MySQL二阶段提交以及xtrabackup如何保证备份不丢失数据
2017-06-16 13:47
656 查看
MySQL二阶段提交与xtrabackup如何保证备份不丢失数据
MySQL二阶段提交与crash
recovery
1.
MySQL二阶段提交
2.
crash recovery的实现
xtrabackup如何实现数据不丢失
1.
general log中xtrabackup的备份记录
前提:设置了双1
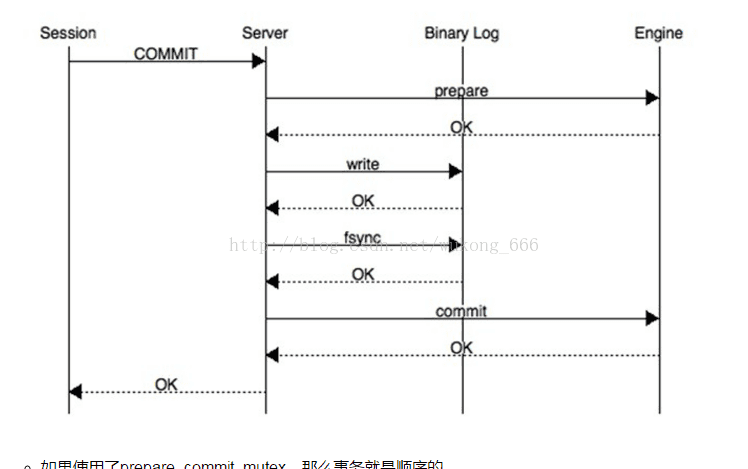
如图,当用户提交事务的时候,当设置了双1,会进行redo日志的实时刷新。实际上,即使一个事务还没有commit,只是执行到了insert,此时redo就已经实时开始记录数据页的变化了(undo记录修改前的数据);当事务commit之后,首先会打上prepare的标记,也就是二阶段提交的redo prepare阶段,此时redo日志已经开始了fsync刷盘动作。
当redo prepare完成后,返回ok;然后开始写binlog buffer,并且开始fsync刷盘到binlog。此时为二阶段提交的binlog fsync阶段。
redo log具体的实现方式与设计特点:
Undo + Redo的设计主要考虑的是提升IO性能。虽说通过缓存数据,减少了写数据的IO.
但是却引入了新的IO,即写Redo Log的IO。如果Redo Log的IO性能不好,就不能起到提高性能的目的。
为了保证Redo Log能够有比较好的IO性能,InnoDB 的 Redo Log的设计有以下几个特点:
A. 尽量保持Redo Log存储在一段连续的空间上。因此在系统第一次启动时就会将日志文件的空间完全分配。以顺序追加的方式记录Redo Log,通过顺序IO来改善性能。
B. 批量写入日志。日志并不是直接写入文件,而是先写入redo log buffer.当需要将日志刷新到磁盘时(如事务提交),将许多日志一起写入磁盘.
C. 并发的事务共享Redo Log的存储空间,它们的Redo Log按语句的执行顺序,依次交替的记录在一起,以减少日志占用的空间。例如,Redo Log中的记录内容可能是这样的:
记录1: trx1, insert …
记录2: trx2, update …
记录3: trx1, delete …
记录4: trx3, update …
记录5: trx2, insert …
D. 因为C的原因,当一个事务将Redo Log写入磁盘时,也会将其他未提交的事务的日志写入磁盘。
E. Redo Log上只进行顺序追加的操作,当一个事务需要回滚时,它的Redo Log记录也不会从Redo Log中删除掉。
来
e247
源: http://www.cnblogs.com/Bozh/archive/2013/03/18/2966494.html
PS: undo的变化也会记录在redo中。InnoDB将Undo Log看作数据,因此记录Undo Log的操作也会记录到redo log中。这样undo log就可以象数据一样缓存起来,而不用在redo log之前写入磁盘了。在redo持久化的同时,就能将undo也顺带持久化了。
当binlog刷盘完成后,然后会将redo中对应事务的prepare标记修改为commit,表明经过上述过程,事务已经在日志(binlog以及redo)里面完成了commit,对应的是二阶段提交的redo commit阶段。redo commit标记这个事务已经在innodb层redo日志中被提交,后续做crash recovery的时候需要前滚(如果数据还未落盘)。
MySQL在做crash recovery的时候,会去比对redo中记录的LSN与数据页中的LSN。
如果redo中的LSN号小,则不需要对该页恢复数据。
如果redo中的LSN号大(数据还未刷到磁盘),
并且事务已经有了commit标记,则前滚;
如果事务带有的是prepare标记,这个时候就需要结合binlog来判断这条事务是需要前滚还是回滚:
- 如果这条事务在binlog中没有,则回滚;
- 如果这条事务已经刷到了binlog日志文件中,则这个事务会被重新提交并在redo log中打上commit标记。(这样的话 也可以保证主从数据的一致)
如果事务既不带prepare标记,也不带commit标记,则回滚。
由此我们可以看到,MySQL在做恢复的时候,并不是单纯的依靠redo、undo来做数据正常恢复,还需要结合binlog中的事务信息,与redo中的进行比对,再决定某些事务是否需要前滚。
那么,xtrabackup备份过程是不备份binlog的,它又是如何实现数据的一致性?
