的带宽来连通不同地域的机房,用于云计算内部资源管理,以及一些特殊的产品场景,比如跨地域的镜像复制。但因为内部带宽有限,一般不会完全开放给用户使用。
所以,地域就是物理意义上的不同地方的机房,这个不同地方,一般来说距离较远,机房之间用光纤直连的成本较高。并且相对来说会在用户需求量较大的地方部署地域机房,比如阿里云的云服务器的地域在境内有杭州,上海,北京,深圳,青岛,海外已经上线的包括香港、硅谷和新加坡。实际上阿里云一开始是没有上海地域的,因为上海杭州距离较近,部署直连光纤的成本也相对可控,阿里内部之前很多应用都是分别部署在杭州和上海,基本上是当作一个地域来使用的,后来可能因为需求大而分开了。
所以,地域很好理解,就是物理上相隔较远的机房,因为跨地域的机房之间的带宽无法满足内网需求,所以不同地域的机器之间内网是不通的。当然,随着骨干网络等物理层基础设施的发展,未来跨地域内网连通并非完全不可能的事情。在这个过程中,公共云计算服务商也可能根据用户的诉求,在某些场景开放一些有限的内部网络带宽来做产品,比如,前面说的阿里云的跨地域镜像复制,以及最近推出来的OSS跨地域复制等。一般来说,在数据和存储领域内的产品会先行支持跨地域的功能,毕竟数据容灾是更强烈的需求。
那么,同一个地域之内又分成多个可用区,为什么要搞这么复杂?原因很简单,IT系统从远古时代就有同城容灾的需求,那使用云计算以后,怎么实现同城跨机房容灾呢?如果用户购买的云服务器无法区分在哪个机房,那么就无法在业务应用层面来设计同城容灾。所以云计算服务商提出了同地域内不同可用区的概念,简单点理解,可以认为就是同城不同机房,云计算服务商会从底层的机房电力/网络等层面仔细设计来保障一个可用区出现故障的时候不会影响到另外一个可用区,当然你要说杭州彻底被钱塘江潮淹没的情况,那可用区也救不了你,要在业务应用层面考虑通过不同的地域来设计异地容灾了。
所以,简单来说,可以将地域理解为不同城市的机房,将可用区理解为同一个城市的不同机房。当然,实际上不同可用区也可能是在同一个机房,可用区的概念严格来说是按照电力和网络设备等相互独立来设计的。同一个地域内的不同可用区之间,内网是连通的,但是网络的响应时间会有差异。下面是我用阿里云杭州地域做的一次ping的测试,来观察同地域不同可用区之间的网络情况。
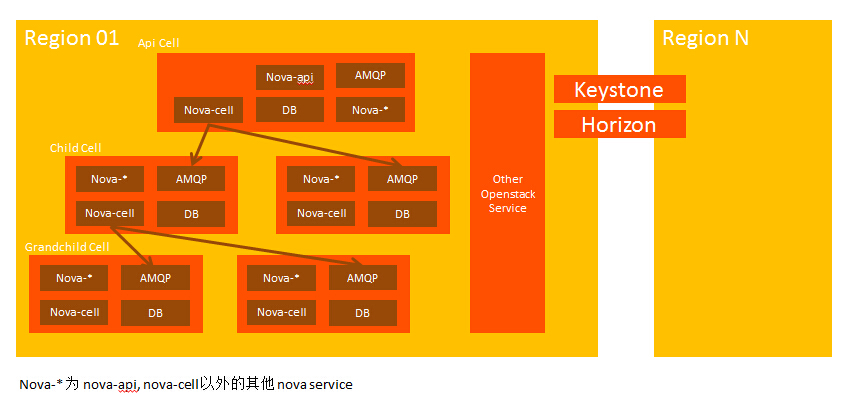
OpenStack在AWS的基础上又引入了Cell 和 Host Aggregates Zone(HAZ) 两个概念,其中 Cell 是为了扩充一个 Region 下的集群的规模而引入的,Host Aggregates 是优化资源调度和利用引入的。

官网手册提到 Cell 不成熟(Considered experimental),巴黎峰会也提到 Cell 的痛点,虽然现在已进入 K 版本迭代开发中了,但是本人还未听说业界成熟使用 Cell 的案例。关于 Cell 更详细的介绍,请参考以下链接
http://www.ibm.com/developerworks/cn/cloud/library/1409_zhaojian_openstacknovacell/index.html
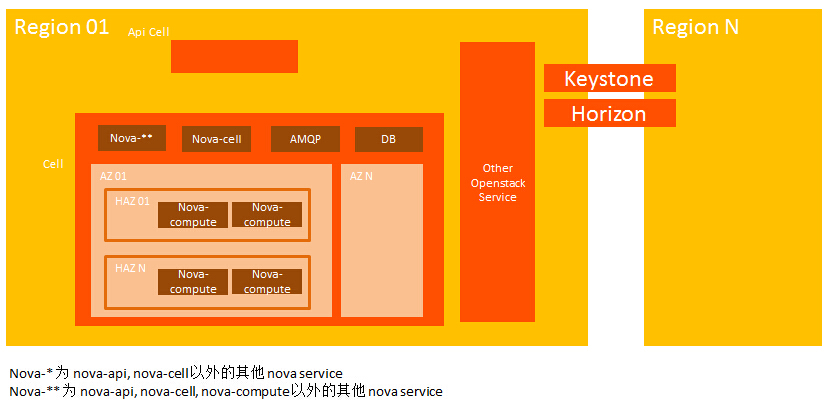
