决策树算法(有监督学习算法)
2017-06-24 10:13
176 查看
一、决策树基础
决策树(Decision Tree)算法是根据数据的属性采用树状结构建立决策模型,这个模型可以高效的对未知的数据进行分类。决策树模型常常用来解决分类和回归问题。如今决策树是一种简单但是广泛使用的分类器。常见的算法包括 CART (Classification And Regression Tree)、ID3、C4.5、随机森林 (Random Forest) 等。
以下面一个经典的案例来说明决策树分类的思想,有点像女孩子找对象,一定要找到一个合适的类型(类别)!!现想象一个女孩的母亲要给这个女孩介绍男朋友,于是有了下面的对话:
女儿:多大年纪了?
母亲:26。
女儿:长的帅不帅?
母亲:挺帅的。
女儿:收入高不?
母亲:不算很高,中等情况。
女儿:是公务员不?
母亲:是,在税务局上班呢。
女儿:那好,我去见见。
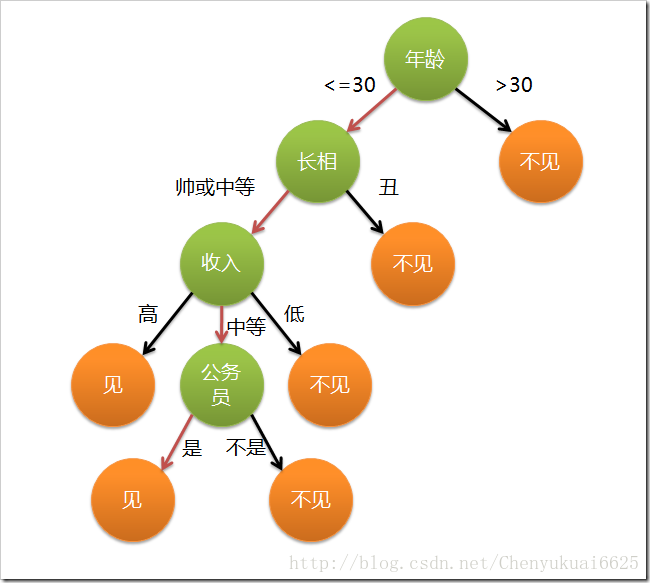
这个女孩最终选择的分类有两种,见或不见,但是判断的属性有好几种,比如年龄、长相、收入、公务员。根据这些对象属性分别进行依次判断,分支的箭头有各个属性满足的条件。
由上面可以看出,决策树是附加概率结果的一个树状的决策图,是直观的运用统计概率分析的图法。机器学习中决策树是一个预测模型,它表示对象属性和对象值之间的一种映射,树中的每一个节点表示对象属性的判断条件,其分支表示符合节点条件的对象。树的叶子节点表示对象所属的预测结果。同时,可知决策树的决策过程非常直观,容易被人理解。目前决策树已经成功运用于医学、制造产业、天文学、分支生物学以及商业等诸多领域。
二、决策树的建立
2.1、决策树构造简介
构建决策树的过程就是选择合适的分裂属性的过程。选择一个合适的分裂属性作为判断节点,可以快速对数据进行分类,减少决策树的深度。决策树的目标就是把数据集按对应的类标签进行分类。最理想的情况是,通过分裂属性的选择能把不同类别的数据集贴上对应类标签。特征属性选择的目标使得分类后的数据集比较纯(即让各个分裂子集尽可能地“纯”)。尽可能“纯”就是尽量让一个分裂子集中待分类项属于同一类别。故决策树构建的基本步骤如下:
(1)开始,所有记录看作一个节点;
(2)遍历每个变量的每一种分割方式,找到最好的分割点;
(3)分割成两个节点N1和N2;
(4)对N1和N2分别继续执行2-3步,直到每个节点足够“纯”为止。
决策树的变量可以有两种:(a) 数字型(Numeric):变量类型是整数或浮点数,如“年收入”。用“>=”,“>”,“<”或“<=”作为分割条件(排序后,利用已有的分割情况,可以优化分割算法的时间复杂度)。(b) 名称型(Nominal):类似编程语言中的枚举类型,变量只能重有限的选项中选取,比如“婚姻情况”,只能是“单身”,“已婚”或“离婚”。使用“=”来分割。
构造决策树的关键性内容是进行属性选择度量,属性选择度量是一种选择分裂准则,是将给定的类标记的训练集合的数据划分D“最好”地分成个体类。属性选择度量算法(即量化纯度的算法)有很多。下面将介绍两种常用的方法。
2.2、属性选择度量算法
属性选择方法总是选择最好的属性最为分裂属性,即让每个分支的记录的类别尽可能纯。它将所有属性列表的属性进行按某个标准排序,从而选出最好的属性。属性选择方法很多,这里介绍三个常用的方法:信息增益(Information gain)、增益比率(gain ratio)、基尼指数(Gini index)。