FLUSH TABLES会关闭所有打开的表,等待所有事物结束并关闭打开的表。
FLUSH TABLES WITH READ LOCK会加一把全局读锁,阻止新的修改数据的操作。
SHOW MASTER STATUS获取一致性位点。在加全局读锁的情况下,数据不会有更新,所以这个时候数据库状态是一致的。
FLUSH NO_WRITE_TO_BINLOG ENGINE LOGS 这个操作会将Innodb层的redo日志进行持久化刷到磁盘,然后再拷贝redo日志,保证了redo日志是最新,保证数据一致性。那如何与binlog做协调?怎么保证redo记录的数据与binlog数据是一致的?这个应该就是结合SHOW MASTER STATUS来确定拷贝所获取到的binlog file以及binlog pos对应的redo点为止,也就是一致性位点。而FLUSH NO_WRITE_TO_BINLOG
ENGINE LOGS确保了还在重做日志缓冲中的commit标记,持久化刷新到redo日志中并落盘;确保不丢掉这个事务。
MySQL二阶段提交与crash
recovery
1.
MySQL二阶段提交
2.
crash recovery的实现
xtrabackup如何实现数据不丢失
1.
general log中xtrabackup的备份记录
MySQL二阶段提交与xtrabackup如何保证备份不丢失数据
前提:设置了双1
MySQL二阶段提交与crash recovery
1. MySQL二阶段提交
如图,当用户提交事务的时候,当设置了双1,会进行redo日志的实时刷新。实际上,即使一个事务还没有commit,只是执行到了insert,此时redo就已经实时开始记录数据页的变化了(undo记录修改前的数据);当事务commit之后,首先会打上prepare的标记,也就是二阶段提交的redo prepare阶段,此时redo日志已经开始了fsync刷盘动作。
当redo prepare完成后,返回ok;然后开始写binlog buffer,并且开始fsync刷盘到binlog。此时为二阶段提交的binlog fsync阶段。
redo log具体的实现方式与设计特点:
Undo + Redo的设计主要考虑的是提升IO性能。虽说通过缓存数据,减少了写数据的IO.
但是却引入了新的IO,即写Redo Log的IO。如果Redo Log的IO性能不好,就不能起到提高性能的目的。
为了保证Redo Log能够有比较好的IO性能,InnoDB 的 Redo Log的设计有以下几个特点:
A. 尽量保持Redo Log存储在一段连续的空间上。因此在系统第一次启动时就会将日志文件的空间完全分配。以顺序追加的方式记录Redo Log,通过顺序IO来改善性能。
B. 批量写入日志。日志并不是直接写入文件,而是先写入redo log buffer.当需要将日志刷新到磁盘时(如事务提交),将许多日志一起写入磁盘.
C. 并发的事务共享Redo Log的存储空间,它们的Redo Log按语句的执行顺序,依次交替的记录在一起,以减少日志占用的空间。例如,Redo Log中的记录内容可能是这样的:
记录1: trx1, insert …
记录2: trx2, update …
记录3: trx1, delete …
记录4: trx3, update …
记录5: trx2, insert …
D. 因为C的原因,当一个事务将Redo Log写入磁盘时,也会将其他未提交的事务的日志写入磁盘。
E. Redo Log上只进行顺序追加的操作,当一个事务需要回滚时,它的Redo Log记录也不会从Redo Log中删除掉。
来
e247
源: http://www.cnblogs.com/Bozh/archive/2013/03/18/2966494.html
PS: undo的变化也会记录在redo中。InnoDB将Undo Log看作数据,因此记录Undo Log的操作也会记录到redo log中。这样undo log就可以象数据一样缓存起来,而不用在redo log之前写入磁盘了。在redo持久化的同时,就能将undo也顺带持久化了。
当binlog刷盘完成后,然后会将redo中对应事务的prepare标记修改为commit,表明经过上述过程,事务已经在日志(binlog以及redo)里面完成了commit,对应的是二阶段提交的redo commit阶段。redo commit标记这个事务已经在innodb层redo日志中被提交,后续做crash recovery的时候需要前滚(如果数据还未落盘)。
2. crash recovery的实现
MySQL在做crash recovery的时候,会去比对redo中记录的LSN与数据页中的LSN。如果redo中的LSN号小,则不需要对该页恢复数据。
如果redo中的LSN号大(数据还未刷到磁盘),
并且事务已经有了commit标记,则前滚;
如果事务带有的是prepare标记,这个时候就需要结合binlog来判断这条事务是需要前滚还是回滚:
- 如果这条事务在binlog中没有,则回滚;
- 如果这条事务已经刷到了binlog日志文件中,则这个事务会被重新提交并在redo log中打上commit标记。(这样的话 也可以保证主从数据的一致)
如果事务既不带prepare标记,也不带commit标记,则回滚。
由此我们可以看到,MySQL在做恢复的时候,并不是单纯的依靠redo、undo来做数据正常恢复,还需要结合binlog中的事务信息,与redo中的进行比对,再决定某些事务是否需要前滚。
那么,xtrabackup备份过程是不备份binlog的,它又是如何实现数据的一致性?