AWS 每个 Region 下有多个 AZ。Openstack 也引入了 AZ 的概念,我个人理解 AZ 的引入是基于可靠性的角度考虑,比如我们定义一个机房为一个 AZ,把该机房所有计算节点纳入到一个 AZ 中,其中一个机房因为某种原因down 掉,不会影响其它机房的虚拟机和网络;同时, AZ 对用户来说是一个可见的概念,用户创建虚拟机时,可以明确指出在哪个 AZ,用户可以通过在多个 AZ 创建虚拟机来保证高可靠性。
HAZ 也是把一批具有共同属性的计算节点划分到同一个 Zone 中,HAZ 可以对 AZ 进一步细分,一个 AZ 可以有多个 HAZ。 同一个 HAZ 下的机器都具有某种共同的属性,比如高性能计算,高性能存储(SSD),高性能网络(支持SRIOV等)。HAZ 和 AZ 另一个不同之处在于 HAZ 对用户不是明确可见的,用户在创建虚拟机时不能像指定 AZ 一样直接指定 HAZ,但是可以通过在 Instance Flavor 中设置相关属性,由 nova-scheduler 调度根据该调度策略调度到满足该属性的的 Host Aggregates Zones 中。
那么,同一个地域之内又分成多个可用区,为什么要搞这么复杂?原因很简单,IT系统从远古时代就有同城容灾的需求,那使用云计算以后,怎么实现同城跨机房容灾呢?如果用户购买的云服务器无法区分在哪个机房,那么就无法在业务应用层面来设计同城容灾。所以云计算服务商提出了同地域内不同可用区的概念,简单点理解,可以认为就是同城不同机房,云计算服务商会从底层的机房电力/网络等层面仔细设计来保障一个可用区出现故障的时候不会影响到另外一个可用区,当然你要说杭州彻底被钱塘江潮淹没的情况,那可用区也救不了你,要在业务应用层面考虑通过不同的地域来设计异地容灾了。
所以,简单来说,可以将地域理解为不同城市的机房,将可用区理解为同一个城市的不同机房。当然,实际上不同可用区也可能是在同一个机房,可用区的概念严格来说是按照电力和网络设备等相互独立来设计的。同一个地域内的不同可用区之间,内网是连通的,但是网络的响应时间会有差异。在阿里云杭州地域做的一次ping的测试,来观察同地域不同可用区之间的网络情况,发现同可用区之间的内网是连通的,但响应时间比同一个可用区之内要慢1ms多。所以,在实际应用中,如果需要考虑同城容灾或者同城双活,需要尽量将应用和数据库分布部署在不同的可用区。如果对响应时间高度敏感,则建议部署在同一个可用区内。在购买云服务器和数据库的时候,要注意选择了。
参考文献:
http://blog.csdn.net/u010305706/article/details/54406060
不过还是打算下定决心做一个系列的分析,不会全部看,大概只看NOVA和Neutron两个模块,而且按照我的认知习惯,还是先要了解全局再去深入细节,所以头几篇分析都会集中在What, Why以及How上来看,重点是怎么用,解决方案是什么。
What is OpenStack
在Openstack的官方网站上对这一点说的非常简单,而且非常好,我先把原文附上:
OpenStack is a cloud operating system that controls large pools of compute, storage, and networking resources throughout a datacenter, all managed through a dashboard that gives administrators control while empowering their users to provision resources through a web interface.
