TensorFlow脑洞人脸识别(一)
2017-06-24 15:40
218 查看
神经网络应用里最唬人的莫过于人脸识别了,今天楼主就做个简单的人脸识别玩玩。
一般来说我们需要通过某种方法获取可能存在人脸的区域,然后对区域内的图像进行分类,确定是人脸还是背景,这属于分类问题。
然后我们需要对区域坐标进行调整,这一步相当于一个回归问题。给定一个区域,获取调整区域对应的参数,比如平移量缩放量之类的。
实际应用中不一定有这么明显的顺序关系,但思路大体如此。
按照惯例,楼主还是准备玩点野路子。也算是开发一点自己的脑洞吧!
如果我们有一个分类人脸和背景很准确的网络,我们可以类似于使用二分搜索的办法对图像进行搜索。先判断整的图片里是否有人脸,然后对图片进行切分,分别判断子图片里是否有人脸,递归进行。最后切分出人脸的时候,再进行切割会导致子图片里人脸消失,递归结束,识别完成。
这样可以避免回归计算的过程,只需要训练分类背景和人脸的网络即可。这样对数据要求也少了不少,完全可以抓取网络图像进行训练。
收集图片最好的地方非各大搜索引擎的图片搜索莫属。Google被墙不方便。对比baidu和bing的图片搜索,bing的准确度明显比baidu高,目标锁定bing。
之后就简单了,分析了一下bing图片搜索的网络数据,写了点Python代码如下:
from bs4 import BeautifulSoup
import urllib.request
import urllib.parse
import os
import threading
import cv2
import numpy as np
keyword={
"face":["http://cn.bing.com/images/async?q=face+people&qft=+filterui%3aface-face+filterui%3aphoto-photo&lostate=r&mmasync=1&dgState=x*410_y*1029_h*166_c*2_i*71_r*12&IG=2F30F17499C7450DBFAFA355CA1BE527&SFX=3&iid=images.5622",
"http://cn.bing.com/images/async?q=human&qft=+filterui%3aface-portrait&lostate=r&mmasync=1&dgState=x*694_y*1201_h*164_c*3_i*36_r*7&IG=6D13393FAE2C46C1B74D874BBE395415&SFX=2&iid=images.5725",
"http://cn.bing.com/images/async?q=handsome&qft=+filterui%3aface-face&lostate=r&mmasync=1&dgState=x*524_y*1065_h*202_c*3_i*36_r*6&IG=B57823857E2843CE87EDB655B7F7F334&SFX=2&iid=images.5709",
"http://cn.bing.com/images/async?q=beautiful+girl&qft=+filterui%3aface-face&lostate=r&mmasync=1&dgState=x*745_y*1194_h*187_c*4_i*36_r*7&IG=55BB00BABF4F478B9060D6A3A19C1B65&SFX=2&iid=images.5670",
"http://cn.bing.com/images/async?q=%e5%b8%85%e5%93%a5&relo=3&qft=+filterui%3aface-face&lostate=c&mmasync=1&dgState=c*7_y*1257s1212s1226s1472s1213s1410s1427_i*39_w*181&IG=6D566BBDC2C4448ABB98B2DDBFAED030&SFX=2&iid=images.5754",
"http://cn.bing.com/images/async?q=%e7%be%8e%e5%a5%b3&qft=+filterui%3aface-face&lostate=r&mmasync=1&dgState=x*486_y*1004_h*192_c*2_i*36_r*6&IG=40A17665192F4434A72B70C4390C64E8&SFX=2&iid=images.5653",
