Python基础知识
2017-06-27 17:53
183 查看
一、安装、编译与运行
Python的安装很容易,直接到官网:http://www.python.org/下载安装就可以了。Ubuntu一般都预安装了。没有的话,就可以#apt-get install python。Windows的话直接下载msi包安装即可。Python
程序是通过解释器执行的,所以安装后,可以看到Python提供了两个解析器,一个是IDLE (Python GUI),一个是Python (command line)。前者是一个带GUI界面的版本,后者实际上和在命令提示符下运行python是一样的。运行解释器后,就会有一个命令提示符>>>,在提示符后键入你的程序语句,键入的语句将会立即执行。就像Matlab一样。
另外,Matlab有.m的脚步文件,python也有.py后缀的脚本文件,这个文件除了可以解释执行外,还可以编译运行,编译后运行速度要比解释运行要快。
例如,我要打印一个helloWorld。
方法1:直接在解释器中,>>> print ‘helloWorld’。
方法2:将这句代码写到一个文件中,例如hello.py。运行这个文件有三种方式:
1)在终端中:python hello.py
2)先编译成.pyc文件:
import py_compile
py_compile.compile("hello.py")
再在终端中:python hello.pyc
3)在终端中:
python -O -m py_compile hello.py
python hello.pyo
编译成.pyc和.pyo文件后,执行的速度会更快。所以一般一些重复性并多次调用的代码会被编译成这两种可执行的方式来待调用。
二、变量、运算与表达式
这里没什么好说的,有其他语言的编程基础的话都没什么问题。和Matlab的相似度比较大。这块差别不是很大。具体如下:
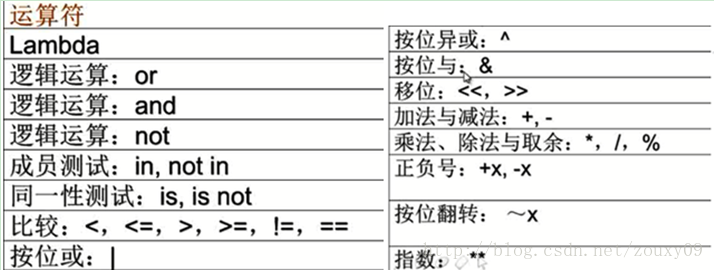
需要注意的一个是:5/2 等于2,5.0/2才等于2.5。
[python] view
plain copy
###################################
### compute #######
# raw_input() get input from keyboard to string type
# So we should transfer to int type
# Some new support computing type:
# and or not in is < <= != == | ^ & << + - / % ~ **
print 'Please input a number:'
number = int(raw_input())
number += 1
print number**2 # ** means ^
print number and 1
print number or 1
print not number
5/2 # is 2
5.0/2 # is 2.5, should be noted
三、数据类型
1、数字
通常的int, long,float,long等等都被支持。而且会看你的具体数字来定义变量的类型。如下:
[python] view
plain copy
###################################
### type of value #######
# int, long, float
# do not need to define the type of value, python will
# do this according to your value
num = 1 # stored as int type
num = 1111111111111 # stored as long int type
num = 1.0 # stored as float type
num = 12L # L stands for long type
num = 1 + 12j # j stands for complex type
num = '1' # string type
2、字符串
单引号,双引号和三引号都可以用来定义字符串。三引号可以定义特别格式的字符串。字符串作为一种序列类型,支持像Matlab一样的索引访问和切片访问。
[python] view
plain copy
###################################
### type of string #######
num = "1" # string type
num = "Let's go" # string type
num = "He's \"old\"" # string type
mail = "Xiaoyi: \n hello \n I am you!"
mail = """Xiaoyi:
hello
I am you!
""" # special string format
string = 'xiaoyi' # get value by index
copy = string[0] + string[1] + string[2:6] # note: [2:6] means [2 5] or[2 6)
copy = string[:4] # start from 1
copy = string[2:] # to end
copy = string[::1] # step is 1, from start to end
copy = string[::2] # step is 2
copy = string[-1] # means 'i', the last one
copy = string[-4:-2:-1] # means 'yoa', -1 step controls direction
memAddr = id(num) # id(num) get the memory address of num
type(num) # get the type of num
3、元组
元组tuple用()来定义。相当于一个可以存储不同类型数据的一个数组。可以用索引来访问,但需要注意的一点是,里面的元素不能被修改。
[python] view
plain copy
###################################
### sequence type #######
## can access the elements by index or slice
## include: string, tuple(or array? structure? cell?), list
# basis operation of sequence type
firstName = 'Zou'
lastName = 'Xiaoyi'
len(string) # the length
name = firstName + lastName # concatenate 2 string
firstName * 3 # repeat firstName 3 times
'Z' in firstName # check contain or not, return true
string = '123'
max(string)
min(string)
cmp(firstName, lastName) # return 1, -1 or 0
## tuple(or array? structure? cell?)
## define this type using ()
user = ("xiaoyi", 25, "male")
name = user[0]
age = user[1]
gender = user[2]
t1 = () # empty tuple
t2 = (2, ) # when tuple has only one element, we should add a extra comma
user[1] = 26 # error!! the elements can not be changed
name, age, gender = user # can get three element respectively
a, b, c = (1, 2, 3)
4、列表
列表list用[]来定义。它和元组的功能一样,不同的一点是,里面的元素可以修改。List是一个类,支持很多该类定义的方法,这些方法可以用来对list进行操作。
[python] view
plain copy
## list type (the elements can be modified)
## define this type using []
userList = ["xiaoyi", 25, "male"]
name = userList[0]
age = userList[1]
gender = userList[2]
userList[3] = 88888 # error! access out of range, this is different with Matlab
userList.append(8888) # add new elements
"male" in userList # search
userList[2] = 'female' # can modify the element (the memory address not change)
userList.remove(8888) # remove element
userList.remove(userList[2]) # remove element
del(userList[1]) # use system operation api
## help(list.append)
################################
######## object and class ######
## object = property + method
## python treats anything as class, here the list type is a class,
## when we define a list "userList", so we got a object, and we use
## its method to operate the elements
5、字典
字典dictionary用{}来定义。它的优点是定义像key-value这种键值对的结构,就像struct结构体的功能一样。它也支持字典类支持的方法进行创建和操作。
[python] view
plain copy
################################
######## dictionary type ######
## define this type using {}
item = ['name', 'age', 'gender']
value = ['xiaoyi', '25', 'male']
zip(item, value) # zip() will produce a new list:
# [('name', 'xiaoyi'), ('age', '25'), ('gender', 'male')]
# but we can not define their corresponding relationship
# and we can define this relationship use dictionary type
# This can be defined as a key-value manner
# dic = {key1: value1, key2: value2, ...}, key and value can be any type
dic = {'name': 'xiaoyi', 'age': 25, 'gender': 'male'}
dic = {1: 'zou', 'age':25, 'gender': 'male'}
# and we access it like this: dic[key1], the key as a index
print dic['name']
print dic[1]
# another methods create dictionary
fdict = dict(['x', 1], ['y', 2]) # factory mode
ddict = {}.fromkeys(('x', 'y'), -1) # built-in mode, default value is the same which is none
# access by for circle
for key in dic
print key
print dic[key]
# add key or elements to dictionary, because dictionary is out of sequence,
# so we can directly and a key-value pair like this:
dic['tel'] = 88888
# update or delete the elements
del dic[1] # delete this key
dic.pop('tel') # show and delete this key
dic.clear() # clear the dictionary
del dic # delete the dictionary
dic.get(1) # get the value of key
dic.get(1, 'error') # return a user-define message if the dictionary do not contain the key
dic.keys()
dic.values()
dic.has_key(key)
# dictionary has many operations, please use help to check out
四、流程控制
在这块,Python与其它大多数语言有个非常不同的地方,Python语言使用缩进块来表示程序逻辑(其它大多数语言使用大括号等)。例如:
if age < 21:
print("你不能买酒。")
print("不过你能买口香糖。")
print("这句话处于if语句块的外面。")
这个代码相当于c语言的:
