【笔记】SPP-Net : Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
2017-06-22 10:58
513 查看
基于空间金字塔池化的卷积神经网络物体检测
论文:http://xueshu.baidu.com/s?wd=paperuri%3A%28c51f05992150d24c15f0dabf0913382e%29&filter=sc_long_sign&tn=SE_xueshusource_2kduw22v&sc_vurl=http%3A%2F%2Farxiv.org%2Fpdf%2F1406.4729v4&ie=utf-8&sc_us=588800853727591174
一、相关理论
本篇博文主要讲解大神何凯明2014年的paper:《Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition》,这篇paper主要的创新点在于提出了空间金字塔池化。 这个算法比R-C
4000
NN算法的速度快了n多倍。
在现有的CNN中,对于结构已经确定的网络,需要输入一张固定大小的图片,比如224*224等。这样对于我们希望检测各种大小的图片的时候,需要经过裁剪,或者缩放等一系列操作,这样往往会降低识别检测的精度,于是paper提出了“空间金字塔池化”方法,这个算法的牛逼之处,可以输入任意大小的图片,不需要经过裁剪缩放等操作,不仅如此,这个算法用了以后,精度也会有提高。
空间金字塔池化,又称之为“SPP-Net”,这个就像什么:OverFeat、GoogleNet、R-CNN、AlexNet……为了方便,学完这篇paper之后,你就需要记住SPP-Net是什么东西了。空间金子塔以前在特征学习、特征表达的相关文献中,看到过几次这个算法。
之前的CNN要求输入固定大小的图片,CNN大体包含3部分,卷积、池化、全连接。
卷积:对图片输入大小没有要求;
池化:对图片大小没有要求;
全连接层:全连接层我们的连接权值矩阵的大小W,经过训练后,就是固定的大小了,比如我们从卷积到全连层,输入和输出的大小,分别是50、30个神经元,那么我们的权值矩阵(50,30)大小的矩阵了。空间金字塔池化要解决的就是从卷积层到全连接层之间的一个过度。一般空间金子塔池化层,都是放在卷积层到全连接层之间的一个网络层。
二、算法概述
空间金字塔特征提取(这边先不考虑“池化”):空间金字塔是很久以前的一种特征提取方法,跟Sift、Hog等特征息息相关。假设一个很简单两层网络:
输入层:一张任意大小的图片,假设其大小为(w,h)。
输出层:21个神经元。
也就是我们输入一张任意大小的特征图的时候,我们希望提取出21个特征。空间金字塔特征提取的过程如下:
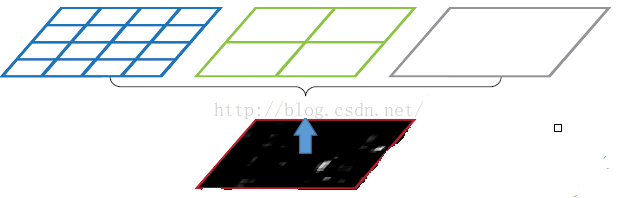
图片尺度划分
如上图所示,当我们输入一张图片的时候,我们利用不同大小的刻度,对一张图片进行了划分。上面示意图中,利用了三种不同大小的刻度,对一张输入的图片进行了划分,最后总共可以得到16+4+1=21个块,我们即将从这21个块中,每个块提取出一个特征,这样刚好就是我们要提取的21维特征向量。
第一张图片,我们把一张完整的图片,分成了16个块,也就是每个块的大小就是(w/4,h/4);
第二张图片,划分了4个块,每个块的大小就是(w/2,h/2);
第三张图片,把一整张图片作为了一个块,也就是块的大小为(w,h)
空间金字塔最大池化的过程,其实就是从这21个图片块中,分别计算每个块的最大值,从而得到一个输出神经元。最后把一张任意大小的图片转换成了一个固定大小的21维特征(当然你可以设计其它维数的输出,增加金字塔的层数,或者改变划分网格的大小)。上面的三种不同刻度的划分,每一种刻度我们称为:金字塔的一层,每一个图片块大小我们称之为:windows
size。如果你希望,金字塔的某一层输出n*n个特征,那么你就要用windows size大小为:(w/n,h/n)进行池化了。
当我们有很多层网络的时候,当网络输入的是一张任意大小的图片,这个时候我们可以一直进行卷积、池化,直到网络的倒数几层的时候,也就是我们即将与全连接层连接的时候,就要使用金字塔池化,使得任意大小的特征图都能够转换成固定大小的特征向量,这就是空间金字塔池化的奥义(多尺度特征提取出固定大小的特征向量)。具体的流程图如下:
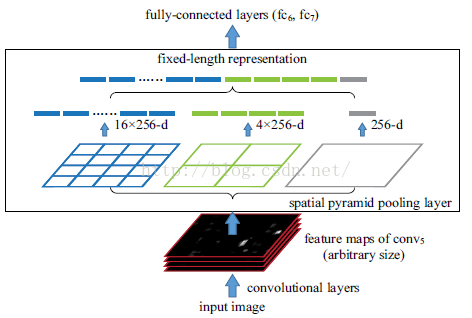
三、算法源码实现
caffe中有关于空间金字塔池化的源码:https://github.com/BVLC/caffe:
函数GetPoolingParam是我们需要细读的函数,里面设置了金子塔每一层窗口大小的计算,其它的函数就不贴了,对caffe底层实现感兴趣的,可以自己慢慢细读。
四、算法应用之物体检测
在SPP-Net还没出来之前,物体检测效果最好的应该是RCNN算法了,简单回顾一下R-CNN的总算法流程:
1、首先通过选择性搜索selective search,对待检测的图片进行搜索出2000个候选窗口。
