欧式距离、标准化欧式距离、马氏距离、余弦距离
2017-06-26 17:15
253 查看
目录
欧氏距离标准化欧氏距离
马氏距离
夹角余弦距离
汉明距离
曼哈顿(Manhattan)距离
1.欧式距离
欧式距离源自N维欧氏空间中两点x1,x2x1,x2间的距离公式:d=∑i=1N(x1i−x2i)2‾‾‾‾‾‾‾‾‾‾√d=∑i=1N(x1i−x2i)2
2.标准化欧式距离
引入标准化欧式距离的原因是一个数据xixi的各个维度之间的尺度不一样。【对于尺度无关的解释】如果向量中第一维元素的数量级是100,第二维的数量级是10,比如v1=(100,10,30),v2 = (500,40),则计算欧式距离
d=100⋅(50−10)2+(40−10)2‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾√d=100⋅(50−10)2+(40−10)2
可见欧式距离会给与第一维度100权重,这会压制第二维度的影响力。对所有维度分别进行处理,使得各个维度分别满足标准正态分布。
还有一种对欧式距离的处理是均值化但没有归一化(Normalized),即
d=∑i=1N(xi−yi)2s2i‾‾‾‾‾‾‾‾‾‾‾‾‾⎷d=∑i=1N(xi−yi)2si2
其中s2isi2是第i维度的方差(此处虽然举例只有X,Y两个点,但整个数据集中会有无数个点,根据数据集得到方差分布)
网络上的Normalized Euclidean distance和Standard Euclidean distance的定义对应这两种处理。
3.马氏距离、标准化欧式距离(Standard Euclidean distance)
标准化欧式距离即是将集合X={xi}X={xi}先进行归一化,映射到正太分布N(0,1)的区间:xipost=(xi−u)/sxipost=(xi−u)/s
其中u为均值,s2s2为方差。
其实,这就是马氏距离要做的事。马氏距离的结果也是将数据投影到N(0,1)区间并求其欧式距离。
马氏距离又称为数据的协方差距离。它是一种有效的计算两个未知样本集的相似度的方法。与标准化欧氏距离不同的是它考虑到各种特性之间的联系。
假设uxux为向量X={x1,x2,...,xN}X={x1,x2,...,xN}的均值,uyuy为Y={y1,y2,...yN}Y={y1,y2,...yN}的均值,ΣΣ 是X与Y的协方差
点X与Y的马氏距离:
(x−ux)TΣ−1(y−uy)‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾√(x−ux)TΣ−1(y−uy)
这个式子可以用矩阵的迹来重写:
(x−ux)TΣ−1(y−uy)‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾√=tr(Σ−1(y−uy)(x−ux)T‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾√(x−ux)TΣ−1(y−uy)=tr(Σ−1(y−uy)(x−ux)T
其中ΣΣ是X与Y的协方差矩阵
可见:
如果ΣΣ是单位矩阵,则马氏距离退化成欧式距离;
如果ΣΣ是对角矩阵,则称为归一化后的欧式距离。
所以马氏距离的特点:
尺度无关
考虑进数据之间的联系
马氏距离可以通过协方差自动生成相应的权重,而使用逆则抵消掉这些权重。
最典型的就是根据距离作判别问题,即假设有n个总体,计算某个样品X归属于哪一类的问题。此时虽然样品X离某个总体的欧氏距离最近,但是未必归属它,比如该总体的方差很小,说明需要非常近才能归为该类。对于这种情况,马氏距离比欧氏距离更适合作判别。
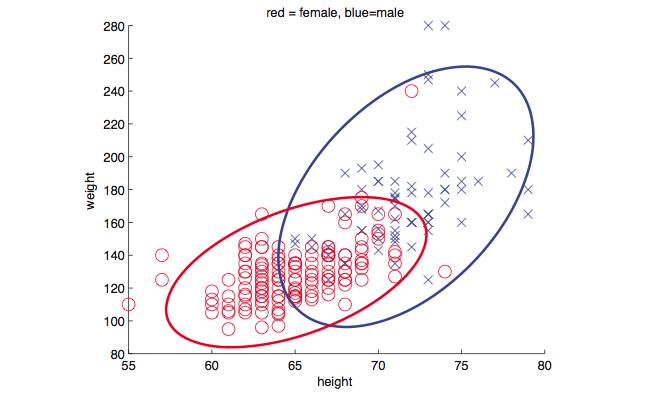
比如下图表示男女两类身高和体重的采样数据,假如男和女先验分布已知,可以用马氏距离判别新的数据。
4.夹脚余弦距离(余弦相似性)
严格来讲余弦距离不是距离,而只是相似性。其他距离直接测量两个高维空间上的点的距离,如果距离为0则两个点“相同”,但余弦的结果为1,只能确定两者高度相似。从几何上看,n维向量空间的一条线段作为底边和原点组成的三角形,其顶角大小是不确定的。对于两条空间向量,即使两点距离一定,他们的夹角余弦值也可以随意变化。