if (age < 21)
{
print("你不能买酒。")
print("不过你能买口香糖。")
}
print("这句话处于if语句块的外面。")
可以看到,Python语言利用缩进表示语句块的开始和退出(Off-side规则),而非使用花括号或者某种关键字。增加缩进表示语句块的开始(注意前面有个:号),而减少缩进则表示语句块的退出。根据PEP的规定,必须使用4个空格来表示每级缩进(不清楚4个空格的规定如何,在实际编写中可以自定义空格数,但是要满足每级缩进间空格数相等)。使用Tab字符和其它数目的空格虽然都可以编译通过,但不符合编码规范。
为了使我们自己编写的程序能很好的兼容别人的程序,我们最好还是按规范来,用四个空格来缩减(注意,要么都是空格,要是么都制表符,千万别混用)。
1、if-else
If-else用来判断一些条件,以执行满足某种条件的代码。
[python] view
plain copy
################################
######## procedure control #####
## if else
if expression: # bool type and do not forget the colon
statement(s) # use four space key
if expression:
statement(s) # error!!!! should use four space key
if 1<2:
print 'ok, ' # use four space key
print 'yeah' # use the same number of space key
if True: # true should be big letter True
print 'true'
def fun():
return 1
if fun():
print 'ok'
else:
print 'no'
con = int(raw_input('please input
4000
a number:'))
if con < 2:
print 'small'
elif con > 3:
print 'big'
else:
print 'middle'
if 1 < 2:
if 2 < 3:
print 'yeah'
else:
print 'no'
print 'out'
else:
print 'bad'
if 1<2 and 2<3 or 2 < 4 not 0: # and, or, not
print 'yeah'
2、for
&n
7d786
bsp; for的作用是循环执行某段代码。还可以用来遍历我们上面所提到的序列类型的变量。
[python] view
plain copy
################################
######## procedure control #####
## for
for iterating_val in sequence:
statements(s)
# sequence type can be string, tuple or list
for i in "abcd":
print i
for i in [1, 2, 3, 4]:
print i
# range(start, end, step), if not set step, default is 1,
# if not set start, default is 0, should be noted that it is [start, end), not [start, end]
range(5) # [0, 1, 2, 3, 4]
range(1, 5) # [1, 2, 3, 4]
range(1, 10, 2) # [1, 3, 5, 7, 9]
for i in range(1, 100, 1):
print i
# ergodic for basis sequence
fruits = ['apple', 'banana', 'mango']
for fruit in range(len(fruits)):
print 'current fruit: ', fruits[fruit]
# ergodic for dictionary
dic = {1: 111, 2: 222, 5: 555}
for x in dic:
print x, ': ', dic[x]
dic.items() # return [(1, 111), (2, 222), (5, 555)]
for key,value in dic.items(): # because we can: a,b=[1,2]
print key, ': ', value
else:
print 'ending'
################################
import time
# we also can use: break, continue to control process
for x in range(1, 11):
print x
time.sleep(1) # sleep 1s
if x == 3:
pass # do nothing
if x == 2:
continue
if x == 6:
break
if x == 7:
exit() # exit the whole program
print '#'*50
3、while
while的用途也是循环。它首先检查在它后边的循环条件,若条件表达式为真,它就执行冒号后面的语句块,然后再次测试循环条件,直至为假。冒号后面的缩近语句块为循环体。
[python] view
plain copy
################################
######## procedure control #####
## while
while expression:
statement(s)
while True:
print 'hello'
x = raw_input('please input something, q for quit:')
if x == 'q':
break
else:
print 'ending'
4、switch
其实Python并没有提供switch结构,但我们可以通过字典和函数轻松的进行构造。例如:
[python] view
plain copy
#############################
## switch ####
## this structure do not support by python
## but we can implement it by using dictionary and function
## cal.py ##
#!/usr/local/python
from __future__ import division
# if used this, 5/2=2.5, 6/2=3.0
def add(x, y):
return x + y
def sub(x, y):
return x - y
def mul(x, y):
return x * y
def div(x, y):
return x / y
operator = {"+": add, "-": sub, "*": mul, "/": div}
operator["+"](1, 2) # the same as add(1, 2)
operator["%"](1, 2) # error, not have key "%", but the below will not
operator.get("+")(1, 2) # the same as add(1, 2)
def cal(x, o, y):
print operator.get(o)(x, y)
cal(2, "+", 3)
# this method will effect than if-else
五、函数
1、自定义函数
在Python中,使用def语句来创建函数:
[python] view
plain copy
################################
######## function #####
def functionName(parameters): # no parameters is ok
bodyOfFunction
def add(a, b):
return a+b # if we do not use a return, any defined function will return default None
a = 100
b = 200
sum = add(a, b)
##### function.py #####
#!/usr/bin/python
#coding:utf8 # support chinese
def add(a = 1, b = 2): # default parameters
return a+b # can return any type of data
# the followings are all ok
add()
add(2)
add(y = 1)
add(3, 4)
###### the global and local value #####
## global value: defined outside any function, and can be used
## in anywhere, even in functions, this should be noted
## local value: defined inside a function, and can only be used
## in its own function
## the local value will cover the global if they have the same name
val = 100 # global value
def fun():
print val # here will access the val = 100
print val # here will access the val = 100, too
def fun():
a = 100 # local value
print a
print a # here can not access the a = 100
def fun():
global a = 100 # declare as a global value
print a
print a # here can not access the a = 100, because fun() not be called yet
fun()
print a # here can access the a = 100
############################
## other types of parameters
def fun(x):
print x
# the follows are all ok
fun(10) # int
fun('hello') # string
fun(('x', 2, 3)) # tuple
fun([1, 2, 3]) # list
fun({1: 1, 2: 2}) # dictionary
## tuple
def fun(x, y):
print "%s : %s" % (x,y) # %s stands for string
fun('Zou', 'xiaoyi')
tu = ('Zou', 'xiaoyi')
fun(*tu) # can transfer tuple parameter like this
## dictionary
def fun(name = "name", age = 0):
print "name: %s" % name
print "age: " % age
dic = {name: "xiaoyi", age: 25} # the keys of dictionary should be same as fun()
fun(**dic) # can transfer dictionary parameter like this
fun(age = 25, name = 'xiaoyi') # the result is the same
## the advantage of dictionary is can specify value name
#############################
## redundancy parameters ####
## the tuple
def fun(x, *args): # the extra parameters will stored in args as tuple type
print x
print args
# the follows are ok
fun(10)
fun(10, 12, 24) # x = 10, args = (12, 24)
## the dictionary
def fun(x, **args): # the extra parameters will stored in args as dictionary type
print x
print args
# the follows are ok
fun(10)
fun(x = 10, y = 12, z = 15) # x = 10, args = {'y': 12, 'z': 15}
# mix of tuple and dictionary
def fun(x, *args, **kwargs):
print x
print args
print kwargs
fun(1, 2, 3, 4, y = 10, z = 12) # x = 1, args = (2, 3, 4), kwargs = {'y': 10, 'z': 12}
2、Lambda函数
Lambda函数用来定义一个单行的函数,其便利在于:
[python] view
plain copy
#############################
## lambda function ####
## define a fast single line function
fun = lambda x,y : x*y # fun is a object of function class
fun(2, 3)
# like
def fun(x, y):