说Openstack是一个云操作系统,这里我们不免要和Linux做对比,同样作为操作系统,Linux需要做如下几件事情:
资源管理:这里的资源包括CPU,网卡,显卡,内存,硬盘等
进程管理:本质上就是任务的调度,在合适的时间分配合适的资源来执行任务
存储管理:包括文件系统,内存管理等
网络通讯:包括主机协议栈的实现以及虚拟设备的支持
安全问题 …
其实从以上几点我们已经看出同为操作系统,大家都大同小异,都要解决资源的抽象和管理问题,资源的分配和调度问题,和用户的人机交互问题,应用的生命周期管理问题,以及系统的管理维护问题。 不同点在于,OpenStack需要管理更多的资源,它管理的CPU已经不仅仅局限于一台服务器内部的CPU而是整个数据中心的资源;另外作为云服务,很重要的一点就是业务上要支持多租户,虽然Linux是支持多核,多任务的操作系统,可以在一定程度上支持资源隔离。但是在云操作系统这个层面才是真正实现多租户的业务场景。
OpenStack能做什么
OpenStack当前在私有云的解决方案更多,基于OpenStack做公有云的还比较少,而且近些年用OpenStack做公有云的公司有越来越多的撤出的趋势,另外是托管云,像Rackspace等传统IDC厂商开始提供此类服务,12%的受访者通过合约委托服务供应商托管专属的OpenStack部署,借此帮助客户省略繁琐的管理问题。其实还有一个大的市场没有没计入,这就是电信云,随着近些年NFV的兴起,电信运营商也开始大规模投入希望完成网络业务云化转型。这里面以AT&T, 中国移动为首。OpenStack在整个云解决方案中是一个什么样的角色呢?OpenStack在云平台这个大的系统里面也只是一个部件,这个部件的定位就是前面所说的操作系统,以OpenStack为框架,将计算、存储、网络、管理、运营、运维等多个领域的软硬件产品组件整合在一起,共同组成面向业务场景的整体解决方案。OpenStack优先关注控制面:OpenStack优先考虑如何将计算、存储、网络领域的各类资源抽象为资源池。在此基础上,对资源池内的各类逻辑对象实施控制操作,并将控制操作包装成服务。数据面、运维面、管理面目前不是OpenStack的重点关注内容。
鉴于OpenStack的定位,OpenStack社区的核心项目主要都是提供IAAS的服务,也有提供PAAS服务和SAAS服务的项目,但是应用度并不广。
OpenStack的设计思想
OpenStack在设计初期就是对标AWS,很多项目在AWS上都能找到对应的模块,但是在设计思想上其秉承着开放,灵活,可扩展的原则。开放性
源代码开放,设计与开发流程开放
“不重复发明轮子”,“站在巨人的肩膀上”,大量使用其他开源软件
不使用任何不可替代的商业产品
灵活
架构可裁减,可以根据实际需要决定选取的组件范围
大量采用驱动与插件机制
通过配置项控制对系统功能特性进行便捷配置
可扩展
松耦合架构,组件间RESTful API通信,组件内消息总线通信
无中心架构,核心组件无中心节点,有效避免单点故障
无状态架构,各组件无本地持久化数据,所有持久化数据保存在数据库中
OpenStack的部署
云计算的理念是在可以网络接入的地方像用水用电一样随时获取计算资源并且按需使用和付费。亚马逊AWS是公共云计算的先驱,一些云计算中重要的产品设计和基础概念可以说都是亚马逊引入的。这其中有两个非常重要的概念:地域(Region)和可用区(AZ:Available Zone)。很多第一次接触云计算的同学,光看这两个名字的字面意义,虽然也能够猜出大致的意思,但深入的学习了解云计算一段时间之后,才能深刻的体会这两个概念对于云计算的重要影响。包括国内的这些云计算服务商,也是过了很长时间才陆续在产品中引入可用区的设计的。理想情况下,我们当然希望云计算能够彻底消除地域的影响,就像我们用电的时候不用关心发电厂在哪里一样。但现实显然没有那么美好,不同地域的机房之间的网络还做不到像电网一样透明。所以在云计算产品的最底层,首先需要考虑不同地域的影响。不同地域之间,一般只能通过公网连通,内部之间网络是不通的。当然,对于云计算服务商来说,为管理需要,一般还是会通过有限的带宽来连通不同地域的机房,用于云计算内部资源管理,以及一些特殊的产品场景,比如跨地域的镜像复制。但因为内部带宽有限,一般不会完全开放给用户使用。
