第1.7章 scrapy之ip代理的使用
2017-06-21 14:19
267 查看
1 代理中间件
代码核心在于随机选择一条代理的ip和port,至于代理ip和port的来源,可以是购买的ip代理,也可以从网上爬取的。
2 settings配置
这里需要注意RetryMiddleware和ProxyMiddleware之间的顺序,否则会出现Python Scrapy不重试连接超时,scrapy会一致超时重连,我找遍QQ群,也没人回答我的问题。
中间件的顺序很重要,详细描述可以参考:SCRAPY中DOWNLOADER_MIDDLEWARES中间件的配置顺序
可供参考的顺序
3 检查ip代理是否成功
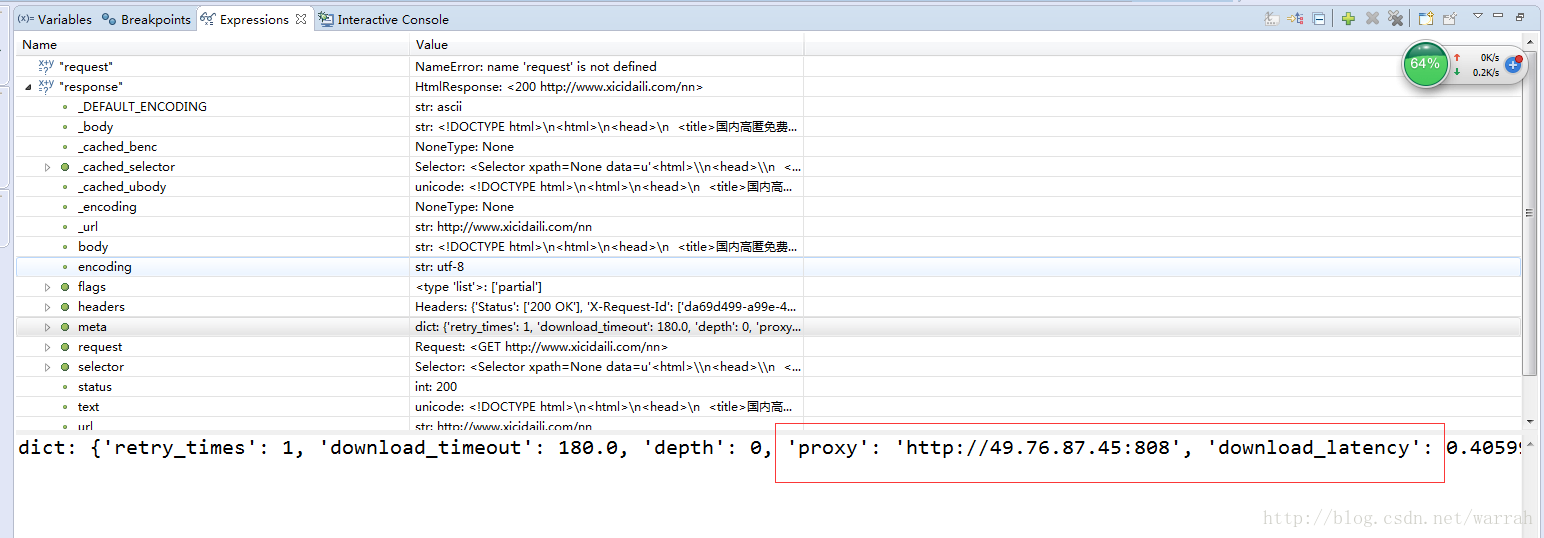
从下图的response可以看出确实是采用了代理地址
4 代理的作用
ip代理及其作用与使用方法
使用代理IP的优缺点?