return x*y
## recursion
# 5=5*4*3*2*1, n!
def recursion(n):
if n > 0:
return n * recursion(n-1) ## wrong
def mul(x, y):
return x * y
numList = range(1, 5)
reduce(mul, numList) # 5! = 120
reduce(lambda x,y : x*y, numList) # 5! = 120, the advantage of lambda function avoid defining a function
### list expression
numList = [1, 2, 6, 7]
filter(lambda x : x % 2 == 0, numList)
print [x for x in numList if x % 2 == 0] # the same as above
map(lambda x : x * 2 + 10, numList)
print [x * 2 + 10 for x in numList] # the same as above
3、Python内置函数
Python内置了很多函数,他们都是一个个的.py文件,在python的安装目录可以找到。弄清它有那些函数,对我们的高效编程非常有用。这样就可以避免重复的劳动了。下面也只是列出一些常用的:
[python] view
plain copy
###################################
## built-in function of python ####
## if do not how to use, please use help()
abs, max, min, len, divmod, pow, round, callable,
isinstance, cmp, range, xrange, type, id, int()
list(), tuple(), hex(), oct(), chr(), ord(), long()
callable # test a function whether can be called or not, if can, return true
# or test a function is exit or not
isinstance # test type
numList = [1, 2]
if type(numList) == type([]):
print "It is a list"
if isinstance(numList, list): # the same as above, return true
print "It is a list"
for i in range(1, 10001) # will create a 10000 list, and cost memory
for i in xrange(1, 10001)# do not create such a list, no memory is cost
## some basic functions about string
str = 'hello world'
str.capitalize() # 'Hello World', first letter transfer to big
str.replace("hello", "good") # 'good world'
ip = "192.168.1.123"
ip.split('.') # return ['192', '168', '1', '123']
help(str.split)
import string
str = 'hello world'
string.replace(str, "hello", "good") # 'good world'
## some basic functions about sequence
len, max, min
# filter(function or none, sequence)
def fun(x):
if x > 5:
return True
numList = [1, 2, 6, 7]
filter(fun, numList) # get [6, 7], if fun return True, retain the element, otherwise delete it
filter(lambda x : x % 2 == 0, numList)
# zip()
name = ["me", "you"]
age = [25, 26]
tel = ["123", "234"]
zip(name, age, tel) # return a list: [('me', 25, '123'), ('you', 26, '234')]
# map()
map(None, name, age, tel) # also return a list: [('me', 25, '123'), ('you', 26, '234')]
test = ["hello1", "hello2", "hello3"]
zip(name, age, tel, test) # return [('me', 25, '123', 'hello1'), ('you', 26, '234', 'hello2')]
map(None, name, age, tel, test) # return [('me', 25, '123', 'hello1'), ('you', 26, '234', 'hello2'), (None, None, None, 'hello3')]
a = [1, 3, 5]
b = [2, 4, 6]
def mul(x, y):
return x*y
map(mul, a, b) # return [2, 12, 30]
# reduce()
reduce(lambda x, y: x+y, [1, 2, 3, 4, 5]) # return ((((1+2)+3)+4)+5)
六、包与模块
1、模块module
python中每一个.py脚本定义一个模块,所以我们可以在一个.py脚本中定义一个实现某个功能的函数或者脚本,这样其他的.py脚本就可以调用这个模块了。调用的方式有三种,如下:
[python] view
plain copy
###################################
## package and module ####
## a .py file define a module which can be used in other script
## as a script, the name of module is the same as the name of the .py file
## and we use the name to import to a new script
## e.g., items.py, import items
## python contains many .py files, which we can import and use
# vi cal.py
def add(x, y):
return x + y
def sub(x, y):
return x - y
def mul(x, y):
return x * y
def div(x, y):
return x / y
print "Your answer is: ", add(3, 5)
if __name__ == "__main__"
r = add(1, 3)
print r
# vi test.py
import cal # will expand cal.py here
# so, this will execute the following code in cal.py
# print "Your answer is: ", add(3, 5)
# it will print "Your answer is: 8"
# but as we import cal.py, we just want to use those functions
# so the above code can do this for me, the r=add(1, 3) will not execute
result = cal.add(1, 2)
print result
# or
import cal as c
result = c.add(1, 2)
# or
from cal import add
result = add(1, 2)
2、包package
python 的每个.py文件执行某种功能,那有时候我们需要多个.py完成某个更大的功能,或者我们需要将同类功能的.py文件组织到一个地方,这样就可以很方便我们的使用。模块可以按目录组织为包,创建一个包的步骤:
# 1、建立一个名字为包名字的文件夹
# 2、在该文件夹下创建一个__init__.py空文件
# 3、根据需要在该文件夹下存放.py脚本文件、已编译拓展及子包
# 4、import pack.m1,pack.m2 pack.m3
[python] view
plain copy
#### package 包
## python 的模块可以按目录组织为包,创建一个包的步骤:
# 1、建立一个名字为包名字的文件夹
# 2、在该文件夹下创建一个__init__.py 空文件
# 3、根据需要在该文件夹下存放.py脚本文件、已编译拓展及子包
# 4、import pack.m1, pack.m2 pack.m3
mkdir calSet
cd calSet
touch __init_.py
cp cal.py .
# vi test.py
import calSet.cal
result = calSet.cal.add(1, 2)
print result
七、正则表达式
正则表达式,(英语:RegularExpression,在代码中常简写为regex、regexp或RE),计算机科学的一个概念。正则表达式使用单个字符串来描述、匹配一系列符合某个句法规则的字符串。在很多文本编辑器里,正则表达式通常被用来检索、替换那些符合某个模式的文本。
Python提供了功能强大的正则表达式引擎re,我们可以利用这个模块来利用正则表达式进行字符串操作。我们用import re来导入这个模块。
正则表达式包含了很多规则,如果能灵活的使用,在匹配字符串方面是非常高效率的。更多的规则,我们需要查阅其他的资料。
1、元字符
很多,一些常用的元字符的使用方法如下:
[python] view
plain copy
##############################
## 正则表达式 RE
## re module in python
import re
rule = r'abc' # r prefix, the rule you want to check in a given string
re.findall(rule, "aaaaabcaaaaaabcaa") # return ['abc', 'abc']
# [] 用来指定一个字符集 [abc] 表示 abc其中任意一个字符符合都可以
rule = r"t[io]p"
re.findall(rule, "tip tep twp top") # return ['tip', 'top']
# ^ 表示 补集,例如[^io] 表示除i和o外的其他字符
rule = r"t[^io]p"
re.findall(rule, "tip tep twp top") # return ['tep', 'twp']
# ^ 也可以 匹配行首,表示要在行首才匹配,其他地方不匹配
rule = r"^hello"
re.findall(rule, "hello tep twp hello") # return ['hello']
re.findall(rule, "tep twp hello") # return []
# $ 表示匹配行尾
rule = r"hello$"
re.findall(rule, "hello tep twp hello") # return ['hello']
re.findall(rule, "hello tep twp") # return []
# - 表示范围
rule = r"x[0123456789]x" # the same as
rule = r"x[0-9]x"
re.findall(rule, "x1x x4x xxx") # return ['x1x', 'x4x']
rule = r"x[a-zA-Z]x"
# \ 表示转义符
rule = r"\^hello"
re.findall(rule, "hello twp ^hello") # return ['^hello']
# \d 匹配一个数字字符。等价于[0-9]。
# \D 匹配一个非数字字符。等价于[^0-9]。
# \n 匹配一个换行符。等价于\x0a和\cJ。
# \r 匹配一个回车符。等价于\x0d和\cM。
# \s 匹配任何空白字符,包括空格、制表符、换页符等等。等价于[ \f\n\r\t\v]。
# \S 匹配任何非空白字符。等价于[^ \f\n\r\t\v]。
# \t 匹配一个制表符。等价于\x09和\cI。
# \w 匹配包括下划线的任何单词字符。等价于“[A-Za-z0-9_]”。
# \W 匹配任何非单词字符。等价于“[^A-Za-z0-9_]”。
# {} 表示重复规则
# 例如我们要查找匹配是否是 广州的号码,020-八位数据
# 以下三种方式都可以实现
rule = r"^020-\d\d\d\d\d\d\d\d$"
rule = r"^020-\d{8}$" # {8} 表示前面的规则重复8次
rule = r"^020-[0-9]{8}$"
re.findall(rule, "020-23546813") # return ['020-23546813']
# * 表示将其前面的字符重复0或者多次
rule = r"ab*"
re.findall(rule, "a") # return ['a']
re.findall(rule, "ab") # return ['ab']
# + 表示将其前面的字符重复1或者多次
rule = r"ab+"
re.findall(rule, "a") # return []
re.findall(rule, "ab") # return ['ab']
re.findall(rule, "abb") # return ['abb']
# ? 表示前面的字符可有可无
rule = r"^020-?\d{8}$"
re.findall(rule, "02023546813") # return ['020-23546813
re.findall(rule, "020-23546813") # return ['020-23546813']
re.findall(rule, "020--23546813") # return []
# ? 表示非贪婪匹配
rule = r"ab+?"
