Linux中的正则表达式和grep使用规范
2017-06-30 23:36
288 查看
正则表达式
概念:
正则表达式,又称规则表达式 。通常被用来检索、替换某个模式(规则)的文本。
正则表达式是一种逻辑公式,就是用一些特定字符或组合。组成一个“规则字符串”,通过该“规则字符串”来表达对字符串的过滤逻辑(匹配)。
特点:
1、逻辑性、功能性强,且具有很强的灵活性。
2、可用简单的正则表达式表示出复杂的字符串过滤逻辑。
用途:
1、可以测试字符串内的模式:比如在给定字符串内查找是否出现邮箱、身份证号的固定格式的字符。
2、替换文本:可以用正则表达式识别文档中的特定文本,用其它文本替换或者删除。
语法:
我们把规定一些特殊语法表示字符类、数量限定符和位置关系,然后将这些特殊语法和普通字符组合在一起表示的一个模式称为正则表达式。
首先我们得知道字符类、数量限定符和位置关系是什么?都有哪些?怎么用?下面我们一一介绍。
例:邮箱:xxxxxxxx@xx.com IP地址:yyy.yyy.yyy.yyy
字符类:
在模式中表示一个字符,但取值范围是一类字符中的任意一个。(如上例中的x和y)

数量限定符:
用来描述模式中某个单元或特定字符出现的次数。(如上例中IP地址每一部分y出现的个数是1-3)

位置限定符:
用来描述模式中各特殊字符和普通字符出现的位置关系。(如邮箱地址必须以.com结尾)
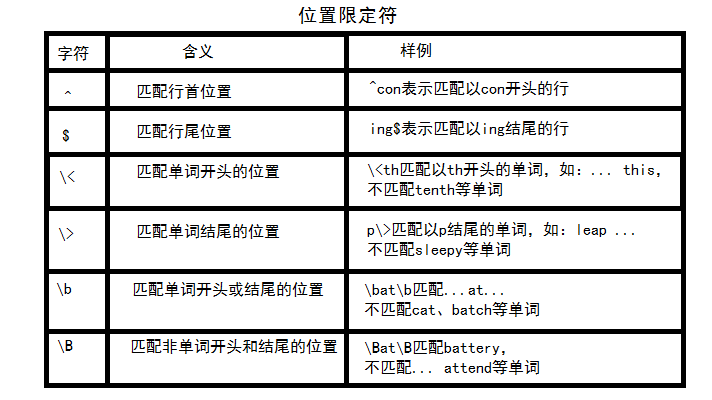
实例:
身份证号的正则表达式:/^[1-9]\d{5}[1-2]\d{3}((0[1-9])|(1[0-2]))((0[1-9])|([1-2]\d)|(3[0-1]))(\d{3}[0-9xX])$/
\d:表示匹配任意数字

