KNN(k-近邻)分类算法讲解与实现(python)
2017-07-10 10:25
961 查看
KNN算法相对于其他算法是一种特别好实现且易于理解的分类算法,主要根据不同特征之间的距离来进行分类。一般的分类算法首先要训练一个模型,然后用测试集检验模型,但是KNN算法不用训练模型,直接采用待测样本与训练样本的距离来实现分类。
KNN基本原理:根据距离函数计算待分类样本X和每个训练样本的距离,选择与待分类样本距离最小的K歌样本作为X的K个最近邻,最后以X的K个最近邻中的大多数所属类别作为X的类别。通常k不大于20。
KNN实现步骤:
1、将待测样本与训练样本集所有样本的距离
2、将各个距离按从小到大排序
3、取距离最小的前K个样本
4、计算在这K个样本中,每个类别所占比例
5、返回K个样本中,类别出现概率最大的就是待测样本的类别。
下面以一个例子说明这个过程:
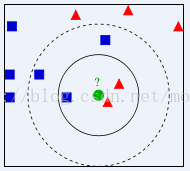
该图主要说明绿色圆形属于蓝色还是红色
当k=3时,位于内侧的圆形内分别有两个红色和一个蓝色,红色概率>蓝色 2/3 > 1/3,所以分类结果属于红色。
当k=5时,位于虚线圆形内分别有两个红色和3个蓝色,红色概率<蓝色 2/5> 3/5,所以分类结果属于蓝色。
本文采用python实现KNN算法,环境python 3.4,具体代码如下:
数据集iris介绍:iris是鸢尾花数据集。分为3类,共有150组数据,每类50组数据,每个数据包含4个属性,分别为花朵,粤片,花瓣的长度,花瓣的宽度。
代码对比了scikit learn中的KNN,最后分类结果差不多0.966
# -*- coding: utf-8 -*-
import pandas as pd
import numpy as np
import glob
import os
from sklearn import cross_validation
from sklearn.neighbors import KNeighborsClassifier
def load_data():
alldata=pd.read_excel('e:/a/iris.xls')
data=alldata.iloc[:,:4]
data=np.array(data)
y=alldata.iloc[:,4]
y=np.array(y)
X_train, X_test, y_train, y_test = cross_validation.train_test_split(data, y, test_size=0.2)
#print(X_train.shape[0])#120
#print(X_train.shape)#(120, 4)
#print(y_train)
return X_train, X_test, y_train, y_test
def calssfiy(x_test,x_train,y_train,k):
trainSize=x_train.shape[0]#行数
#============================================
#计算待测样本与训练集所有样本距离
'''
tile(A,n)功能是将A数组重复n次
'''
comp=np.tile(x_test,(trainSize,1))
disqu=(comp-x_train)**2#矩阵中的每个元素的平方
sqldis=np.sum(disqu,axis=1)#计算行和
distance=np.sqrt(sqldis)
#==============================================
#将各个距离从大到小排序
sortedDist = np.argsort(distance) #argsort函数返回的是数组值从小到大的索引值
classCount={}#主要记录每个类别及其出现次数
for i in range(k):
votey=y_train[sortedDist[i]]#取出前k个样本的标签
classCount[votey]=classCount.get(votey,0)+1#key为votey,如果没有返回0,如果有就加1
#===============================================
#返回K个样本中,类别出现概率最大的就是待测样本的类别
maxCoutn=0
for key ,value in classCount.items() :
if value>maxCoutn:
maxCoutn=value
maxY=key
return maxY
if __name__=='__main__':
X_train, X_test, y_train, y_test=load_data()
X_test_num=X_test.shape[0]
#==================================
print('####采用scikit learn###########')
clf=KNeighborsClassifier()
clf.fit(X_train,y_train)
doc_class_predicted = clf.predict(X_test)
#print(doc_class_predicted )
print(np.mean(doc_class_predicted == y_test))
#===========================================
print('###############')#30
count=0
