基于Java的网络爬虫实现抓取网络小说(一)
2017-06-23 15:07
489 查看
基于Java的网络爬虫实现抓取网络小说(一)
今天开始写点东西,一方面加深印象一方面再学习。网络爬虫(Web crawler),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本,它们被广泛用于互联网搜索引擎或其他类似网站,可以自动采集所有其能够访问到的页面内容,以获取或更新这些网站的内容和检索方式。从功能上来讲,爬虫一般分为数据采集,处理,储存三个部分。传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件。聚焦爬虫的工作流程较为复杂,需要根据一定的网页分析算法过滤与主题无关的链接,保留有用的链接并将其放入等待抓取的URL队列。然后,它将根据一定的搜索策略从队列中选择下一步要抓取的网页URL,并重复上述过程,直到达到系统的某一条件时停止。另外,所有被爬虫抓取的网页将会被系统存贮,进行一定的分析、过滤,并建立索引,以便之后的查询和检索;对于聚焦爬虫来说,这一过程所得到的分析结果还可能对以后的抓取过程给出反馈和指导。
接下来是正题。在这里我们先以笔下文学:http://www.bxwx8.org;为准抓取一本其中的小说,例如《完美世界》链接是:http://www.xs.la/0_5/;来实现一个简单的抓取。
首先建立一个名为Novel的maven项目
项目所需要的jar包pom.xml
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://ma a65f ven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>Novel</groupId> <artifactId>novel.spider</artifactId> <version>0.0.1-SNAPSHOT</version> <dependencies> <dependency> <groupId>org.jsoup</groupId> <artifactId>jsoup</artifactId> <version>1.9.2</version> </dependency> <dependency> <groupId>org.apache.httpcomponents</groupId> <artifactId>httpclient</artifactId> <version>4.5.2</version> </dependency> <dependency> <groupId>dom4j</groupId> <artifactId>dom4j</artifactId> <version>1.6.1</version> </dependency> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.12</version> </dependency> </dependencies> </project>
我们要获取的是章节目录,需要相关的实体类Chapter.java
package novel.spider.entity;
import java.io.Serializable;
/**
* 小说章节实体类
* @author lilonghua
* @date: 2017年6月22日
*/
public class Chapter implements Serializable {
private static final long serialVersionUID = 1L;
private String title;//小说章节
private String url;//章节链接
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getUrl() {
return url;
}
public void setUrl(String url) {
this.url = url;
}
@Override
public String toString() {
return "Chapter [title=" + title + ", url=" + url + "]";
}
}接下来我们要写一个接口,一个用来获取章节url的方法IChapterInter.java
ackage novel.spider.interfaces;
import java.util.List;
import novel.spider.entity.Chapter;
/**
* 小说url接口
* @author lilonghua
* @date: 2017年6月22日
*/
public interface IChapterInter {
/**
* 获取一个完整的url链接,显示所有章节列表
* @param @param url
* @param @return
* @return
* @throws
*/
public List<Chapter> getChapter(String url);
}之后我们需要在写一个方法来获取传过来的url,并且实现它的抓取IChapterInterImpl.java
package novel.spider.impl;
import java.util.ArrayList;
import java.util.List;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClientBuilder;
import org.apache.http.util.EntityUtils;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import novel.spider.entity.Chapter;
import novel.spider.interfaces.IChapterInter;
/**
* 小说url接口实现类
*
* @author lilonghua
* @date: 2017年6月22日
*/
public class IChapterInterImpl implements IChapterInter {
protected String crawl(String url) throws Exception {
//采用HttpClient技术
try (CloseableHttpClient httpClient = HttpClientBuilder.create().build();
CloseableHttpResponse httpResponse = httpClient.execute(new HttpGet(url))) {
String result = EntityUtils.toString(httpResponse.getEntity());
return result;
} catch (Exception e) {
throw new RuntimeException(e);
}
}
@Override
public List<Chapter> getChapter(String url) {
try {
String result = crawl(url);
Document doc = Jsoup.parse(result);
Elements as = doc.select("#list dd a");
List<Chapter> chapters = new ArrayList<>();
for (Element a : as) {
Chapter chapter = new Chapter();
chapter.setTitle(a.text());
chapter.setUrl("http://www.bxwx8.org" + a.attr("href"));
chapters.add(chapter);
}
return chapters;
} catch (Exception e) {
throw new RuntimeException(e);
}
}
}最后是测试,我们需要在test下创建测试类TestOne.java
package novel.spider.test;
import java.util.List;
import org.junit.Test;
import novel.spider.entity.Chapter;
import novel.spider.impl.IChapterInterImpl;
/**
* 测试链接
* @author lilonghua
* @date: 2017年6月22日
*/
public class TestOne {
@Test
public void test1(){
IChapterInterImpl ChapterInterImpl = new IChapterInterImpl();
List<Chapter> chapterList = ChapterInterImpl.getChapter("http://www.biquge.tw/0_5/");
for (Chapter chapter : chapterList) {
System.out.println(chapter);
}
}
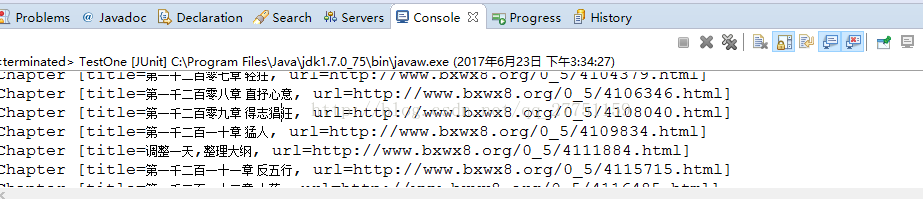
}测试结果,完美实现
最后来个完整的项目结构图
今天先到这,功能还得完善。第一次写,有不足之处欢迎大家指出。

相关文章推荐
- 转载:基于java的网络爬虫框架(实现京东数据的爬取,并将插入数据库)
- 基于java的网络爬虫框架(实现京东数据的爬取,并将插入数据库)
- 基于java的网络爬虫框架(实现京东数据的爬取,并将插入数据库)
- 基于Java HttpClient和Htmlparser实现网络爬虫代码
- 基于Java的简单网络爬虫的实现--下载Silverlight视频
- 基于java的网络爬虫框架(实现京东数据的爬取,并将插入数据库)
- 【JAVA】基于HttpClient4.0的网络爬虫基本框架(Java实现)
- 基于HttpClient4.0的网络爬虫基本框架(Java实现)
- Java--实现网络爬虫抓取RSS新闻(1)网络爬虫详解
- 基于HttpClient4.0的网络爬虫基本框架(Java实现)
- 基于HttpClient4.0的网络爬虫基本框架(Java实现)
- java实现网络爬虫--抓取网站数据
- 【正完成】Java基于Jsoup的网络爬虫工具实现
- [置顶] 基于java的网络爬虫框架(实现京东数据的爬取,并将插入数据库)
- 搜索引擎----Java实现一个简单的网络爬虫
- java搜索---网络爬虫实现
- java网络爬虫的实现
- java搜索---网络爬虫实现
- 用Java实现基于SOAP的XML文档网络传输及远程过程调用(RPC).doc
- 网络爬虫源码分析(java实现)