2、把这2k个候选窗口的图片都缩放到227*227,然后分别输入CNN中,每个候选窗台提取出一个特征向量,也就是说利用CNN进行提取特征向量。
3、把上面每个候选窗口的对应特征向量,利用SVM算法进行分类识别。
可以看到R-CNN计算量肯定很大,因为2k个候选窗口都要输入到CNN中,分别进行特征提取,计算量肯定不是一般的大。
利用SPP-Net进行物体检测识别的具体算法的大体流程如下:
1、首先通过选择性搜索selective search,对待检测的图片进行搜索出2000个候选窗口。同R-CNN。
2、特征提取阶段。这一步就是和R-CNN最大的区别了,同样是用卷积神经网络进行特征提取,但是SPP-Net用的是金字塔池化。这一步骤的具体操作如下:把整张待检测的图片,输入CNN中,进行一次性特征提取,得到feature maps,然后在feature maps中找到各个候选框的区域,再对各个候选框采用金字塔空间池化,提取出固定长度的特征向量。SPP-Net只需要一次对整张图片进行特征提取,提高100倍的速度,R-CNN相当于遍历一个CNN两千次,而SPP-Net只需要遍历1次。
3、最后一步也是和R-CNN一样,采用SVM算法进行特征向量分类识别。
算法细节说明:看完上面的步骤二,我们会有一个疑问,那就是如何在feature maps中找到原始图片中候选框的对应区域?因为候选框是通过一整张原图片进行检测得到的,而feature maps的大小和原始图片的大小是不同的,feature maps是经过原始图片卷积、下采样等一系列操作后得到的。那么我们要如何在feature maps中找到对应的区域呢?这个答案可以在文献中的最后面附录中找到答案:APPENDIX A:Mapping a Window to Feature Maps。这个作者直接给出了一个很方便我们计算的公式:假设(x’,y’)表示特征图上的坐标点,坐标点(x,y)表示原输入图片上的点,那么它们之间有如下转换关系:
(x,y)=(S*x’,S*y’)
其中S的就是CNN中所有的strides的乘积。比如paper所用的ZF-5:
S=2*2*2*2=16
而对于Overfeat-5/7就是S=12,这个可以看一下下面的表格:
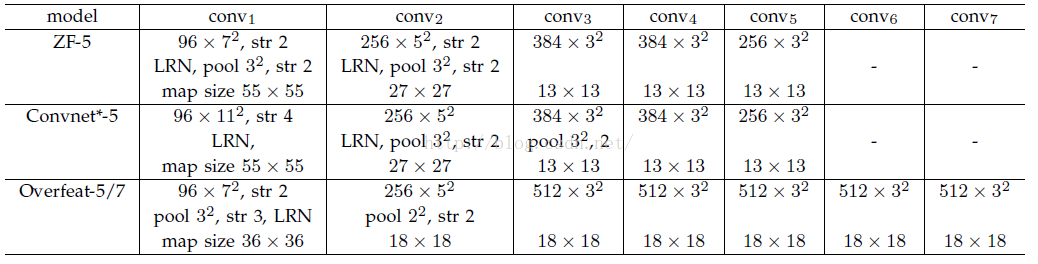
需要注意的是Strides包含了池化、卷积的stride。自己计算一下Overfeat-5/7(前5层)是不是等于12。
反过来,我们希望通过(x,y)坐标求解(x’,y’),那么计算公式如下:
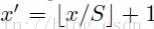
因此我们输入原图片检测到的windows,可以得到每个矩形候选框的四个角点,然后我们再根据公式:
Left、Top:
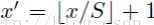
Right、Bottom:
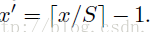
参考文献:
1、https://github.com/BVLC/caffe
2、《Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition》
3、http://research.microsoft.com/en-us/um/people/kahe/eccv14sppnet/index.html
4、http://caffe.berkeleyvision.org/
论文:http://xueshu.baidu.com/s?wd=paperuri%3A%28c51f05992150d24c15f0dabf0913382e%29&filter=sc_long_sign&tn=SE_xueshusource_2kduw22v&sc_vurl=http%3A%2F%2Farxiv.org%2Fpdf%2F1406.4729v4&ie=utf-8&sc_us=588800853727591174
一、相关理论
本篇博文主要讲解大神何凯明2014年的paper:《Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition》,这篇paper主要的创新点在于提出了空间金字塔池化。 这个算法比R-C
4000
NN算法的速度快了n多倍。
在现有的CNN中,对于结构已经确定的网络,需要输入一张固定大小的图片,比如224*224等。这样对于我们希望检测各种大小的图片的时候,需要经过裁剪,或者缩放等一系列操作,这样往往会降低识别检测的精度,于是paper提出了“空间金字塔池化”方法,这个算法的牛逼之处,可以输入任意大小的图片,不需要经过裁剪缩放等操作,不仅如此,这个算法用了以后,精度也会有提高。
空间金字塔池化,又称之为“SPP-Net”,这个就像什么:OverFeat、GoogleNet、R-CNN、AlexNet……为了方便,学完这篇paper之后,你就需要记住SPP-Net是什么东西了。空间金子塔以前在特征学习、特征表达的相关文献中,看到过几次这个算法。