"http://cn.bing.com/images/async?q=%e4%ba%ba%e7%89%a9%e5%9b%be%e7%89%87&relo=3&qft=+filterui%3aface-face&lostate=c&mmasync=1&dgState=c*7_y*1430s1159s1189s1250s1358s1183s1285_i*39_w*181&IG=2245EBFC2E5D4104BAE25B78BD3F9B99&SFX=2&iid=images.5682"],
"body":["http://cn.bing.com/images/async?q=Group+photo+friends&qft=+filterui%3aface-portrait&lostate=r&mmasync=1&dgState=x*0_y*0_h*0_c*5_i*211_r*37&IG=61B156F4951A445FABD823619621B21A&SFX=7&iid=images.5622",
"http://cn.bing.com/images/async?q=street+young+man+woman+photo&lostate=r&mmasync=1&dgState=x*870_y*1226_h*195_c*3_i*71_r*13&IG=A6DBFAAFB9F246C58CA1C6E48D7B9EC8&SFX=3&iid=images.5678",
"http://cn.bing.com/images/async?q=%e5%90%88%e7%85%a7&lostate=r&mmasync=1&dgState=x*0_y*0_h*0_c*4_i*281_r*47&IG=38AADDB045FA476A874BCE211808938A&SFX=9&iid=images.5725"
],
"background":["http://cn.bing.com/images/async?q=outdoor&lostate=r&mmasync=1&dgState=x*529_y*1137_h*184_c*2_i*211_r*42&IG=36C7889B63534668B101BA10E4200710&SFX=7&iid=images.5713",
"http://cn.bing.com/images/async?q=%e9%a3%8e%e6%99%af&lostate=r&mmasync=1&dgState=x*0_y*0_h*0_c*5_i*71_r*14&IG=844AED80FBB44BEDA47A7D2201D6D642&SFX=3&iid=images.5725"]
}
##############################################################
def checkDir():
if os.path.exists("./data")==False:
os.mkdir("./data")
for subDir in list(keyword.keys()):
if os.path.exists("./data/"+subDir)==False:
os.mkdir("./data/"+subDir)
def writeData(data,tag,name):
image = np.asarray(bytearray(data), dtype="uint8")
image = cv2.imdecode(image, cv2.IMREAD_COLOR)
cv2.imwrite("./data/"+tag+"/"+name+".jpg", cv2.resize(image,(128,128)))
##################################################################
globalSet=set()
class imageUrlGeter:
def __init__(self,url,getIndex,start,end):
self.url=url
self.getIndex=getIndex
self.curIndex=start
self.maxIndex=end
self.urlList=[]
self.urlSet=globalSet
def __iter__(self):