re.findall(rule, "abbbbbbb") # return ['ab']
# {} 可以表示范围
rule = r"a{1,3}"
re.findall(rule, "a") # return ['a']
re.findall(rule, "aa") # return ['aa']
re.findall(rule, "aaa") # return ['aaa']
re.findall(rule, "aaaa") # return ['aaa', 'a']
## compile re string
rule = r"\d{3,4}-?\d{8}"
re.findall(rule, "020-23546813")
# faster when you compile it
# return a object
p_tel = re.compile(rule)
p_tel.findall("020-23546813")
# the parameter re.I 不区分大小写
name_re = re.compile(r"xiaoyi", re.I)
name_re.findall("Xiaoyi")
name_re.findall("XiaoYi")
name_re.findall("xiAOyi")
2、常用函数
Re模块作为一个对象,它还支持很多的操作,例如:
[python] view
plain copy
# the object contain some methods we can use
# match 去搜索字符串开头,如果匹配对,那就返回一个对象,否则返回空
obj = name_re.match('Xiaoyi, Zou')
# search 去搜索字符串(任何位置),如果匹配对,那就返回一个对象
obj = name_re.search('Zou, Xiaoyi')
# 然后可以用它来进行判断某字符串是否存在我们的正则表达式
if obj:
pass
# findall 返回一个满足正则的列表
name_re.findall("Xiaoyi")
# finditer 返回一个满足正则的迭代器
name_re.finditer("Xiaoyi")
# 正则替换
rs = r"z..x"
re.sub(rs, 'python', 'zoux ni ziox me') # return 'python ni python me'
re.subn(rs, 'python', 'zoux ni ziox me') # return ('python ni python me', 2), contain a number
# 正则切片
str = "123+345-32*78"
re.split(r'[\+\-\*]', str) # return ['123', '345', '32', '78']
# 可以打印re模块支持的属性和方法,然后用help
dir(re)
##### 编译正则表达式式 可以加入一些属性,可以增加很多功能
# 多行匹配
str = """
hello xiaoyi
xiaoyi hello
hello zou
xiaoyi hello
"""
re.findall(r'xiaoyi', str, re.M)
3、分组
分组有两个作用,它用()来定义一个组,组内的规则只对组内有效。
[python] view
plain copy
# () 分组
email = r"\w{3}@\w+(\.com|\.cn|\.org)"
re.match(email, "zzz@scut.com")
re.match(email, "zzz@scut.cn")
re.match(email, "zzz@scut.org")
另外,分组可以优先返回分组内匹配的字符串。
[python] view
plain copy
# 另外,分组可以优先返回分组内匹配的字符串
str = """
idk hello name=zou yes ok d
hello name=xiaoyi yes no dksl
dfi lkasf dfkdf hello name=zouxy yes d
"""
r1 = r"hello name=.+ yes"
re.findall(r1, str) # return ['hello name=zou yes', 'hello name=xiaoyi yes', 'hello name=zouxy yes']
r2 = r"hello name=(.+) yes"
re.findall(r2, str) # return ['zou', 'xiaoyi', 'zouxy']
# 可以看到,它会匹配整个正则表达式,但只会返回()括号分组内的字符串,
# 用这个属性,我们就可以进行爬虫,抓取一些想要的数据
4、一个小实例-爬虫
这个实例利用上面的正则和分组的优先返回特性来实现一个小爬虫算法。它的功能是到一个给定的网址里面将.jpg后缀的图片全部下载下来。
[python] view
plain copy
## 一个小爬虫
## 下载贴吧 或 空间中的所有图片
## getJpg.py
#!/usr/bin/python
import re
import urllib
# Get the source code of a website
def getHtml(url):
print 'Getting html source code...'
page = urllib.open(url)
html = page.read()
return html
# Open the website and check up the address of images,
# and find the common features to decide the re_rule
def getImageAddrList(html):
print 'Getting all address of images...'
rule = r"src=\"(.+\.jpg)\" pic_ext"
imReg = re.compile(rule)
imList = re.findall(imReg, html)
return imList
def getImage(imList):
print 'Downloading...'
name = 1;
for imgurl in imList:
urllib.urlretrieve(imgurl, '%s.jpg' % name)
name += 1
print 'Got ', len(imList), ' images!'
## main
htmlAddr = "http://tieba.baidu.com/p/2510089409"
html = getHtml(htmlAddr)
imList = getImageAddrList(html)
getImage(imList)
八、深拷贝与浅拷贝
Python中对数据的复制有两个需要注意的差别:
浅拷贝:对引用对象的拷贝(只拷贝父对象),深拷贝:对对象资源的拷贝。具体的差别如下:
[python] view
plain copy
##############################
### memory operation
## 浅拷贝:对引用对象的拷贝(只拷贝父对象)
## 深拷贝:对对象资源的拷贝
a = [1, 2, 3]
b = a # id(a) == id (b), 同一个标签,相当于引用
a.append(4) # a = [1, 2, 3, 4], and b also change to = [1, 2, 3, 4]
import copy
a = [1, 2, ['a', 'b']] # 二元列表
c = copy.copy(a) # id(c) != id(a)
a.append('d') # a = [1, 2, ['a', 'b'], 'd'] but c keeps not changed
# 但只属于浅拷贝,只拷贝父对象
# 所以 id(a[0]) == id(c[0]),也就是说对a追加的元素不影响c,
# 但修改a被拷贝的数据后,c的对应数据也会改变,因为拷贝不会改变元素的地址
a[2].append('d') # will change c, too
a[1] = 3 # will change c, too
# 深拷贝
d = copy.deepcopy(a) # 全部拷贝,至此恩断义绝,两者各走
# 各的阳关道和独木桥,以后毫无瓜葛
九、文件与目录
1、文件读写
Python的文件操作和其他的语言没有太大的差别。通过open或者file类来访问。但python支持了很多的方法,以支持文件内容和list等类型的交互。具体如下:
[python] view
plain copy
########################
## file and directory
# file_handler = open(filename, mode)
# mode is the same as other program langurage
## read
# method 1
fin = open('./test.txt')
fin.read()
fin.close()
# method 2, class file
fin = file('./test.txt')
fin.read()
fin.close()
## write
fin = open('./test.txt', 'r+') # r, r+, w, w+, a, a+, b, U
fin.write('hello')
fin.close()
### 文件对象的方法
## help(file)
for i in open('test.txt'):
print i
str = fin.readline() # 每次读取一行
list = fin.readlines() # 读取多行,返回一个列表,每行作为列表的一个元素
fin.next() # 读取改行,指向下一行
# 用列表来写入多行
fin.writelines(list)
# 移动指针
fin.seek(0, 0)
fin.seek(0, 1)
fin.seek(-1, 2)
# 提交更新
fin.flush() # 平时写数据需要close才真正写入文件,这个函数可以立刻写入文件
2、OS模块
os模块提供了很多对系统的操作。例如对目录的操作等。我们需要用import os来插入这个模块以便使用。
[python] view
plain copy
#########################
## OS module
## directory operation should import this
import os
os.mkdir('xiaoyi') # mkdir
os.makedirs('a/b/c', mode = 666) # 创建分级的目录
os.listdir() # ls 返回当前层所有文件或者文件夹名到一个列表中(不包括子目录)
os.chdir() # cd
os.getcwd() # pwd
os.rmdir() # rm
3、目录遍历
目录遍历的实现可以做很多普遍的功能,例如杀毒软件,垃圾清除软件,文件搜索软件等等。因为他们都涉及到了扫描某目录下所有的包括子目录下的文件。所以需要对目录进行遍历。在这里我们可以使用两种方法对目录进行遍历:
1)递归
[python] view
plain copy
#!/usr/bin/python
#coding:utf8
import os
def dirList(path):
fileList = os.listdir(path)
allFile = []
for fileName in fileList:
# allFile.append(dirPath + '/' + fileName) # the same as below
filePath = os.path.join(path, fileName)
if os.path.isdir(filePath):
dirList(filePath)
allFile.append(filePath)
return allFile
2)os.walk函数
[python] view
plain copy
# os.walk 返回一个生成器,每次是一个三元组 [目录, 子目录, 文件]
gen = os.walk('/')
for path, dir, filelist in os.walk('/'):
for filename in filelist:
os.path.join(path, filename)
十、异常处理
异常意味着错误,未经处理的异常会中止程序运行。而异常抛出机制,为程序开发人员提供一种在运行时发现错误,并进行恢复处理,然后继续执行的能力。
[python] view
plain copy
###################################
### 异常处理
# 异常抛出机制,为程序开发人员提供一种在运行时发现错误,
# 进行恢复处理,然后继续执行的能力
# 用try去尝试执行一些代码,如果错误,就抛出异常,
# 异常由except来捕获,并由我们写代码来处理这种异常
try:
fin = open("abc.txt")
print hello
### your usually process code here
except IOError, msg:
print "On such file!"
### your code to handle this error
except NameError, msg:
print msg
### your code to handle this error
finally: # 不管上面有没有异常,这个代码块都会被执行
print 'ok'
# 抛出异常,异常类型要满足python内定义的
if filename == "hello":
raise TypeError("Nothing!!")
