wireshark源码探索No.3---README.dissector文档
2017-06-17 13:59
411 查看
根据上文的介绍,大家都已了解到wireshark的README文档中README.dissector是比较重要的一个文档,那文档主要讲了什么,我们一起来看看。文档主要分为两部分:Setting up your protocol dissector code和Advanced dissector topics。
1、Setting up your protocol dissector code
该部分主要介绍了一个协议解析器(dissector)的架构,并详细讲解了wireshark提供的接口函数,例如wireshark列信息打印、协议树接口以及有关域信息的工作方式。文档是先介绍的解析器架构,然后详细描述各个部分的内容,我们为了理解方便,直接从界面开始,然后贴出相应文档的内容。
1.0)wireshark界面基本结构:

上图是wireshark普遍版本的界面,明显的将主要内容展示为三个区域,文档将这些命名为“pane”。第一个区域叫做包列表区域,主要是显示抓到的一些列cap包,每一个包对应一行信息,每行信息又包含多列,概括性描述了包的基本信息;第二个区域叫做协议树区域,主要是将1区域选中的某个包按照protocol
tree的形式分级展示包的实际解析内容,也是我们最为常用的区域;第三个区域就是原始包区域,以16进制展示数据包,便于协议解析人员分析具体包内容(很多协议解析的人会对着2、3区域做分析)。好了,界面分析完了,那这些界面的内容是如何展现的,如何处理的,就是我们所关注的重点。wireshark为1 2 区域都提供了完备的接口,我们首先了解一下这些.
1.1)包列表区域对应接口------对应文档1.4 Functions to handle columns in the traffic summary window.
包列表区域对应的列是数量固定的,用户可以在wireshark “column preference”配置,也就说明了接口数量也是固定的。每一列是怎么标识呢?宏定义,每一列都有一个宏定义标识,在代码里面看到COL_开头的基本都是对这部分的操作。

相对应的对列信息操作的接口函数如下:
col_set_str:最为常用函数之一,将某一列设置输入的字符串。col_set_str(pinfo->cinfo, COL_PROTOCOL, "FTP");/*设置COL_PROTOCOL列的数据为“FTP”*/
[align=justify]col_add_str:功能同上,只不过是将字符串做一份拷贝,避免字符串变量修改,相对来说安全一些。[/align]
col_add_fstr:将某一列设置为格式化后的字符串。col_add_fstr(pinfo->cinfo, COL_INFO, "%s: %s", is_request ? "Request" : "Response", format_text(line, linelen));/*将命令信息打印到COL_INFO列上*/
[align=justify]col_clear:填充列值之前,调用该接口去删除原有的列信息(层层协议解析都填充内容,例如ftp,会先填充ip层信息,在用tcp层信息覆盖,最后用ftp信息覆盖,该函数就是清理上层信息内容)[/align]
[align=justify]col_append_str:追加信息。在原有列信息上追加数据[/align]
[align=justify]col_append_fstr:追加格式化信息[/align]
[align=justify]col_append_sep_str、col_append_sep_fstr:即分段方式的信息追加。例如想在info列追加逗号分隔的数据“a,b,c,d,e,f”。如果用col_append_str追加“,a”时,信息就变成了“,a,b,c,d,e,f”多了一个逗号,这个函数就是避免第一个是逗号标记的问题。[/align]
[align=justify]col_set_fence、col_prepend_fence_fstr:有一些协议自身会带多个高层协议信息,例如SCTP,可能一个包会包含多个不同高层内容,为了避免解析器互相覆盖内容,fence接口用于隔离不同的信息。[/align]
[align=justify]col_set_time:没啥好介绍的,设置时间[/align]
1.2)协议树区域对应接口----对应文档1.5 Constructing the protocol tree.
