Hadoop+Hbase+Zookeeper集群配置
2017-07-12 15:56
495 查看
系统版本: CentOS 7.3 最小化安装
软件版本: Hadoop 2.8.0 Hbase 1.3.1 Zookeeper 3.4.9
集群规划:
一、服务器初始配置 (所有服务器执行)
1、按集群规划修改主机名及IP地址。
2、关闭防火墙
3、关闭Selinux
4、安装yum源及软件
5、添加host
6、配置免密码登录
7、安装JDK
8、添加系统变量
9、系统升级并重启
二、Zookeeper集群部署
1、下载安装
2、添加配置文件
3、设置myid
4、添加开机启动脚本并配置系统服务
5、验证配置

三、Hadoop集群部署
1、下载安装
2、修改/usr/hadoop/etc/hadoop/hadoop-env.sh
3、修改/usr/hadoop/etc/hadoop/core-site.xml,修改后文件如下:
4、修改/usr/hadoop/etc/hadoop/hdfs-site.xml,修改后文件如下:
5、复制并修改/usr/hadoop/etc/hadoop/mapred-site.xml
6、修改/usr/hadoop/etc/hadoop/yarn-site.xml,修改后文件如下:
7、配置/usr/hadoop/etc/hadoop/slaves,修改后文件如下:
8、将Hadoop安装文件夹复制到其他服务器
9、格式化HDFS文件系统

10、启动hadoop集群
11、验证配置

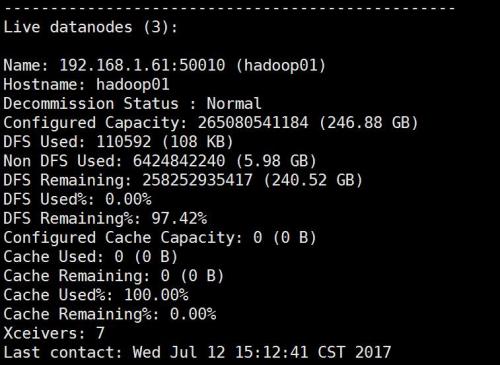

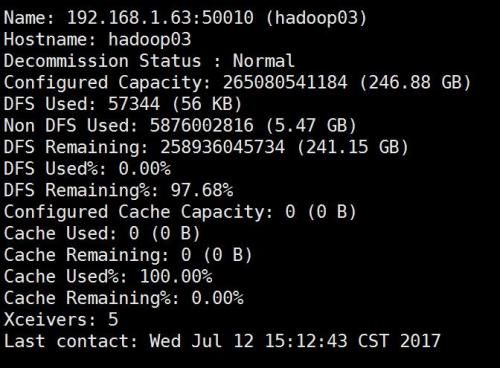
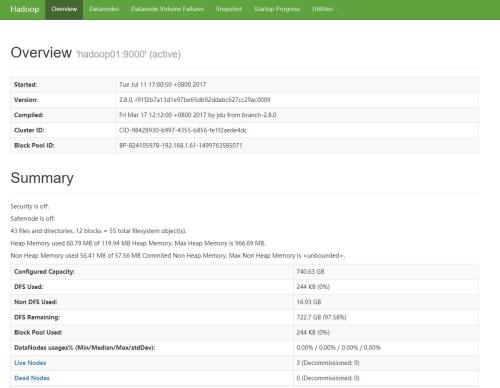
通过页面 http://192.168.1.61:50070/dfshealth.html 查看
四、Hbase集群部署
1、下载安装
2、修改/data/hbase/conf/hbase-env.sh,修改后文件如下:
3、修改/data/hbase/conf/hbase-site.xml,修改后文件如下:
4、修改/data/hbase/conf/regionservers,修改后文件如下:
5、复制Hadoop配置文件到hbase配置文件目录下
6、将Hbase安装文件夹复制到其他服务器
7、启动Hbase集群
8、验证安装
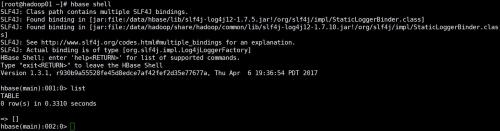
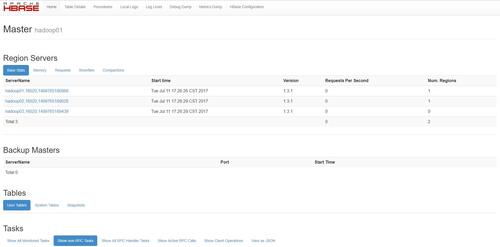
通过页面 http://192.168.1.61:16010 查看
集群配置全部完成!