1、信息增益(ID3算法)
信息熵表示的是不确定度。均匀分布时,不确定度最大,此时熵就最大。当选择某个特征对数据集进行分类时,分类后的数据集信息熵会比分类前的小,其差值表示为信息增益。信息增益可以衡量某个特征对分类结果的影响大小。
假设在样本数据集 D 中,混有 c 种类别的数据。构建决策树时,根据给定的样本数据集选择某个特征值作为树的节点。在数据集中,可以计算出该数据中作用前的信息熵计算公式:
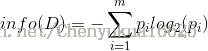
其中 D 表示训练数据集,c 表示数据类别数,Pi 表示类别 i 样本数量占所有样本的比例。
对应数据集 D,选择特征属性 A 作为决策树判断节点时,在特征 属性A 作用后的信息熵的为 Info(D),计算公式如下:
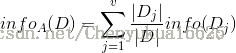
其中 v 表示样本 D 被分为 v 个部分。
信息增益表示数据集 D 在特征 A 的作用后,其信息熵减少的值。公式如下:

对数据集中每个特征属性进行信息增益计算,选择gain()值最大的特征属性作为决策树节点最合适的特征属性选择。下面以一个案例(不真实账号检测)为例来进行说明如何利用信息增益来进行特征属性的选择:
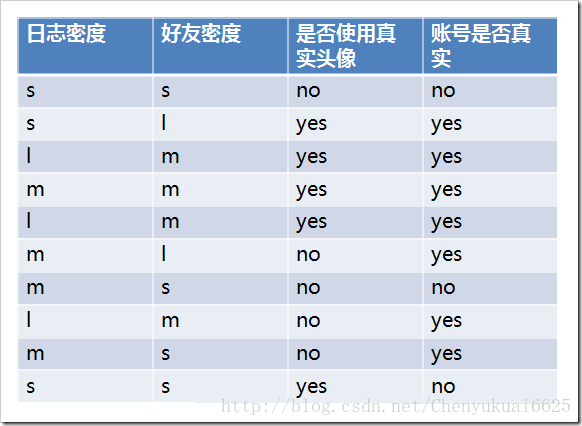
其中s、m和l分别表示小、中和大。 设L、F、H和R表示日志密度、好友密度、是否使用真实头像和账号是否真实,下面计算各属性的信息增益。首先计算数据集作用前的信息熵:
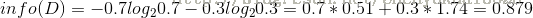
然后计算各个特征属性作为判断节点的信息增益:
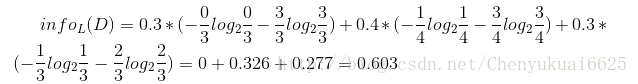
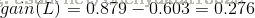
因此日志密度的信息增益是0.276。用同样方法得到H和F的信息增益分别为0.033和0.553。所以F具有最大的信息增益,所以第一次选择F属性作为分裂属性,分裂后的结果如下图所示:
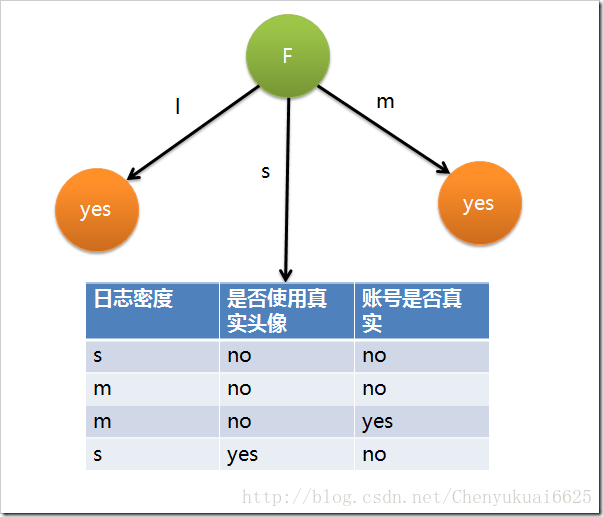
在上图的基础上,再递归使用这个方法计算子节点的分裂属性,最终就可以得到整个决策树。
上面为了简便,将特征属性离散化了,其实日志密度和好友密度都是连续的属性。对于特征属性为连续值,可以如此使用ID3算法:先将D中元素按照特征属性排序,则每两个相邻元素的中间点可以看做潜在分裂点,从第一个潜在分裂点开始,分裂D并计算两个集合的期望信息,具有最小期望信息的点称为这个属性的最佳分裂点,其信息期望作为此属性的信息期望。
2、增益比率(C4.5算法)
信息增益选择方法有一个很大的缺陷,它总是会倾向于选择属性值多的属性,如果我们在上面的数据记录中加一个账号名属性,假设10条记录中的每个账号名不同,那么信息增益就会选择账号名作为最佳属性,因为按账号名分裂后,每个组只包含一条记录,而每个记录只属于一类(要么账号真实要么不真实),因此纯度最高,以账号名作为测试分裂的结点下面有10个分支。但是这样的分类没有意义,它没有任何泛化能力。增益比率对此进行了改进,它引入一个分裂信息:

其中各符号意义与信息增益算法相同,然后,增益率被定义为:

增益比率选择具有最大增益率的属性作为分裂属性,其具体应用与信息增益算法类似。
三、决策树的相关问题
3.1、分类什么时候停止?