return self
def pushImageUrl(self):
while True:
try:
text=urllib.request.urlopen(self.url+"&count=20&relp=20"+"&first="+str(self.getIndex)).read()
break
except Exception:
9330
print("exception raised when get image url")
html=str(text,encoding = "utf-8")
self.getIndex+=20
tempList=[]
soup=BeautifulSoup(html)
images=soup.find_all(name="img",class_="mimg")
for image in images:
url=image.get("src")
param=urllib.parse.parse_qs(urllib.parse.urlparse(url).query)
if param["id"][0] in self.urlSet:
continue
self.urlSet.add(param["id"][0])
tempList.append(url)
if len(tempList)<=0:
raise StopIteration()
self.urlList+=tempList
def __next__(self):
if self.curIndex>=self.maxIndex:
raise StopIteration()
if len(self.urlList)==0:
self.pushImageUrl()
cur=self.curIndex
self.curIndex+=1
return self.urlList.pop(0),cur
def downloadFun(geter,key):
for url,index in geter:
try:
data = urllib.request.urlopen(url).read()
writeData(data, key, str(index))
except Exception:
print("image " + str(index) + " skiped")
def startDownload(url,key,start,end):
numOfThread=32
threadList=[]
perThread=int((end-start)/numOfThread)
for i in range(numOfThread):
urlGeter=imageUrlGeter(url,i*perThread,start+i*perThread,start+(i+1)*perThread)
thread=threading.Thread(target=downloadFun,args=[urlGeter,key])
thread.setDaemon(True)
threadList.append(thread)
thread.start()
for thread in threadList:
thread.join()
def downLoadImages(dic):
for key in list(dic):
i=0
urlList=keyword[key]
for url in urlList:
startDownload(url,key,i*5000,(i+1)*5000)
i+=1
if __name__=="__main__":
checkDir()
downLoadImages(keyword)
人脸图片:

身体图片:
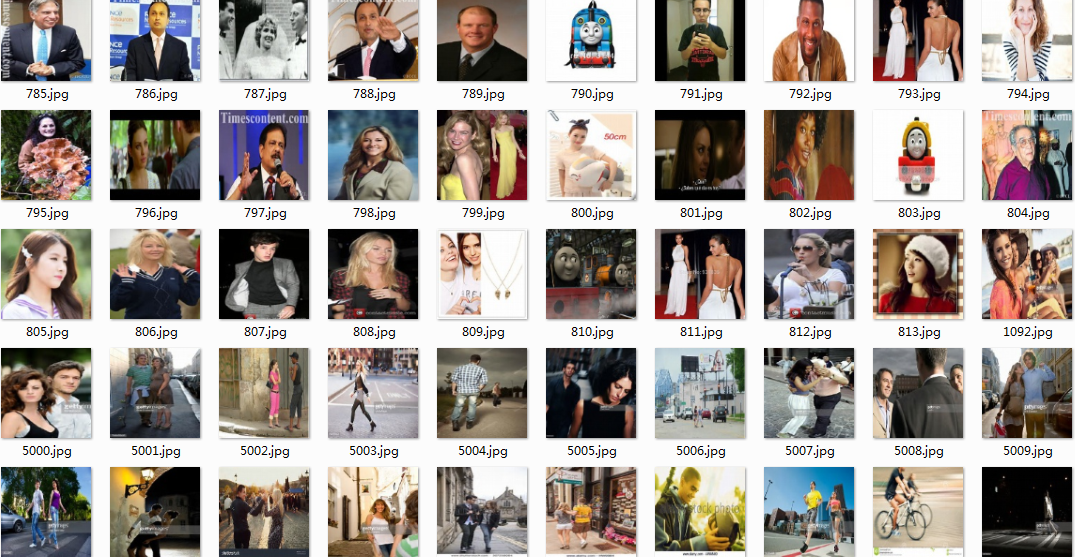
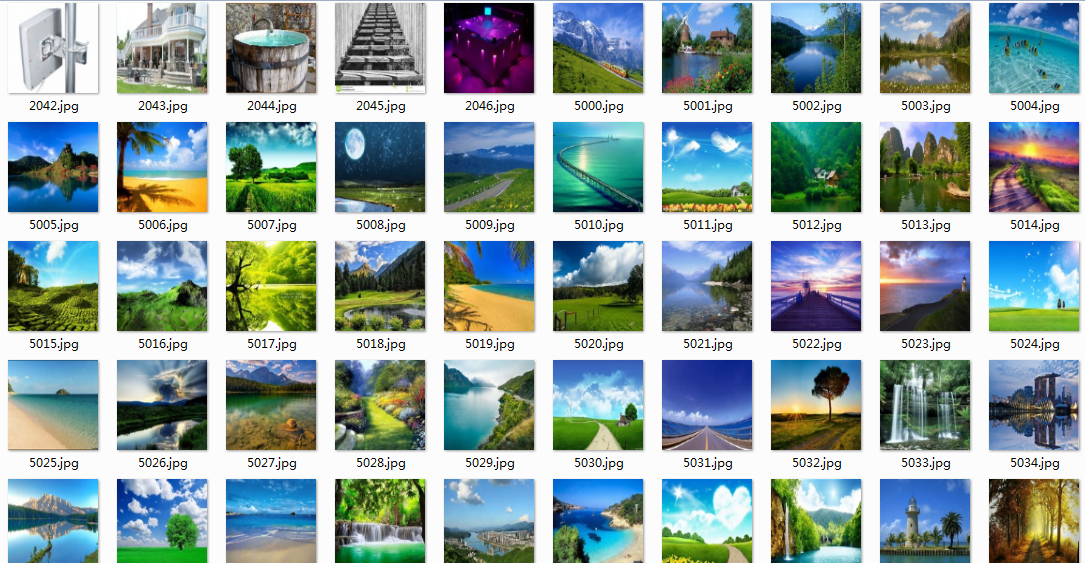
背景图片:
下一篇给大家介绍网络模型的建立和训练
1.引言
人脸识别既是分类问题,也是回归问题。一般来说我们需要通过某种方法获取可能存在人脸的区域,然后对区域内的图像进行分类,确定是人脸还是背景,这属于分类问题。
然后我们需要对区域坐标进行调整,这一步相当于一个回归问题。给定一个区域,获取调整区域对应的参数,比如平移量缩放量之类的。
实际应用中不一定有这么明显的顺序关系,但思路大体如此。
按照惯例,楼主还是准备玩点野路子。也算是开发一点自己的脑洞吧!