协议树是wireshark最为重要的协议解析部分,也是我们平时用到的最多的部分,例如拿过包来看看里面具体是什么内容,都是要看这一部分。这里先解释一下所谓的协议树是什么意思。wireshark将所有能解析的内容形成一个树形结构(倒立的树。。),例如每个协议相当于一棵树,树干是协议名称,而协议下面是所有能够解析的参数。协议又互相挂载,例如下图:
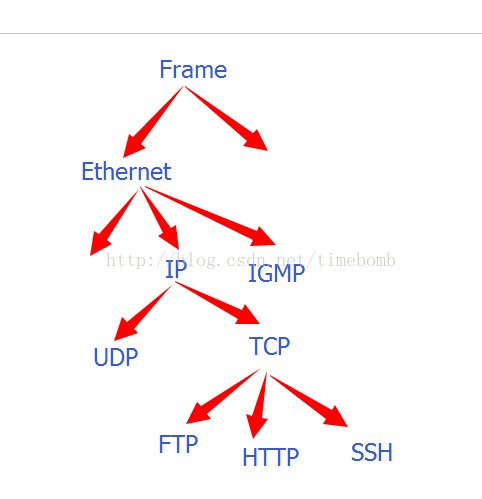
我们先看到Frame层,然后逐层解析以后会得到最高层数据信息,所以就形成了这个树形结构。但是在wireshark中直接这样展示会占用空间,也就有了wireshark现有的结构(第一幅图中的“2”区域),其实他也是一种树形结构。
既然有树,那么就要有构建树的接口,起码我们认为有两种1、添加节点;2、节点下挂载value树叶。
我们先讲解树叶:wireshark的处理是每个协议都是一个节点,节点下面所有能解析的内容都是其value树叶,所以它是①先定义树叶的属性(大小,类型,长度,名称等等),②然后注册所有数据到wireshark那棵巨大的树上(包含所有协议,所有变量),③最后解析器去解析的时候只需要将对应packet里面的数据挂上去,④展现只要按照之前注册的属性printf出来即可。
有关wireshark能够解析到的参数,你可以在界面直接看到,点击过滤界面的“Expression...”,弹出的界面就可以看到各个协议下面所有能解析到的树叶,如下图:
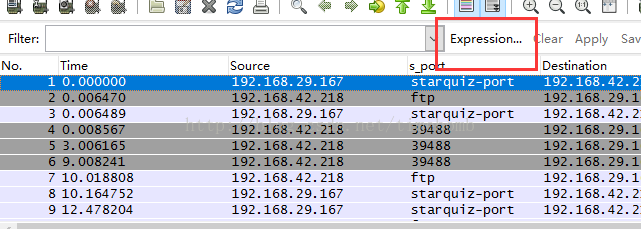
===》
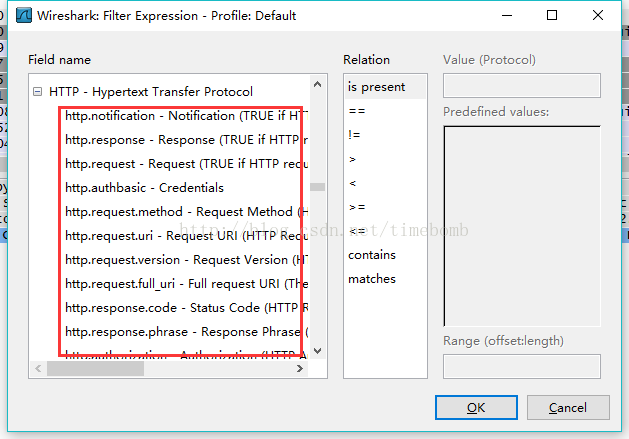
①:定义树叶的属性
如下图为ftp协议的摘抄:
有关hf_register_info_hf的定义包含两部分:
一个是p_id,注意这个变量在wireshark中都定义为了全局变量,例如ftp中的hf_ftp_response,它是一个树叶的id,默认为0,在后面注册的时候,会根据系统修改这个树叶的id为唯一,后续的树叶赋值都是根据这个id来操作的。第二个参数hfinfo,他是树叶详细信息的描述(解释见本章的开头):
有了这些信息,就可以描述出具体的树叶信息了。其中有一个bitmask需要关注一下,这个做的非常好,以tcp的flag标记为为例,大家都知道flag标记为是bit位标识的,而我们传统的都是用的字节来获取数据,这个bitmask就是一个bit掩码作用,在对如tcp的reset这个树叶赋值时,传过去的是一个字节,但是会自动根据其属性用
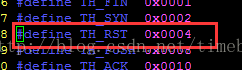
掩码处理得到真正是否有reset标记。
②:注册树叶---详见文档1.5.1 Field Registration.