软件版本: Hadoop 2.8.0 Hbase 1.3.1 Zookeeper 3.4.9
集群规划:
| 主机名 | IP |
| hadoop01 | 192.168.1.61 |
| hadoop02 | 192.168.1.62 |
| hadoop03 | 192.168.1.63 |
1、按集群规划修改主机名及IP地址。
2、关闭防火墙
systemctl stop firewalld.service systemctl disable firewalld.service
3、关闭Selinux
sed -i "s/SELINUX=enforcing/SELINUX=disabled/g" /etc/selinux/config sed -i "s/SELINUXTYPE=targeted/#SELINUXTYPE=targeted/g" /etc/selinux/config
4、安装yum源及软件
yum install epel-release -y yum install yum-axelget -y yum install expect wget unzip bash-completion vim* -y echo "alias vi='vim'">>/etc/bashrc
5、添加host
echo " 192.168.1.61 hadoop01 192.168.1.62 hadoop02 192.168.1.63 hadoop03 ">>/etc/hosts
6、配置免密码登录
#在所有服务器执行以下操作 ssh-keygen #一路回车 #在hadoop01执行以下操作 cd /root/.ssh cat id_rsa.pub >>authorized_keys scp authorized_keys hadoop02:/root/.ssh #在hadoop02执行以下操作 cd /root/.ssh cat id_rsa.pub >>authorized_keys scp authorized_keys hadoop03:/root/.ssh #在hadoop03执行以下操作 cd /root/.ssh cat id_rsa.pub >>authorized_keys scp authorized_keys hadoop01:/root/.ssh scp authorized_keys hadoop02:/root/.ssh #验证配置 #在任意服务器ssh其他服务器,是否可直接登录
7、安装JDK
cd /tmp #去官网下载jdk-8u131-linux-x64.rpm yum install jdk-8u131-linux-x64.rpm -y
8、添加系统变量
echo " export JAVA_HOME=/usr/java/jdk1.8.0_131 export PATH=\$PATH:\$JAVA_HOME/bin export HADOOP_HOME=/data/hadoop export PATH=\$PATH:\$HADOOP_HOME/bin export ZK_HOME=/data/zk export PATH=\$PATH:\$ZK_HOME/bin export HBASE_HOME=/data/hbase export PATH=\$PATH:\$HBASE_HOME/bin ">>/etc/profile
9、系统升级并重启
yum update -y reboot
二、Zookeeper集群部署
1、下载安装
#在所有服务器执行 mkdir /data cd /tmp wget https://archive.apache.org/dist/zookeeper/stable/zookeeper-3.4.9.tar.gz tar zxvf zookeeper-3.4.9.tar.gz mv zookeeper-3.4.9 /data/zk mkdir /data/zk/logs mkdir /data/zk/data chown -R root:root /data/zk
2、添加配置文件
#在所有服务器执行 cat >>/data/zk/conf/zoo.cfg<<EOF tickTime=2000 initLimit=5 syncLimit=2 dataDir=/data/zk/data deployLogDir=/data/zk/logs clientPort=2181 maxClientCnxns=65535 autopurge.snapRetainCount=3 autopurge.purgeInterval=1 server.1=192.168.1.61:2888:3888 server.2=192.168.1.62:2888:3888 server.3=192.168.1.63:2888:3888 EOF
3、设置myid
#在hadoop01执行 echo "1" > /data/zk/data/myid #在hadoop02执行 echo "2" > /data/zk/data/myid #在hadoop03执行 echo "3" > /data/zk/data/myid
4、添加开机启动脚本并配置系统服务
echo "[Unit] Description=Zookeeper After=syslog.target network.target remote-fs.target nss-lookup.target [Service] Type=forking PIDFile=/data/zk/data/zookeeper_server.pid ExecStart=/data/zk/bin/zkServer.sh start ExecStop=/data/zk/bin/zkServer.sh stop [Install] WantedBy=multi-user.target ">>/usr/lib/systemd/system/zookeeper.service systemctl enable zookeeper.service systemctl start zookeeper.service systemctl status -l zookeeper.service