决策树的构建过程是一个递归的过程,所以需要确定停止条件,否则过程将不会结束。一种最直观的方式是当每个子节点只有一种类型的记录时停止,但是这样往往会使得树的节点过多,导致过拟合问题(Overfitting)。另一种可行的方法是当前节点中的记录数低于一个最小的阀值,那么就停止分割,将max(P(i))对应的分类作为当前叶节点的分类。
3.2、如果属性分类用完了怎么办?
在决策树构造过程中可能会出现这种情况:所有属性都作为分裂属性用光了,但有的子集还不是纯净集,即集合内的元素不属于同一类别。在这种情况下,由于没有更多信息可以使用了,一般对这些子集进行“多数表决”,即使用此子集中出现次数最多的类别作为此节点类别,然后将此节点作为叶子节点。
3.3、过度拟合出现的原因?
采用上面算法生成的决策树在事件中往往会导致过度拟合。也就是该决策树对训练数据可以得到很低的错误率,但是运用到测试数据上却得到非常高的错误率。过度拟合的原因有以下几点:
(1)噪音数据:训练数据中存在噪音数据,决策树的某些节点有噪音数据作为分割标准,导致决策树无法代表真实数据。
(2)缺少代表性数据:训练数据没有包含所有具有代表性的数据,导致某一类数据无法很好的匹配,这一点可以通过观察混淆矩阵(Confusion Matrix)分析得出。
(3)多重比较:决策树需要在每个变量的每一个值中选取一个作为分割的代表,所以选出一个噪音分割标准的概率是很大的。
3.4、如何解决存在的过度拟合的问题?
1、修剪枝叶
决策树过渡拟合往往是因为太过“茂盛”,也就是节点过多,所以需要裁剪(Prune Tree)枝叶。裁剪枝叶的策略对决策树正确率的影响很大。主要有两种裁剪策略:
(1)前置裁剪 在构建决策树的过程时,提前停止。那么,会将切分节点的条件设置的很苛刻,导致决策树很短小。结果就是决策树无法达到最优。实践证明这中策略无法得到较好的结果。
(2)后置裁剪 决策树构建好后,然后才开始裁剪。采用两种方法:(a)用单一叶节点代替整个子树,叶节点的分类采用子树中最主要的分类;(b)将一个字数完全替代另外一颗子树。后置裁剪有个问题就是计算效率,有些节点计算后就被裁剪了,导致有点浪费。
2、K层交叉验证
首先计算出整体的决策树T,叶节点个数记作N,设i属于[1,N]。对每个i,使用K-Fold Validataion方法计算决策树,并裁剪到i个节点,计算错误率,最后求出平均错误率。这样可以用具有最小错误率对应的i作为最终决策树的大小,对原始决策树进行裁剪,得到最优决策树。
3、随机森林
Random Forest是用训练数据随机的计算出许多决策树,形成了一个森林。然后用这个森林对未知数据进行预测,选取投票最多的分类。实践证明,此算法的错误率得到了经一步的降低。这种方法背后的原理可以用“三个臭皮匠定一个诸葛亮”这句谚语来概括。一颗树预测正确的概率可能不高,但是集体预测正确的概率却很高。
4、 及早停止增长树法,在ID3算法完美分类训练数据之前停止增长树。
四、决策树的优缺点
4.1、决策树的优点
相对于其他数据挖掘算法,决策树在以下几个方面拥有优势:
(1) 决策树易于理解和实现. 人们在通过解释后都有能力去理解决策树所表达的意义。
(2) 对于决策树,数据的准备往往是简单或者是不必要的 。其他的技术往往要求先把数据一般化,比如去掉多余的或者空白的属性。
(3) 能够同时处理数据型和常规型属性。其他的技术往往要求数据属性的单一。
(4) 在相对短的时间内能够对大型数据源做出可行且效果良好的结果。
(5) 对缺失值不敏感。
(6) 可以处理不相关特征数据。
(7) 效率高,决策树只需要一次构建,反复使用,每一次预测的最大计算次数不超过决策树的深度。
4.2、决策树的缺点
(1)对连续性的字段比较难预测。
(2)对有时间顺序的数据,需要很多预处理的工作。
(3)当类别太多时,错误可能就会增加的比较快。
