spark核心原理之SparkContext原理(2)
2017-07-10 11:20
183 查看
任务调度部件TaskScheduler
TaskScheduler负责tasks的提交和请求调度,是任务调度的client端。创建TaskScheduler时会获取master配置,配置部署模式,创建TaskSchedulerImpl和SchedulerBackend。
TaskSchedulerImpl构造过程包括:从SparkConf读取配置信息,包括为task分配的核数和FAIR或FIFO(默认)模式,调度模式的具体实现在接口SchedulerBackend端完成。创建TaskResultGetter线程(线程池方式,默认为4个),处理Task结果,task结果来自Worker端的Executor发送。之后进行initialize部分,添加SchedulerdulerBackend引用,创建Pool实例(缓存调度队列,调度算法等)
TaskScheduler的启动过程首先调用backend.start()方法,以localBackend为例,创建localActor,主要是Executor部件,主要包括以下过程:
1)创建并注册ExecutorSource。ExecutorSource用于测量系统。调用metricRegistry的register方法注册计量计量信息,创建完ExecutorSource后,调用MetricsSystem的registerSource方法将ExecutorSource注册到MetricsSystem。registerSource方法使用MetricRegistry的register方法将ExecutorSource注册到MetricRegistry,
2)获取SparkEnv。
3)创建并注册ExecutorActor接受发送给Executor的消息。
4)urlClassLoader的创建。在非local模式中,Driver或者Worker上都会有多个Executor,每个Executor都设置自身的urlClassLoader,用于加载任务上传的jar包中的类,有效对任务的类加载环境进行隔离。
5)创建Executor执行Task的线程池。此线程池用于执行任务。
6)启动Executor的心跳线程。按一定时间间隔向Driver发送心跳,更新测量信息,让BlockManangerMaster确保Executor中的BlockManager未失效。
之后会初始化块管理模块BlockManager,这也是一个比较重要的数据结构,后面考虑单独介绍。
DAGScheduler创建
如下图所示,DAGScheduler的作用主要是根据用户提交的job,按照RDD的依赖关系(宽依赖,窄依赖)划分一系列的包含tasks的stage,并向Cluster manager(在TaskScheduler中)提交TaskSet。
DAGScheduler构造完成,并初始化一个eventProcessLoop实例后,会调用其eventProcessLoop.start()方法,启动一个多线程,然后把event提交到eventProcessLoop中。
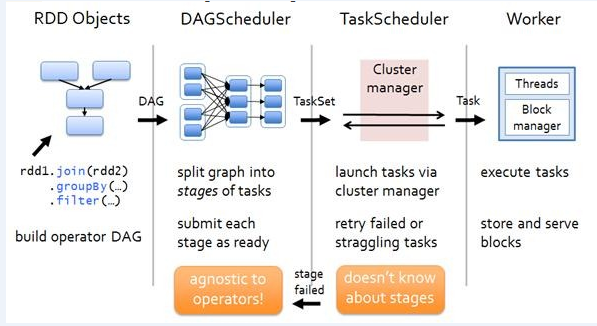
DAGScheduler构造调用initializeEventProcessActor方法创建DAGSchedulerEvent-ProcessActo。DAG-SchedulerActorSupervisor生成DAGSchedulerEventProcessActor,并注册到ActorSystem,ActorSystem就会调用DAGSchedulerEventProcessActor的preStart,taskScheduler持有dagScheduler。DAG-SchedulerEventProcessActor能处理的消息类型为JobSubmitted、BeginEvent、CompletionEvent等。
MetricsSystem测量系统的启动:
MetricsSystem中有三个概念:1 Instance:指定了谁在使用测量系统;2 Source:指定了从哪里收集测量数据;3 Sink:指定了往哪里输出测量数据。Spark Instance可包括Master、Worker、Application、Driver和Executor。Spark目前提供的Sink有ConsoleSink、CsvSink、JmxSink、MetricsServlet、GraphiteSink等。Spark中使用MetricsServlet作为默认的Sink。
MetricsSystem的启动过程包括以下步骤:
1)注册Sources;
2)注册Sinks;
3)给Sinks增加Jetty的ServletContextHandler。
接下来SparkContext创建和启动ExecutorAllocationManager,管理Executor的分配,ExecutorAllocationManager可以设置动态分配最小Executor数量、动态分配最大Executor数量、每个Executor可以运行的Task数量等配置信息,并对配置信息进行校验。
SparkContext进行ContextCleaner的创建与启动:ContextCleaner用于清理那些超出应用范围的RDD、ShuffleDependency和Broadcast对象。SparkContext创建DAGSchedulerSource和BlockManagerSource,用于测量信息。
最后SparkContext初始化的最后将当前SparkContext的状态从contextBeingConstructed(正在构建中)改为activeContext(已激活),至此,SparkContext构建完成。
TaskScheduler负责tasks的提交和请求调度,是任务调度的client端。创建TaskScheduler时会获取master配置,配置部署模式,创建TaskSchedulerImpl和SchedulerBackend。
TaskSchedulerImpl构造过程包括:从SparkConf读取配置信息,包括为task分配的核数和FAIR或FIFO(默认)模式,调度模式的具体实现在接口SchedulerBackend端完成。创建TaskResultGetter线程(线程池方式,默认为4个),处理Task结果,task结果来自Worker端的Executor发送。之后进行initialize部分,添加SchedulerdulerBackend引用,创建Pool实例(缓存调度队列,调度算法等)