如图,注册了ftp协议这个节点后,将所有的树叶(hf内包含)注册到节点上。
③:解析树叶数据--详见文档1.5.2 Adding Items and Values to the Protocol Tree.
④:展现
展现这一节就不做过多介绍了,因为我们是想了解wireshark的解析机制,具体页面展示,人性化等就不用涉及了。
小尾巴
上面介绍了树叶的详细操作,那树是如何操作的呢?---对应文档其实也是1.5.2 Adding Items and Values to the Protocol Tree.只不过是在开头部分。
proto_register_subtree_array就是用于创建一个个的小树枝,具体我觉得将代码不好阐述,下节内容我们以实际例子(packet-ftp.c)讲解他的使用方法。
1.3)原始包区域
这个也没啥好介绍的,就是把原始包以十六进制形式打印,
2、Advanced dissector topics
挖个坑,这一部分高级功能目前了解的还不是太多,后续理清楚了继续更新。
1、Setting up your protocol dissector code
该部分主要介绍了一个协议解析器(dissector)的架构,并详细讲解了wireshark提供的接口函数,例如wireshark列信息打印、协议树接口以及有关域信息的工作方式。文档是先介绍的解析器架构,然后详细描述各个部分的内容,我们为了理解方便,直接从界面开始,然后贴出相应文档的内容。
1.0)wireshark界面基本结构:
上图是wireshark普遍版本的界面,明显的将主要内容展示为三个区域,文档将这些命名为“pane”。第一个区域叫做包列表区域,主要是显示抓到的一些列cap包,每一个包对应一行信息,每行信息又包含多列,概括性描述了包的基本信息;第二个区域叫做协议树区域,主要是将1区域选中的某个包按照protocol
tree的形式分级展示包的实际解析内容,也是我们最为常用的区域;第三个区域就是原始包区域,以16进制展示数据包,便于协议解析人员分析具体包内容(很多协议解析的人会对着2、3区域做分析)。好了,界面分析完了,那这些界面的内容是如何展现的,如何处理的,就是我们所关注的重点。wireshark为1 2 区域都提供了完备的接口,我们首先了解一下这些.
1.1)包列表区域对应接口------对应文档1.4 Functions to handle columns in the traffic summary window.
包列表区域对应的列是数量固定的,用户可以在wireshark “column preference”配置,也就说明了接口数量也是固定的。每一列是怎么标识呢?宏定义,每一列都有一个宏定义标识,在代码里面看到COL_开头的基本都是对这部分的操作。
相对应的对列信息操作的接口函数如下:
col_set_str:最为常用函数之一,将某一列设置输入的字符串。col_set_str(pinfo->cinfo, COL_PROTOCOL, "FTP");/*设置COL_PROTOCOL列的数据为“FTP”*/
[align=justify]col_add_str:功能同上,只不过是将字符串做一份拷贝,避免字符串变量修改,相对来说安全一些。[/align]
col_add_fstr:将某一列设置为格式化后的字符串。col_add_fstr(pinfo->cinfo, COL_INFO, "%s: %s", is_request ? "Request" : "Response", format_text(line, linelen));/*将命令信息打印到COL_INFO列上*/
[align=justify]col_clear:填充列值之前,调用该接口去删除原有的列信息(层层协议解析都填充内容,例如ftp,会先填充ip层信息,在用tcp层信息覆盖,最后用ftp信息覆盖,该函数就是清理上层信息内容)[/align]
[align=justify]col_append_str:追加信息。在原有列信息上追加数据[/align]
[align=justify]col_append_fstr:追加格式化信息[/align]
[align=justify]col_append_sep_str、col_append_sep_fstr:即分段方式的信息追加。例如想在info列追加逗号分隔的数据“a,b,c,d,e,f”。如果用col_append_str追加“,a”时,信息就变成了“,a,b,c,d,e,f”多了一个逗号,这个函数就是避免第一个是逗号标记的问题。[/align]
[align=justify]col_set_fence、col_prepend_fence_fstr:有一些协议自身会带多个高层协议信息,例如SCTP,可能一个包会包含多个不同高层内容,为了避免解析器互相覆盖内容,fence接口用于隔离不同的信息。[/align]
[align=justify]col_set_time:没啥好介绍的,设置时间[/align]
1.2)协议树区域对应接口----对应文档1.5 Constructing the protocol tree.