for i in range(X_test_num):
label=calssfiy(X_test[i],X_train,y_train,5)
if (label==y_test[i]):
count=count+1
accury=float(count/X_test_num)
print(accury)
KNN算法优点:
1.简单,易于理解,易于实现,无需估计参数,无需训练;
2. 适合对稀有事件进行分类;
3.当有新样本加入训练集中,无需重新训练
缺点:
1.该算法在分类时有个主要的不足是,当样本不平衡时,如一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,该样本的K个邻居中大容量类的样本占多数。 该算法只计算“最近的”邻居样本,某一类的样本数量很大,那么或者这类样本并不接近目标样本,或者这类样本很靠近目标样本。无论怎样,数量并不能影响运行结果。
2.该方法的另一个不足之处是计算量较大,因为对每一个待分类的文本都要计算它到全体已知样本的距离,才能求得它的K个最近邻点。
3.K值不好确定,如果k值选择过小,会降低分类的精度,同时放大噪声干扰,如果k值选择过大,如果待分类样本属于训练集中包含数据较少的类,那么选择k个近邻的时候,实际上并不相似的数据也会包含进来,增加了噪声,导致最终分类准确率也会下降。
KNN算法优点:
1.简单,易于理解,易于实现,无需估计参数,无需训练;
2. 适合对稀有事件进行分类;
3.当有新样本加入训练集中,无需重新训练
缺点:
缺点:
1.该算法在分类时有个主要的不足是,当样本不平衡时,如一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,该样本的K个邻居中大容量类的样本占多数。 该算法只计算“最近的”邻居样本,某一类的样本数量很大,那么或者这类样本并不接近目标样本,或者这类样本很靠近目标样本。无论怎样,数量并不能影响运行结果。
2.该方法的另一个不足之处是计算量较大,因为对每一个待分类的文本都要计算它到全体已知样本的距离,才能求得它的K个最近邻点。
3.K值不好确定,如果k值选择过小,会降低分类的精度,同时放大噪声干扰,如果k值选择过大,如果待分类样本属于训练集中包含数据较少的类,那么选择k个近邻的时候,实际上并不相似的数据也会包含进来,增加了噪声,导致最终分类准确率也会下降。
KNN基本原理:根据距离函数计算待分类样本X和每个训练样本的距离,选择与待分类样本距离最小的K歌样本作为X的K个最近邻,最后以X的K个最近邻中的大多数所属类别作为X的类别。通常k不大于20。
KNN实现步骤:
1、将待测样本与训练样本集所有样本的距离
2、将各个距离按从小到大排序
3、取距离最小的前K个样本
4、计算在这K个样本中,每个类别所占比例
5、返回K个样本中,类别出现概率最大的就是待测样本的类别。
下面以一个例子说明这个过程:
该图主要说明绿色圆形属于蓝色还是红色
当k=3时,位于内侧的圆形内分别有两个红色和一个蓝色,红色概率>蓝色 2/3 > 1/3,所以分类结果属于红色。
当k=5时,位于虚线圆形内分别有两个红色和3个蓝色,红色概率<蓝色 2/5> 3/5,所以分类结果属于蓝色。
本文采用python实现KNN算法,环境python 3.4,具体代码如下:
数据集iris介绍:iris是鸢尾花数据集。分为3类,共有150组数据,每类50组数据,每个数据包含4个属性,分别为花朵,粤片,花瓣的长度,花瓣的宽度。
代码对比了scikit learn中的KNN,最后分类结果差不多0.966
# -*- coding: utf-8 -*-
import pandas as pd
import numpy as np
import glob
import os
from sklearn import cross_validation
from sklearn.neighbors import KNeighborsClassifier
def load_data():
alldata=pd.read_excel('e:/a/iris.xls')
data=alldata.iloc[:,:4]
data=np.array(data)
y=alldata.iloc[:,4]
y=np.array(y)
X_train, X_test, y_train, y_test = cross_validation.train_test_split(data, y, test_size=0.2)
#print(X_train.shape[0])#120
#print(X_train.shape)#(120, 4)
#print(y_train)
return X_train, X_test, y_train, y_test
def calssfiy(x_test,x_train,y_train,k):
trainSize=x_train.shape[0]#行数
#============================================
#计算待测样本与训练集所有样本距离
'''
tile(A,n)功能是将A数组重复n次
'''
comp=np.tile(x_test,(trainSize,1))
disqu=(comp-x_train)**2#矩阵中的每个元素的平方
sqldis=np.sum(disqu,axis=1)#计算行和
distance=np.sqrt(sqldis)
#==============================================
#将各个距离从大到小排序