假设两用户只对两件商品评分,向量分别为(3,3)和(5,5),这两位用户的认知其实是一样的,但是欧式距离给出的解显然没有余弦值合理。
相对于标准化后的欧式距离,余弦距离少了将数据投影到一个均值为0的区间里这一步骤。对于点X和点Y,其余弦距离:
d=∑Ni=1xiyi∑x2i‾‾‾‾‾√∑y2i‾‾‾‾‾√d=∑i=1Nxiyi∑xi2∑yi2
余弦距离在给文本分类的词袋模型中使用,例如给一篇文章一共出现过6000个词;因此用一个6000维度的向量X表示这篇文章,每个维度代表字出现数目。另外一篇文章也恰好只出现了这6000字并用向量Y表示该文章,则这两篇文章相似度可以用余弦距离来测量。
优点:余弦距离根据向量方向重合度来判断向量相似度,不受样本
缺点:没有对每个维度进行0均值化处理,如在图片分类中一张图片受光照影响后,前后的余弦距离可能就非常大了。
5.汉明距离
汉明距离是两个等长字符串之间的汉明距离是两个字符串对应位置的不同字符的个数。比如:1011101 与 1001001 为 2
2143896 与 2233796 是 3
可以把它看做将一个字符串变换成另外一个字符串所需要替换的字符个数。
此外,汉明重量是字符串相对于同样长度的零字符串的汉明距离,如:
11101 的汉明重量是 4。
所以两者间的汉明距离等于它们汉明重量的差a-b
[b]6.曼哈顿距离 (Manhattan distance)[/b]
曼哈顿距离的定义如下:
∑p||Ip1−Ip2||∑p||I1p−I2p||
p是I的维度。当I为图像坐标时,曼哈顿距离即是x,y坐标距离之和。
【补充】协方差矩阵的逆Σ−1Σ−1的求法:
先将ΣΣ进行SVD分解(由于协方差矩阵是对称矩阵,因此此处严格说来是特征值分解EVD)。由于协方差矩阵是对称的,
UΛVT=Σ=ΣT=(UΛVT)T=VΛUTUΛVT=Σ=ΣT=(UΛVT)T=VΛUT
即V=Un×n=[u1,u2,...,un]V=Un×n=[u1,u2,...,un]。
因此SVD分解结果:
Σ=UΛUT=∑i=1nλiuiuTiΣ=UΛUT=∑i=1nλiuiuiT
则:
Σ−1=(UT)−1Λ−1U−1=UΛ−1UT=∑i=1nλ−1iuiuTiΣ−1=(UT)−1Λ−1U−1=UΛ−1UT=∑i=1nλi−1uiuiT
因此马氏距离:
d=(xi−ux)Σ−1(yi−uy)Td=(xi−ux)Σ−1(yi−uy)T
=(xi−ux)(∑i=1nλ−1iuiuTi)(yi−uy)T=(xi−ux)(∑i=1nλi−1uiuiT)(yi−uy)T
=∑i=1Nλi(xi−ux)uiuTi(yi−uy)T=∑i=1Nλi(xi−ux)uiuiT(yi−uy)T
=∑i=1Npiqi=∑i=1Npiqi
上式中,由于U是正交矩阵,可以将其视作旋转矩阵,对向量X,Y进行旋转;再对其除以特征值,可以视作尺度处理。这两者的结果就是将数据处理旋转并缩放到一个标准化的空间里去。
Reference:
[1]马氏距离及其几何解释http://www.weixinnu.com/tag/article/1082683923
[2]欧氏距离和余弦相似度的区别是什么?
https://www.zhihu.com/question/19640394

相关文章推荐
- 欧式距离、标准化欧式距离、马氏距离、余弦距离
- 欧式距离、标准化欧式距离、马氏距离、余弦距离
- 算法中的各种距离(欧式距离,马氏距离,闵可夫斯基距离......)
- 马氏距离与欧式距离
- 曼哈顿距离,欧式距离,明式距离,切比雪夫距离以及马氏距离
- 欧式距离与马氏距离
- 机器学习两种距离——欧式距离和马氏距离
- 马氏距离与欧式距离
- 曼哈顿距离,欧式距离,余弦距离
- 马氏距离与欧式距离
- 两个单位向量的 夹角余弦 加上 欧式距离平方的一半 等于 1
- MATLAB学习之路(一) 实现简单的基于欧式距离的新型聚类算法(Clustering by fast search and find of density peaksd)
- 协方差和马氏距离的理解
- Hulu机器学习问题与解答系列 | 第五弹:余弦距离
- 马氏距离通俗理解
- 欧式距离 caffe tensorflow
- PostgreSQL 遗传学应用 - 矩阵相似距离计算 (欧式距离,...XX距离)
- 欧氏距离与马氏距离
- 基于欧氏距离和马氏距离的异常点检测—matlab实现
- LP距离与余弦距离物理意义