协议树是wireshark最为重要的协议解析部分,也是我们平时用到的最多的部分,例如拿过包来看看里面具体是什么内容,都是要看这一部分。这里先解释一下所谓的协议树是什么意思。wireshark将所有能解析的内容形成一个树形结构(倒立的树。。),例如每个协议相当于一棵树,树干是协议名称,而协议下面是所有能够解析的参数。协议又互相挂载,例如下图:
我们先看到Frame层,然后逐层解析以后会得到最高层数据信息,所以就形成了这个树形结构。但是在wireshark中直接这样展示会占用空间,也就有了wireshark现有的结构(第一幅图中的“2”区域),其实他也是一种树形结构。
既然有树,那么就要有构建树的接口,起码我们认为有两种1、添加节点;2、节点下挂载value树叶。
我们先讲解树叶:wireshark的处理是每个协议都是一个节点,节点下面所有能解析的内容都是其value树叶,所以它是①先定义树叶的属性(大小,类型,长度,名称等等),②然后注册所有数据到wireshark那棵巨大的树上(包含所有协议,所有变量),③最后解析器去解析的时候只需要将对应packet里面的数据挂上去,④展现只要按照之前注册的属性printf出来即可。
有关wireshark能够解析到的参数,你可以在界面直接看到,点击过滤界面的“Expression...”,弹出的界面就可以看到各个协议下面所有能解析到的树叶,如下图:
===》
①:定义树叶的属性
struct header_field_info {
const char *name;/*参数名称*/
const char *abbrev;/*参数索引,用于过滤,必须以协议名开头,中间用点号分隔*/
enum ftenum type;/*参数的数据类型,类型非常丰富,可对照文档查看*/
int display;/*定义显示方式,例如FT_ABSOLUTE_TIME表示显示为事件*/
const void *strings;/*转译,例如ftp.response.code返回数值是200,会自动转换为response_table中的 "Command okay"*/
guint64 bitmask;/*bit位掩码,例如tcp中flag标记位,不够一个字节怎么赋值?直接用bitmask与传入的字节与运算,取出bit位*/
const char *blurb;
.....
};/*其他内容详见文档*/如下图为ftp协议的摘抄:
void
proto_register_ftp(void)
{
static hf_register_info hf[] = {
{ &hf_ftp_response,
{ "Response", "ftp.response",
FT_BOOLEAN, BASE_NONE, NULL, 0x0,
"TRUE if FTP response", HFILL }},
{ &hf_ftp_request,
{ "Request", "ftp.request",
FT_BOOLEAN, BASE_NONE, NULL, 0x0,
"TRUE if FTP request", HFILL }},
{ &hf_ftp_request_command,
{ "Request command", "ftp.request.command",
FT_STRING, BASE_NONE, NULL, 0x0,
NULL, HFILL }},
{ &hf_ftp_request_arg,
{ "Request arg", "ftp.request.arg",
FT_STRING, BASE_NONE, NULL, 0x0,
NULL, HFILL }},
{ &hf_ftp_response_code,
{ "Response code", "ftp.response.code",
FT_UINT32, BASE_DEC|BASE_EXT_STRING, &response_table_ext, 0x0,
NULL, HFILL }},有关hf_register_info_hf的定义包含两部分:
/** Used when registering many fields at once, using proto_register_field_array() */
typedef struct hf_register_info {
int *p_id; /**< written to by register() function */
header_field_info hfinfo; /**< the field info to be registered */
} hf_register_info;一个是p_id,注意这个变量在wireshark中都定义为了全局变量,例如ftp中的hf_ftp_response,它是一个树叶的id,默认为0,在后面注册的时候,会根据系统修改这个树叶的id为唯一,后续的树叶赋值都是根据这个id来操作的。第二个参数hfinfo,他是树叶详细信息的描述(解释见本章的开头):
/** information describing a header field */
struct _header_field_info {
/* ---------- set by dissector --------- */
const char *name; /**< [FIELDNAME] full name of this field */
const char *abbrev; /**< [FIELDABBREV] abbreviated name of this field */
enum ftenum type; /**< [FIELDTYPE] field type, one of FT_ (from ftypes.h) */
int display; /**< [FIELDDISPLAY] one of BASE_, or field bit-width if FT_BOOLEAN and non-zero bitmask */
const void *strings; /**< [FIELDCONVERT] value_string, val64_string, range_string or true_false_string,
typically converted by VALS(), RVALS() or TFS().