gre
4000
p命令:
grep命令是一种强大的文本搜索工具,它支持使用正则表达式,将匹配的行打印出来。(是一个行过滤工具)
grep的选项:
-E:表示可使用扩展正则表达式
-i:忽略字母的大小写进行行过滤
-R:以递归方式查找过滤
-v:如果找到匹配内容则不显示,显示其他没匹配到的
-q:安静模式匹配(无论匹配成功与否均不显示结果)
grep的常见用法:
1、在文件中查找单词“make”
grep “make” file_name 结果返回含有make的文本行
2、在多个文件中查找“make”
grep “make” file1 file2 file3
3、给匹配到的结果配色
grep “make” file_name --color=auto
4、grep和正则表达式搭配使用
1)grep -E “[1-9]+”
2) egrep “[1-9]+”
此处1)和2)结果完全一致,只是两个不同的规范,grep -E是Basic规范,而egrep是Extended规范。
总结:
grep命令是Linux中使用频率较高的一条命令。正则表达式是实际应用中使用非常广泛的一种逻辑公式。所以经常会出现grep和正则表达式的结合使用,所以应该尽可能了解grep的每一个选项和正则表达式的每个特殊符号的意义,并且需要勤加练习才可以应用的得心应手。
概念:
正则表达式,又称规则表达式 。通常被用来检索、替换某个模式(规则)的文本。
正则表达式是一种逻辑公式,就是用一些特定字符或组合。组成一个“规则字符串”,通过该“规则字符串”来表达对字符串的过滤逻辑(匹配)。
特点:
1、逻辑性、功能性强,且具有很强的灵活性。
2、可用简单的正则表达式表示出复杂的字符串过滤逻辑。
用途:
1、可以测试字符串内的模式:比如在给定字符串内查找是否出现邮箱、身份证号的固定格式的字符。
2、替换文本:可以用正则表达式识别文档中的特定文本,用其它文本替换或者删除。
语法:
我们把规定一些特殊语法表示字符类、数量限定符和位置关系,然后将这些特殊语法和普通字符组合在一起表示的一个模式称为正则表达式。
首先我们得知道字符类、数量限定符和位置关系是什么?都有哪些?怎么用?下面我们一一介绍。
例:邮箱:xxxxxxxx@xx.com IP地址:yyy.yyy.yyy.yyy
字符类:
在模式中表示一个字符,但取值范围是一类字符中的任意一个。(如上例中的x和y)
数量限定符:
用来描述模式中某个单元或特定字符出现的次数。(如上例中IP地址每一部分y出现的个数是1-3)
位置限定符:
用来描述模式中各特殊字符和普通字符出现的位置关系。(如邮箱地址必须以.com结尾)
实例:
身份证号的正则表达式:/^[1-9]\d{5}[1-2]\d{3}((0[1-9])|(1[0-2]))((0[1-9])|([1-2]\d)|(3[0-1]))(\d{3}[0-9xX])$/
\d:表示匹配任意数字
gre
4000
p命令:
grep命令是一种强大的文本搜索工具,它支持使用正则表达式,将匹配的行打印出来。(是一个行过滤工具)
grep的选项:
-E:表示可使用扩展正则表达式
-i:忽略字母的大小写进行行过滤
-R:以递归方式查找过滤
-v:如果找到匹配内容则不显示,显示其他没匹配到的
-q:安静模式匹配(无论匹配成功与否均不显示结果)
grep的常见用法:
1、在文件中查找单词“make”
grep “make” file_name 结果返回含有make的文本行
2、在多个文件中查找“make”
grep “make” file1 file2 file3
3、给匹配到的结果配色
grep “make” file_name --color=auto
4、grep和正则表达式搭配使用
1)grep -E “[1-9]+”
2) egrep “[1-9]+”
此处1)和2)结果完全一致,只是两个不同的规范,grep -E是Basic规范,而egrep是Extended规范。
总结:
grep命令是Linux中使用频率较高的一条命令。正则表达式是实际应用中使用非常广泛的一种逻辑公式。所以经常会出现grep和正则表达式的结合使用,所以应该尽可能了解grep的每一个选项和正则表达式的每个特殊符号的意义,并且需要勤加练习才可以应用的得心应手。

相关文章推荐
- Linux下正则表达式和grep命令的使用
- Linux/Unix工具与正则表达式的POSIX规范--awk使用中遇到的坑
- Linux学习-grep与正则表达式使用方法
- linux 命令 grep 不使用 正则表达式
- Linux:grep基本使用、与之配合的正则表达式
- linux grep 基本正则表达式与扩展正则表达式使用解析
- Linux中grep、egrep正则表达式的使用
- Linux下正则表达式和grep命令的使用
- Linux的文本处理工具及grep正则表达式的使用
- Linux下正则表达式的使用及grep工具
- linux系统中grep命令是一种强大的文本搜索工具,它能使用正则表达式搜索文本
- 在Linux中使用grep和egrep结合正则表达式查找字符
- linux grep命令 1.作用 Linux系统中grep命令是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹 配的行打印出来。grep全称是Global Regular Express
- Linux 下 grep 命令的正则表达式规范
- bzgrep命令_Linux bzgrep 命令用法详解:使用正则表达式搜索.bz2压缩包中文件
- 在Linux下正则表达式和grep命令的使用
- linux(5)--补充(管道| / 重定向> / xargs)/find 与xargs结合使用/vi,grep,sed,awk(支持正则表达式的工具程序)
- linux文本处理三剑客之grep家族及其相应的正则表达式使用详解
- Linux基础(三)--grep的使用和基本正则表达式
- Linux正则表达式的使用和基本命令grep、egrep、fgrep的用法