所以,地域就是物理意义上的不同地方的机房,这个不同地方,一般来说距离较远,机房之间用光纤直连的成本较高。并且相对来说会在用户需求量较大的地方部署地域机房,比如阿里云的云服务器的地域在境内有杭州,上海,北京,深圳,青岛,海外已经上线的包括香港、硅谷和新加坡。实际上阿里云一开始是没有上海地域的,因为上海杭州距离较近,部署直连光纤的成本也相对可控,阿里内部之前很多应用都是分别部署在杭州和上海,基本上是当作一个地域来使用的,后来可能因为需求大而分开了。
所以,地域很好理解,就是物理上相隔较远的机房,因为跨地域的机房之间的带宽无法满足内网需求,所以不同地域的机器之间内网是不通的。当然,随着骨干网络等物理层基础设施的发展,未来跨地域内网连通并非完全不可能的事情。在这个过程中,公共云计算服务商也可能根据用户的诉求,在某些场景开放一些有限的内部网络带宽来做产品,比如,前面说的阿里云的跨地域镜像复制,以及最近推出来的OSS跨地域复制等。一般来说,在数据和存储领域内的产品会先行支持跨地域的功能,毕竟数据容灾是更强烈的需求。
那么,同一个地域之内又分成多个可用区,为什么要搞这么复杂?原因很简单,IT系统从远古时代就有同城容灾的需求,那使用云计算以后,怎么实现同城跨机房容灾呢?如果用户购买的云服务器无法区分在哪个机房,那么就无法在业务应用层面来设计同城容灾。所以云计算服务商提出了同地域内不同可用区的概念,简单点理解,可以认为就是同城不同机房,云计算服务商会从底层的机房电力/网络等层面仔细设计来保障一个可用区出现故障的时候不会影响到另外一个可用区,当然你要说杭州彻底被钱塘江潮淹没的情况,那可用区也救不了你,要在业务应用层面考虑通过不同的地域来设计异地容灾了。
所以,简单来说,可以将地域理解为不同城市的机房,将可用区理解为同一个城市的不同机房。当然,实际上不同可用区也可能是在同一个机房,可用区的概念严格来说是按照电力和网络设备等相互独立来设计的。同一个地域内的不同可用区之间,内网是连通的,但是网络的响应时间会有差异。下面是我用阿里云杭州地域做的一次ping的测试,来观察同地域不同可用区之间的网络情况。
OpenStack在AWS的基础上又引入了Cell 和 Host Aggregates Zone(HAZ) 两个概念,其中 Cell 是为了扩充一个 Region 下的集群的规模而引入的,Host Aggregates 是优化资源调度和利用引入的。
Region的部署
顾名思义,Region 直译过来就是区域,地域的概念,而事实上,AWS 按地域(国家或者城市)设置一个 Region,每个 Region 下有多个 Availability Zone。Openstack 同样支持 Region 的概念,支持全球化部署,比如为了降低网络延时,用户可以选择特定的 Region 来部署服务。各个 Region 之间的计算资源、网络资源、存储资源都是独立的,但所有 Region 共享账户用户信息,因为 Keystone 是实现 openstack 租户用户管理和认证的功能的组件,所以 Keystone 全局唯一,所有 Region 共享一个 Keystone,Keystone endpoint 中存储了访问各个 Region 的 URL。Cell的部署
Cell 概念的引入,是为了扩充单个 Region 下的集群规模,主要解决 AMQP 和 Database 的性能瓶颈,每个 Region 下的 openstack 集群都有自己的消息中间件和数据库,当计算节点达到一定规模(和IBM,easystack,华为等交流的数据是300~500),消息中间件就成为了扩展计算节点的性能瓶颈。Cell 的引入就是为了解决单个 Region 的规模问题,每个 Region 下可以有多个 Cell,每个 Cell 维护自己的数据库和消息中间件,所有 Cell 共享本 Region 下的 nova-api,共享全局唯一的 Keystone。官网手册提到 Cell 不成熟(Considered experimental),巴黎峰会也提到 Cell 的痛点,虽然现在已进入 K 版本迭代开发中了,但是本人还未听说业界成熟使用 Cell 的案例。关于 Cell 更详细的介绍,请参考以下链接
http://www.ibm.com/developerworks/cn/cloud/library/1409_zhaojian_openstacknovacell/index.html