如果我们有一个分类人脸和背景很准确的网络,我们可以类似于使用二分搜索的办法对图像进行搜索。先判断整的图片里是否有人脸,然后对图片进行切分,分别判断子图片里是否有人脸,递归进行。最后切分出人脸的时候,再进行切割会导致子图片里人脸消失,递归结束,识别完成。
这样可以避免回归计算的过程,只需要训练分类背景和人脸的网络即可。这样对数据要求也少了不少,完全可以抓取网络图像进行训练。
2.数据收集准备
首先我们需要人脸和背景的图片。其次,由于我们人脸离镜头比较远时也可以识别,需要网络可以分类身体的图片,所以我们还需要身体的图片。收集图片最好的地方非各大搜索引擎的图片搜索莫属。Google被墙不方便。对比baidu和bing的图片搜索,bing的准确度明显比baidu高,目标锁定bing。
之后就简单了,分析了一下bing图片搜索的网络数据,写了点Python代码如下:
from bs4 import BeautifulSoup
import urllib.request
import urllib.parse
import os
import threading
import cv2
import numpy as np
keyword={
"face":["http://cn.bing.com/images/async?q=face+people&qft=+filterui%3aface-face+filterui%3aphoto-photo&lostate=r&mmasync=1&dgState=x*410_y*1029_h*166_c*2_i*71_r*12&IG=2F30F17499C7450DBFAFA355CA1BE527&SFX=3&iid=images.5622",
"http://cn.bing.com/images/async?q=human&qft=+filterui%3aface-portrait&lostate=r&mmasync=1&dgState=x*694_y*1201_h*164_c*3_i*36_r*7&IG=6D13393FAE2C46C1B74D874BBE395415&SFX=2&iid=images.5725",
"http://cn.bing.com/images/async?q=handsome&qft=+filterui%3aface-face&lostate=r&mmasync=1&dgState=x*524_y*1065_h*202_c*3_i*36_r*6&IG=B57823857E2843CE87EDB655B7F7F334&SFX=2&iid=images.5709",
"http://cn.bing.com/images/async?q=beautiful+girl&qft=+filterui%3aface-face&lostate=r&mmasync=1&dgState=x*745_y*1194_h*187_c*4_i*36_r*7&IG=55BB00BABF4F478B9060D6A3A19C1B65&SFX=2&iid=images.5670",
"http://cn.bing.com/images/async?q=%e5%b8%85%e5%93%a5&relo=3&qft=+filterui%3aface-face&lostate=c&mmasync=1&dgState=c*7_y*1257s1212s1226s1472s1213s1410s1427_i*39_w*181&IG=6D566BBDC2C4448ABB98B2DDBFAED030&SFX=2&iid=images.5754",
"http://cn.bing.com/images/async?q=%e7%be%8e%e5%a5%b3&qft=+filterui%3aface-face&lostate=r&mmasync=1&dgState=x*486_y*1004_h*192_c*2_i*36_r*6&IG=40A17665192F4434A72B70C4390C64E8&SFX=2&iid=images.5653",
"http://cn.bing.com/images/async?q=%e4%ba%ba%e7%89%a9%e5%9b%be%e7%89%87&relo=3&qft=+filterui%3aface-face&lostate=c&mmasync=1&dgState=c*7_y*1430s1159s1189s1250s1358s1183s1285_i*39_w*181&IG=2245EBFC2E5D4104BAE25B78BD3F9B99&SFX=2&iid=images.5682"],
"body":["http://cn.bing.com/images/async?q=Group+photo+friends&qft=+filterui%3aface-portrait&lostate=r&mmasync=1&dgState=x*0_y*0_h*0_c*5_i*211_r*37&IG=61B156F4951A445FABD823619621B21A&SFX=7&iid=images.5622",
"http://cn.bing.com/images/async?q=street+young+man+woman+photo&lostate=r&mmasync=1&dgState=x*870_y*1226_h*195_c*3_i*71_r*13&IG=A6DBFAAFB9F246C58CA1C6E48D7B9EC8&SFX=3&iid=images.5678",
"http://cn.bing.com/images/async?q=%e5%90%88%e7%85%a7&lostate=r&mmasync=1&dgState=x*0_y*0_h*0_c*4_i*281_r*47&IG=38AADDB045FA476A874BCE211808938A&SFX=9&iid=images.5725"
],
"background":["http://cn.bing.com/images/async?q=outdoor&lostate=r&mmasync=1&dgState=x*529_y*1137_h*184_c*2_i*211_r*42&IG=36C7889B63534668B101BA10E4200710&SFX=7&iid=images.5713",
"http://cn.bing.com/images/async?q=%e9%a3%8e%e6%99%af&lostate=r&mmasync=1&dgState=x*0_y*0_h*0_c*5_i*71_r*14&IG=844AED80FBB44BEDA47A7D2201D6D642&SFX=3&iid=images.5725"]
}
##############################################################
def checkDir():