之前的CNN要求输入固定大小的图片,CNN大体包含3部分,卷积、池化、全连接。
卷积:对图片输入大小没有要求;
池化:对图片大小没有要求;
全连接层:全连接层我们的连接权值矩阵的大小W,经过训练后,就是固定的大小了,比如我们从卷积到全连层,输入和输出的大小,分别是50、30个神经元,那么我们的权值矩阵(50,30)大小的矩阵了。空间金字塔池化要解决的就是从卷积层到全连接层之间的一个过度。一般空间金子塔池化层,都是放在卷积层到全连接层之间的一个网络层。
二、算法概述
空间金字塔特征提取(这边先不考虑“池化”):空间金字塔是很久以前的一种特征提取方法,跟Sift、Hog等特征息息相关。假设一个很简单两层网络:
输入层:一张任意大小的图片,假设其大小为(w,h)。
输出层:21个神经元。
也就是我们输入一张任意大小的特征图的时候,我们希望提取出21个特征。空间金字塔特征提取的过程如下:
图片尺度划分
如上图所示,当我们输入一张图片的时候,我们利用不同大小的刻度,对一张图片进行了划分。上面示意图中,利用了三种不同大小的刻度,对一张输入的图片进行了划分,最后总共可以得到16+4+1=21个块,我们即将从这21个块中,每个块提取出一个特征,这样刚好就是我们要提取的21维特征向量。
第一张图片,我们把一张完整的图片,分成了16个块,也就是每个块的大小就是(w/4,h/4);
第二张图片,划分了4个块,每个块的大小就是(w/2,h/2);
第三张图片,把一整张图片作为了一个块,也就是块的大小为(w,h)
空间金字塔最大池化的过程,其实就是从这21个图片块中,分别计算每个块的最大值,从而得到一个输出神经元。最后把一张任意大小的图片转换成了一个固定大小的21维特征(当然你可以设计其它维数的输出,增加金字塔的层数,或者改变划分网格的大小)。上面的三种不同刻度的划分,每一种刻度我们称为:金字塔的一层,每一个图片块大小我们称之为:windows
size。如果你希望,金字塔的某一层输出n*n个特征,那么你就要用windows size大小为:(w/n,h/n)进行池化了。
当我们有很多层网络的时候,当网络输入的是一张任意大小的图片,这个时候我们可以一直进行卷积、池化,直到网络的倒数几层的时候,也就是我们即将与全连接层连接的时候,就要使用金字塔池化,使得任意大小的特征图都能够转换成固定大小的特征向量,这就是空间金字塔池化的奥义(多尺度特征提取出固定大小的特征向量)。具体的流程图如下:
三、算法源码实现
caffe中有关于空间金字塔池化的源码:https://github.com/BVLC/caffe:
//1、输入参数pyramid_level:表示金字塔的第几层。我们将对这一层,进行划分为2^n个图片块。金字塔从第0层开始算起,0层就是一整张图片
//第1层就是把图片划分为2*2个块,第2层把图片划分为4*4个块,以此类推……,也就是说我们块的大小就是[w/(2^n),h/(2^n)]
//2、参数bottom_w、bottom_h是我们要输入这一层网络的特征图的大小
//3、参数spp_param是设置我们要进行池化的方法,比如最大池化、均值池化、概率池化……
LayerParameter SPPLayer<Dtype>::GetPoolingParam(const int pyramid_level,
const int bottom_h, const int bottom_w, const SPPParameter spp_param)
{
LayerParameter pooling_param;
int num_bins = pow(2, pyramid_level);//计算可以划分多少个刻度,最后我们图片块的个数就是num_bins*num_bins
//计算垂直方向上可以划分多少个刻度,不足的用pad补齐。然后我们最后每个图片块的大小就是(kernel_w,kernel_h)
int kernel_h = ceil(bottom_h / static_cast<double>(num_bins));//向上取整。采用pad补齐,pad的像素都是0
int remainder_h = kernel_h * num_bins - bottom_h;
int pad_h = (remainder_h + 1) / 2;//上下两边分摊pad
//计算水平方向的刻度大小,不足的用pad补齐
int kernel_w = ceil(bottom_w / static_cast<double>(num_bins));
int remainder_w = kernel_w * num_bins - bottom_w;
int pad_w = (remainder_w + 1) / 2;
pooling_param.mutable_pooling_param()->set_pad_h(pad_h);
pooling_param.mutable_pooling_param()->set_pad_w(pad_w);
