梯度提升树GBDT原理
2017-07-08 21:31
211 查看
转载学习:http://blog.csdn.net/a819825294/article/details/51188740,如有侵权,联系删除
提升方法实际采用加法模型(即基函数的线性组合)与前向分布算法。以决策树为基函数的提升方法称为提升树(boosting
tree)。对分类问题决策树是二叉分类树,对回归问题决策树是二叉决策树。提升树模型可以表示为决策树的加法模型:
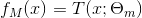
其中,
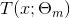
表示决策树;
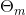
为决策树的参数;M为树的个数
回归问题提升树使用以下前向分布算法:
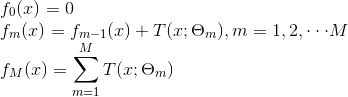
在前向分布算法的第m步,给定当前模型
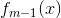
,需求解
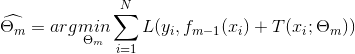
得到
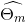
,即第m棵树的参数
当采用平方误差损失函数时,
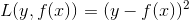
其损失变为
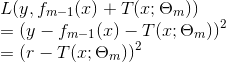
其中,
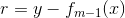
是当前模型拟合数据的残差(residual)。对于平方损失函数,拟合的就是残差;对于一般损失函数(梯度下降),拟合的就是残差的近似值
输入:训练数据集
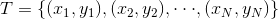
输出:提升树
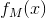
算法流程:
(1)初始化
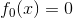
(2)对m = 1,2,…,M
计算残差
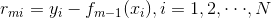
拟合残差学习一个回归树,得到
更新
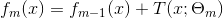
(3)得到回归问题提升树
附sklearn中GBDT文档 地址
这部分整理自网络资源,思路很好,可以借鉴
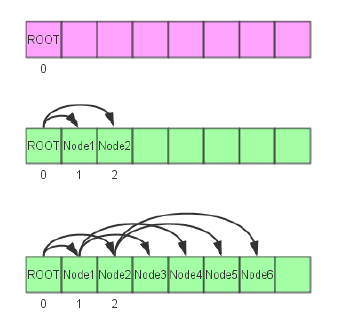
非递归建树
节点的存放
终止条件
树的节点数
树的深度
没有适合分割的节点
特征值排序
在对每个节点进行分割的时候,首先需要遍历所有的特征,然后对每个样本的特征的值进行枚举计算。(CART)
在对单个特征量进行枚举取值之前,我们可以先将该特征量的所有取值进行排序,然后再进行排序。
优点
避免计算重复的value值
方便更佳分割值的确定
减少信息的重复计算
多线程/MPI并行化的实现
通过MPI实现对GBDT的并行化,最主要的步骤是在建树的过程中,由于每个特征值计算最佳分割值是相互独立的,故可以对特征进行平分,再同时进行计算。
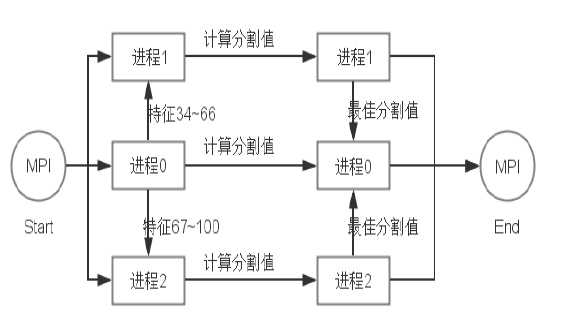
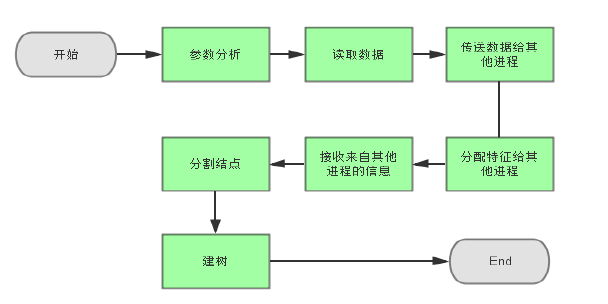
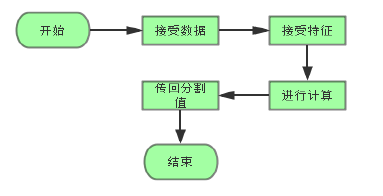
MPI并行化的实现
主线程
其他线程
1.模型
提升方法实际采用加法模型(即基函数的线性组合)与前向分布算法。以决策树为基函数的提升方法称为提升树(boostingtree)。对分类问题决策树是二叉分类树,对回归问题决策树是二叉决策树。提升树模型可以表示为决策树的加法模型:
其中,
表示决策树;
为决策树的参数;M为树的个数
2.学习过程
回归问题提升树使用以下前向分布算法:在前向分布算法的第m步,给定当前模型
,需求解
得到
,即第m棵树的参数
当采用平方误差损失函数时,
其损失变为
其中,
是当前模型拟合数据的残差(residual)。对于平方损失函数,拟合的就是残差;对于一般损失函数(梯度下降),拟合的就是残差的近似值
3.算法
输入:训练数据集输出:提升树
算法流程:
(1)初始化
(2)对m = 1,2,…,M
计算残差
拟合残差学习一个回归树,得到
更新
(3)得到回归问题提升树
附sklearn中GBDT文档 地址
4.GBDT并行
这部分整理自网络资源,思路很好,可以借鉴非递归建树
节点的存放
终止条件
树的节点数
树的深度
没有适合分割的节点
特征值排序
在对每个节点进行分割的时候,首先需要遍历所有的特征,然后对每个样本的特征的值进行枚举计算。(CART)
在对单个特征量进行枚举取值之前,我们可以先将该特征量的所有取值进行排序,然后再进行排序。
优点
避免计算重复的value值
方便更佳分割值的确定
减少信息的重复计算
多线程/MPI并行化的实现
通过MPI实现对GBDT的并行化,最主要的步骤是在建树的过程中,由于每个特征值计算最佳分割值是相互独立的,故可以对特征进行平分,再同时进行计算。
MPI并行化的实现
主线程
其他线程

相关文章推荐
- 梯度提升树(GBDT)原理小结
- 梯度提升树(GBDT)原理小结
- 梯度提升树(GBDT)原理
- 梯度提升树(GBDT)原理小结
- 梯度提升树(GBDT)原理小结
- 梯度提升树(GBDT)原理小结
- 梯度提升树(GBDT)原理小结
- 梯度提升树GBDT原理
- 梯度提升树GBDT原理
- GBDT梯度提升树算法原理小结(一)
- 梯度提升树GBDT原理
- GBDT梯度提升树原理剖析
- GBDT梯度提升树算法原理小结(三)
- 梯度提升树(GBDT)原理小结
- 梯度提升树(GBDT)原理小结
- 梯度提升树(GBDT)原理
- 统计学习方法--提升树模型(Boosting Tree)与梯度提升树(GBDT)
- 【机器学习】GBDT梯度下降提升算法及参数寻优实例
- GBDT(梯度提升决策树)剖析
- Spark2.0机器学习系列之5:GBDT(梯度提升决策树)、GBDT与随机森林差异、参数调试及Scikit代码分析