if os.path.exists("./data")==False:
os.mkdir("./data")
for subDir in list(keyword.keys()):
if os.path.exists("./data/"+subDir)==False:
os.mkdir("./data/"+subDir)
def writeData(data,tag,name):
image = np.asarray(bytearray(data), dtype="uint8")
image = cv2.imdecode(image, cv2.IMREAD_COLOR)
cv2.imwrite("./data/"+tag+"/"+name+".jpg", cv2.resize(image,(128,128)))
##################################################################
globalSet=set()
class imageUrlGeter:
def __init__(self,url,getIndex,start,end):
self.url=url
self.getIndex=getIndex
self.curIndex=start
self.maxIndex=end
self.urlList=[]
self.urlSet=globalSet
def __iter__(self):
return self
def pushImageUrl(self):
while True:
try:
text=urllib.request.urlopen(self.url+"&count=20&relp=20"+"&first="+str(self.getIndex)).read()
break
except Exception:
9330
print("exception raised when get image url")
html=str(text,encoding = "utf-8")
self.getIndex+=20
tempList=[]
soup=BeautifulSoup(html)
images=soup.find_all(name="img",class_="mimg")
for image in images:
url=image.get("src")
param=urllib.parse.parse_qs(urllib.parse.urlparse(url).query)
if param["id"][0] in self.urlSet:
continue
self.urlSet.add(param["id"][0])
tempList.append(url)
if len(tempList)<=0:
raise StopIteration()
self.urlList+=tempList
def __next__(self):
if self.curIndex>=self.maxIndex:
raise StopIteration()
if len(self.urlList)==0:
self.pushImageUrl()
cur=self.curIndex
self.curIndex+=1
return self.urlList.pop(0),cur
def downloadFun(geter,key):
for url,index in geter:
try:
data = urllib.request.urlopen(url).read()
writeData(data, key, str(index))
except Exception:
print("image " + str(index) + " skiped")
def startDownload(url,key,start,end):
numOfThread=32
threadList=[]
perThread=int((end-start)/numOfThread)
for i in range(numOfThread):
urlGeter=imageUrlGeter(url,i*perThread,start+i*perThread,start+(i+1)*perThread)
thread=threading.Thread(target=downloadFun,args=[urlGeter,key])
thread.setDaemon(True)
threadList.append(thread)
thread.start()
for thread in threadList:
thread.join()
def downLoadImages(dic):
for key in list(dic):
i=0
urlList=keyword[key]
for url in urlList:
startDownload(url,key,i*5000,(i+1)*5000)
i+=1
if __name__=="__main__":
checkDir()
downLoadImages(keyword)
3.收集数据
楼主比较懒,就加了几个链接,所以总共就抓了1万多张图,先试试再说吧!如果需要更多,加几个链接就好了。人脸图片:
身体图片:
背景图片:
4.总结
数据比较寒酸,主要还是楼主懒…下一篇给大家介绍网络模型的建立和训练

相关文章推荐
- TensorFlow脑洞人脸识别(二)
- TensorFlow 实现人脸识别
- Tensorflow实现卷积神经网络,用于人脸关键点识别
- TensorFlow实现人脸识别(1)------Linux下用opencv打开视频
- Tensorflow,opencv,dlib,cnn,人脸识别
- TensorFlow在人脸识别中的应用-人脸检测
- TensorFlow 人脸识别网络与对抗网络搭建
- Tensorflow实现卷积神经网络,用于人脸关键点识别
- tensorflow1.1/autoencoder人脸识别
- tensorflow搭建cnn人脸识别训练+识别代码(python)
- TensorFlow实现人脸识别(3)------将得到的训练图片以及测试图片进行处理
- tensorflow1.1/人脸识别Yale数据集
- TensorFlow的学习之路--人脸识别
- 基于Tensorflow的Facenet 人脸识别实现
- TensorFlow 人脸识别网络与对抗网络搭建
- TensorFlow环境 人脸识别 FaceNet 应用(一)验证测试集
- TensorFlow实践|TensorFlow实现人脸表情识别
- TensorFlow技术解析与实战 10 人脸识别
- TensorFlow实现人脸识别(4)--------对人脸样本进行训练,保存人脸识别模型
- tensorflow1.1/构建卷积神经网络人脸识别