TaskScheduler的启动过程首先调用backend.start()方法,以localBackend为例,创建localActor,主要是Executor部件,主要包括以下过程:
1)创建并注册ExecutorSource。ExecutorSource用于测量系统。调用metricRegistry的register方法注册计量计量信息,创建完ExecutorSource后,调用MetricsSystem的registerSource方法将ExecutorSource注册到MetricsSystem。registerSource方法使用MetricRegistry的register方法将ExecutorSource注册到MetricRegistry,
2)获取SparkEnv。
3)创建并注册ExecutorActor接受发送给Executor的消息。
4)urlClassLoader的创建。在非local模式中,Driver或者Worker上都会有多个Executor,每个Executor都设置自身的urlClassLoader,用于加载任务上传的jar包中的类,有效对任务的类加载环境进行隔离。
5)创建Executor执行Task的线程池。此线程池用于执行任务。
6)启动Executor的心跳线程。按一定时间间隔向Driver发送心跳,更新测量信息,让BlockManangerMaster确保Executor中的BlockManager未失效。
之后会初始化块管理模块BlockManager,这也是一个比较重要的数据结构,后面考虑单独介绍。
DAGScheduler创建
如下图所示,DAGScheduler的作用主要是根据用户提交的job,按照RDD的依赖关系(宽依赖,窄依赖)划分一系列的包含tasks的stage,并向Cluster manager(在TaskScheduler中)提交TaskSet。
DAGScheduler构造完成,并初始化一个eventProcessLoop实例后,会调用其eventProcessLoop.start()方法,启动一个多线程,然后把event提交到eventProcessLoop中。
DAGScheduler构造调用initializeEventProcessActor方法创建DAGSchedulerEvent-ProcessActo。DAG-SchedulerActorSupervisor生成DAGSchedulerEventProcessActor,并注册到ActorSystem,ActorSystem就会调用DAGSchedulerEventProcessActor的preStart,taskScheduler持有dagScheduler。DAG-SchedulerEventProcessActor能处理的消息类型为JobSubmitted、BeginEvent、CompletionEvent等。
MetricsSystem测量系统的启动:
MetricsSystem中有三个概念:1 Instance:指定了谁在使用测量系统;2 Source:指定了从哪里收集测量数据;3 Sink:指定了往哪里输出测量数据。Spark Instance可包括Master、Worker、Application、Driver和Executor。Spark目前提供的Sink有ConsoleSink、CsvSink、JmxSink、MetricsServlet、GraphiteSink等。Spark中使用MetricsServlet作为默认的Sink。
MetricsSystem的启动过程包括以下步骤:
1)注册Sources;
2)注册Sinks;
3)给Sinks增加Jetty的ServletContextHandler。
接下来SparkContext创建和启动ExecutorAllocationManager,管理Executor的分配,ExecutorAllocationManager可以设置动态分配最小Executor数量、动态分配最大Executor数量、每个Executor可以运行的Task数量等配置信息,并对配置信息进行校验。
SparkContext进行ContextCleaner的创建与启动:ContextCleaner用于清理那些超出应用范围的RDD、ShuffleDependency和Broadcast对象。SparkContext创建DAGSchedulerSource和BlockManagerSource,用于测量信息。
最后SparkContext初始化的最后将当前SparkContext的状态从contextBeingConstructed(正在构建中)改为activeContext(已激活),至此,SparkContext构建完成。

相关文章推荐
- spark核心原理之SparkContext原理(1)
- Spark内核源码深度剖析:SparkContext原理剖析与源码分析
- Spark内核源码深度剖析:sparkContext初始化的源码核心
- 加米谷:Spark核心技术原理透视二(Spark运行模式)
- Spark 以及 spark streaming 核心原理及实践
- Spark 以及 spark streaming 核心原理及实践
- spark内核揭秘-05-SparkContext核心源码解析初体验
- Spark核心技术原理透视二(Spark运行模式)
- spark内核揭秘-05-SparkContext核心源码解析初体验
- Spark核心技术原理透视一(Spark运行原理)
- spark核心编程原理
- Spark2.2 SparkContext原理剖析图及源码
- SparkContext初始化的核心过程
- Spark核心编程:Spark架构原理
- Spark内核源码深度剖析:SparkContext原理剖析与源码分析
- 我的Spark源码核心SparkContext走读全纪录
- Spark核心编程原理
- Spark核心原理之Executor原理
- Spark核心技术原理透视一(Spark运行原理)
- Spark Streaming运行原理与核心概念