5 获取随机代理
下面的方式是从数据库中随机找一条,数据库是mysql
代码核心在于随机选择一条代理的ip和port,至于代理ip和port的来源,可以是购买的ip代理,也可以从网上爬取的。
# -*- coding: utf-8 -*-
'''
Created on 2017年6月14日
@author: dzm
'''
from eie.middlewares import udf_config
from eie.service.EieIpService import EieIpService
logger = udf_config.logger
eieIpService = EieIpService()
class ProxyMiddleware(object):
'''
ip代理中间件
'''
def process_request(self,request,spider):
'''
在请求上添加ip代理
'''
if request.url.startswith('http://'):
proxy = eieIpService.select_rand('HTTP')
if proxy:
proxies = 'http://{}:{}'.format(proxy['ip'],proxy['port'])
else:
raise Exception('没有找到合适的IP代理')
else:
proxy = eieIpService.select_rand('HTTPS')
if proxy:
proxies = 'https://{}:{}'.format(proxy['ip'],proxy['port'])
else:
raise Exception('没有找到合适的IP代理')
request.meta['proxy'] = proxies2 settings配置
这里需要注意RetryMiddleware和ProxyMiddleware之间的顺序,否则会出现Python Scrapy不重试连接超时,scrapy会一致超时重连,我找遍QQ群,也没人回答我的问题。
中间件的顺序很重要,详细描述可以参考:SCRAPY中DOWNLOADER_MIDDLEWARES中间件的配置顺序
DOWNLOADER_MIDDLEWARES = {
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware':None,
'eie.middlewares.random_user_agent.RandomUserAgent': 100,
'eie.middlewares.proxy_middleware.ProxyMiddleware': 110,
'scrapy.downloadermiddlewares.retry.RetryMiddleware':120,
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware': 130,
}可供参考的顺序
DOWNLOADER_MIDDLEWARES_BASE
{
'scrapy.contrib.downloadermiddleware.robotstxt.RobotsTxtMiddleware': 100,
'scrapy.contrib.downloadermiddleware.httpauth.HttpAuthMiddleware': 300,
'scrapy.contrib.downloadermiddleware.downloadtimeout.DownloadTimeoutMiddleware': 350,
'scrapy.contrib.downloadermiddleware.useragent.UserAgentMiddleware': 400,
'scrapy.contrib.downloadermiddleware.retry.RetryMiddleware': 500,
'scrapy.contrib.downloadermiddleware.defaultheaders.DefaultHeadersMiddleware': 550,
'scrapy.contrib.downloadermiddleware.redirect.MetaRefreshMiddleware': 580,
'scrapy.contrib.downloadermiddleware.httpcompression.HttpCompressionMiddleware': 590,
'scrapy.contrib.downloadermiddleware.redirect.RedirectMiddleware': 600,
'scrapy.contrib.downloadermiddleware.cookies.CookiesMiddleware': 700,
'scrapy.contrib.downloadermiddleware.httpproxy.HttpProxyMiddleware': 750,
'scrapy.contrib.downloadermiddleware.chunked.ChunkedTransferMiddleware': 830,
'scrapy.contrib.downloadermiddleware.stats.DownloaderStats': 850,
'scrapy.contrib.downloadermiddleware.httpcache.HttpCacheMiddleware': 900,
}3 检查ip代理是否成功
从下图的response可以看出确实是采用了代理地址
4 代理的作用
ip代理及其作用与使用方法
使用代理IP的优缺点?
5 获取随机代理
def select_rand_zhimadaili(self): ''' 从芝麻代理中获取ip代理清单 @see: http://http.zhimadaili.com/index/api/newapi.html ''' try: proxy_keys_list = self.redis.keys() if proxy_keys_list: key_list = range(1, len(proxy_keys_list)) key = key_list[random.choice(key_list)] # proxy_list = json.load(self.redis.get(proxy_keys_list[key])) strs = self.redis.get(proxy_keys_list[key]) return eval(strs) else: socket = urllib2.urlopen('http://http.zhimadaili.com/index/api/new_get_use_ips.html?num=20&type=2&pro=0&city=0&yys=0&port=1&time=1') result = socket.read() result = json.loads(result) proxy_list = result['data'] for proxy in proxy_list: name = '{}:{}'.format(proxy['ip'],proxy['port']) self.redis.setex(name, proxy, 600) socket.close() key_list = range(1, len(proxy_list)) key = key_list[random.choice(key_list)] return proxy_list[key] except Exception,e: logger.error('请求zhimadaili.com获取代理失败,失败原因:%s' % e)
下面的方式是从数据库中随机找一条,数据库是mysql
def select_rand_db(self,types=None):
if types:
sql = "select ip,port,types from eie_ip where types='{}' order by rand() limit 1".format(types)
else:
sql = "select ip,port,types from eie_ip order by rand() limit 1 "
df = pd.read_sql(sql,self.engine)
results = json.loads(df.to_json(orient='records'))
if results and len(results)==1:
return results[0]
return None

相关文章推荐
- scrapy使用代理ip的时候下载器中间件的配置文件设置
- c# 使用HttpWebRequest,HttpWebResponse 快速验证代理IP是否有用
- 如何利用C#编写网页投票器程序 如何使用代理来投票 代理IP来投票
- 如何利用C#编写网页投票器程序 如何使用代理来投票 代理IP来投票
- httpclient使用代理ip
- IIS tomcat共用80端口解决一个IP多个域名:使用Nginx反向代理方式使两者兼容
- 使用代理IP,点击你的链接
- (转)IIS tomcat共用80端口解决一个IP多个域名:使用Nginx反向代理方式使两者兼容
- IIS tomcat共用80端口解决一个IP多个域名:使用Nginx反向代理方式使两者兼容
- 使用代理IP,点击你的链接
- PHP中使用curl及代理IP模拟post提交【两种实用方法】
- 使用代理IP安全吗?
- 【转】如何利用C#编写网页投票器程序|如何使用代理来投票|代理IP来投票
- idHTTP使用代理IP
- IIS tomcat共用80端口解决一个IP多个域名:使用Nginx反向代理方式使两者兼容
- c# 使用HttpWebRequest,HttpWebResponse 快速验证代理IP是否有用
- C# 使用HttpWebRequest,HttpWebResponse 快速验证代理IP是否有用
- 突破IP屏障,使用代理的方法
- 破解火车头采集器不能使用随机代理IP的限制
- Java中使用多线程、curl及代理IP模拟post提交和get访问