Python的安装很容易,直接到官网:http://www.python.org/下载安装就可以了。Ubuntu一般都预安装了。没有的话,就可以#apt-get install python。Windows的话直接下载msi包安装即可。Python
程序是通过解释器执行的,所以安装后,可以看到Python提供了两个解析器,一个是IDLE (Python GUI),一个是Python (command line)。前者是一个带GUI界面的版本,后者实际上和在命令提示符下运行python是一样的。运行解释器后,就会有一个命令提示符>>>,在提示符后键入你的程序语句,键入的语句将会立即执行。就像Matlab一样。
另外,Matlab有.m的脚步文件,python也有.py后缀的脚本文件,这个文件除了可以解释执行外,还可以编译运行,编译后运行速度要比解释运行要快。
例如,我要打印一个helloWorld。
方法1:直接在解释器中,>>> print ‘helloWorld’。
方法2:将这句代码写到一个文件中,例如hello.py。运行这个文件有三种方式:
1)在终端中:python hello.py
2)先编译成.pyc文件:
import py_compile
py_compile.compile("hello.py")
再在终端中:python hello.pyc
3)在终端中:
python -O -m py_compile hello.py
python hello.pyo
编译成.pyc和.pyo文件后,执行的速度会更快。所以一般一些重复性并多次调用的代码会被编译成这两种可执行的方式来待调用。
二、变量、运算与表达式
这里没什么好说的,有其他语言的编程基础的话都没什么问题。和Matlab的相似度比较大。这块差别不是很大。具体如下:
需要注意的一个是:5/2 等于2,5.0/2才等于2.5。
[python] view
plain copy
###################################
### compute #######
# raw_input() get input from keyboard to string type
# So we should transfer to int type
# Some new support computing type:
# and or not in is < <= != == | ^ & << + - / % ~ **
print 'Please input a number:'
number = int(raw_input())
number += 1
print number**2 # ** means ^
print number and 1
print number or 1
print not number
5/2 # is 2
5.0/2 # is 2.5, should be noted
三、数据类型
1、数字
通常的int, long,float,long等等都被支持。而且会看你的具体数字来定义变量的类型。如下:
[python] view
plain copy
###################################
### type of value #######
# int, long, float
# do not need to define the type of value, python will
# do this according to your value
num = 1 # stored as int type
num = 1111111111111 # stored as long int type
num = 1.0 # stored as float type
num = 12L # L stands for long type
num = 1 + 12j # j stands for complex type
num = '1' # string type
2、字符串
单引号,双引号和三引号都可以用来定义字符串。三引号可以定义特别格式的字符串。字符串作为一种序列类型,支持像Matlab一样的索引访问和切片访问。
[python] view
plain copy
###################################
### type of string #######
num = "1" # string type
num = "Let's go" # string type
num = "He's \"old\"" # string type
mail = "Xiaoyi: \n hello \n I am you!"
mail = """Xiaoyi:
hello
I am you!
""" # special string format
string = 'xiaoyi' # get value by index
copy = string[0] + string[1] + string[2:6] # note: [2:6] means [2 5] or[2 6)
copy = string[:4] # start from 1
copy = string[2:] # to end
copy = string[::1] # step is 1, from start to end
copy = string[::2] # step is 2
copy = string[-1] # means 'i', the last one
copy = string[-4:-2:-1] # means 'yoa', -1 step controls direction
memAddr = id(num) # id(num) get the memory address of num
type(num) # get the type of num
3、元组
元组tuple用()来定义。相当于一个可以存储不同类型数据的一个数组。可以用索引来访问,但需要注意的一点是,里面的元素不能被修改。
[python] view
plain copy
###################################
### sequence type #######
## can access the elements by index or slice
## include: string, tuple(or array? structure? cell?), list
# basis operation of sequence type
firstName = 'Zou'
lastName = 'Xiaoyi'
len(string) # the length
name = firstName + lastName # concatenate 2 string
firstName * 3 # repeat firstName 3 times
'Z' in firstName # check contain or not, return true
string = '123'
max(string)
min(string)
cmp(firstName, lastName) # return 1, -1 or 0
## tuple(or array? structure? cell?)
## define this type using ()
user = ("xiaoyi", 25, "male")
name = user[0]
age = user[1]
gender = user[2]
t1 = () # empty tuple
t2 = (2, ) # when tuple has only one element, we should add a extra comma
user[1] = 26 # error!! the elements can not be changed
name, age, gender = user # can get three element respectively
a, b, c = (1, 2, 3)
4、列表
列表list用[]来定义。它和元组的功能一样,不同的一点是,里面的元素可以修改。List是一个类,支持很多该类定义的方法,这些方法可以用来对list进行操作。
[python] view
plain copy
## list type (the elements can be modified)
## define this type using []
userList = ["xiaoyi", 25, "male"]
name = userList[0]
age = userList[1]
gender = userList[2]
userList[3] = 88888 # error! access out of range, this is different with Matlab
userList.append(8888) # add new elements
"male" in userList # search
userList[2] = 'female' # can modify the element (the memory address not change)
userList.remove(8888) # remove element
userList.remove(userList[2]) # remove element
del(userList[1]) # use system operation api
## help(list.append)
################################
######## object and class ######
## object = property + method
## python treats anything as class, here the list type is a class,
## when we define a list "userList", so we got a object, and we use
## its method to operate the elements
5、字典
字典dictionary用{}来定义。它的优点是定义像key-value这种键值对的结构,就像struct结构体的功能一样。它也支持字典类支持的方法进行创建和操作。
[python] view
plain copy
################################
######## dictionary type ######
## define this type using {}
item = ['name', 'age', 'gender']
value = ['xiaoyi', '25', 'male']
zip(item, value) # zip() will produce a new list:
# [('name', 'xiaoyi'), ('age', '25'), ('gender', 'male')]
# but we can not define their corresponding relationship
# and we can define this relationship use dictionary type
# This can be defined as a key-value manner
# dic = {key1: value1, key2: value2, ...}, key and value can be any type
dic = {'name': 'xiaoyi', 'age': 25, 'gender': 'male'}
dic = {1: 'zou', 'age':25, 'gender': 'male'}
# and we access it like this: dic[key1], the key as a index
print dic['name']
print dic[1]
# another methods create dictionary
fdict = dict(['x', 1], ['y', 2]) # factory mode
ddict = {}.fromkeys(('x', 'y'), -1) # built-in mode, default value is the same which is none
# access by for circle
for key in dic
print key
print dic[key]
# add key or elements to dictionary, because dictionary is out of sequence,
# so we can directly and a key-value pair like this:
dic['tel'] = 88888
# update or delete the elements
del dic[1] # delete this key
dic.pop('tel') # show and delete this key
dic.clear() # clear the dictionary
del dic # delete the dictionary
dic.get(1) # get the value of key
dic.get(1, 'error') # return a user-define message if the dictionary do not contain the key
dic.keys()
dic.values()
dic.has_key(key)
# dictionary has many operations, please use help to check out
四、流程控制
在这块,Python与其它大多数语言有个非常不同的地方,Python语言使用缩进块来表示程序逻辑(其它大多数语言使用大括号等)。例如:
if age < 21:
print("你不能买酒。")
print("不过你能买口香糖。")
print("这句话处于if语句块的外面。")
这个代码相当于c语言的:
if (age < 21)
{
print("你不能买酒。")
print("不过你能买口香糖。")
