JavaScript机器学习之KNN算法
2017-07-12 00:00
323 查看
译者按: 机器学习原来很简单啊,不妨动手试试!
原文: Machine Learning with JavaScript : Part 2
译者: Fundebug
为了保证可读性,本文采用意译而非直译。另外,本文版权归原作者所有,翻译仅用于学习。另外,我们修正了原文代码中的错误
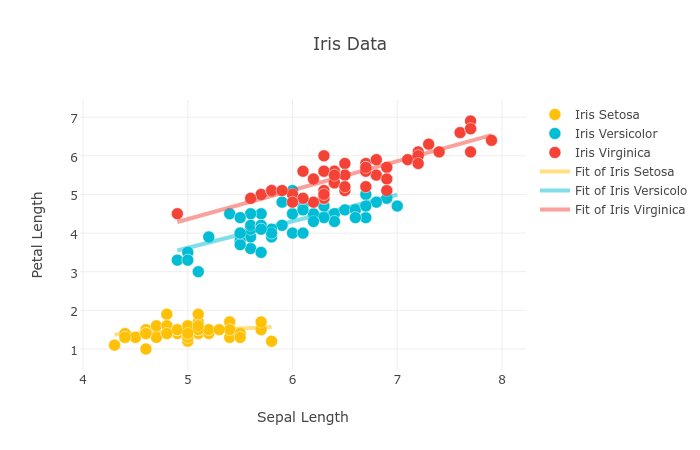
上图使用plot.ly所画。
上次我们用JavaScript实现了线性规划,这次我们来聊聊KNN算法。
KNN是k-Nearest-Neighbours的缩写,它是一种监督学习算法。KNN算法可以用来做分类,也可以用来解决回归问题。
GitHub仓库: machine-learning-with-js
如果待分类的数据有这些邻近数据,NY: 7, NJ: 0, IN: 4,即它有7个NY邻居,0个NJ邻居,4个IN邻居,则这个数据应该归类为NY。
假设你在邮局工作,你的任务是为邮递员分配信件,目标是最小化到各个社区的投递旅程。不妨假设一共有7个街区。这就是一个实际的分类问题。你需要将这些信件分类,决定它属于哪个社区,比如上东城、曼哈顿下城等。
最坏的方案是随意分配信件分配给邮递员,这样每个邮递员会拿到各个社区的信件。
最佳的方案是根据信件地址进行分类,这样每个邮递员只需要负责邻近社区的信件。
也许你是这样想的:"将邻近3个街区的信件分配给同一个邮递员"。这时,邻近街区的个数就是k。你可以不断增加k,直到获得最佳的分配方案。这个k就是分类问题的最佳值。
每一个机器学习算法都需要数据,这次我将使用IRIS数据集。其数据集包含了150个样本,都属于鸢尾属下的三个亚属,分别是山鸢尾、变色鸢尾和维吉尼亚鸢尾。四个特征被用作样本的定量分析,它们分别是花萼和花瓣的长度和宽度。
ml-knn: k-Nearest-Neighbours模块,不同版本的接口可能不同,这篇博客使用了2.0.0
csvtojson: 用于将CSV数据转换为JSON
prompt: 在控制台输入输出数据
假设你已经初始化了一个NPM项目,请在index.js中输入以下内容:
seperationSize用于分割数据和测试数据
使用csvtojson模块的fromFile方法加载数据:
我们将seperationSize设为样本数目的0.7倍。注意,如果训练数据集太小的话,分类效果将变差。
由于数据集是根据种类排序的,所以需要使用shuffleArray函数对数据进行混淆,这样才能方便分割出训练数据。这个函数的定义请参考StackOverflow的提问How to randomize (shuffle) a JavaScript array?:
在使用KNN算法训练数据之前,需要对数据进行这些处理:
将属性(sepalLength, sepalWidth,petalLength,petalWidth)由字符串转换为浮点数. (parseFloat)
将分类 (type)用数字表示
train方法需要2个必须的参数: 输入数据,即花萼和花瓣的长度和宽度;实际分类,即山鸢尾、变色鸢尾和维吉尼亚鸢尾。另外,第三个参数是可选的,用于提供调整KNN算法的内部参数。我将k参数设为7,其默认值为5。
训练好模型之后,就可以使用测试数据来检查准确性了。我们主要对预测出错的个数比较感兴趣。
比较预测值与真实值,就可以得到出错个数:
在控制台执行node index.js
输出如下:
安德森鸢尾花卉数据集
欢迎加入我们Fundebug的全栈BUG监控交流群: 622902485。
版权声明:
转载时请注明作者Fundebug以及本文地址:
https://blog.fundebug.com/2017/07/10/javascript-machine-learning-knn/
原文: Machine Learning with JavaScript : Part 2
译者: Fundebug
为了保证可读性,本文采用意译而非直译。另外,本文版权归原作者所有,翻译仅用于学习。另外,我们修正了原文代码中的错误
上图使用plot.ly所画。
上次我们用JavaScript实现了线性规划,这次我们来聊聊KNN算法。
KNN是k-Nearest-Neighbours的缩写,它是一种监督学习算法。KNN算法可以用来做分类,也可以用来解决回归问题。
GitHub仓库: machine-learning-with-js
KNN算法简介
简单地说,KNN算法由那离自己最近的K个点来投票决定待分类数据归为哪一类。如果待分类的数据有这些邻近数据,NY: 7, NJ: 0, IN: 4,即它有7个NY邻居,0个NJ邻居,4个IN邻居,则这个数据应该归类为NY。
假设你在邮局工作,你的任务是为邮递员分配信件,目标是最小化到各个社区的投递旅程。不妨假设一共有7个街区。这就是一个实际的分类问题。你需要将这些信件分类,决定它属于哪个社区,比如上东城、曼哈顿下城等。
最坏的方案是随意分配信件分配给邮递员,这样每个邮递员会拿到各个社区的信件。
