Java--实现网络爬虫抓取RSS新闻(1)网络爬虫详解
2015-05-17 21:26
330 查看
网络爬虫定义
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动的抓取万维网信息的程序或者脚本。可以更形象的理解:网络相当于一个巨大的蜘蛛网,每个蜘蛛丝的交叉点就是一个资源(URI),爬虫这张巨大的网上爬取需要的资源后,通过一定的机制和容器进行存储。
网络爬虫原理
网络爬虫的基本原理可以用一张经典的图概括: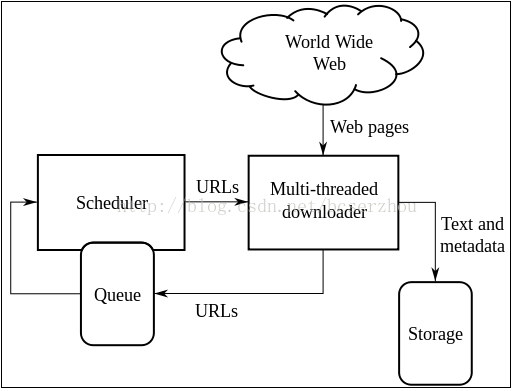
多线程下载器功能:从互联网爬取网页信息。其中,通过URL下载队列调度器,通过某种时间或调度机制进行下载,将下载的目标资源通多存储器(DB)进行保存。
网络爬虫爬取策略
抓取策略,是网络爬虫系统中最重要的一环。抓取策略就是爬虫系统按照某种方法/方式进行规则抓取目标资源。目前比较常见的抓取策略有:深度优先、广度优先、最佳优先。还有一些抓取策略:反向链接数策略、Partial PageRank策略、OPIC策略策略、大站优先策略 等等。深度优先
深度优先搜索策略从起始网页开始,选择一个URL进入,分析这个网页中的URL,选择一个再进入。如此一个链接一个链接地抓取下去,直到处理完一条路线之后再处理下一条路线。深度优先策略设计较为简单。然而门户网站提供的链接往往最具价值,PageRank也很高,但每深入一层,网页价值和PageRank都会相应地有所下降。这暗示了重要网页通常距离种子较近,而过度深入抓取到的网页却价值很低。同时,这种策略抓取深度直接影响着抓取命中率以及抓取效率,对抓取深度是该种策略的关键。相对于其他两种策略而言。此种策略很少被使用。广度优先
广度优先搜索策略是指在抓取过程中,在完成当前层次的搜索后,才进行下一层次的搜索。该算法的设计和实现相对简单。在目前为覆盖尽可能多的网页,一般使用广度优先搜索方法。也有很多研究将广度优先搜索策略应用于聚焦爬虫中。其基本思想是认为与初始URL在一定链接距离内的网页具有主题相关性的概率很大。另外一种方法是将广度优先搜索与网页过滤技术结合使用,先用广度优先策略抓取网页,再将其中无关的网页过滤掉。这些方法的缺点在于,随着抓取网页的增多,大量的无关网页将被下载并过滤,算法的效率将变低。最佳优先
最佳优先搜索策略按照一定的网页分析算法,预测候选URL与目标网页的相似度,或与主题的相关性,并选取评价最好的一个或几个URL进行抓取。它只访问经过网页分析算法预测为“有用”的网页。存在的一个问题是,在爬虫抓取路径上的很多相关网页可能被忽略,因为最佳优先策略是一种局部最优搜索算法。因此需要将最佳优先结合具体的应用进行改进,以跳出局部最优点。将在第4节中结合网页分析算法作具体的讨论。研究表明,这样的闭环调整可以将无关网页数量降低30%~90%。反向链接数策略
反向链接数是指一个网页被其他网页链接指向的数量。反向链接数表示的是一个网页的内容受到其他人的推荐的程度。因此,很多时候搜索引擎的抓取系统会使用这个指标来评价网页的重要程度,从而决定不同网页的抓取先后顺序。在真实的网络环境中,由于广告链接、作弊链接的存在,反向链接数不能完全等他我那个也的重要程度。因此,搜索引擎往往考虑一些可靠的反向链接数。Partial PageRank策略
Partial PageRank算法借鉴了PageRank算法的思想:对于已经下载的网页,连同待抓取URL队列中的URL,形成网页集合,计算每个页面的PageRank值,计算完之后,将待抓取URL队列中的URL按照PageRank值的大小排列,并按照该顺序抓取页面。如果每次抓取一个页面,就重新计算PageRank值,一种折中方案是:每抓取K个页面后,重新计算一次PageRank值。但是这种情况还会有一个问题:对于已经下载下来的页面中分析出的链接,也就是我们之前提到的未知网页那一部分,暂时是没有PageRank值的。为了解决这个问题,会给这些页面一个临时的PageRank值:将这个网页所有入链传递进来的Pa4000
geRank值进行汇总,这样就形成了该未知页面的PageRank值,从而参与排序。
OPIC策略策略
该算法实际上也是对页面进行一个重要性打分。在算法开始前,给所有页面一个相同的初始现金(cash)。当下载了某个页面P之后,将P的现金分摊给所有从P中分析出的链接,并且将P的现金清空。对于待抓取URL队列中的所有页面按照现金数进行排序。大站优先策略
对于待抓取URL队列中的所有网页,根据所属的网站进行分类。对于待下载页面数多的网站,优先下载。这个策略也因此叫做大站优先策略。小结:在实际操作过程中,往往不是单独选择某种策略,而是结合多种策略的优势,去其糟粕,针对业务实现相应的功能。
网络爬虫还有重要的一环就是进行网页分析,具体的方法有:拓扑分析算法、网页分析算法等。此处关注的重点是如何实现爬取这个动作,而不需要关心在爬取大范围的网页中取得需要的目标网页,故此处不再做详细分析。
参考:
百度百科
博客园博客
...
下一篇将进行对腾讯新闻RSS网页进行爬取的原理。请关注。

相关文章推荐
- java实现网络爬虫--抓取网站数据
- 基于Java的网络爬虫实现抓取网络小说(一)
- 【JAVA】基于HttpClient4.0的网络爬虫基本框架(Java实现)
- java 网络爬虫之多线程抓取文件
- Java实现网络爬虫入门Demo
- 【 网络爬虫】java 使用Socket, HttpUrlConnection方式抓取数据
- java实现简单的网络爬虫(爬取电影天堂电影信息)
- Java爬虫,信息抓取的实现
- Java网络爬虫(八)--使用多线程进行百度图片的抓取
- [Java]中的HttpClient对象实现简单的爬虫,抓取妹子图片
- dySE:一个 Java 搜索引擎的实现,第 1 部分 网络爬虫
- Java爬虫,信息抓取的实现
- Java爬虫,信息抓取的实现
- 实现简易Java网络爬虫
- 关于使用Java实现的简单网络爬虫Demo
- Java爬虫,信息抓取的实现
- 简单的java爬虫抓取网页实现代码(未测试)
- 网络爬虫讲解(附java实现的实例)
- java爬虫,信息抓取的实现手法
- [置顶] 基于java的网络爬虫框架(实现京东数据的爬取,并将插入数据库)