}
print("这句话处于if语句块的外面。")
可以看到,Python语言利用缩进表示语句块的开始和退出(Off-side规则),而非使用花括号或者某种关键字。增加缩进表示语句块的开始(注意前面有个:号),而减少缩进则表示语句块的退出。根据PEP的规定,必须使用4个空格来表示每级缩进(不清楚4个空格的规定如何,在实际编写中可以自定义空格数,但是要满足每级缩进间空格数相等)。使用Tab字符和其它数目的空格虽然都可以编译通过,但不符合编码规范。
为了使我们自己编写的程序能很好的兼容别人的程序,我们最好还是按规范来,用四个空格来缩减(注意,要么都是空格,要是么都制表符,千万别混用)。
1、if-else
If-else用来判断一些条件,以执行满足某种条件的代码。
[python] view
plain copy
################################
######## procedure control #####
## if else
if expression: # bool type and do not forget the colon
statement(s) # use four space key
if expression:
statement(s) # error!!!! should use four space key
if 1<2:
print 'ok, ' # use four space key
print 'yeah' # use the same number of space key
if True: # true should be big letter True
print 'true'
def fun():
return 1
if fun():
print 'ok'
else:
print 'no'
con = int(raw_input('please input
4000
a number:'))
if con < 2:
print 'small'
elif con > 3:
print 'big'
else:
print 'middle'
if 1 < 2:
if 2 < 3:
print 'yeah'
else:
print 'no'
print 'out'
else:
print 'bad'
if 1<2 and 2<3 or 2 < 4 not 0: # and, or, not
print 'yeah'
2、for
&n
7d786
bsp; for的作用是循环执行某段代码。还可以用来遍历我们上面所提到的序列类型的变量。
[python] view
plain copy
################################
######## procedure control #####
## for
for iterating_val in sequence:
statements(s)
# sequence type can be string, tuple or list
for i in "abcd":
print i
for i in [1, 2, 3, 4]:
print i
# range(start, end, step), if not set step, default is 1,
# if not set start, default is 0, should be noted that it is [start, end), not [start, end]
range(5) # [0, 1, 2, 3, 4]
range(1, 5) # [1, 2, 3, 4]
range(1, 10, 2) # [1, 3, 5, 7, 9]
for i in range(1, 100, 1):
print i
# ergodic for basis sequence
fruits = ['apple', 'banana', 'mango']
for fruit in range(len(fruits)):
print 'current fruit: ', fruits[fruit]
# ergodic for dictionary
dic = {1: 111, 2: 222, 5: 555}
for x in dic:
print x, ': ', dic[x]
dic.items() # return [(1, 111), (2, 222), (5, 555)]
for key,value in dic.items(): # because we can: a,b=[1,2]
print key, ': ', value
else:
print 'ending'
################################
import time
# we also can use: break, continue to control process
for x in range(1, 11):
print x
time.sleep(1) # sleep 1s
if x == 3:
pass # do nothing
if x == 2:
continue
if x == 6:
break
if x == 7:
exit() # exit the whole program
print '#'*50
3、while
while的用途也是循环。它首先检查在它后边的循环条件,若条件表达式为真,它就执行冒号后面的语句块,然后再次测试循环条件,直至为假。冒号后面的缩近语句块为循环体。
[python] view
plain copy
################################
######## procedure control #####
## while
while expression:
statement(s)
while True:
print 'hello'
x = raw_input('please input something, q for quit:')
if x == 'q':
break
else:
print 'ending'
4、switch
其实Python并没有提供switch结构,但我们可以通过字典和函数轻松的进行构造。例如:
[python] view
plain copy
#############################
## switch ####
## this structure do not support by python
## but we can implement it by using dictionary and function
## cal.py ##
#!/usr/local/python
from __future__ import division
# if used this, 5/2=2.5, 6/2=3.0
def add(x, y):
return x + y
def sub(x, y):
return x - y
def mul(x, y):
return x * y
def div(x, y):
return x / y
operator = {"+": add, "-": sub, "*": mul, "/": div}
operator["+"](1, 2) # the same as add(1, 2)
operator["%"](1, 2) # error, not have key "%", but the below will not
operator.get("+")(1, 2) # the same as add(1, 2)
def cal(x, o, y):
print operator.get(o)(x, y)
cal(2, "+", 3)
# this method will effect than if-else
五、函数
1、自定义函数
在Python中,使用def语句来创建函数:
[python] view
plain copy
################################
######## function #####
def functionName(parameters): # no parameters is ok
bodyOfFunction
def add(a, b):
return a+b # if we do not use a return, any defined function will return default None
a = 100
b = 200
sum = add(a, b)
##### function.py #####
#!/usr/bin/python
#coding:utf8 # support chinese
def add(a = 1, b = 2): # default parameters
return a+b # can return any type of data
# the followings are all ok
add()
add(2)
add(y = 1)
add(3, 4)
###### the global and local value #####
## global value: defined outside any function, and can be used
## in anywhere, even in functions, this should be noted
## local value: defined inside a function, and can only be used
## in its own function
## the local value will cover the global if they have the same name
val = 100 # global value
def fun():
print val # here will access the val = 100
print val # here will access the val = 100, too
def fun():
a = 100 # local value
print a
print a # here can not access the a = 100
def fun():
global a = 100 # declare as a global value
print a
print a # here can not access the a = 100, because fun() not be called yet
fun()
print a # here can access the a = 100
############################
## other types of parameters
def fun(x):
print x
# the follows are all ok
fun(10) # int
fun('hello') # string
fun(('x', 2, 3)) # tuple
fun([1, 2, 3]) # list
fun({1: 1, 2: 2}) # dictionary
## tuple
def fun(x, y):
print "%s : %s" % (x,y) # %s stands for string
fun('Zou', 'xiaoyi')
tu = ('Zou', 'xiaoyi')
fun(*tu) # can transfer tuple parameter like this
## dictionary
def fun(name = "name", age = 0):
print "name: %s" % name
print "age: " % age
dic = {name: "xiaoyi", age: 25} # the keys of dictionary should be same as fun()
fun(**dic) # can transfer dictionary parameter like this
fun(age = 25, name = 'xiaoyi') # the result is the same
## the advantage of dictionary is can specify value name
#############################
## redundancy parameters ####
## the tuple
def fun(x, *args): # the extra parameters will stored in args as tuple type
print x
print args
# the follows are ok
fun(10)
fun(10, 12, 24) # x = 10, args = (12, 24)
## the dictionary
def fun(x, **args): # the extra parameters will stored in args as dictionary type
print x
print args
# the follows are ok
fun(10)
fun(x = 10, y = 12, z = 15) # x = 10, args = {'y': 12, 'z': 15}
# mix of tuple and dictionary
def fun(x, *args, **kwargs):
print x
print args
print kwargs
fun(1, 2, 3, 4, y = 10, z = 12) # x = 1, args = (2, 3, 4), kwargs = {'y': 10, 'z': 12}
2、Lambda函数
Lambda函数用来定义一个单行的函数,其便利在于:
[python] view
plain copy
#############################
## lambda function ####
## define a fast single line function
fun = lambda x,y : x*y # fun is a object of function class
fun(2, 3)
# like
def fun(x, y):