xtrabackup如何实现数据不丢失
1. general log中xtrabackup的备份记录
13 Connect root@localhost on
13 Query SET SESSION wait_timeout=2147483
13 Query SHOW VARIABLES
13 Query SHOW ENGINE INNODB STATUS
170507 22:12:29 13 Query SET SESSION lock_wait_timeout=31536000
13 Query FLUSH NO_WRITE_TO_BINLOG TABLES
13 Query FLUSH TABLES WITH READ LOCK
170507 22:12:39 13 Query SHOW MASTER STATUS
13 Query SHOW VARIABLES
13 Query FLUSH NO_WRITE_TO_BINLOG ENGINE LOGS
13 Query UNLOCK TABLES
13 Query SELECT UUID()
13 Query SELECT VERSION()
13 Quit
FLUSH TABLES会关闭所有打开的表,等待所有事物结束并关闭打开的表。
FLUSH TABLES WITH READ LOCK会加一把全局读锁,阻止新的修改数据的操作。
SHOW MASTER STATUS获取一致性位点。在加全局读锁的情况下,数据不会有更新,所以这个时候数据库状态是一致的。
FLUSH NO_WRITE_TO_BINLOG ENGINE LOGS 这个操作会将Innodb层的redo日志进行持久化刷到磁盘,然后再拷贝redo日志,保证了redo日志是最新,保证数据一致性。那如何与binlog做协调?怎么保证redo记录的数据与binlog数据是一致的?这个应该就是结合SHOW MASTER STATUS来确定拷贝所获取到的binlog file以及binlog pos对应的redo点为止,也就是一致性位点。而FLUSH NO_WRITE_TO_BINLOG
ENGINE LOGS确保了还在重做日志缓冲中的commit标记,持久化刷新到redo日志中并落盘;确保不丢掉这个事务。

相关文章推荐
- Mariadb 分布式事务两阶段提交 binlog日志 查询日志 都记录了一些什么内容 以及恢复被丢失数据方式
- PHP中如何连接Mysql以及读取数据
- [SQL Server] 主数据文件损坏(或丢失)情况下,如何备份尾部事务日志.
- Mysql ibdata 丢失或损坏如何通过frm&ibd 恢复数据
- 程序猿(媛)Shell脚本必备技能之一: 在Linux下如何自动备份mysql数据
- 如何在servlet中获取jsp中form表单提交的变量,以及jsp与servlet之间的数据传递
- Mysql ibdata 丢失或损坏如何通过frm&ibd 恢复数据
- 忆龙2009:Cams重新安装如何保证数据库用户数据不丢失
- 重装MySQL后如何恢复没有备份的早先数据
- Mysql ibdata 丢失或损坏如何通过frm&ibd 恢复数据
- 丢失oracle参数文件,数据文件以及控制文件,只有rman备份的恢复
- 丢失数据文件,没有备份,如何启库的解决方法
- WAYOS PPPOE用户数据定时备份并上传到FTP,保证数据不会因为掉配置、挂机等而丢失
- 重装MySQL后如何恢复没有备份的早先数据
- Twitter Storm是如何保证数据不丢失的?
- Mysql数据备份以及异地存储
- 主数据文件损坏(或丢失)情况下,如何备份尾部事务日志.
- Mysql数据同步方案:Percona Xtrabackup备份mysql大数据库(完整备份与增量备份)
- mysql 如何保证数据完整性 -- 笔记
- Mysql ibdata 丢失或损坏如何通过frm&ibd 恢复数据