(4)一般的算法分类的时候,只是根据一个字段来分类。
(5)在处理特征关联性比较强的数据时表现得不是太好。
决策树(Decision Tree)算法是根据数据的属性采用树状结构建立决策模型,这个模型可以高效的对未知的数据进行分类。决策树模型常常用来解决分类和回归问题。如今决策树是一种简单但是广泛使用的分类器。常见的算法包括 CART (Classification And Regression Tree)、ID3、C4.5、随机森林 (Random Forest) 等。
以下面一个经典的案例来说明决策树分类的思想,有点像女孩子找对象,一定要找到一个合适的类型(类别)!!现想象一个女孩的母亲要给这个女孩介绍男朋友,于是有了下面的对话:
女儿:多大年纪了?
母亲:26。
女儿:长的帅不帅?
母亲:挺帅的。
女儿:收入高不?
母亲:不算很高,中等情况。
女儿:是公务员不?
母亲:是,在税务局上班呢。
女儿:那好,我去见见。
这个女孩最终选择的分类有两种,见或不见,但是判断的属性有好几种,比如年龄、长相、收入、公务员。根据这些对象属性分别进行依次判断,分支的箭头有各个属性满足的条件。
由上面可以看出,决策树是附加概率结果的一个树状的决策图,是直观的运用统计概率分析的图法。机器学习中决策树是一个预测模型,它表示对象属性和对象值之间的一种映射,树中的每一个节点表示对象属性的判断条件,其分支表示符合节点条件的对象。树的叶子节点表示对象所属的预测结果。同时,可知决策树的决策过程非常直观,容易被人理解。目前决策树已经成功运用于医学、制造产业、天文学、分支生物学以及商业等诸多领域。
二、决策树的建立
2.1、决策树构造简介
构建决策树的过程就是选择合适的分裂属性的过程。选择一个合适的分裂属性作为判断节点,可以快速对数据进行分类,减少决策树的深度。决策树的目标就是把数据集按对应的类标签进行分类。最理想的情况是,通过分裂属性的选择能把不同类别的数据集贴上对应类标签。特征属性选择的目标使得分类后的数据集比较纯(即让各个分裂子集尽可能地“纯”)。尽可能“纯”就是尽量让一个分裂子集中待分类项属于同一类别。故决策树构建的基本步骤如下:
(1)开始,所有记录看作一个节点;
(2)遍历每个变量的每一种分割方式,找到最好的分割点;
(3)分割成两个节点N1和N2;
(4)对N1和N2分别继续执行2-3步,直到每个节点足够“纯”为止。
决策树的变量可以有两种:(a) 数字型(Numeric):变量类型是整数或浮点数,如“年收入”。用“>=”,“>”,“<”或“<=”作为分割条件(排序后,利用已有的分割情况,可以优化分割算法的时间复杂度)。(b) 名称型(Nominal):类似编程语言中的枚举类型,变量只能重有限的选项中选取,比如“婚姻情况”,只能是“单身”,“已婚”或“离婚”。使用“=”来分割。
构造决策树的关键性内容是进行属性选择度量,属性选择度量是一种选择分裂准则,是将给定的类标记的训练集合的数据划分D“最好”地分成个体类。属性选择度量算法(即量化纯度的算法)有很多。下面将介绍两种常用的方法。
2.2、属性选择度量算法
属性选择方法总是选择最好的属性最为分裂属性,即让每个分支的记录的类别尽可能纯。它将所有属性列表的属性进行按某个标准排序,从而选出最好的属性。属性选择方法很多,这里介绍三个常用的方法:信息增益(Information gain)、增益比率(gain ratio)、基尼指数(Gini index)。
1、信息增益(ID3算法)
信息熵表示的是不确定度。均匀分布时,不确定度最大,此时熵就最大。当选择某个特征对数据集进行分类时,分类后的数据集信息熵会比分类前的小,其差值表示为信息增益。信息增益可以衡量某个特征对分类结果的影响大小。
假设在样本数据集 D 中,混有 c 种类别的数据。构建决策树时,根据给定的样本数据集选择某个特征值作为树的节点。在数据集中,可以计算出该数据中作用前的信息熵计算公式:
其中 D 表示训练数据集,c 表示数据类别数,Pi 表示类别 i 样本数量占所有样本的比例。
对应数据集 D,选择特征属性 A 作为决策树判断节点时,在特征 属性A 作用后的信息熵的为 Info(D),计算公式如下:
其中 v 表示样本 D 被分为 v 个部分。
信息增益表示数据集 D 在特征 A 的作用后,其信息熵减少的值。公式如下:
对数据集中每个特征属性进行信息增益计算,选择gain()值最大的特征属性作为决策树节点最合适的特征属性选择。下面以一个案例(不真实账号检测)为例来进行说明如何利用信息增益来进行特征属性的选择:
其中s、m和l分别表示小、中和大。 设L、F、H和R表示日志密度、好友密度、是否使用真实头像和账号是否真实,下面计算各属性的信息增益。首先计算数据集作用前的信息熵:
然后计算各个特征属性作为判断节点的信息增益:
因此日志密度的信息增益是0.276。用同样方法得到H和F的信息增益分别为0.033和0.553。所以F具有最大的信息增益,所以第一次选择F属性作为分裂属性,分裂后的结果如下图所示:
在上图的基础上,再递归使用这个方法计算子节点的分裂属性,最终就可以得到整个决策树。
上面为了简便,将特征属性离散化了,其实日志密度和好友密度都是连续的属性。对于特征属性为连续值,可以如此使用ID3算法:先将D中元素按照特征属性排序,则每两个相邻元素的中间点可以看做潜在分裂点,从第一个潜在分裂点开始,分裂D并计算两个集合的期望信息,具有最小期望信息的点称为这个属性的最佳分裂点,其信息期望作为此属性的信息期望。
2、增益比率(C4.5算法)
信息增益选择方法有一个很大的缺陷,它总是会倾向于选择属性值多的属性,如果我们在上面的数据记录中加一个账号名属性,假设10条记录中的每个账号名不同,那么信息增益就会选择账号名作为最佳属性,因为按账号名分裂后,每个组只包含一条记录,而每个记录只属于一类(要么账号真实要么不真实),因此纯度最高,以账号名作为测试分裂的结点下面有10个分支。但是这样的分类没有意义,它没有任何泛化能力。增益比率对此进行了改进,它引入一个分裂信息:
其中各符号意义与信息增益算法相同,然后,增益率被定义为:
增益比率选择具有最大增益率的属性作为分裂属性,其具体应用与信息增益算法类似。
三、决策树的相关问题
3.1、分类什么时候停止?
决策树的构建过程是一个递归的过程,所以需要确定停止条件,否则过程将不会结束。一种最直观的方式是当每个子节点只有一种类型的记录时停止,但是这样往往会使得树的节点过多,导致过拟合问题(Overfitting)。另一种可行的方法是当前节点中的记录数低于一个最小的阀值,那么就停止分割,将max(P(i))对应的分类作为当前叶节点的分类。
3.2、如果属性分类用完了怎么办?
在决策树构造过程中可能会出现这种情况:所有属性都作为分裂属性用光了,但有的子集还不是纯净集,即集合内的元素不属于同一类别。在这种情况下,由于没有更多信息可以使用了,一般对这些子集进行“多数表决”,即使用此子集中出现次数最多的类别作为此节点类别,然后将此节点作为叶子节点。
3.3、过度拟合出现的原因?
采用上面算法生成的决策树在事件中往往会导致过度拟合。也就是该决策树对训练数据可以得到很低的错误率,但是运用到测试数据上却得到非常高的错误率。过度拟合的原因有以下几点:
(1)噪音数据:训练数据中存在噪音数据,决策树的某些节点有噪音数据作为分割标准,导致决策树无法代表真实数据。
(2)缺少代表性数据:训练数据没有包含所有具有代表性的数据,导致某一类数据无法很好的匹配,这一点可以通过观察混淆矩阵(Confusion Matrix)分析得出。
(3)多重比较:决策树需要在每个变量的每一个值中选取一个作为分割的代表,所以选出一个噪音分割标准的概率是很大的。
3.4、如何解决存在的过度拟合的问题?