return x*y
## recursion
# 5=5*4*3*2*1, n!
def recursion(n):
if n > 0:
return n * recursion(n-1) ## wrong
def mul(x, y):
return x * y
numList = range(1, 5)
reduce(mul, numList) # 5! = 120
reduce(lambda x,y : x*y, numList) # 5! = 120, the advantage of lambda function avoid defining a function
### list expression
numList = [1, 2, 6, 7]
filter(lambda x : x % 2 == 0, numList)
print [x for x in numList if x % 2 == 0] # the same as above
map(lambda x : x * 2 + 10, numList)
print [x * 2 + 10 for x in numList] # the same as above
3、Python内置函数
Python内置了很多函数,他们都是一个个的.py文件,在python的安装目录可以找到。弄清它有那些函数,对我们的高效编程非常有用。这样就可以避免重复的劳动了。下面也只是列出一些常用的:
[python] view
plain copy
###################################
## built-in function of python ####
## if do not how to use, please use help()
abs, max, min, len, divmod, pow, round, callable,
isinstance, cmp, range, xrange, type, id, int()
list(), tuple(), hex(), oct(), chr(), ord(), long()
callable # test a function whether can be called or not, if can, return true
# or test a function is exit or not
isinstance # test type
numList = [1, 2]
if type(numList) == type([]):
print "It is a list"
if isinstance(numList, list): # the same as above, return true
print "It is a list"
for i in range(1, 10001) # will create a 10000 list, and cost memory
for i in xrange(1, 10001)# do not create such a list, no memory is cost
## some basic functions about string
str = 'hello world'
str.capitalize() # 'Hello World', first letter transfer to big
str.replace("hello", "good") # 'good world'
ip = "192.168.1.123"
ip.split('.') # return ['192', '168', '1', '123']
help(str.split)
import string
str = 'hello world'
string.replace(str, "hello", "good") # 'good world'
## some basic functions about sequence
len, max, min
# filter(function or none, sequence)
def fun(x):
if x > 5:
return True
numList = [1, 2, 6, 7]
filter(fun, numList) # get [6, 7], if fun return True, retain the element, otherwise delete it
filter(lambda x : x % 2 == 0, numList)
# zip()
name = ["me", "you"]
age = [25, 26]
tel = ["123", "234"]
zip(name, age, tel) # return a list: [('me', 25, '123'), ('you', 26, '234')]
# map()
map(None, name, age, tel) # also return a list: [('me', 25, '123'), ('you', 26, '234')]
test = ["hello1", "hello2", "hello3"]
zip(name, age, tel, test) # return [('me', 25, '123', 'hello1'), ('you', 26, '234', 'hello2')]
map(None, name, age, tel, test) # return [('me', 25, '123', 'hello1'), ('you', 26, '234', 'hello2'), (None, None, None, 'hello3')]
a = [1, 3, 5]
b = [2, 4, 6]
def mul(x, y):
return x*y
map(mul, a, b) # return [2, 12, 30]
# reduce()
reduce(lambda x, y: x+y, [1, 2, 3, 4, 5]) # return ((((1+2)+3)+4)+5)
六、包与模块
1、模块module
python中每一个.py脚本定义一个模块,所以我们可以在一个.py脚本中定义一个实现某个功能的函数或者脚本,这样其他的.py脚本就可以调用这个模块了。调用的方式有三种,如下:
[python] view
plain copy
###################################
## package and module ####
## a .py file define a module which can be used in other script
## as a script, the name of module is the same as the name of the .py file
## and we use the name to import to a new script
## e.g., items.py, import items
## python contains many .py files, which we can import and use
# vi cal.py
def add(x, y):
return x + y
def sub(x, y):
return x - y
def mul(x, y):
return x * y
def div(x, y):
return x / y
print "Your answer is: ", add(3, 5)
if __name__ == "__main__"
r = add(1, 3)
print r
# vi test.py
import cal # will expand cal.py here
# so, this will execute the following code in cal.py
# print "Your answer is: ", add(3, 5)
# it will print "Your answer is: 8"
# but as we import cal.py, we just want to use those functions
# so the above code can do this for me, the r=add(1, 3) will not execute
result = cal.add(1, 2)
print result
# or
import cal as c
result = c.add(1, 2)
# or
from cal import add
result = add(1, 2)
2、包package
python 的每个.py文件执行某种功能,那有时候我们需要多个.py完成某个更大的功能,或者我们需要将同类功能的.py文件组织到一个地方,这样就可以很方便我们的使用。模块可以按目录组织为包,创建一个包的步骤:
# 1、建立一个名字为包名字的文件夹
# 2、在该文件夹下创建一个__init__.py空文件
# 3、根据需要在该文件夹下存放.py脚本文件、已编译拓展及子包
# 4、import pack.m1,pack.m2 pack.m3
[python] view
plain copy
#### package 包
## python 的模块可以按目录组织为包,创建一个包的步骤:
# 1、建立一个名字为包名字的文件夹
# 2、在该文件夹下创建一个__init__.py 空文件
# 3、根据需要在该文件夹下存放.py脚本文件、已编译拓展及子包
# 4、import pack.m1, pack.m2 pack.m3
mkdir calSet
cd calSet
touch __init_.py
cp cal.py .
# vi test.py
import calSet.cal
result = calSet.cal.add(1, 2)
print result
七、正则表达式
正则表达式,(英语:RegularExpression,在代码中常简写为regex、regexp或RE),计算机科学的一个概念。正则表达式使用单个字符串来描述、匹配一系列符合某个句法规则的字符串。在很多文本编辑器里,正则表达式通常被用来检索、替换那些符合某个模式的文本。
Python提供了功能强大的正则表达式引擎re,我们可以利用这个模块来利用正则表达式进行字符串操作。我们用import re来导入这个模块。
正则表达式包含了很多规则,如果能灵活的使用,在匹配字符串方面是非常高效率的。更多的规则,我们需要查阅其他的资料。
1、元字符
很多,一些常用的元字符的使用方法如下:
[python] view
plain copy
##############################
## 正则表达式 RE
## re module in python
import re
rule = r'abc' # r prefix, the rule you want to check in a given string
re.findall(rule, "aaaaabcaaaaaabcaa") # return ['abc', 'abc']
# [] 用来指定一个字符集 [abc] 表示 abc其中任意一个字符符合都可以
rule = r"t[io]p"
re.findall(rule, "tip tep twp top") # return ['tip', 'top']
# ^ 表示 补集,例如[^io] 表示除i和o外的其他字符
rule = r"t[^io]p"
re.findall(rule, "tip tep twp top") # return ['tep', 'twp']
# ^ 也可以 匹配行首,表示要在行首才匹配,其他地方不匹配
rule = r"^hello"
re.findall(rule, "hello tep twp hello") # return ['hello']
re.findall(rule, "tep twp hello") # return []
# $ 表示匹配行尾
rule = r"hello$"
re.findall(rule, "hello tep twp hello") # return ['hello']
re.findall(rule, "hello tep twp") # return []
# - 表示范围
rule = r"x[0123456789]x" # the same as
rule = r"x[0-9]x"
re.findall(rule, "x1x x4x xxx") # return ['x1x', 'x4x']
rule = r"x[a-zA-Z]x"
# \ 表示转义符
rule = r"\^hello"
re.findall(rule, "hello twp ^hello") # return ['^hello']
# \d 匹配一个数字字符。等价于[0-9]。
# \D 匹配一个非数字字符。等价于[^0-9]。
# \n 匹配一个换行符。等价于\x0a和\cJ。
# \r 匹配一个回车符。等价于\x0d和\cM。
# \s 匹配任何空白字符,包括空格、制表符、换页符等等。等价于[ \f\n\r\t\v]。
# \S 匹配任何非空白字符。等价于[^ \f\n\r\t\v]。
# \t 匹配一个制表符。等价于\x09和\cI。
# \w 匹配包括下划线的任何单词字符。等价于“[A-Za-z0-9_]”。
# \W 匹配任何非单词字符。等价于“[^A-Za-z0-9_]”。
# {} 表示重复规则
# 例如我们要查找匹配是否是 广州的号码,020-八位数据
# 以下三种方式都可以实现
rule = r"^020-\d\d\d\d\d\d\d\d$"
rule = r"^020-\d{8}$" # {8} 表示前面的规则重复8次
rule = r"^020-[0-9]{8}$"
re.findall(rule, "020-23546813") # return ['020-23546813']
# * 表示将其前面的字符重复0或者多次
rule = r"ab*"
re.findall(rule, "a") # return ['a']
re.findall(rule, "ab") # return ['ab']
# + 表示将其前面的字符重复1或者多次
rule = r"ab+"
re.findall(rule, "a") # return []
re.findall(rule, "ab") # return ['ab']
re.findall(rule, "abb") # return ['abb']
# ? 表示前面的字符可有可无
rule = r"^020-?\d{8}$"
re.findall(rule, "02023546813") # return ['020-23546813
re.findall(rule, "020-23546813") # return ['020-23546813']
re.findall(rule, "020--23546813") # return []
# ? 表示非贪婪匹配
rule = r"ab+?"