pooling_param.mutable_pooling_param()->set_kernel_h(kernel_h);
pooling_param.mutable_pooling_param()->set_kernel_w(kernel_w);
pooling_param.mutable_pooling_param()->set_stride_h(kernel_h);
pooling_param.mutable_pooling_param()->set_stride_w(kernel_w);
switch (spp_param.pool()) {
case SPPParameter_PoolMethod_MAX://窗口最大池化
pooling_param.mutable_pooling_param()->set_pool(
PoolingParameter_PoolMethod_MAX);
break;
case SPPParameter_PoolMethod_AVE://平均池化
pooling_param.mutable_pooling_param()->set_pool(
PoolingParameter_PoolMethod_AVE);
break;
case SPPParameter_PoolMethod_STOCHASTIC://随机概率池化
pooling_param.mutable_pooling_param()->set_pool(
PoolingParameter_PoolMethod_STOCHASTIC);
break;
default:
LOG(FATAL) << "Unknown pooling method.";
}
return pooling_param;
}
template <typename Dtype>
//这个函数是为了获取我们本层网络的输入特征图、输出相关参数,然后设置相关变量,比如输入特征图的图片的大小、个数
void SPPLayer<Dtype>::LayerSetUp(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
SPPParameter spp_param = this->layer_param_.spp_param();
num_ = bottom[0]->num();//batch size 大小
channels_ = bottom[0]->channels();//特征图个数
bottom_h_ = bottom[0]->height();//特征图宽高
bottom_w_ = bottom[0]->width();
reshaped_first_time_ = false;
CHECK_GT(bottom_h_, 0) << "Input dimensions cannot be zero.";
CHECK_GT(bottom_w_, 0) << "Input dimensions cannot be zero.";
pyramid_height_ = spp_param.pyramid_height();//金子塔有多少层
split_top_vec_.clear();//清空相关数据
pooling_bottom_vecs_.clear();
pooling_layers_.clear();
pooling_top_vecs_.clear();
pooling_outputs_.clear();
flatten_layers_.clear();
flatten_top_vecs_.clear();
flatten_outputs_.clear();
concat_bottom_vec_.clear();
//如果金字塔只有一层,那么我们其实是对一整张图片进行pooling,也就是文献所提到的:global pooling
if (pyramid_height_ == 1) {
// pooling layer setup
LayerParameter pooling_param = GetPoolingParam(0, bottom_h_, bottom_w_,spp_param);
pooling_layers_.push_back(shared_ptr<PoolingLayer<Dtype> > (new PoolingLayer<Dtype>(pooling_param)));
pooling_layers_[0]->SetUp(bottom, top);
return;
}
//这个将用于保存金子塔每一层
for (int i = 0; i < pyramid_height_; i++) {
split_top_vec_.push_back(new Blob<Dtype>());
}
// split layer setup
LayerParameter split_param;
split_layer_.reset(new SplitLayer<Dtype>(split_param));