sortedDist = np.argsort(distance) #argsort函数返回的是数组值从小到大的索引值
classCount={}#主要记录每个类别及其出现次数
for i in range(k):
votey=y_train[sortedDist[i]]#取出前k个样本的标签
classCount[votey]=classCount.get(votey,0)+1#key为votey,如果没有返回0,如果有就加1
#===============================================
#返回K个样本中,类别出现概率最大的就是待测样本的类别
maxCoutn=0
for key ,value in classCount.items() :
if value>maxCoutn:
maxCoutn=value
maxY=key
return maxY
if __name__=='__main__':
X_train, X_test, y_train, y_test=load_data()
X_test_num=X_test.shape[0]
#==================================
print('####采用scikit learn###########')
clf=KNeighborsClassifier()
clf.fit(X_train,y_train)
doc_class_predicted = clf.predict(X_test)
#print(doc_class_predicted )
print(np.mean(doc_class_predicted == y_test))
#===========================================
print('###############')#30
count=0
for i in range(X_test_num):
label=calssfiy(X_test[i],X_train,y_train,5)
if (label==y_test[i]):
count=count+1
accury=float(count/X_test_num)
print(accury)
KNN算法优点:
1.简单,易于理解,易于实现,无需估计参数,无需训练;
2. 适合对稀有事件进行分类;
3.当有新样本加入训练集中,无需重新训练
缺点:
1.该算法在分类时有个主要的不足是,当样本不平衡时,如一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,该样本的K个邻居中大容量类的样本占多数。 该算法只计算“最近的”邻居样本,某一类的样本数量很大,那么或者这类样本并不接近目标样本,或者这类样本很靠近目标样本。无论怎样,数量并不能影响运行结果。
2.该方法的另一个不足之处是计算量较大,因为对每一个待分类的文本都要计算它到全体已知样本的距离,才能求得它的K个最近邻点。
3.K值不好确定,如果k值选择过小,会降低分类的精度,同时放大噪声干扰,如果k值选择过大,如果待分类样本属于训练集中包含数据较少的类,那么选择k个近邻的时候,实际上并不相似的数据也会包含进来,增加了噪声,导致最终分类准确率也会下降。
KNN算法优点:
1.简单,易于理解,易于实现,无需估计参数,无需训练;
2. 适合对稀有事件进行分类;
3.当有新样本加入训练集中,无需重新训练
缺点:
缺点:
1.该算法在分类时有个主要的不足是,当样本不平衡时,如一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,该样本的K个邻居中大容量类的样本占多数。 该算法只计算“最近的”邻居样本,某一类的样本数量很大,那么或者这类样本并不接近目标样本,或者这类样本很靠近目标样本。无论怎样,数量并不能影响运行结果。
2.该方法的另一个不足之处是计算量较大,因为对每一个待分类的文本都要计算它到全体已知样本的距离,才能求得它的K个最近邻点。
3.K值不好确定,如果k值选择过小,会降低分类的精度,同时放大噪声干扰,如果k值选择过大,如果待分类样本属于训练集中包含数据较少的类,那么选择k个近邻的时候,实际上并不相似的数据也会包含进来,增加了噪声,导致最终分类准确率也会下降。

相关文章推荐
- KNN分类算法--python实现
- K-Nearest Neighbor(KNN) 最邻近分类算法及Python实现方式
- K近邻(KNN)算法---Python实现(一)
- kNN分类算法python实现
- 机器学习之k-近邻(kNN)算法与Python实现
- 【JAVA实现】K-近邻(KNN)分类算法
- KNN最邻近规则分类算法实践实现【Python实现】
- 机器学习经典算法详解及Python实现--K近邻(KNN)算法
- <Python><有监督>kNN--近邻分类算法
- 机器学习经典算法详解及Python实现--K近邻(KNN)算法
- K近邻分类算法实现 in Python
- python 实现 knn分类算法 (Iris 数据集)
- 数据挖掘 --- Python实现KNN算法项目 - 水果分类
- 机器学习经典算法详解及Python实现–K近邻(KNN)算法
- k近邻(kNN)算法的Python实现(基于欧氏距离)
- KNN分类算法及python代码实现
- K近邻分类算法实现 in Python
- K近邻分类算法实现 in Python
- K近邻(knn)算法简介及用python实现
- 机器学习经典算法详解及Python实现--K近邻(KNN)算法