使用docx4j进行docx文档合并。
2017-06-22 00:00
731 查看
摘要: 之前做了一个项目,需要用到word合并。早期调研时间紧迫直接用了卓正解决的方案。
#docx4j介绍
docx4j是一个用于创建和操作Microsoft Open XML (Word docx, Powerpoint pptx, 和 Excel xlsx)文件的Java类库。
github docx4j项目地址
#开发环境
笔记仅供参考,具体开发环境可能存在版本差异。
OS:Windows 10
JDK:SUN 1.8
Eclipse:4.5[STS Spring定制版]
Maven:3.3.9
#使用介绍
这个问题之前是用卓正office解决的文档合成,我个人不是很满意效果。现在找到了新的方案感觉挺不错的,所以只是演示合成。我感觉poi也是可以的,但是我并没发现有合并文档的方法。也许是我不够深入吧。
#添加依赖
#代码用例
#测试数据

#测试结果
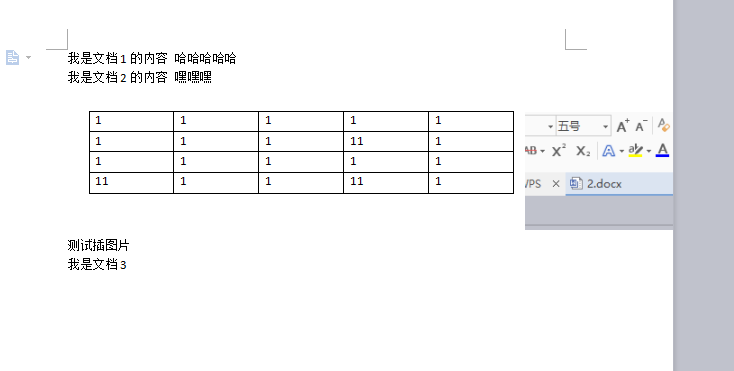
图片文字样式都可以合成,唯独插入的表单是个合成的时候位置不对。有待研究用法。
#docx4j介绍
docx4j是一个用于创建和操作Microsoft Open XML (Word docx, Powerpoint pptx, 和 Excel xlsx)文件的Java类库。
github docx4j项目地址
#开发环境
笔记仅供参考,具体开发环境可能存在版本差异。
OS:Windows 10
JDK:SUN 1.8
Eclipse:4.5[STS Spring定制版]
Maven:3.3.9
#使用介绍
这个问题之前是用卓正office解决的文档合成,我个人不是很满意效果。现在找到了新的方案感觉挺不错的,所以只是演示合成。我感觉poi也是可以的,但是我并没发现有合并文档的方法。也许是我不够深入吧。
#添加依赖
<dependency> <groupId>org.docx4j</groupId> <artifactId>docx4j</artifactId> <version>3.3.1</version> </dependency> <dependency> <groupId>org.docx4j</groupId> <artifactId>docx4j-ImportXHTML</artifactId> <version>3.3.1</version> </dependency> <dependency> <groupId>org.docx4j.org.capaxit.textimage</groupId> <artifactId>TextImageGen</artifactId> <version>1.9</version> </dependency> <!-- https://mvnrepository.com/artifact/org.plutext/jaxb-xmldsig-core --> <dependency> <groupId>org.plutext</groupId> <artifactId>jaxb-xmldsig-core</artifactId> <version>1.0.0</version> </dependency>
#代码用例
import java.io.Closeable;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import org.apache.commons.io.IOUtils;
import org.docx4j.jaxb.Context;
import org.docx4j.openpackaging.exceptions.Docx4JException;
import org.docx4j.openpackaging.packages.WordprocessingMLPackage;
import org.docx4j.openpackaging.parts.PartName;
import org.docx4j.openpackaging.parts.WordprocessingML.AlternativeFormatInputPart;
import org.docx4j.openpackaging.parts.WordprocessingML.MainDocumentPart;
import org.docx4j.relationships.Relationship;
import org.docx4j.wml.CTAltChunk;
public class MargeDoc {
public static final int BUFFER_LENGTH = 10240; //缓冲
public void mergeDocx(List<String> list, File file) {
List<InputStream> inList = new ArrayList<InputStream>();
for (int i = 0; i < list.size(); i++)
try {
inList.add(new FileInputStream(list.get(i)));
} catch (FileNotFoundException e) {
e.printStackTrace();
}
try {
InputStream inputStream = mergeDocx(inList);
write(inputStream, file);
} catch (Docx4JException | IOException e) {
e.printStackTrace();
}
}
public InputStream mergeDocx(final List<InputStream> streams) throws Docx4JException, IOException {
WordprocessingMLPackage target = null;
final File generated = File.createTempFile("generated", ".docx");
int chunkId = 0;
Iterator<InputStream> it = streams.iterator();