最佳的方案是根据信件地址进行分类,这样每个邮递员只需要负责邻近社区的信件。
也许你是这样想的:"将邻近3个街区的信件分配给同一个邮递员"。这时,邻近街区的个数就是k。你可以不断增加k,直到获得最佳的分配方案。这个k就是分类问题的最佳值。
KNN代码实现
像上次一样,我们将使用mljs的KNN模块ml-knn来实现。每一个机器学习算法都需要数据,这次我将使用IRIS数据集。其数据集包含了150个样本,都属于鸢尾属下的三个亚属,分别是山鸢尾、变色鸢尾和维吉尼亚鸢尾。四个特征被用作样本的定量分析,它们分别是花萼和花瓣的长度和宽度。
1. 安装模块
$ npm install ml-knn@2.0.0 csvtojson prompt
ml-knn: k-Nearest-Neighbours模块,不同版本的接口可能不同,这篇博客使用了2.0.0
csvtojson: 用于将CSV数据转换为JSON
prompt: 在控制台输入输出数据
2. 初始化并导入数据
**IRIS数据集**由加州大学欧文分校提供。curl https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data > iris.csv
假设你已经初始化了一个NPM项目,请在index.js中输入以下内容:
const KNN = require('ml-knn');
const csv = require('csvtojson');
const prompt = require('prompt');
var knn;
const csvFilePath = 'iris.csv'; // 数据集
const names = ['sepalLength', 'sepalWidth', 'petalLength', 'petalWidth', 'type'];
let seperationSize; // 分割训练和测试数据
let data = [],
X = [],
y = [];
let trainingSetX = [],
trainingSetY = [],
testSetX = [],
testSetY = [];seperationSize用于分割数据和测试数据
使用csvtojson模块的fromFile方法加载数据:
csv(
{
noheader: true,
headers: names
})
.fromFile(csvFilePath)
.on('json', (jsonObj) =>
{
data.push(jsonObj); // 将数据集转换为JS对象数组
})
.on('done', (error) =>
{
seperationSize = 0.7 * data.length;
data = shuffleArray(data);
dressData();
});我们将seperationSize设为样本数目的0.7倍。注意,如果训练数据集太小的话,分类效果将变差。
由于数据集是根据种类排序的,所以需要使用shuffleArray函数对数据进行混淆,这样才能方便分割出训练数据。这个函数的定义请参考StackOverflow的提问How to randomize (shuffle) a JavaScript array?:
function shuffleArray(array)
{
for (var i = array.length - 1; i > 0; i--)
{
var j = Math.floor(Math.random() * (i + 1));
var temp = array[i];
array[i] = array[j];
array[j] = temp;
}
return array;
}3. 转换数据
数据集中每一条数据可以转换为一个JS对象:{
sepalLength: ‘5.1’,
sepalWidth: ‘3.5’,
petalLength: ‘1.4’,
petalWidth: ‘0.2’,
type: ‘Iris-setosa’
}在使用KNN算法训练数据之前,需要对数据进行这些处理:
将属性(sepalLength, sepalWidth,petalLength,petalWidth)由字符串转换为浮点数. (parseFloat)
将分类 (type)用数字表示
function dressData()
{
let types = new Set();
data.forEach((row) =>
{
types.add(row.type);
});
let typesArray = [...types];
data.forEach((row) =>
{
let rowArray, typeNumber;
rowArray = Object.keys(row).map(key => parseFloat(row[key])).slice(0, 4);
typeNumber = typesArray.indexOf(row.type); // Convert type(String) to type(Number)
X.push(rowArray);