split_layer_->SetUp(bottom, split_top_vec_);
for (int i = 0; i < pyramid_height_; i++) {
// pooling layer input holders setup
pooling_bottom_vecs_.push_back(new vector<Blob<Dtype>*>);
pooling_bottom_vecs_[i]->push_back(split_top_vec_[i]);
pooling_outputs_.push_back(new Blob<Dtype>());
pooling_top_vecs_.push_back(new vector<Blob<Dtype>*>);
pooling_top_vecs_[i]->push_back(pooling_outputs_[i]);
// 获取金字塔每一层相关参数
LayerParameter pooling_param = GetPoolingParam(i, bottom_h_, bottom_w_, spp_param);
pooling_layers_.push_back(shared_ptr<PoolingLayer<Dtype> > (new PoolingLayer<Dtype>(pooling_param)));
pooling_layers_[i]->SetUp(*pooling_bottom_vecs_[i], *pooling_top_vecs_[i]);
//每一层金字塔输出向量
flatten_outputs_.push_back(new Blob<Dtype>());
flatten_top_vecs_.push_back(new vector<Blob<Dtype>*>);
flatten_top_vecs_[i]->push_back(flatten_outputs_[i]);
// flatten layer setup
LayerParameter flatten_param;
flatten_layers_.push_back(new FlattenLayer<Dtype>(flatten_param));
flatten_layers_[i]->SetUp(*pooling_top_vecs_[i], *flatten_top_vecs_[i]);
// concat layer input holders setup
concat_bottom_vec_.push_back(flatten_outputs_[i]);
}
// 把所有金字塔层的输出,串联成一个特征向量
LayerParameter concat_param;
concat_layer_.reset(new ConcatLayer<Dtype>(concat_param));
concat_layer_->SetUp(concat_bottom_vec_, top);
}函数GetPoolingParam是我们需要细读的函数,里面设置了金子塔每一层窗口大小的计算,其它的函数就不贴了,对caffe底层实现感兴趣的,可以自己慢慢细读。
四、算法应用之物体检测
在SPP-Net还没出来之前,物体检测效果最好的应该是RCNN算法了,简单回顾一下R-CNN的总算法流程:
1、首先通过选择性搜索selective search,对待检测的图片进行搜索出2000个候选窗口。
2、把这2k个候选窗口的图片都缩放到227*227,然后分别输入CNN中,每个候选窗台提取出一个特征向量,也就是说利用CNN进行提取特征向量。
3、把上面每个候选窗口的对应特征向量,利用SVM算法进行分类识别。
可以看到R-CNN计算量肯定很大,因为2k个候选窗口都要输入到CNN中,分别进行特征提取,计算量肯定不是一般的大。
利用SPP-Net进行物体检测识别的具体算法的大体流程如下:
1、首先通过选择性搜索selective search,对待检测的图片进行搜索出2000个候选窗口。同R-CNN。
2、特征提取阶段。这一步就是和R-CNN最大的区别了,同样是用卷积神经网络进行特征提取,但是SPP-Net用的是金字塔池化。这一步骤的具体操作如下:把整张待检测的图片,输入CNN中,进行一次性特征提取,得到feature maps,然后在feature maps中找到各个候选框的区域,再对各个候选框采用金字塔空间池化,提取出固定长度的特征向量。SPP-Net只需要一次对整张图片进行特征提取,提高100倍的速度,R-CNN相当于遍历一个CNN两千次,而SPP-Net只需要遍历1次。
3、最后一步也是和R-CNN一样,采用SVM算法进行特征向量分类识别。