Availability Zone & Host Aggregates Zone
之所以把 AZ 和 HAZ 放到一同分析,是因为二者的概念实在类似。AWS 每个 Region 下有多个 AZ。Openstack 也引入了 AZ 的概念,我个人理解 AZ 的引入是基于可靠性的角度考虑,比如我们定义一个机房为一个 AZ,把该机房所有计算节点纳入到一个 AZ 中,其中一个机房因为某种原因down 掉,不会影响其它机房的虚拟机和网络;同时, AZ 对用户来说是一个可见的概念,用户创建虚拟机时,可以明确指出在哪个 AZ,用户可以通过在多个 AZ 创建虚拟机来保证高可靠性。
HAZ 也是把一批具有共同属性的计算节点划分到同一个 Zone 中,HAZ 可以对 AZ 进一步细分,一个 AZ 可以有多个 HAZ。 同一个 HAZ 下的机器都具有某种共同的属性,比如高性能计算,高性能存储(SSD),高性能网络(支持SRIOV等)。HAZ 和 AZ 另一个不同之处在于 HAZ 对用户不是明确可见的,用户在创建虚拟机时不能像指定 AZ 一样直接指定 HAZ,但是可以通过在 Instance Flavor 中设置相关属性,由 nova-scheduler 调度根据该调度策略调度到满足该属性的的 Host Aggregates Zones 中。
那么,同一个地域之内又分成多个可用区,为什么要搞这么复杂?原因很简单,IT系统从远古时代就有同城容灾的需求,那使用云计算以后,怎么实现同城跨机房容灾呢?如果用户购买的云服务器无法区分在哪个机房,那么就无法在业务应用层面来设计同城容灾。所以云计算服务商提出了同地域内不同可用区的概念,简单点理解,可以认为就是同城不同机房,云计算服务商会从底层的机房电力/网络等层面仔细设计来保障一个可用区出现故障的时候不会影响到另外一个可用区,当然你要说杭州彻底被钱塘江潮淹没的情况,那可用区也救不了你,要在业务应用层面考虑通过不同的地域来设计异地容灾了。
所以,简单来说,可以将地域理解为不同城市的机房,将可用区理解为同一个城市的不同机房。当然,实际上不同可用区也可能是在同一个机房,可用区的概念严格来说是按照电力和网络设备等相互独立来设计的。同一个地域内的不同可用区之间,内网是连通的,但是网络的响应时间会有差异。在阿里云杭州地域做的一次ping的测试,来观察同地域不同可用区之间的网络情况,发现同可用区之间的内网是连通的,但响应时间比同一个可用区之内要慢1ms多。所以,在实际应用中,如果需要考虑同城容灾或者同城双活,需要尽量将应用和数据库分布部署在不同的可用区。如果对响应时间高度敏感,则建议部署在同一个可用区内。在购买云服务器和数据库的时候,要注意选择了。
参考文献:
http://blog.csdn.net/u010305706/article/details/54406060

相关文章推荐
- openstack nova 源码分析4-nova目录下的driver.py
- openstack nova 源码分析
- OpenStack建立实例完整过程源码详细分析(1)
- OpenStack建立实例完整过程源码详细分析(5)
- OpenStack建立实例完整过程源码详细分析(4)
- openstack nova 源码分析2之nova-api,nova-compute
- OpenStack源码分析之live_migration
- OpenStack建立实例完整过程源码详细分析(9)
- openstack G版源码分析
- OpenStack建立实例完整过程源码详细分析(6)
- 【原创】OpenStack Swift源码分析(二)ring文件的生成
- OpenStack之Swift:账户服务器(Account Server)源码分析
- OpenStack之Swift:环(Ring)源码分析
- 【原创】OpenStack Swift源码分析(六)object服务
- openstack G版源码分析
- openstack nova 源码分析5-4 -nova/virt/libvirt目录下的connection.py
- 【原创】OpenStack Swift源码分析(五)keystone鉴权
- 【原创】OpenStack Swift源码分析(七)Replication服务
- OpenStack建立实例完整过程源码详细分析(3)
- OpenStack建立实例完整过程源码详细分析(8)