y.push(typeNumber);
});
trainingSetX = X.slice(0, seperationSize);
trainingSetY = y.slice(0, seperationSize);
testSetX = X.slice(seperationSize);
testSetY = y.slice(seperationSize);
train();
}4. 训练数据并测试
function train()
{
knn = new KNN(trainingSetX, trainingSetY,
{
k: 7
});
test();
}train方法需要2个必须的参数: 输入数据,即花萼和花瓣的长度和宽度;实际分类,即山鸢尾、变色鸢尾和维吉尼亚鸢尾。另外,第三个参数是可选的,用于提供调整KNN算法的内部参数。我将k参数设为7,其默认值为5。
训练好模型之后,就可以使用测试数据来检查准确性了。我们主要对预测出错的个数比较感兴趣。
function test()
{
const result = knn.predict(testSetX);
const testSetLength = testSetX.length;
const predictionError = error(result, testSetY);
console.log(`Test Set Size = ${testSetLength} and number of Misclassifications = ${predictionError}`);
predict();
}比较预测值与真实值,就可以得到出错个数:
function error(predicted, expected)
{
let misclassifications = 0;
for (var index = 0; index < predicted.length; index++)
{
if (predicted[index] !== expected[index])
{
misclassifications++;
}
}
return misclassifications;
}5. 进行预测(可选)
任意输入属性值,就可以得到预测值function predict()
{
let temp = [];
prompt.start();
prompt.get(['Sepal Length', 'Sepal Width', 'Petal Length', 'Petal Width'], function(err, result)
{
if (!err)
{
for (var key in result)
{
temp.push(parseFloat(result[key]));
}
console.log(`With ${temp} -- type = ${knn.predict(temp)}`);
}
});
}6. 完整程序
完整的程序index.js是这样的:const KNN = require('ml-knn');
const csv = require('csvtojson');
const prompt = require('prompt');
var knn;
const csvFilePath = 'iris.csv'; // 数据集
const names = ['sepalLength', 'sepalWidth', 'petalLength', 'petalWidth', 'type'];
let seperationSize; // 分割训练和测试数据
let data = [],
X = [],
y = [];
let trainingSetX = [],
trainingSetY = [],
testSetX = [],
testSetY = [];
csv(
{
noheader: true,
headers: names
})
.fromFile(csvFilePath)
.on('json', (jsonObj) =>
{
data.push(jsonObj); // 将数据集转换为JS对象数组
})
.on('done', (error) =>
{
seperationSize = 0.7 * data.length;
data = shuffleArray(data);
dressData();
});
function dressData()
{
let types = new Set();
data.forEach((row) =>
{
types.add(row.type);
});
let typesArray = [...types];
data.forEach((row) =>
{
let rowArray, typeNumber;
rowArray = Object.keys(row).map(key => parseFloat(row[key])).slice(0, 4);
typeNumber = typesArray.indexOf(row.type); // Convert type(String) to type(Number)