算法细节说明:看完上面的步骤二,我们会有一个疑问,那就是如何在feature maps中找到原始图片中候选框的对应区域?因为候选框是通过一整张原图片进行检测得到的,而feature maps的大小和原始图片的大小是不同的,feature maps是经过原始图片卷积、下采样等一系列操作后得到的。那么我们要如何在feature maps中找到对应的区域呢?这个答案可以在文献中的最后面附录中找到答案:APPENDIX A:Mapping a Window to Feature Maps。这个作者直接给出了一个很方便我们计算的公式:假设(x’,y’)表示特征图上的坐标点,坐标点(x,y)表示原输入图片上的点,那么它们之间有如下转换关系:
(x,y)=(S*x’,S*y’)
其中S的就是CNN中所有的strides的乘积。比如paper所用的ZF-5:
S=2*2*2*2=16
而对于Overfeat-5/7就是S=12,这个可以看一下下面的表格:
需要注意的是Strides包含了池化、卷积的stride。自己计算一下Overfeat-5/7(前5层)是不是等于12。
反过来,我们希望通过(x,y)坐标求解(x’,y’),那么计算公式如下:
因此我们输入原图片检测到的windows,可以得到每个矩形候选框的四个角点,然后我们再根据公式:
Left、Top:
Right、Bottom:
参考文献:
1、https://github.com/BVLC/caffe
2、《Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition》
3、http://research.microsoft.com/en-us/um/people/kahe/eccv14sppnet/index.html
4、http://caffe.berkeleyvision.org/

相关文章推荐
- Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition(SPP-net) 笔记
- Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition--SPP-net论文笔记
- R-CNN学习笔记3:Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition(SPP-net)
- 【转】R-CNN学习笔记3:Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition(SPP-net)
- [SPP-NET]Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
- SPP-net:Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
- (SPP-net)Spatial Pyramid Pooling in deep convolutional networks for visual recognition
- RCNN学习笔记(3):Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition(SPP-net)
- RCNN学习笔记(3):Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition(SPP-net)
- RCNN学习笔记(3):Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition(SPP-net)
- RCNN学习笔记(3):Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition(SPP-net)
- RCNN学习笔记(3):Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition(SPP-net)
- SPPNet论文翻译-空间金字塔池化Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
- SPP-Net:Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
- RCNN(二)SPP-NET:Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
- Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition(SPP-Net)解读
- Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition(SPP-net)
- 深度学习笔记空间金字塔池化阅读笔记Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
- 深度学习论文笔记:Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
- 深度学习论文笔记-Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition