python使用百度进行爬虫简单学习例子
2017-07-05 14:48
681 查看
http://www.baidu.com/s?wd=python
wd后面的参数就是在百度搜索引擎里面输入的关键字。
分析页面:
获取每一页的链接。
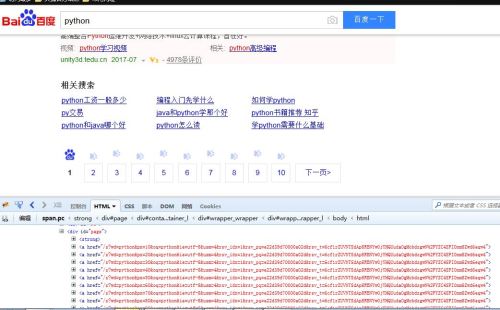
代码:
运行结果
wd后面的参数就是在百度搜索引擎里面输入的关键字。
分析页面:
获取每一页的链接。
代码:
| root@kali:~/py# more table.py import urllib import urllib2 from lxml import etree #输入python关键字进行查询 text = "python" starurl = "http://www.baidu.com/s?wd=%s" % text html = urllib.urlopen(starurl).read() PageUrlList = [] page = etree.HTML(html.lower().decode('utf-8')) #crapy pageurl list #解析出id为page的所有div下的a标签的href属性,如果要显示a标签的内容则把“@href”替换成“text()”即可 hrefs = page.xpath("//div[@id='page']//a/@href") for href in hrefs: hrefurl = "http://www.baidu.com"+href PageUrlList.append(hrefurl) print "list:" print PageUrlList |
| root@kali:~/py# python table.py list: ['http://www.baidu.com/s?wd=python&pn=10&oq=python&ie=utf-8&usm=4&rsv_pq=897a8df20000da9b&rsv_t=075dbfoz2dplnlb7ts%2boyopf06je%2bi1j1whmgcrvjurdkieecwvsl%2bhdvum', 'http://www.baidu.com/s?wd=python&pn=20&oq=python&ie=utf-8&usm=4&rsv_pq=897a8df20000da9b&rsv_t=075dbfoz2dplnlb7ts%2boyopf06je%2bi1j1whmgcrvjurdkieecwvsl%2bhdvum', 'http://www.baidu.com/s?wd=python&pn=30&oq=python&ie=utf-8&usm=4&rsv_pq=897a8df20000da9b&rsv_t=075dbfoz2dplnlb7ts%2boyopf06je%2bi1j1whmgcrvjurdkieecwvsl%2bhdvum', 'http://www.baidu.com/s?wd=python&pn=40&oq=python&ie=utf-8&usm=4&rsv_pq=897a8df20000da9b&rsv_t=075dbfoz2dplnlb7ts%2boyopf06je%2bi1j1whmgcrvjurdkieecwvsl%2bhdvum', 'http://www.baidu.com/s?wd=python&pn=50&oq=python&ie=utf-8&usm=4&rsv_pq=897a8df20000da9b&rsv_t=075dbfoz2dplnlb7ts%2boyopf06je%2bi1j1whmgcrvjurdkieecwvsl%2bhdvum', 'http://www.baidu.com/s?wd=python&pn=60&oq=python&ie=utf-8&usm=4&rsv_pq=897a8df20000da9b&rsv_t=075dbfoz2dplnlb7ts%2boyopf06je%2bi1j1whmgcrvjurdkieecwvsl%2bhdvum', 'http://www.baidu.com/s?wd=python&pn=70&oq=python&ie=utf-8&usm=4&rsv_pq=897a8df20000da9b&rsv_t=075dbfoz2dplnlb7ts%2boyopf06je%2bi1j1whmgcrvjurdkieecwvsl%2bhdvum', 'http://www.baidu.com/s?wd=python&pn=80&oq=python&ie=utf-8&usm=4&rsv_pq=897a8df20000da9b&rsv_t=075dbfoz2dplnlb7ts%2boyopf06je%2bi1j1whmgcrvjurdkieecwvsl%2bhdvum', 'http://www.baidu.com/s?wd=python&pn=90&oq=python&ie=utf-8&usm=4&rsv_pq=897a8df20000da9b&rsv_t=075dbfoz2dplnlb7ts%2boyopf06je%2bi1j1whmgcrvjurdkieecwvsl%2bhdvum', 'http://www.baidu.com/s?wd=python&pn=10&oq=python&ie=utf-8&usm=4&rsv_pq=897a8df20000da9b&rsv_t=075dbfoz2dplnlb7ts%2boyopf06je%2bi1j1whmgcrvjurdkieecwvsl%2bhdvum&rsv_page=1'] |

相关文章推荐
- 使用 Suricata 进行入侵监控(一个简单小例子访问百度)
- 【学习笔记】使用Python对文件进行简单操作
- 【Python3.6爬虫学习记录】(五)Cookie的使用以及简单的爬取知乎
- 【Python3.6爬虫学习记录】(二)使用BeautifulSoup爬取简单静态网页文章
- Python3 爬虫学习(一):urllib库的使用及简单的爬取
- Python学习21:Python中函数的用法,使用函数进行简单的数学运算
- 使用python进行爬虫学习(一)
- python:使用socket模块,进行服务器与客户端简单交互
- socket上http协议应用(使用socket进行http通信的例子,准备好报头以后,简单read/write就可以了)
- Python爬虫学习(1): urllib的使用
- 简单爬虫python实现02——BeautifulSoup的使用
- [Python模块学习]使用base64模块进行二进制数据编码
- libcurl的使用简单例子(python)
- [转] 最简单的使用UDP通信的Python Socket例子
- Python学习之使用Pillow(PIL)进行图像操作方法详解
- 学习淘淘商城第十九课(搭建单机版FastDFS图片服务器以及使用FastDFS-Client客户端进行简单测试)
- 第8章 使用Spring Web Flow--学习一个简单例子
- 萌新的Python学习日记 - 爬虫无影 - 使用BeautifulSoup + css selector 抓取动态网页内容:Knewone
- [Python学习] 简单网络爬虫抓取博客文章及思想介绍
- 简单使用scipy.weave混合使用Python和C++代码的简单例子