while (it.hasNext()) {
InputStream is = it.next();
if (is != null) {
if (target == null) {
// Copy first (master) document
OutputStream os = new FileOutputStream(generated);
os.write(IOUtils.toByteArray(is));
os.close();
target = WordprocessingMLPackage.load(generated);
} else {
insertDocx(target.getMainDocumentPart(), IOUtils.toByteArray(is), chunkId++);
}
}
}
if (target != null) {
target.save(generated);
return new FileInputStream(generated);
} else {
return null;
}
}
/**
* 插入单个文档
* @param main
* @param bytes
* @param chunkId
*/
private void insertDocx(MainDocumentPart main, byte[] bytes, int chunkId) {
try {
AlternativeFormatInputPart afiPart = new AlternativeFormatInputPart(
new PartName("/part" + chunkId + ".docx"));
afiPart.setBinaryData(bytes);
Relationship altChunkRel = main.addTargetPart(afiPart);
CTAltChunk chunk = Context.getWmlObjectFactory().createCTAltChunk();
chunk.setId(altChunkRel.getId());
main.addObject(chunk);
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 写入文件
* @param req
* @return
* @throws IOException
*/
public static boolean write(InputStream content,File file) {
OutputStream out = null;
int read = 0;
final byte[] bytes = new byte[BUFFER_LENGTH];
try {
out = new FileOutputStream(file, true);
while ((read = content.read(bytes)) != -1){
out.write(bytes, 0, read);
}
} catch (IOException e) {
return false;
}finally {
close(out);
close(content);
}
return true;
}
/**
* 关闭流
* @param stream
*/
public static void close(Closeable stream) {
try {
if (stream != null)
stream.close();
} catch (IOException e) {
}
}
public static void main(String[] args) throws Docx4JException, IOException{
MargeDoc wordUtil=new MargeDoc();
String template="D:/import/docx";
List<String> list=new ArrayList<String>();
list.add(template+"/1.docx");
list.add(template+"/2.docx");
list.add(template+"/3.docx");
wordUtil.mergeDocx(list, new File(template+"/out.docx"));
}
}#测试数据
#测试结果
图片文字样式都可以合成,唯独插入的表单是个合成的时候位置不对。有待研究用法。

相关文章推荐
- 使用docx4j编程式地创建复杂的Word(.docx)文档
- docx4j -- 使用Java处理word2007(.docx)文档
- 使用docx4j编程式地创建复杂的Word(.docx)文档
- 使用Apache POI生成Excel文档时,当进行单元格合并操作后,被合并的单元格边框会消失,使用如下方式可以解决。
- 使用Docx4j向docx文档中指定书签位置插入图片
- Java Web项目使用openoffice进行附件预览office文档(doc,docx,xls,xlsx,ppt,pptx)
- 使用Lucene对doc、docx、pdf、txt文档进行全文检索功能的实现
- 使用docx4j编程式地创建复杂的Word(.docx)文档
- 技术文档-使用C#进行E-Mail的收发操作
- Word2007使用小技巧——给word文档模版进行加密
- 技术文档:使用JavaFX Script 进行客户端-服务器通信(eNew 第二十八期/2007.09)
- 使用版本控制的分支合并进行开发,模拟,运营环境的统一部署
- 使用Pivot进行行列转换不能合并为一行的问题
- 使用未写入文档参数"_ALLOW_RESETLOGS_CORRUPTION"进行崩溃恢复经典
- 使用 jsoup 对 HTML 文档进行解析和操作
- 第一步:使用mshtml获取html文档dom树,解析html结构,进行高亮标记
- 使用ICU进行字符集探测 文档译稿
- 使用SQL Server 2008进行服务器合并
- 如何使用RMS对文档权限进行限制
- 使用JasperReports合并多个报表的word文档问题解决方法