1、修剪枝叶
决策树过渡拟合往往是因为太过“茂盛”,也就是节点过多,所以需要裁剪(Prune Tree)枝叶。裁剪枝叶的策略对决策树正确率的影响很大。主要有两种裁剪策略:
(1)前置裁剪 在构建决策树的过程时,提前停止。那么,会将切分节点的条件设置的很苛刻,导致决策树很短小。结果就是决策树无法达到最优。实践证明这中策略无法得到较好的结果。
(2)后置裁剪 决策树构建好后,然后才开始裁剪。采用两种方法:(a)用单一叶节点代替整个子树,叶节点的分类采用子树中最主要的分类;(b)将一个字数完全替代另外一颗子树。后置裁剪有个问题就是计算效率,有些节点计算后就被裁剪了,导致有点浪费。
2、K层交叉验证
首先计算出整体的决策树T,叶节点个数记作N,设i属于[1,N]。对每个i,使用K-Fold Validataion方法计算决策树,并裁剪到i个节点,计算错误率,最后求出平均错误率。这样可以用具有最小错误率对应的i作为最终决策树的大小,对原始决策树进行裁剪,得到最优决策树。
3、随机森林
Random Forest是用训练数据随机的计算出许多决策树,形成了一个森林。然后用这个森林对未知数据进行预测,选取投票最多的分类。实践证明,此算法的错误率得到了经一步的降低。这种方法背后的原理可以用“三个臭皮匠定一个诸葛亮”这句谚语来概括。一颗树预测正确的概率可能不高,但是集体预测正确的概率却很高。
4、 及早停止增长树法,在ID3算法完美分类训练数据之前停止增长树。
四、决策树的优缺点
4.1、决策树的优点
相对于其他数据挖掘算法,决策树在以下几个方面拥有优势:
(1) 决策树易于理解和实现. 人们在通过解释后都有能力去理解决策树所表达的意义。
(2) 对于决策树,数据的准备往往是简单或者是不必要的 。其他的技术往往要求先把数据一般化,比如去掉多余的或者空白的属性。
(3) 能够同时处理数据型和常规型属性。其他的技术往往要求数据属性的单一。
(4) 在相对短的时间内能够对大型数据源做出可行且效果良好的结果。
(5) 对缺失值不敏感。
(6) 可以处理不相关特征数据。
(7) 效率高,决策树只需要一次构建,反复使用,每一次预测的最大计算次数不超过决策树的深度。
4.2、决策树的缺点
(1)对连续性的字段比较难预测。
(2)对有时间顺序的数据,需要很多预处理的工作。
(3)当类别太多时,错误可能就会增加的比较快。
(4)一般的算法分类的时候,只是根据一个字段来分类。
(5)在处理特征关联性比较强的数据时表现得不是太好。

相关文章推荐
- 决策树算法(有监督学习算法)
- ML之监督学习算法之分类算法一 ——— 决策树算法
- 单层网络模型下对无监督特征学习算法的分析
- 监督学习_最近邻算法(KNN, k-近邻算法)
- 【机器学习】从分类问题区别机器学习类型 与 初步介绍无监督学习算法 PAC
- 【ML算法】监督学习——KNN算法
- 无监督学习算法K-means算法总结与c++编程实现
- scikit-learn 中文文档-多类和多标签算法-监督学习|ApacheCN
- 论文共读 | “阳奉阴违”的半监督学习算法 - Virtual Adversarial Training
- 报名 | “阳奉阴违”的半监督学习算法 - Virtual Adversarial Training
- 监督学习最常见的四种算法
- 数据挖掘学习笔记——十大算法之决策树算法、逻辑回归概述
- 机器学习笔记 监督学习算法小结(一)
- 【优达学城测评】监督学习的三种算法
- 无监督学习之K-均值算法分析与MATLAB代码实现
- 对分类算法-决策树算法的学习(一)
- lpa 半监督学习 之--标签传播算法
- 监督学习-决策树算法模板
- 【Scikit-Learn 中文文档】十四:多类和多标签算法 - 监督学习 - 用户指南 | ApacheCN
- 【Scikit-Learn 中文文档】多类和多标签算法 - 监督学习 - 用户指南 | ApacheCN