X.push(rowArray);
y.push(typeNumber);
});
trainingSetX = X.slice(0, seperationSize);
trainingSetY = y.slice(0, seperationSize);
testSetX = X.slice(seperationSize);
testSetY = y.slice(seperationSize);
train();
}
// 使用KNN算法训练数据
function train()
{
knn = new KNN(trainingSetX, trainingSetY,
{
k: 7
});
test();
}
// 测试训练的模型
function test()
{
const result = knn.predict(testSetX);
const testSetLength = testSetX.length;
const predictionError = error(result, testSetY);
console.log(`Test Set Size = ${testSetLength} and number of Misclassifications = ${predictionError}`);
predict();
}
// 计算出错个数
function error(predicted, expected)
{
let misclassifications = 0;
for (var index = 0; index < predicted.length; index++)
{
if (predicted[index] !== expected[index])
{
misclassifications++;
}
}
return misclassifications;
}
// 根据输入预测结果
function predict()
{
let temp = [];
prompt.start();
prompt.get(['Sepal Length', 'Sepal Width', 'Petal Length', 'Petal Width'], function(err, result)
{
if (!err)
{
for (var key in result)
{
temp.push(parseFloat(result[key]));
}
console.log(`With ${temp} -- type = ${knn.predict(temp)}`);
}
});
}
// 混淆数据集的顺序
function shuffleArray(array)
{
for (var i = array.length - 1; i > 0; i--)
{
var j = Math.floor(Math.random() * (i + 1));
var temp = array[i];
array[i] = array[j];
array[j] = temp;
}
return array;
}在控制台执行node index.js
$ node index.js
输出如下:
Test Set Size = 45 and number of Misclassifications = 2 prompt: Sepal Length: 1.7 prompt: Sepal Width: 2.5 prompt: Petal Length: 0.5 prompt: Petal Width: 3.4 With 1.7,2.5,0.5,3.4 -- type = 2
参考链接
K NEAREST NEIGHBOR 算法安德森鸢尾花卉数据集
欢迎加入我们Fundebug的全栈BUG监控交流群: 622902485。
版权声明:
转载时请注明作者Fundebug以及本文地址:
https://blog.fundebug.com/2017/07/10/javascript-machine-learning-knn/

相关文章推荐
- 机器学习经典算法1--knn
- 数学之路(3)-机器学习(3)-常用算法-KD树和与KNN
- 机器学习 Python kNN算法
- 【机器学习】knn(k-近邻算法)&numpy安装
- [机器学习]kNN算法python实现(实例:数字识别)
- 机器学习之KNN 算法
- 机器学习(3)——KNN算法及手写数字的识别(一)
- 机器学习经典算法详解及Python实现--K近邻(KNN)算法
- 机器学习实战之KNN算法
- 【机器学习实战之一】:C++实现K-近邻算法KNN
- 机器学习:KNN算法
- 机器学习-kNN算法改进约会效果
- 机器学习(4)——KNN算法及手写数字的识别(二)
- 用Python开始机器学习(4:KNN分类算法)
- 机器学习_算法_KNN
- 【机器学习实战】:C++实现K-近邻算法KNN
- Python机器学习(二)--kNN算法实现
- 机器学习--k-近邻(kNN)算法
- KNN演算法--通俗易懂的机器学习理论介绍