python入门系列16―——正则表达式1
2017-07-05 13:02
387 查看
欢迎前往我的个人博客
正则表达式是一个特殊的字符序列,主要检查一个字符串是否与某种模式匹配。
现在,我们来介绍最常用的元字符(metacharacters)——特殊字符和符号,正是它们赋予了正则表达式强大的功能和灵活性。正则表达式中最常见的符号和字符见表
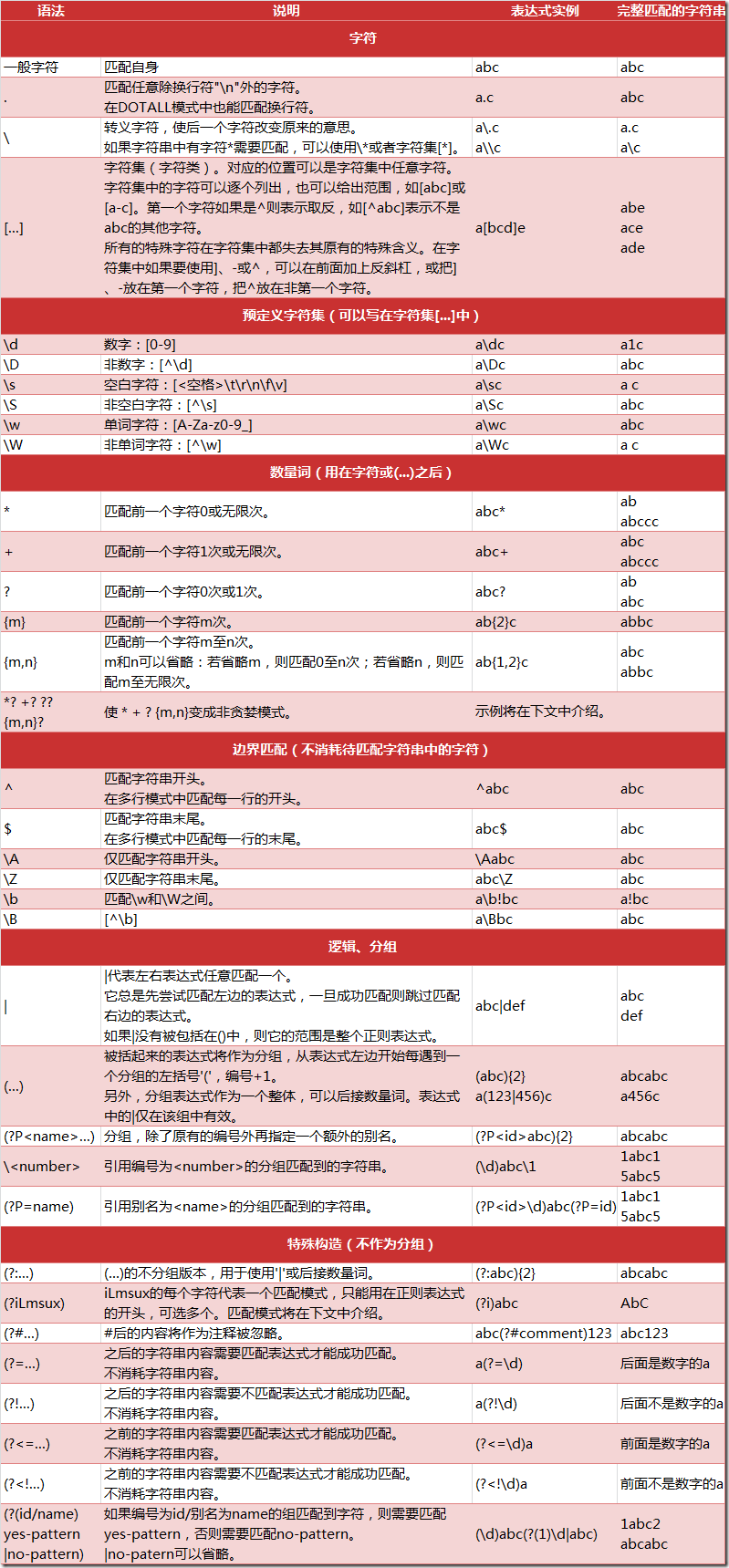
PS:此表来自互联网
re 模块使 Python 语言拥有全部的正则表达式功能。
1.re.match函数
函数从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none。
语法:
string:要匹配的字符串。
flags:标志位,控制匹配方式,比如:是否区分大小写,多行匹配等等
例如:
2.re.search方法
re.search 扫描整个字符串并返回第一个成功的匹配。
函数语法:
earch 和 match 的工作方式一样,不同之处在于 search 会检查
参数字符串任意位置的地方给定正则表达式模式的匹配情况。如果搜索到成功的匹配,会返回一个匹配对象,否则返回 None。
我们来看下区别:
接下来我们利用match和search来学习正则表达式语法中的绝大部分特殊字符和符号
匹配多个字符串:
匹配任意单个字符串:
字符集合[ ]:
重复、特殊字符和子组:
匹配子组:
从字符串的开头或结尾匹配及在单词边界上的匹配:
非某个字符:
正则表达式是一个特殊的字符序列,主要检查一个字符串是否与某种模式匹配。
现在,我们来介绍最常用的元字符(metacharacters)——特殊字符和符号,正是它们赋予了正则表达式强大的功能和灵活性。正则表达式中最常见的符号和字符见表
PS:此表来自互联网
re 模块使 Python 语言拥有全部的正则表达式功能。
1.re.match函数
函数从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none。
语法:
re.match(pattern, string, flags=0)pattern:需要检查的字符串
string:要匹配的字符串。
flags:标志位,控制匹配方式,比如:是否区分大小写,多行匹配等等
例如:
import re
a= re.match("www","www.baidu.com") # 是否在起始位置
print a.group() #输出匹配的字符串
a = re.match("com","www.baidu.com") #因为不是在开始,所以a是None
print a.group() #a为None,所以匹配字符串会报错2.re.search方法
re.search 扫描整个字符串并返回第一个成功的匹配。
函数语法:
re.search(pattern, string, flags=0)匹配成功re.search方法返回一个匹配的对象,否则返回None。
earch 和 match 的工作方式一样,不同之处在于 search 会检查
参数字符串任意位置的地方给定正则表达式模式的匹配情况。如果搜索到成功的匹配,会返回一个匹配对象,否则返回 None。
我们来看下区别:
import re
m = re.match('foo', 'seafood') # no match 匹配失败
if m is not None:
print m.group()
else:
print "匹配失败"
m = re.search('foo', 'seafood') # search()匹配成功
if m is not None:
print m.group()
else:
print "匹配失败"结果:匹配失败 foo
接下来我们利用match和search来学习正则表达式语法中的绝大部分特殊字符和符号
匹配多个字符串:
import re bt = 'hi|hello' m = re.match(bt, 'hi python') if m is not None: print m.group() else: print '匹配失败' m = re.match(bt, 'python') if m is not None: print m.group() else: print '匹配失败' m = re.match(bt, 'python hello') if m is not None: print m.group() else: print '匹配失败' m = re.search(bt, 'python hello!') if m is not None: print m.group() else: print '匹配失败'结果:
hi 匹配失败 匹配失败 hello
匹配任意单个字符串:
import re bt = '.ello' m = re.match(bt, 'hi python') if m is not None: print m.group() else: print '匹配失败' m = re.match(bt, 'hello python') if m is not None: print m.group() else: print '匹配失败' m = re.search(bt, 'python hello!') if m is not None: print m.group() else: print '匹配失败' #多个单字符 bt = '.ell..' m = re.search(bt, 'python h.ello!') if m is not None: print m.group() else: print '匹配失败' #如果想检查小数点本身就需要加\ bt = '\.ello' m = re.search(bt, 'python h.ello!') if m is not None: print m.group() else: print '匹配失败'结果:
匹配失败 hello hello .ello! .ello
字符集合[ ]:
import re bt = '[ab][cd][0-9]' m = re.match(bt, 'ac99') if m is not None: print m.group() else: print '匹配失败' m = re.match(bt, '9ac9') if m is not None: print m.group() else: print '匹配失败' m = re.search(bt, '9ac9') if m is not None: print m.group() else: print '匹配失败'结果:
ac9 匹配失败 ac9
重复、特殊字符和子组:
import re bt = '\w+@(\w+\.)?\w+\.com' #“?”表示此模式可出现 0 次或 1 次 m = re.match(bt, 'python@123.com') if m is not None: print m.group() else: print '匹配失败' m = re.match(bt, 'hi python@123.com') if m is not None: print m.group() else: print '匹配失败' m = re.search(bt, 'hi python@123.com') if m is not None: print m.group() else: print '匹配失败' m = re.search(bt, 'hi python@123.789.com') if m is not None: print m.group() else: print '匹配失败' m = re.search(bt, 'hi python@123.456.789.com') if m is not None: print m.group() else: print '匹配失败' bt = '\w+@(\w+\.)*\w+\.com' #允许任意数量的子域名存在 m = re.search(bt, 'hi python@123.456.com') if m is not None: print m.group() else: print '匹配失败'结果:
python@123.com 匹配失败 python@123.com 匹配失败 python@123.456.com
匹配子组:
import re bt = '\w\w\w-\d\d\d' m = re.match(bt, 'abc-123') if m is not None: print m.group() else: print '匹配失败' m = re.match(bt, 'abc-abc') if m is not None: print m.group() else: print '匹配失败' bt ='(\w\w\w)-(\d\d\d)' m = re.match(bt, 'abc-123') if m is not None: print m.group() print m.group(1) print m.group(2) print m.groups() else: print '匹配失败'结果:
abc-123
匹配失败
abc-123
abc
123
('abc', '123')从字符串的开头或结尾匹配及在单词边界上的匹配:
import re bt = '^hi' #hi 开头的 m = re.match(bt, 'hi hello') if m is not None: print m.group() else: print '匹配失败' m = re.match(bt, 'hello hi') if m is not None: print m.group() else: print '匹配失败' m = re.search(bt, 'hello hi') if m is not None: print m.group() else: print '匹配失败' bt = r'\bhi' #前面的一个 r 表示字符串为非转义的原始字符串,让编译器忽略反斜杠, #也就是忽略转义字符。但是这个字符串里没有反斜杠,所以这个 r 可有可无。 m = re.search(bt, 'hello hi python') if m is not None: print m.group() else: print '匹配失败' m = re.search(bt, 'hellohi python') if m is not None: print m.group() else: print '匹配失败' m = re.search(bt, 'hi hello python ') if m is not None: print m.group() else: print '匹配失败' bt = '\Bhi' m = re.search(bt, 'hellohi python') if m is not None: print m.group() else: print '匹配失败' bt='thon$' #thon结尾的 m = re.search(bt, 'hellohi python') if m is not None: print m.group() else: print '匹配失败' bt='thon$' #thon结尾的 m = re.search(bt, 'python hellohi') if m is not None: print m.group() else: print '匹配失败' bt='^thon$' # 单独 thon 字符串 m = re.search(bt, 'hellohi python') if m is not None: print m.group() else: print '匹配失败' bt='thon$' #单独 thon 字符串 m = re.search(bt, 'hellohi thon') if m is not None: print m.group() else: print '匹配失败'结果:
hi 匹配失败 匹配失败 hi 匹配失败 hi hi thon 匹配失败 匹配失败 thon
非某个字符:
import re bt = '[^abc]x' #非abc的+x m = re.search(bt, 'ax') if m is not None: print m.group() else: print '匹配失败' m = re.search(bt, 'dx') if m is not None: print m.group() else: print '匹配失败'结果:
匹配失败 dx

相关文章推荐
- python入门系列17―——正则表达式2
- Clojure 学习入门(16)—— 正则表达式
- Linux系统编程(16)——正则表达式入门
- python3爬虫之入门和正则表达式
- JavaScript语法入门系列(七) 类和对象(正则表达式RegExp)
- python3爬虫之入门和正则表达式
- Python 学习入门(13)—— 正则表达式
- python3爬虫之入门基础和正则表达式
- python3爬虫之入门和正则表达式
- Python爬虫教程——入门七之正则表达式
- 正则表达式快速入门(python示例)
- Python 学习入门(13)—— 正则表达式
- Python入门篇之正则表达式
- python3爬虫之入门基础和正则表达式
- [转载]Python爬虫入门七之正则表达式
- Python 学习入门(13)—— 正则表达式
- python正则表达式入门笔记
- python正则表达式入门与提高
- Linux系统编程(16)——正则表达式入门
- 给新手一个python正则表达式的入门例子