5、验证配置
#在任意服务器上执行 zkServer.sh status
三、Hadoop集群部署
1、下载安装
cd /tmp wget https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-2.8.0/hadoop-2.8.0.tar.gz tar zxvf hadoop-2.8.0.tar.gz mv hadoop-2.8.0 /data/hadoop cd /data/hadoop/ mkdir tmp hdfs mkdir hdfs/name hdfs/tmp hdfs/data chown -R root:root /data/hadoop/
2、修改/usr/hadoop/etc/hadoop/hadoop-env.sh
#修改第25行jdk环境变量 export JAVA_HOME=/usr/java/jdk1.8.0_131 #修改第33行,配置文件目录位置 export HADOOP_CONF_DIR=/data/hadoop/etc/hadoop
3、修改/usr/hadoop/etc/hadoop/core-site.xml,修改后文件如下:
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>hadoop.tmp.dir</name> <value>/data/hadoop/tmp</value> <final>true</final> <description>A base for other temporary directories.</description> </property> <property> <name>fs.default.name</name> <value>hdfs://192.168.1.61:9000</value> <final>true</final> </property> <property> <name>io.file.buffer.size</name> <value>131072</value> </property> <property> <name>ha.zookeeper.quorum</name> <value>192.168.1.61:2181,192.168.1.62:2181,192.168.1.63:2181</value> </property> </configuration>
4、修改/usr/hadoop/etc/hadoop/hdfs-site.xml,修改后文件如下:
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>dfs.replication</name> <value>2</value> </property> <property> <name>dfs.name.dir</name> <value>/data/hadoop/hdfs/name</value> </property> <property> <name>dfs.data.dir</name> <value>/data/hadoop/hdfs/data</value> </property> <property> <name>dfs.namenode.secondary.http-address</name> <value>192.168.1.61:9001</value> </property> <property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property> <property> <name>dfs.permissions</name> <value>false</value> </property> </configuration>
5、复制并修改/usr/hadoop/etc/hadoop/mapred-site.xml
cd /data/hadoop/etc/hadoop/ cp mapred-site.xml.template mapred-site.xml
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
6、修改/usr/hadoop/etc/hadoop/yarn-site.xml,修改后文件如下:
<?xml version="1.0"?> <configuration> <property> <name>yarn.resourcemanager.address</name> <value>192.168.1.61:18040</value> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>192.168.1.61:18030</value> </property> <property> <name>yarn.resourcemanager.webapp.address</name> <value>192.168.1.61:18088</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>192.168.1.61:18025</value> </property> <property> <name>yarn.resourcemanager.admin.address</name> <value>192.168.1.61:18141</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> </configuration>
7、配置/usr/hadoop/etc/hadoop/slaves,修改后文件如下:
192.168.1.61 192.168.1.62 192.168.1.63
8、将Hadoop安装文件夹复制到其他服务器
scp -r /data/hadoop hadoop02:/data scp -r /data/hadoop hadoop03:/data
9、格式化HDFS文件系统
hadoop namenode -format
10、启动hadoop集群
cd /data/hadoop/sbin/ ./start-all.sh #此命令会直接启动所有节点,只在hadoop01服务器上执行即可
11、验证配置
#查看集群状态 hadoop dfsadmin -report
通过页面 http://192.168.1.61:50070/dfshealth.html 查看
四、Hbase集群部署
1、下载安装
cd /tmp wget http://apache.fayea.com/hbase/1.3.1/hbase-1.3.1-bin.tar.gz tar zxvf hbase-1.3.1-bin.tar.gz mv hbase-1.3.1 /data/hbase chown -R root:root /data/hbase/
2、修改/data/hbase/conf/hbase-env.sh,修改后文件如下:
#修改第27行jdk环境变量 export JAVA_HOME=/usr/java/jdk1.8.0_131 #修改第128行禁用自有Zookeeper export HBASE_MANAGES_ZK=false
3、修改/data/hbase/conf/hbase-site.xml,修改后文件如下:
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>hbase.rootdir</name> <value>hdfs://192.168.1.61:9000/hbase</value> </property> <property> <name>hbase.cluster.distributed</name> <value>true</value> </property> <property> <name>hbase.zookeeper.quorum</name> <value>192.168.1.61:2181,192.168.1.62:2181,192.168.1.63:2181</value> </property> <property> <name>hbase.master.port</name> <value>16000</value> </property> <property> <name>hbase.master.info.port</name> <value>16010</value> </property> </configuration>
4、修改/data/hbase/conf/regionservers,修改后文件如下:
192.168.1.61 192.168.1.62 192.168.1.63
5、复制Hadoop配置文件到hbase配置文件目录下
cd /data/hbase/conf/ cp /data/hadoop/etc/hadoop/core-site.xml . cp /data/hadoop/etc/hadoop/hdfs-site.xml .
6、将Hbase安装文件夹复制到其他服务器
scp -r /data/hbase hadoop02:/data scp -r /data/hbase hadoop03:/data
7、启动Hbase集群
cd /data/hbase/bin/ ./start-hbase.sh #此命令会直接启动所有节点,只在hadoop01服务器上执行即可
8、验证安装
#进入shell hbase shell
通过页面 http://192.168.1.61:16010 查看
集群配置全部完成!

相关文章推荐
- HBase+ZooKeeper+Hadoop2.6.0的ResourceManager HA集群高可用配置
- 集群环境下配置hadoop1.0,zookeeper,hbase
- hadoop、zookeeper、hbase安装配置集群
- 配置密码分布式集群环境hadoop、hbase、zookeeper搭建(全)
- HBase+ZooKeeper+Hadoop2.6.0的ResourceManager HA集群高可用配置
- Hadoop、Zookeeper、Hbase集群安装配置过程及常见问题(一)准备工作
- HBase+ZooKeeper+Hadoop2.6.0的ResourceManager HA集群高可用配置
- HBase+ZooKeeper+Hadoop2.6.0的ResourceManager HA集群高可用配置 [复制链接] 韩克拉玛寒 韩克拉玛寒 当前离线 积分2439. 窥视卡 雷达
- hadoop-1.0.4 hbase-0.94.10 zookeeper-3.4.5集群配置
- hadoop2.6集群下Zookeeper与Hbase的安装与配置
- HBase+ZooKeeper+Hadoop2.6.0的ResourceManager HA集群高可用配置
- Hadoop+ZooKeeper+HBase集群配置
- [推荐]Hadoop+HBase+Zookeeper集群的配置
- Hadoop+Hbase+Spark集群配置—Zookeeper安装
- Hadoop+Hbase+ZooKeeper 安装配置及需要注意的事项
- hadoop1.2.1+zookeeper-3.4.5+hbase-0.94.1集群安装过程详解
- Hadoop+Hbase+ZooKeeper 安装配置及需要注意的事项
- hadoop1.2.1+zookeeper-3.4.5+hbase-0.94.1集群安装
- hadoop,hbase,zookeeper安装配置
- HBase入门笔记(三)-- 完全分布模式Hadoop集群安装配置