If this is an FT_PROTOCOL then it points to the
associated protocol_t structure */
guint64 bitmask; /**< [BITMASK] bitmask of interesting bits */
const char *blurb; /**< [FIELDDESCR] Brief description of field */
/* ------- set by proto routines (prefilled by HFILL macro, see below) ------ */
int id; /**< Field ID */
int parent; /**< parent protocol tree */
hf_ref_type ref_type; /**< is this field referenced by a filter */
int same_name_prev_id; /**< ID of previous hfinfo with same abbrev */
header_field_info *same_name_next; /**< Link to next hfinfo with same abbrev */
};有了这些信息,就可以描述出具体的树叶信息了。其中有一个bitmask需要关注一下,这个做的非常好,以tcp的flag标记为为例,大家都知道flag标记为是bit位标识的,而我们传统的都是用的字节来获取数据,这个bitmask就是一个bit掩码作用,在对如tcp的reset这个树叶赋值时,传过去的是一个字节,但是会自动根据其属性用
掩码处理得到真正是否有reset标记。
②:注册树叶---详见文档1.5.1 Field Registration.
如图,注册了ftp协议这个节点后,将所有的树叶(hf内包含)注册到节点上。
③:解析树叶数据--详见文档1.5.2 Adding Items and Values to the Protocol Tree.
/* 如下为所有的解析接口,第一参数tree是实际页面展现的tree(后续章节会有实例介绍),id为每个树叶注册后得到的p_id;tvb是wireshark中专有的数据结构,叫做Testy, Virtual(-izable) Buffer,所有数据包信息的读取都要通过它,他对数据包访问做了大量的封装,后面会介绍到;start是实际数据在tvb中的偏移量;length是长度;encoding视情况而定,如果树叶是数值型数据,它就表示大端序ENC_BIG_ENDIAN小端序 ENC_LITTLE_ENDIAN(具体意义Google),如果是字符串型数据,则表示其编码格式ENC_UTF_8等。 接口将tvb的数据信息发送到指定的树叶上,然后接口会自动根据树叶类型格式化数据,有的可能是字符串,有的可能是值,各种都不一样。 */ proto_item* proto_tree_add_item(tree, id, tvb, start, length, encoding); proto_item* proto_tree_add_item_ret_int(tree, id, tvb, start, length, encoding, *retval); proto_item* proto_tree_add_item_ret_uint(tree, id, tvb, start, length, encoding, *retval); proto_item* proto_tree_add_subtree(tree, tvb, start, length, idx, tree_item, text); proto_item* proto_tree_add_subtree_format(tree, tvb, start, length, idx, tree_item, format, ...); proto_item* proto_tree_add_none_format(tree, id, tvb, start, length, format, ...); proto_item* proto_tree_add_protocol_format(tree, id, tvb, start, length, format, ...); proto_item * proto_tree_add_bytes(tree, id, tvb, start, length, start_ptr); proto_item * proto_tree_add_bytes_item(tree, id, tvb, start, length, encoding, retval, endoff, err); proto_item * proto_tree_add_bytes_format(tree, id, tvb, start, length, start_ptr, format, ...); proto_item * proto_tree_add_bytes_format_value(tree, id, tvb, start, length, start_ptr, format, ...); proto_item * proto_tree_add_bytes_with_length(tree, id, tvb, start, tvb_length, start_ptr, ptr_length); proto_item * proto_tree_add_time(tree, id, tvb, start, length, value_ptr); proto_item * proto_tree_add_time_item(tree, id, tvb, start, length, encoding, retval, endoff, err); proto_item * proto_tree_add_time_format(tree, id, tvb, start, length, value_ptr, format, ...); proto_item * proto_tree_add_time_format_value(tree, id, tvb, start, length, value_ptr, format, ...); proto_item * proto_tree_add_ipxnet(tree, id, tvb, start, length, value); proto_item * proto_tree_add_ipxnet_format(tree, id, tvb, start, length, value, format, ...); proto_item * proto_tree_add_ipxnet_format_value(tree, id, tvb, start, length, value, format, ...); proto_item * proto_tree_add_ipv4(tree, id, tvb, start, length, value); proto_item * proto_tree_add_ipv4_format(tree, id, tvb, start, length, value, format, ...); proto_item * proto_tree_add_ipv4_format_value(tree, id, tvb, start, length, value, format, ...); proto_item * proto_tree_add_ipv6(tree, id, tvb, start, length, value_ptr); proto_item * proto_tree_add_ipv6_format(tree, id, tvb, start, length, value_ptr, format, ...); proto_item * proto_tree_add_ipv6_format_value(tree, id, tvb, start, length, value_ptr, format, ...); proto_item * proto_tree_add_ether(tree, id, tvb, start, length, value_ptr); proto_item * proto_tree_add_ether_format(tree, id, tvb, start, length, value_ptr, format, ...); proto_item * proto_tree_add_ether_format_value(tree, id, tvb, start, length, value_ptr, format, ...); proto_item * proto_tree_add_guid(tree, id, tvb, start, length, value_ptr); proto_item * proto_tree_add_guid_format(tree, id, tvb, start, length, value_ptr, format, ...); proto_item * proto_tree_add_guid_format_value(tree, id, tvb, start, length, value_ptr, format, ...); proto_item * proto_tree_add_oid(tree, id, tvb, start, length, value_ptr); proto_item * proto_tree_add_oid_format(tree, id, tvb, start, length, value_ptr, format, ...); proto_item * proto_tree_add_oid_format_value(tree, id, tvb, start, length, value_ptr, format, ...); proto_item * proto_tree_add_string(tree, id, tvb, start, length, value_ptr); proto_item * proto_tree_add_string_format(tree, id, tvb, start, length, value_ptr, format, ...); proto_item * proto_tree_add_string_format_value(tree, id, tvb, start, length, value_ptr, format, ...); proto_item * proto_tree_add_boolean(tree, id, tvb, start, length, value); proto_item * proto_tree_add_boolean_format(tree, id, tvb, start, length, value, format, ...); proto_item * proto_tree_add_boolean_format_value(tree, id, tvb, start, length, value, format, ...); proto_item * proto_tree_add_float(tree, id, tvb, start, length, value); proto_item * proto_tree_add_float_format(tree, id, tvb, start, length, value, format, ...); proto_item * proto_tree_add_float_format_value(tree, id, tvb, start, length, value, format, ...); proto_item * proto_tree_add_double(tree, id, tvb, start, length, value); proto_item * proto_tree_add_double_format(tree, id, tvb, start, length, value, format, ...); proto_item * proto_tree_add_double_format_value(tree, id, tvb, start, length, value, format, ...); proto_item * proto_tree_add_uint(tree, id, tvb, start, length, value); proto_item * proto_tree_add_uint_format(tree, id, tvb, start, length, value, format, ...); proto_item * proto_tree_add_uint_format_value(tree, id, tvb, start, length, value, format, ...); proto_item * proto_tree_add_uint64(tree, id, tvb, start, length, value); proto_item * proto_tree_add_uint64_format(tree, id, tvb, start, length, value, format, ...); proto_item * proto_tree_add_uint64_format_value(tree, id, tvb, start, length, value, format, ...); proto_item * proto_tree_add_int(tree, id, tvb, start, length, value); proto_item * proto_tree_add_int_format(tree, id, tvb, start, length, value, format, ...); proto_item * proto_tree_add_int_format_value(tree, id, tvb, start, length, value, format, ...); proto_item * proto_tree_add_int64(tree, id, tvb, start, length, value); proto_item * proto_tree_add_int64_format(tree, id, tvb, start, length, value, format, ...); proto_item * proto_tree_add_int64_format_value(tree, id, tvb, start, length, value, format, ...); proto_item * proto_tree_add_eui64(tree, id, tvb, start, length, value); proto_item * proto_tree_add_eui64_format(tree, id, tvb, start, length, value, format, ...); proto_item * proto_tree_add_eui64_format_value(tree, id, tvb, start, length, value, format, ...); proto_item * proto_tree_add_bitmask(tree, tvb, start, header, ett, fields, encoding); proto_item * proto_tree_add_bitmask_len(tree, tvb, start, len, header, ett, fields, encoding); proto_item * proto_tree_add_bitmask_text(tree, tvb, offset, len, name, fallback, ett, fields, encoding, flags); proto_item * proto_tree_add_bitmask_with_flags(tree, tvb, offset, hf_hdr, ett, fields, encoding, flags); proto_item* proto_tree_add_bits_item(tree, id, tvb, bit_offset, no_of_bits, encoding); proto_item * proto_tree_add_split_bits_item_ret_val(tree, hf_index, tvb, bit_offset, crumb_spec, return_value); voidproto_tree_add_split_bits_crumb(tree, hf_index, tvb, bit_offset, crumb_spec, crumb_index); proto_item * proto_tree_add_bits_ret_val(tree, id, tvb, bit_offset, no_of_bits, return_value, encoding); proto_item * proto_tree_add_uint_bits_format_value(tree, id, tvb, bit_offset, no_of_bits, value, format, ...); proto_item * proto_tree_add_boolean_bits_format_value(tree, id, tvb, bit_offset, no_of_bits, value, format, ...); proto_item * proto_tree_add_int_bits_format_value(tree, id, tvb, bit_offset, no_of_bits, value, format, ...); proto_item * proto_tree_add_float_bits_format_value(tree, id, tvb, bit_offset, no_of_bits, value, format, ...); proto_item * proto_tree_add_ts_23_038_7bits_item(tree, hf_index, tvb, bit_offset, no_of_chars);
④:展现
展现这一节就不做过多介绍了,因为我们是想了解wireshark的解析机制,具体页面展示,人性化等就不用涉及了。
小尾巴
上面介绍了树叶的详细操作,那树是如何操作的呢?---对应文档其实也是1.5.2 Adding Items and Values to the Protocol Tree.只不过是在开头部分。
proto_register_subtree_array就是用于创建一个个的小树枝,具体我觉得将代码不好阐述,下节内容我们以实际例子(packet-ftp.c)讲解他的使用方法。
1.3)原始包区域
这个也没啥好介绍的,就是把原始包以十六进制形式打印,
2、Advanced dissector topics
挖个坑,这一部分高级功能目前了解的还不是太多,后续理清楚了继续更新。

相关文章推荐
- wireshark源码探索No.4---packet-ftp.c源码分析
- wireshark源码探索No.1---编译,调试,阅读
- wireshark源码探索No.5---wireshark的流管理
- CoreCLR源码探索(六) NullReferenceException是如何发生的
- Android源码探索-View体系(一)
- CoordinatorLayout源码解析,探索Behavior机制的奥秘
- CoreCLR源码探索(一) Object是什么
- CoreCLR源码探索(八) JIT的工作原理(详解篇)
- numberOfLeadingZeros(int i)源码探索
- WireShark抓包 图解探索网络请求过程(五层网络模型、三次握手、滑动窗口协议)
- 源码探索系列5---关于Broadcast、LocalBroadcastManager 、EventBus的比较和源码解析
- Blade源码深入探索1--注册路由之ioc容器
- 源码探索系列13---Window的PhoneWindow与WindowManager
- Android View 绘制之Layout源码探索
- 【wireshark】fedora 或者ubuntu 源码编译安装wireshark1.70
- Wireshark的Pcap文件格式分析及解析源码
- 探索angular源码--启动(1)
- Vue.js v2.1.10 源码探索 v1.0
- 写在探索源码的路上
- CoreCLR源码探索(六) NullReferenceException是如何发生的