re.findall(rule, "abbbbbbb") # return ['ab']
# {} 可以表示范围
rule = r"a{1,3}"
re.findall(rule, "a") # return ['a']
re.findall(rule, "aa") # return ['aa']
re.findall(rule, "aaa") # return ['aaa']
re.findall(rule, "aaaa") # return ['aaa', 'a']
## compile re string
rule = r"\d{3,4}-?\d{8}"
re.findall(rule, "020-23546813")
# faster when you compile it
# return a object
p_tel = re.compile(rule)
p_tel.findall("020-23546813")
# the parameter re.I 不区分大小写
name_re = re.compile(r"xiaoyi", re.I)
name_re.findall("Xiaoyi")
name_re.findall("XiaoYi")
name_re.findall("xiAOyi")
2、常用函数
Re模块作为一个对象,它还支持很多的操作,例如:
[python] view
plain copy
# the object contain some methods we can use
# match 去搜索字符串开头,如果匹配对,那就返回一个对象,否则返回空
obj = name_re.match('Xiaoyi, Zou')
# search 去搜索字符串(任何位置),如果匹配对,那就返回一个对象
obj = name_re.search('Zou, Xiaoyi')
# 然后可以用它来进行判断某字符串是否存在我们的正则表达式
if obj:
pass
# findall 返回一个满足正则的列表
name_re.findall("Xiaoyi")
# finditer 返回一个满足正则的迭代器
name_re.finditer("Xiaoyi")
# 正则替换
rs = r"z..x"
re.sub(rs, 'python', 'zoux ni ziox me') # return 'python ni python me'
re.subn(rs, 'python', 'zoux ni ziox me') # return ('python ni python me', 2), contain a number
# 正则切片
str = "123+345-32*78"
re.split(r'[\+\-\*]', str) # return ['123', '345', '32', '78']
# 可以打印re模块支持的属性和方法,然后用help
dir(re)
##### 编译正则表达式式 可以加入一些属性,可以增加很多功能
# 多行匹配
str = """
hello xiaoyi
xiaoyi hello
hello zou
xiaoyi hello
"""
re.findall(r'xiaoyi', str, re.M)
3、分组
分组有两个作用,它用()来定义一个组,组内的规则只对组内有效。
[python] view
plain copy
# () 分组
email = r"\w{3}@\w+(\.com|\.cn|\.org)"
re.match(email, "zzz@scut.com")
re.match(email, "zzz@scut.cn")
re.match(email, "zzz@scut.org")
另外,分组可以优先返回分组内匹配的字符串。
[python] view
plain copy
# 另外,分组可以优先返回分组内匹配的字符串
str = """
idk hello name=zou yes ok d
hello name=xiaoyi yes no dksl
dfi lkasf dfkdf hello name=zouxy yes d
"""
r1 = r"hello name=.+ yes"
re.findall(r1, str) # return ['hello name=zou yes', 'hello name=xiaoyi yes', 'hello name=zouxy yes']
r2 = r"hello name=(.+) yes"
re.findall(r2, str) # return ['zou', 'xiaoyi', 'zouxy']
# 可以看到,它会匹配整个正则表达式,但只会返回()括号分组内的字符串,
# 用这个属性,我们就可以进行爬虫,抓取一些想要的数据
4、一个小实例-爬虫
这个实例利用上面的正则和分组的优先返回特性来实现一个小爬虫算法。它的功能是到一个给定的网址里面将.jpg后缀的图片全部下载下来。
[python] view
plain copy
## 一个小爬虫
## 下载贴吧 或 空间中的所有图片
## getJpg.py
#!/usr/bin/python
import re
import urllib
# Get the source code of a website
def getHtml(url):
print 'Getting html source code...'
page = urllib.open(url)
html = page.read()
return html
# Open the website and check up the address of images,
# and find the common features to decide the re_rule
def getImageAddrList(html):
print 'Getting all address of images...'
rule = r"src=\"(.+\.jpg)\" pic_ext"
imReg = re.compile(rule)
imList = re.findall(imReg, html)
return imList
def getImage(imList):
print 'Downloading...'
name = 1;
for imgurl in imList:
urllib.urlretrieve(imgurl, '%s.jpg' % name)
name += 1
print 'Got ', len(imList), ' images!'
## main
htmlAddr = "http://tieba.baidu.com/p/2510089409"
html = getHtml(htmlAddr)
imList = getImageAddrList(html)
getImage(imList)
八、深拷贝与浅拷贝
Python中对数据的复制有两个需要注意的差别:
浅拷贝:对引用对象的拷贝(只拷贝父对象),深拷贝:对对象资源的拷贝。具体的差别如下:
[python] view
plain copy
##############################
### memory operation
## 浅拷贝:对引用对象的拷贝(只拷贝父对象)
## 深拷贝:对对象资源的拷贝
a = [1, 2, 3]
b = a # id(a) == id (b), 同一个标签,相当于引用
a.append(4) # a = [1, 2, 3, 4], and b also change to = [1, 2, 3, 4]
import copy
a = [1, 2, ['a', 'b']] # 二元列表
c = copy.copy(a) # id(c) != id(a)
a.append('d') # a = [1, 2, ['a', 'b'], 'd'] but c keeps not changed
# 但只属于浅拷贝,只拷贝父对象
# 所以 id(a[0]) == id(c[0]),也就是说对a追加的元素不影响c,
# 但修改a被拷贝的数据后,c的对应数据也会改变,因为拷贝不会改变元素的地址
a[2].append('d') # will change c, too
a[1] = 3 # will change c, too
# 深拷贝
d = copy.deepcopy(a) # 全部拷贝,至此恩断义绝,两者各走
# 各的阳关道和独木桥,以后毫无瓜葛
九、文件与目录
1、文件读写
Python的文件操作和其他的语言没有太大的差别。通过open或者file类来访问。但python支持了很多的方法,以支持文件内容和list等类型的交互。具体如下:
[python] view
plain copy
########################
## file and directory
# file_handler = open(filename, mode)
# mode is the same as other program langurage
## read
# method 1
fin = open('./test.txt')
fin.read()
fin.close()
# method 2, class file
fin = file('./test.txt')
fin.read()
fin.close()
## write
fin = open('./test.txt', 'r+') # r, r+, w, w+, a, a+, b, U
fin.write('hello')
fin.close()
### 文件对象的方法
## help(file)
for i in open('test.txt'):
print i
str = fin.readline() # 每次读取一行
list = fin.readlines() # 读取多行,返回一个列表,每行作为列表的一个元素
fin.next() # 读取改行,指向下一行
# 用列表来写入多行
fin.writelines(list)
# 移动指针
fin.seek(0, 0)
fin.seek(0, 1)
fin.seek(-1, 2)
# 提交更新
fin.flush() # 平时写数据需要close才真正写入文件,这个函数可以立刻写入文件
2、OS模块
os模块提供了很多对系统的操作。例如对目录的操作等。我们需要用import os来插入这个模块以便使用。
[python] view
plain copy
#########################
## OS module
## directory operation should import this
import os
os.mkdir('xiaoyi') # mkdir
os.makedirs('a/b/c', mode = 666) # 创建分级的目录
os.listdir() # ls 返回当前层所有文件或者文件夹名到一个列表中(不包括子目录)
os.chdir() # cd
os.getcwd() # pwd
os.rmdir() # rm
3、目录遍历
目录遍历的实现可以做很多普遍的功能,例如杀毒软件,垃圾清除软件,文件搜索软件等等。因为他们都涉及到了扫描某目录下所有的包括子目录下的文件。所以需要对目录进行遍历。在这里我们可以使用两种方法对目录进行遍历:
1)递归
[python] view
plain copy
#!/usr/bin/python
#coding:utf8
import os
def dirList(path):
fileList = os.listdir(path)
allFile = []
for fileName in fileList:
# allFile.append(dirPath + '/' + fileName) # the same as below
filePath = os.path.join(path, fileName)
if os.path.isdir(filePath):
dirList(filePath)
allFile.append(filePath)
return allFile
2)os.walk函数
[python] view
plain copy
# os.walk 返回一个生成器,每次是一个三元组 [目录, 子目录, 文件]
gen = os.walk('/')
for path, dir, filelist in os.walk('/'):
for filename in filelist:
os.path.join(path, filename)
十、异常处理
异常意味着错误,未经处理的异常会中止程序运行。而异常抛出机制,为程序开发人员提供一种在运行时发现错误,并进行恢复处理,然后继续执行的能力。
[python] view
plain copy
###################################
### 异常处理
# 异常抛出机制,为程序开发人员提供一种在运行时发现错误,
# 进行恢复处理,然后继续执行的能力
# 用try去尝试执行一些代码,如果错误,就抛出异常,
# 异常由except来捕获,并由我们写代码来处理这种异常
try:
fin = open("abc.txt")
print hello
### your usually process code here
except IOError, msg:
print "On such file!"
### your code to handle this error
except NameError, msg:
print msg
### your code to handle this error
finally: # 不管上面有没有异常,这个代码块都会被执行
print 'ok'
# 抛出异常,异常类型要满足python内定义的
if filename == "hello":
raise TypeError("Nothing!!")

相关文章推荐
- [Python]类的基础知识
- 适用于PHP开发人员的Python基础知识
- Python基础知识(五)--数据类型
- 适用于 PHP 开发人员的 Python 基础知识
- python基础知识(第一章)
- python模块之bsddb: bdb高性能嵌入式数据库 1.基础知识
- Python基础知识(四)--函数
- Python基础知识(七)--字符串详解
- Python基础知识(四)--函数
- Python基础知识(二)--控制流语句
- 学学python(1)一些基础知识点
- Python基础知识汇总
- python基础教程-第1章节 基础知识
- Python基础知识(一)
- Python基础知识(一)
- Python自学笔记(一)(Python基础知识)
- Python基础知识(二)--控制流语句
- Python入门:基础知识
- Python基础知识(八)--序列类型_元组
- Python基础知识(三)--基本的异常处理、算术运算符、输入/输出