Centos 7.0 下hadoop集群模式安装(以3个节点为例,master,slave1,slave2)超详细
2017-06-16 09:20
666 查看
一、目标:
构建由3台PC机构成的hadoop环境,安装完成后使用HDFS、Mapreduce、Hbase等完成一些小例子。
二、硬件需求:
3台Centos
7.0 系统PC机,每台PC机4G内存,500G硬盘,双核CPU。
三、软件需求:
每台PC机装有Centos
7.0系统,其中一台namenode,安装系统时命名master;另外两台为datanode,安装系统时分别命名为slave1、slave2。
四、Hadoop集群模式安装过程:
1 修改3台主机上的/etc/hosts,主机名和IP地址分配:master、slave1、slave2。
首先、以root身份在master主机上修改/etc/hosts文件的内容:(注意,修改IP时以3台真实联网的IP为准)
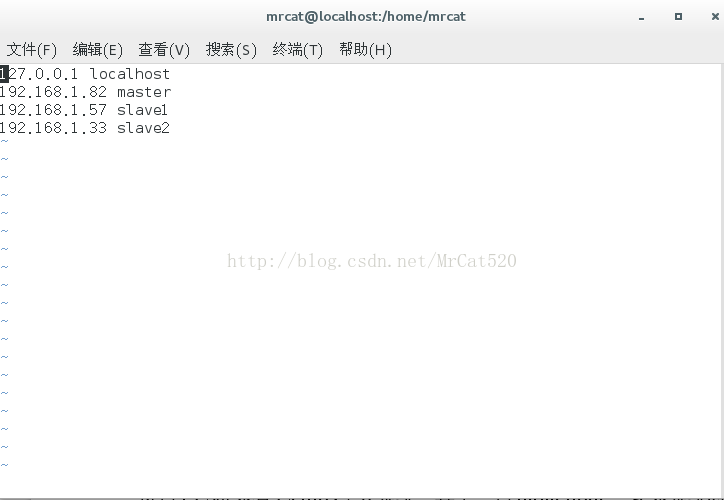
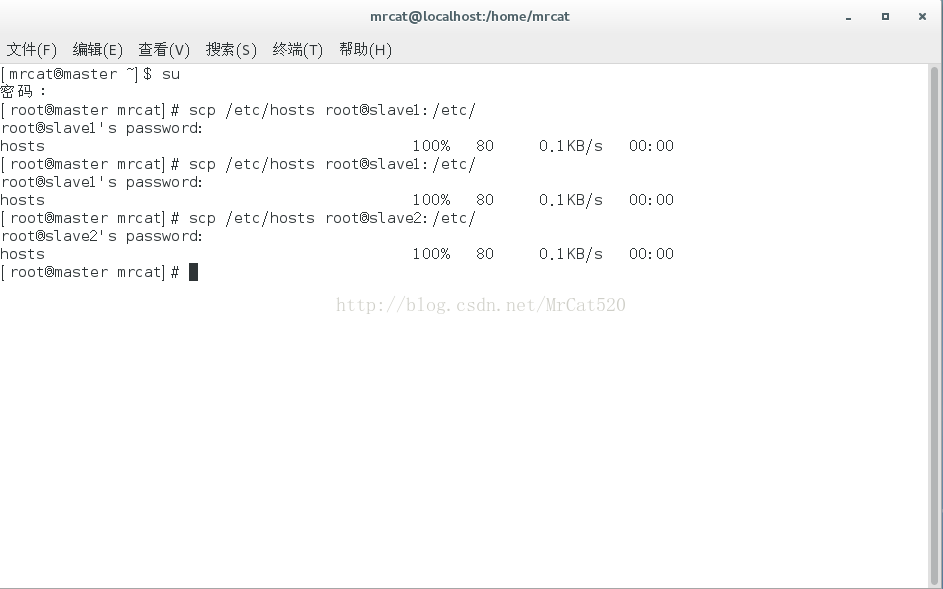
2 将master主机上的/etc/hosts复制到其它2台主机上(复制过程需要输入root认证密码)
3 因为Hadoop集群中所有节点主机上都以hadoop账户安装、配置、加载运行,所以首先需要以root身份在3个节点上创建一个hadoop账户,默认情况下所有主机的/home目录下创建一个hadoop的目录为hadoop账户的宿主目录。
4
设置主机间无密码信任连接:
4.1 在master主机上以hadoop账户身份使用ssh-keygen命令生成master主机hadoop账户密钥对。此时在master节点主机的~/.ssh目录生成密钥对id_rsa和di_rsa.pub,可以通过ls命令列表查看。
4.2 再分别用ssh命令操作slave1、slave2主机生成2台节点的密钥对。
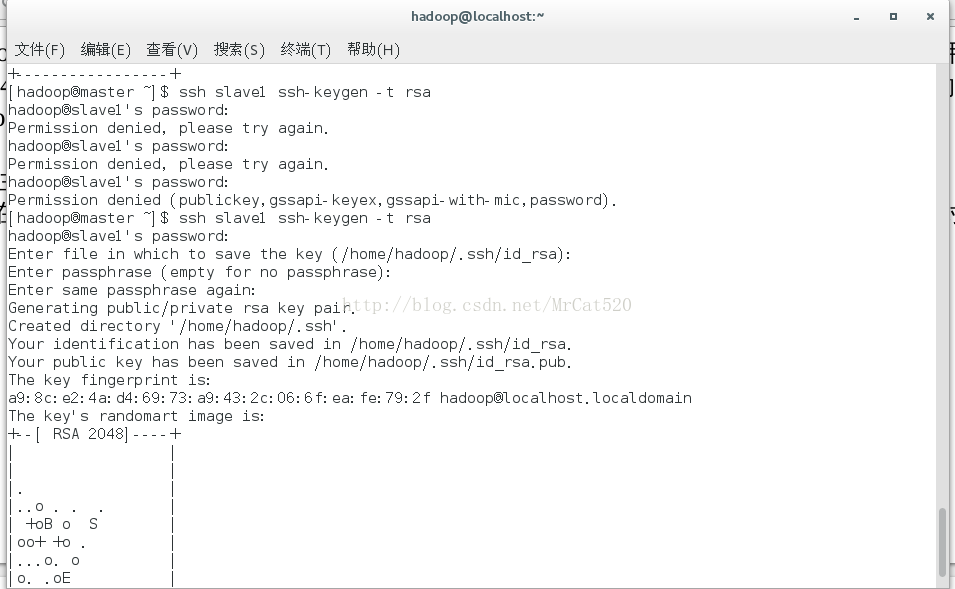
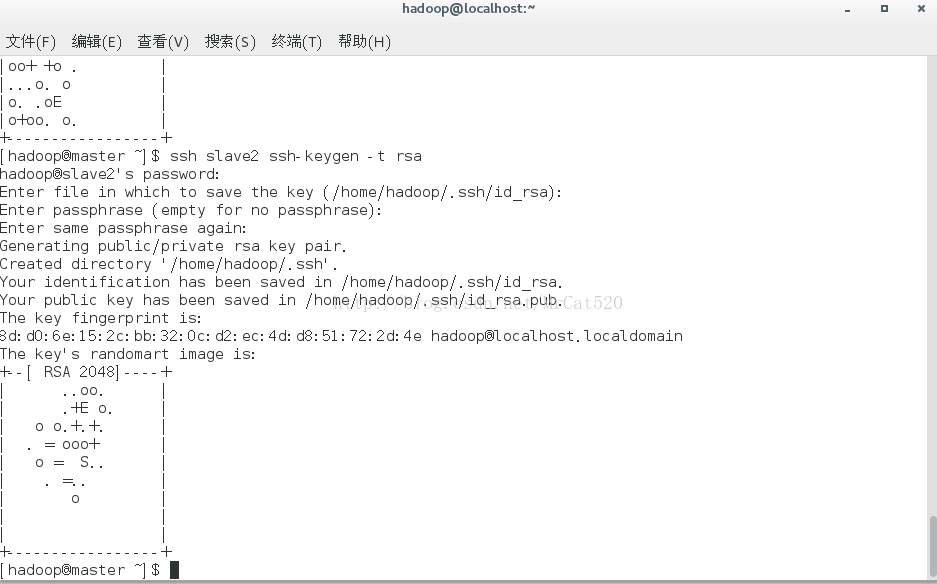
4.3
将刚刚生成的密钥对中的公钥复制到master节点的~/.ssh/目录之下
4.4 将master、slave1、slave2主机的公钥写入master主机~/.ssh目录的认证文件authorized_keys中
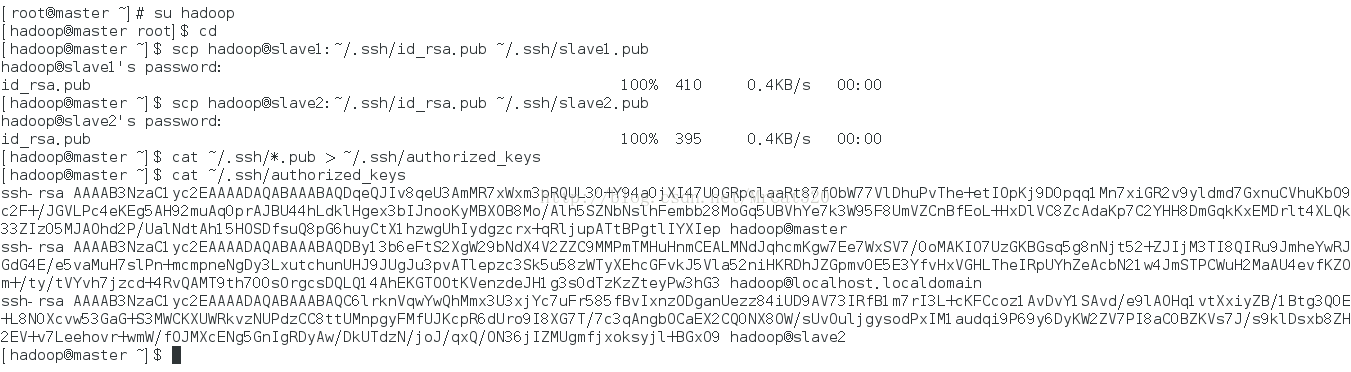
4.5 用chmod命令修改认证文件authorized_keys的属性为600
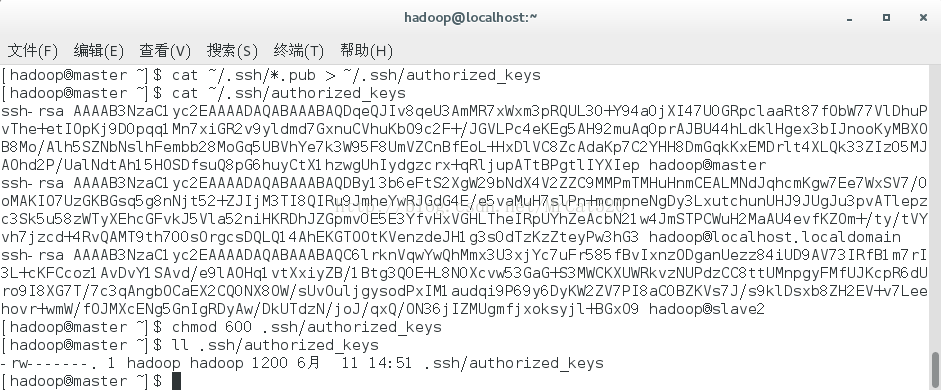
4.6
将~/.ssh/authorized_keys认证文件复制到所有节点主机的~/.ssh/目录中,并进行密码连接测试。
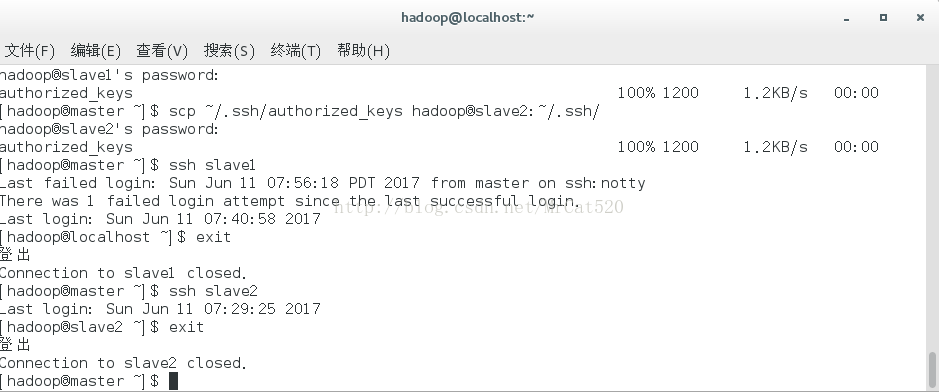
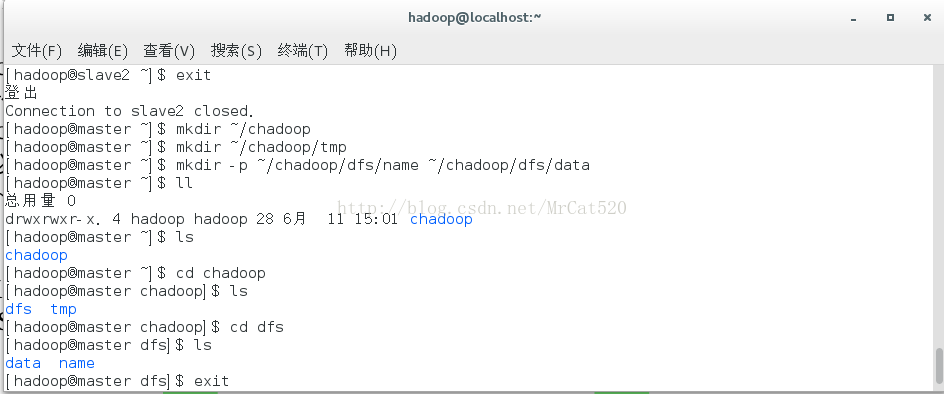
5 hadoop目录结构的创建
5.1 chadoop目录创建:mkdir
~/chadoop
5.2 tmp目录创建:mkdir
~/chadoop/tmp
5.3 dfs目录以及其下name和data目录的创建:mkdir
-p~/chadoop/dfs/name ~/chadoop/dfs/data
6
Java SDK安装与配置
6.1 Java SDK下载(wget http://202.118.69.111/res/jdk-8u121-linux-x64.tar.gz),并对其移动改名。
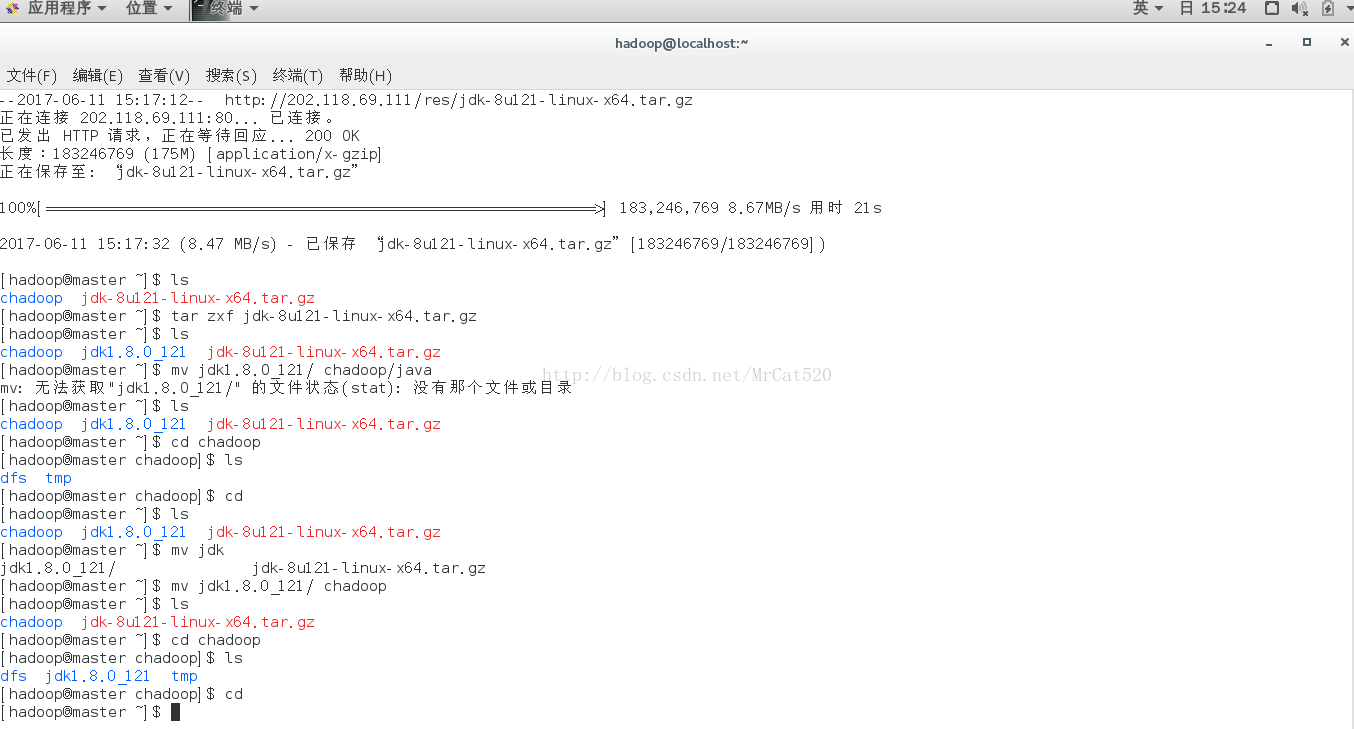
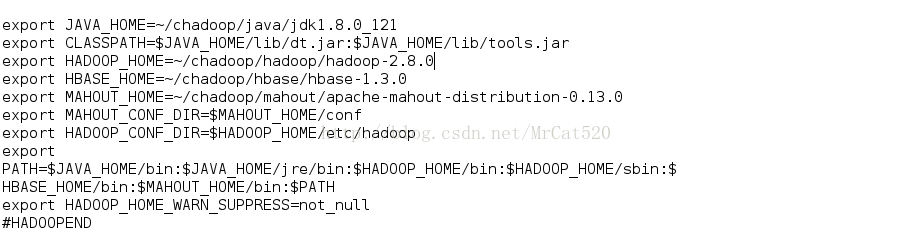
6.2 Java SDK环境变量的设置,将~/.bash_profile加入JAVA——HOME,CLASSPATH和PATH
(配置环境变量命令 vi
~/.bash_profile,配置完后需用命令生效 .
~/.bash_profile)并可用(java-version查看环境变量是否生效)
注意:配置环境变量时一定要填写到安装目录bin之前的目录,否则不会成功。
7 hadoop下载与安装
7.1 hadoop下载解压并移动
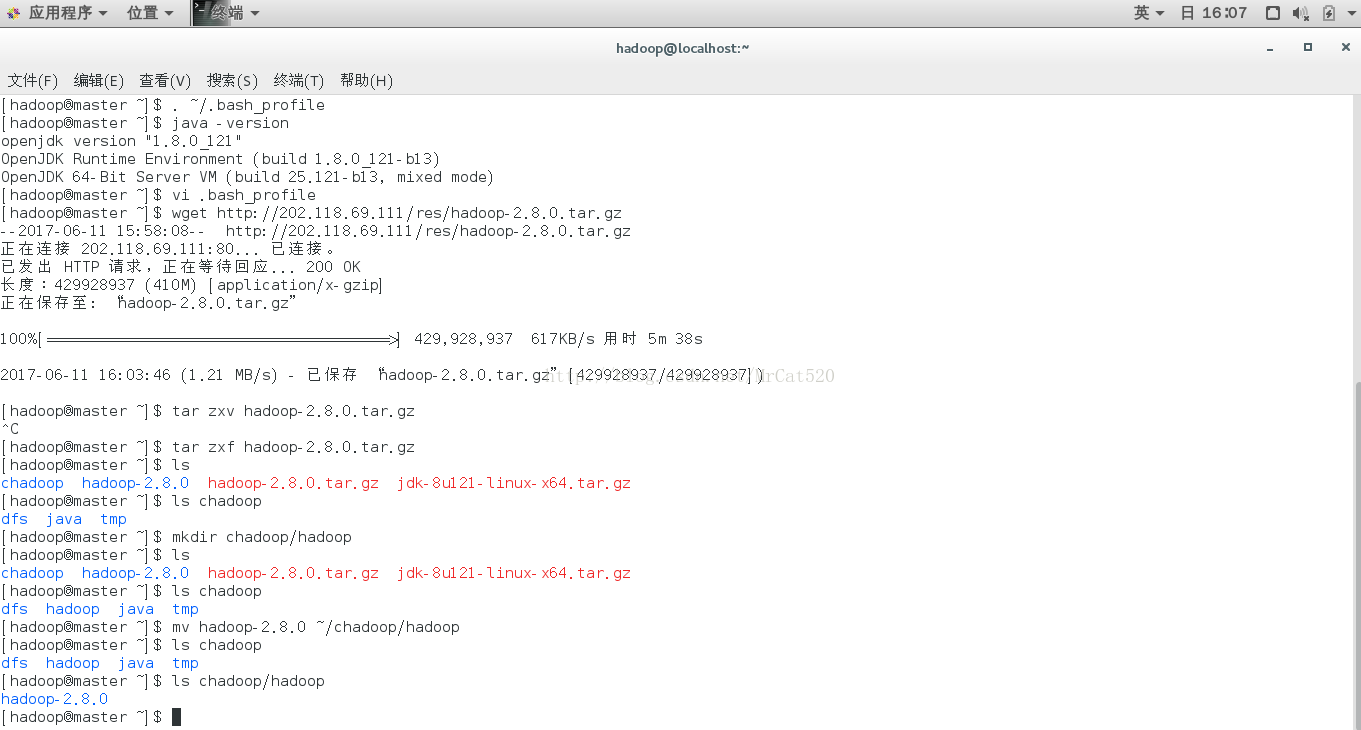
7.2环境变量的配置
(配置环境变量命令 vi~/.bash_profile,配置完后需用命令生效 .
~/.bash_profile)
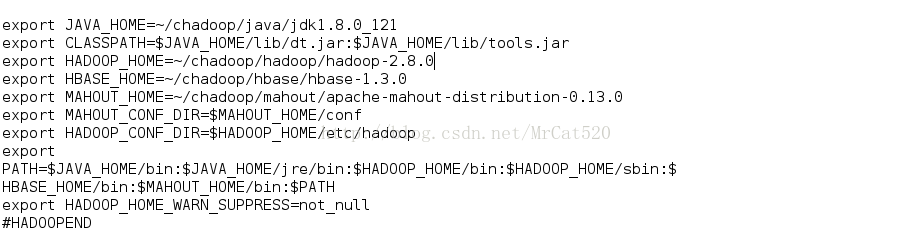
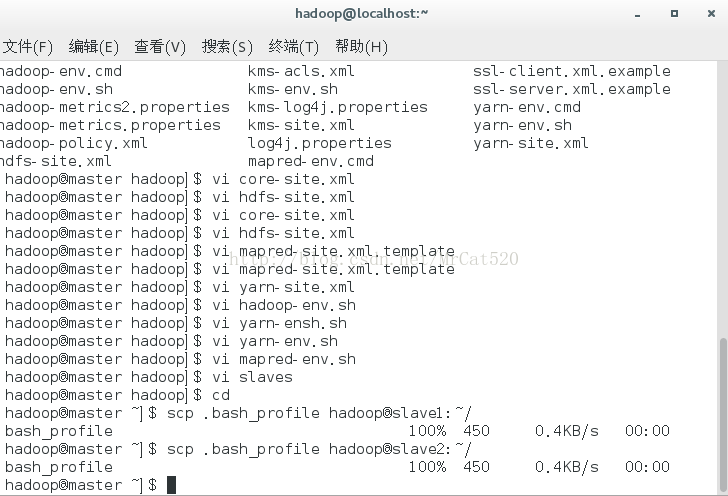
7.3因为时hadoop集群模式,所以我们还要修改~/chadoop/hadoop/hadoop-2.8.0/etc/hadoop目录下的文件(core-site.xml,hdfs-site.xml,
mapred-site.xml, yarn-site.xml,hadoop-env.sh, mapred-env.sh,yarn-env.sh 和
slaves)
core-site.xml
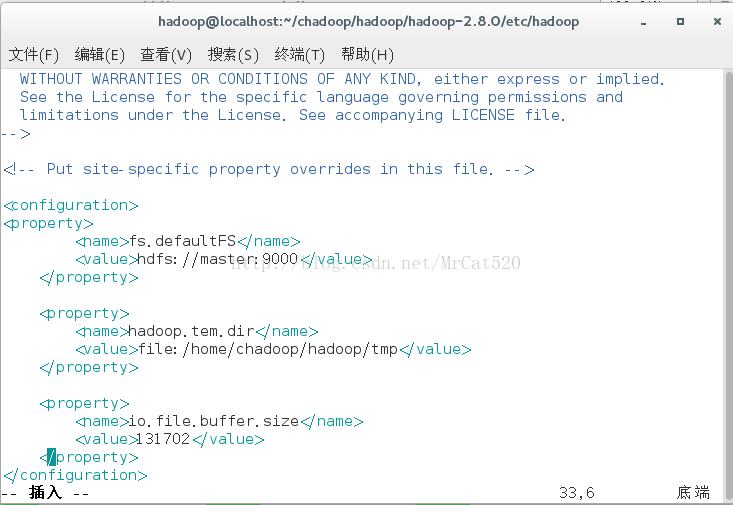
hdfs-site.xml

mapred-site.xml
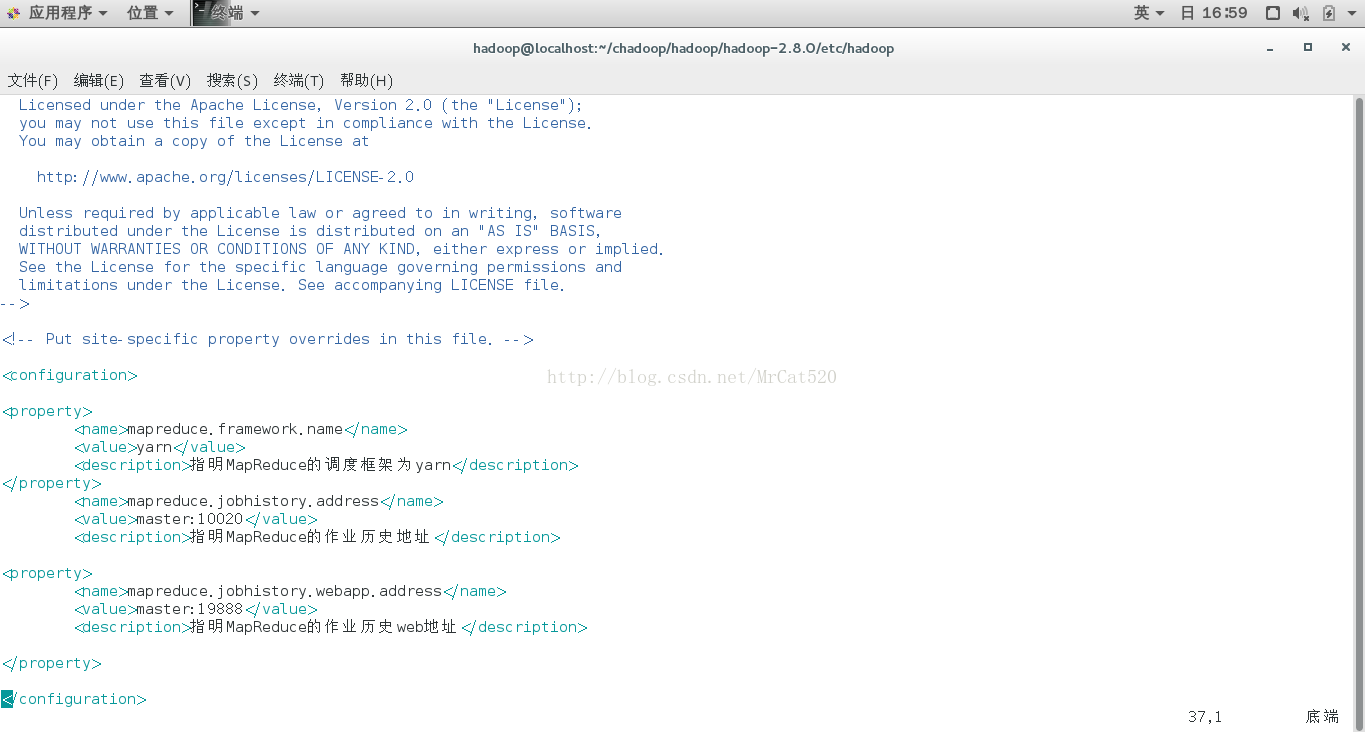
yarn-site.xml
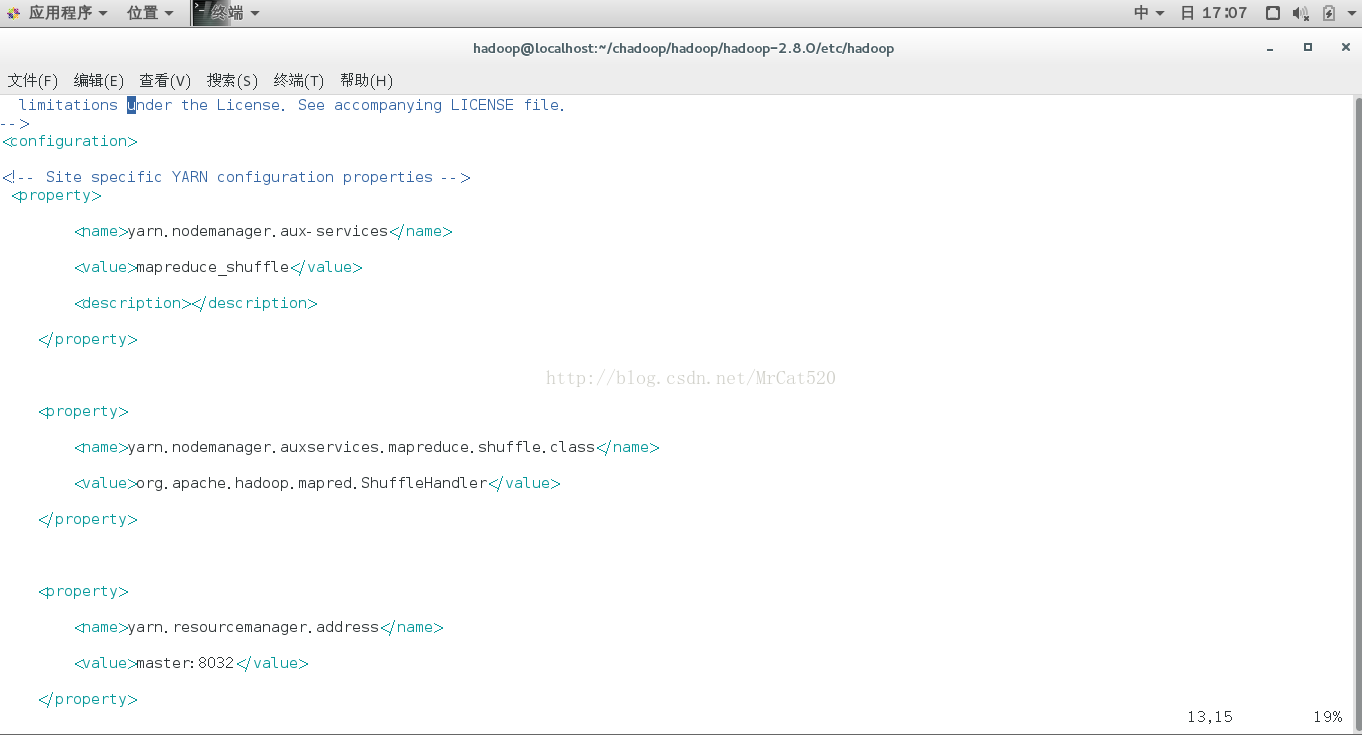
hadoop-env.sh

mapred-env.sh
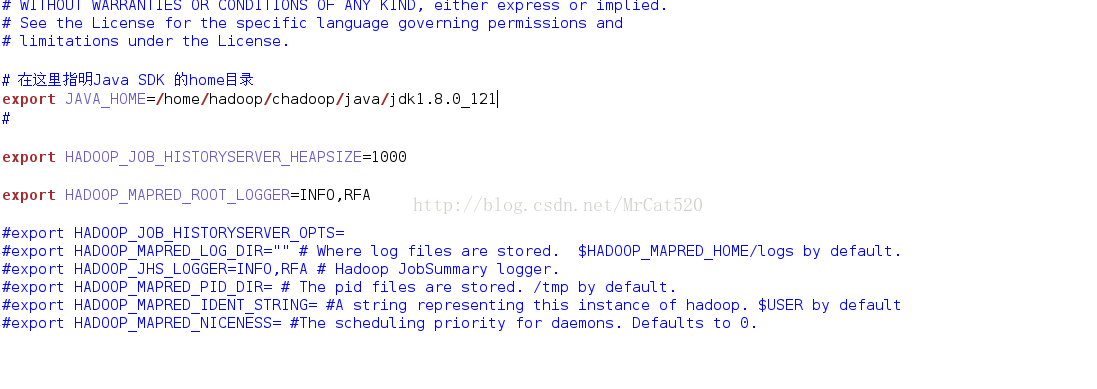
yarn-env.sh

slaves
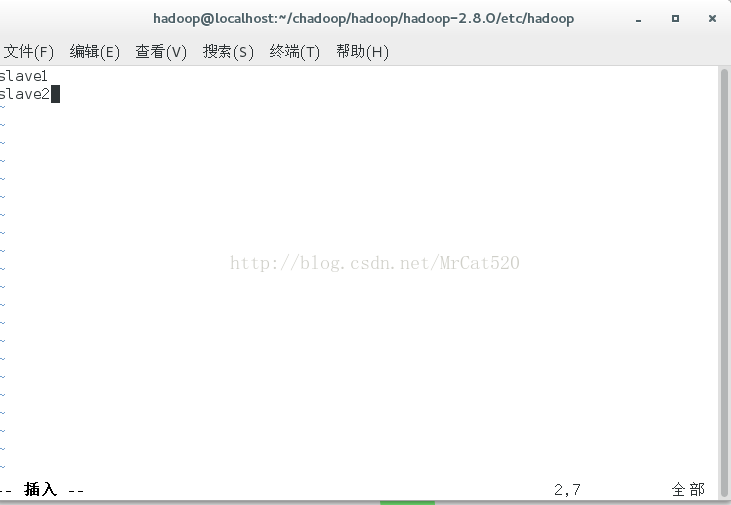
8 master主节点克隆到slave1、slave2节点
8.1克隆“画像”文件
scp ~/.bash_profilehadoop@slave1:~/
scp ~/.bash_profilehadoop@slave2:~/
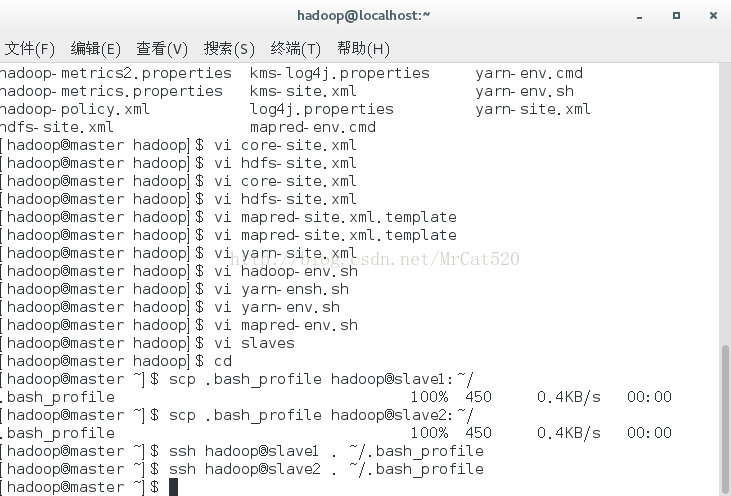
8.2画像文件生效
ssh hadoop@slave1 . ~/.bash_profile
ssh hadoop@slave2 . ~/.bash_profile
8.3 chadoop目录克隆到slave1、slave2
scp -r chadoop/hadoop@slave1:~
scp -r chadoop/hadoop@slave2:~
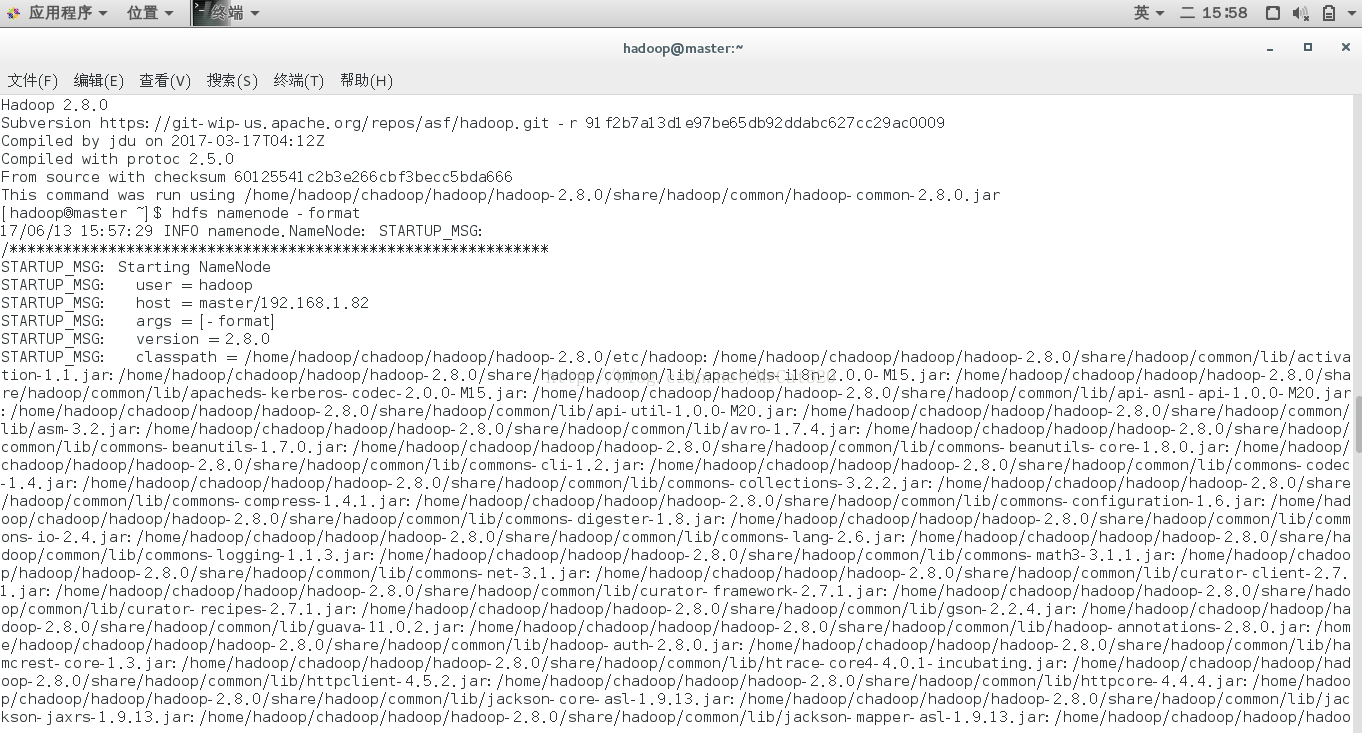
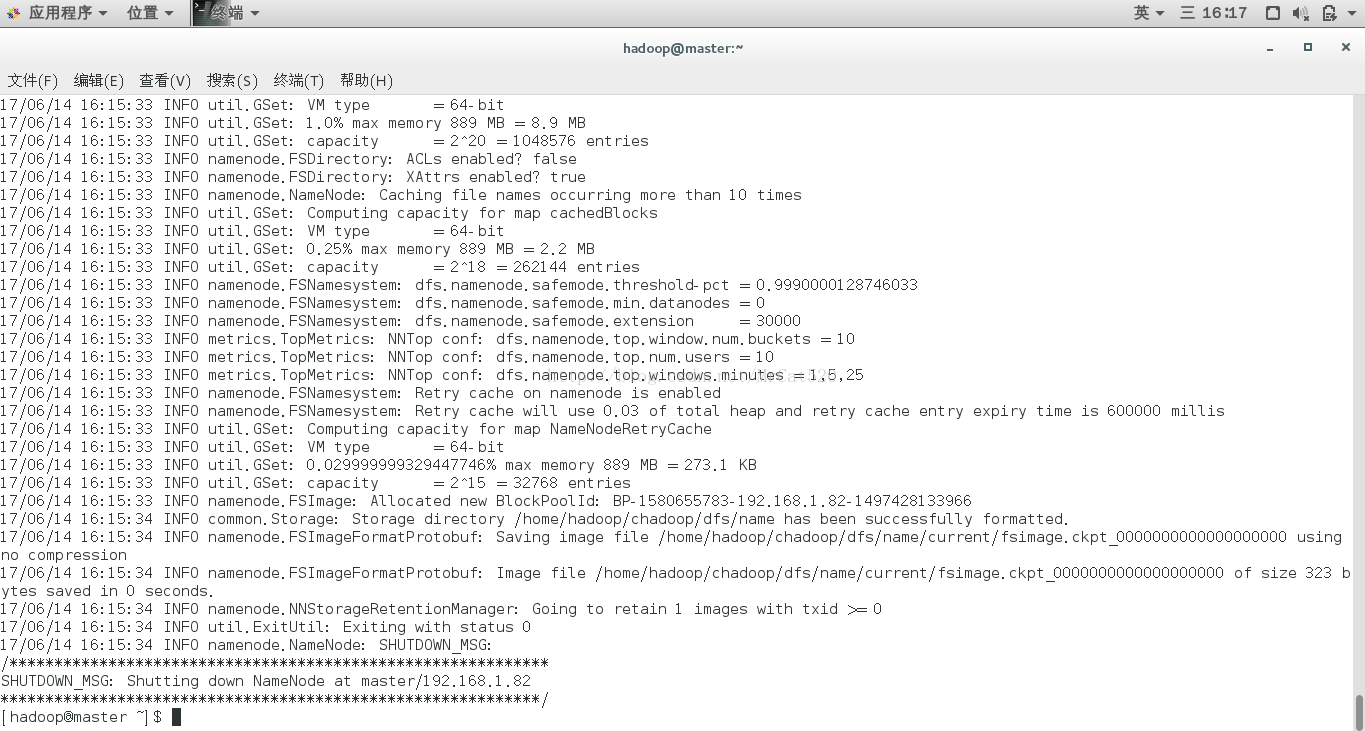
9在master节点主机上格式化hdfs文件系统
9.1 hdfs namenode -format
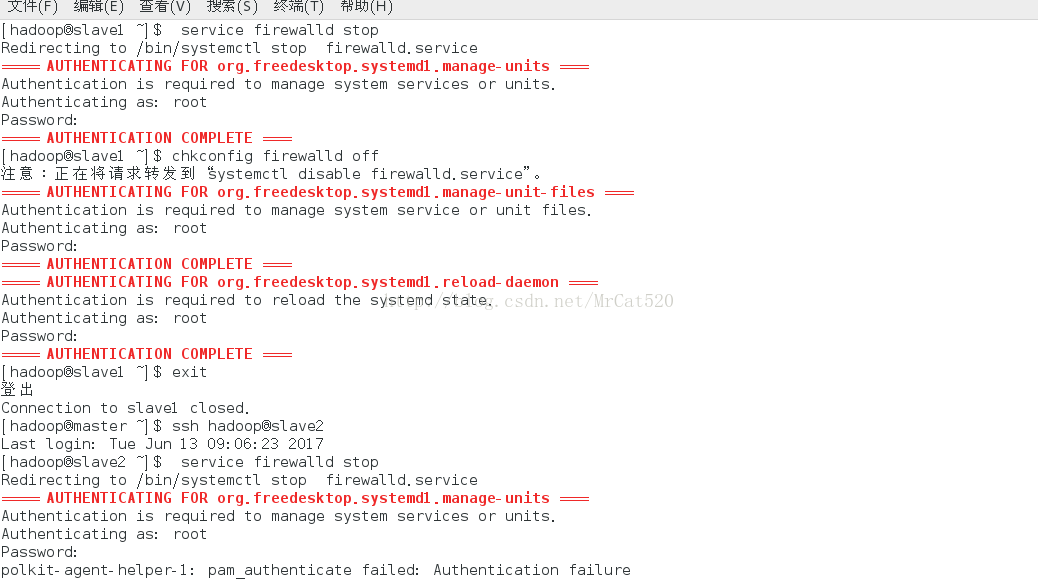
9.2启动hadoop(启动前关闭所有节点主机的防火墙,开放所有端口号)
service firewalld stop(会提示输入root用户密码)
chkconfig firewalld off
(首先关闭主节点,再分别利用ssh命令进入slave1与slave2关闭其余节点防火墙)
9.3 hadoop的启动
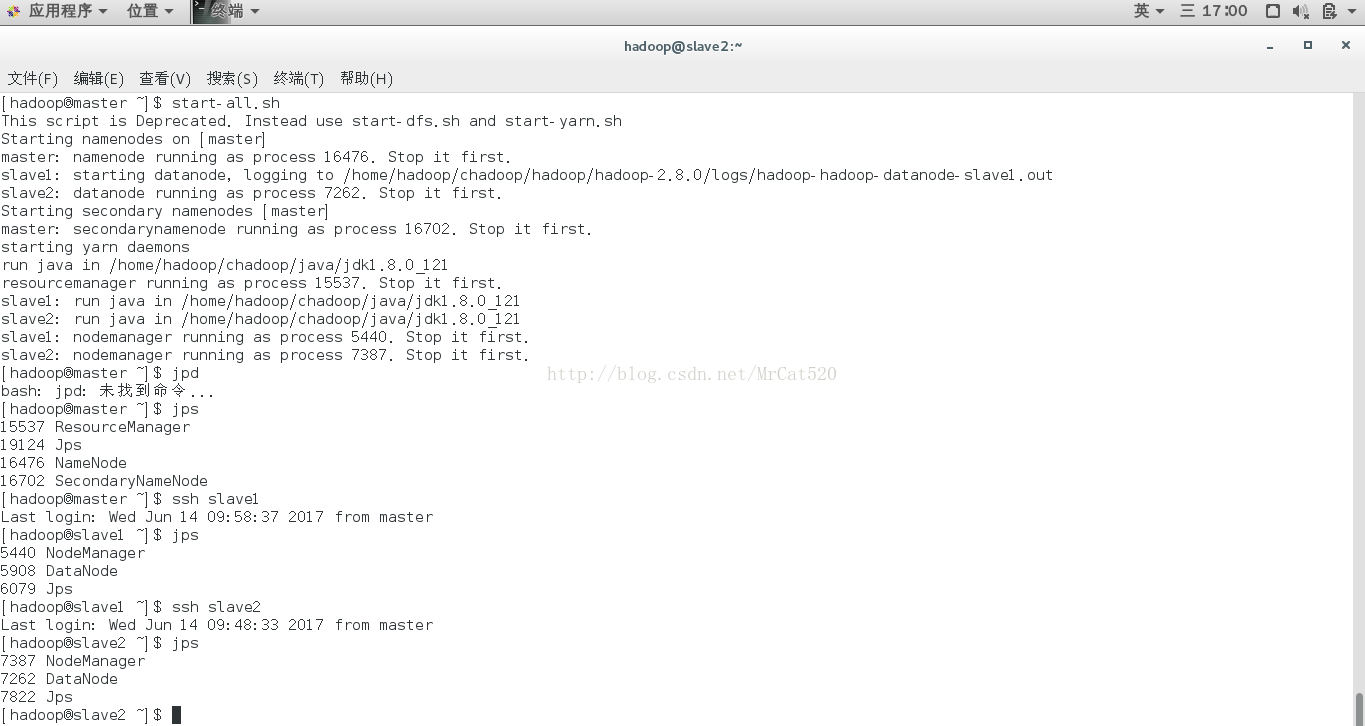
启动命令:start-all.sh
检验hadoop进程:jps(master节点有4个ResourceManager,
Jps, NameNode, SecondaryNamenode,slave1与slave2有3个NodeManager,
DataNode, Jps)
9.4 hadoop的停止
命令:stop-all.sh
10 hadoop的操作
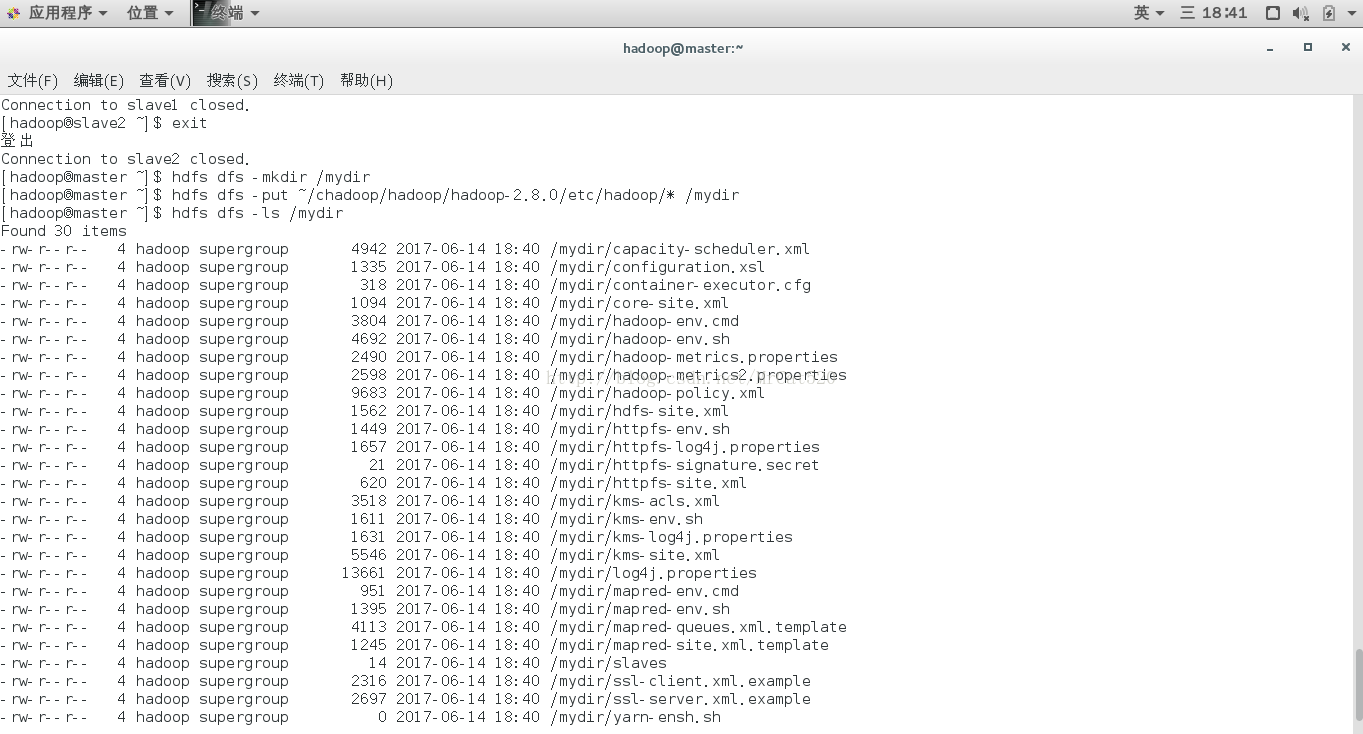
10.1在hdfs文件系统里面操作。首先,用-mkdir命令在hdfs中创建一个mydir目录,然后用-put命令上载文件,步骤如下:
hdfs dfs -mkdir /mydir
hdfs dfs -put ~/chadoop/hadoop/hadoop-2.8.0/etc/hadoop/*/mydir
hdfs dfs -ls /mydir
10.2利用hadoop平台上Mapreduce程序运行(统计所给例子词频)
命令:hadoop jar~/chadoop/hadoop/hadoop-2.8.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.0.jarwordcount
/mydir/* /mydir/output
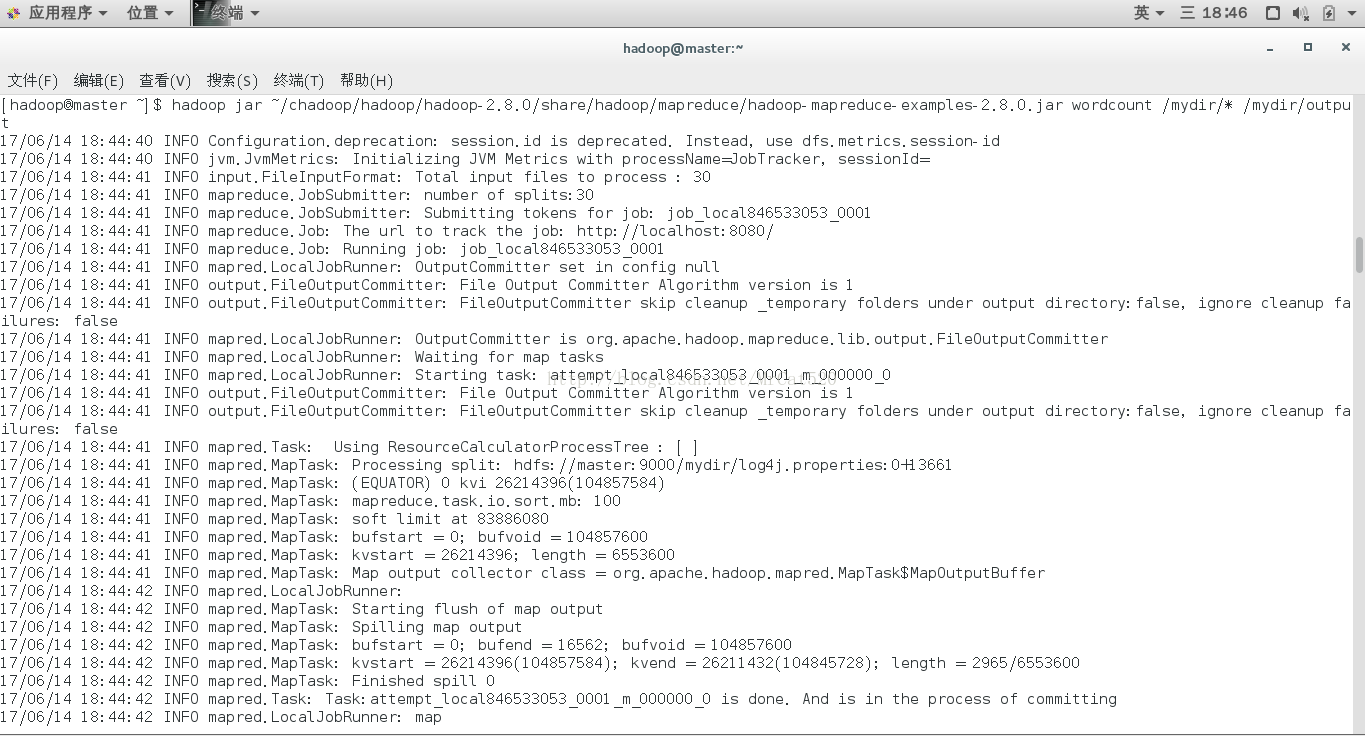
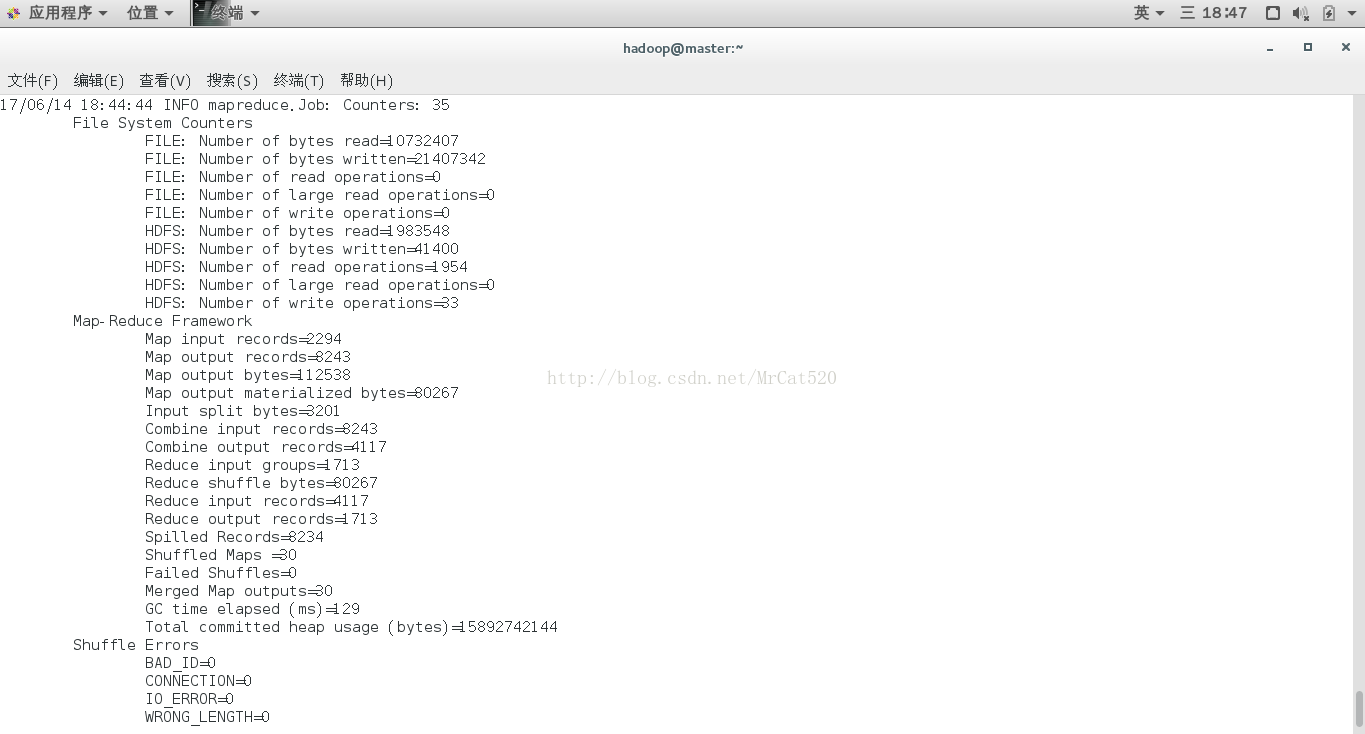
注意:hadoop jar(算法包位置)(例子输入文件夹)(例子结果输出文件夹)
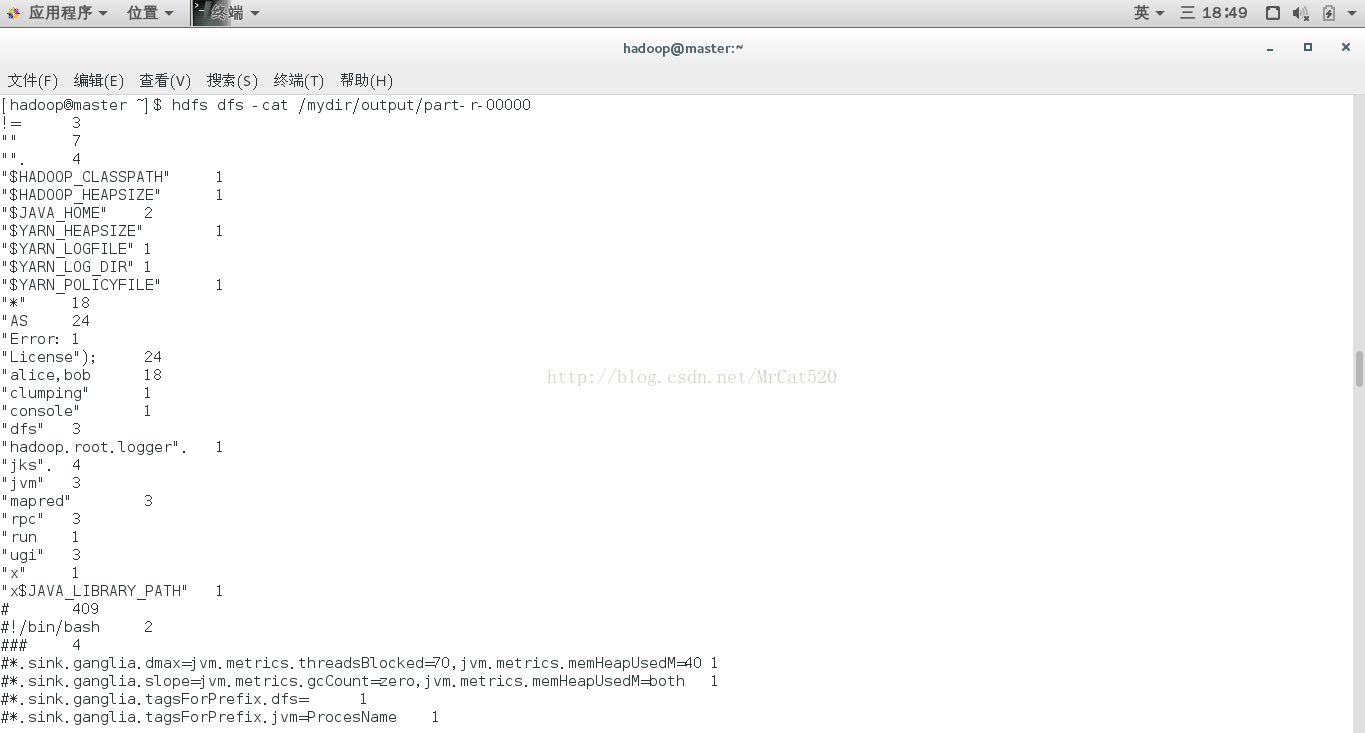
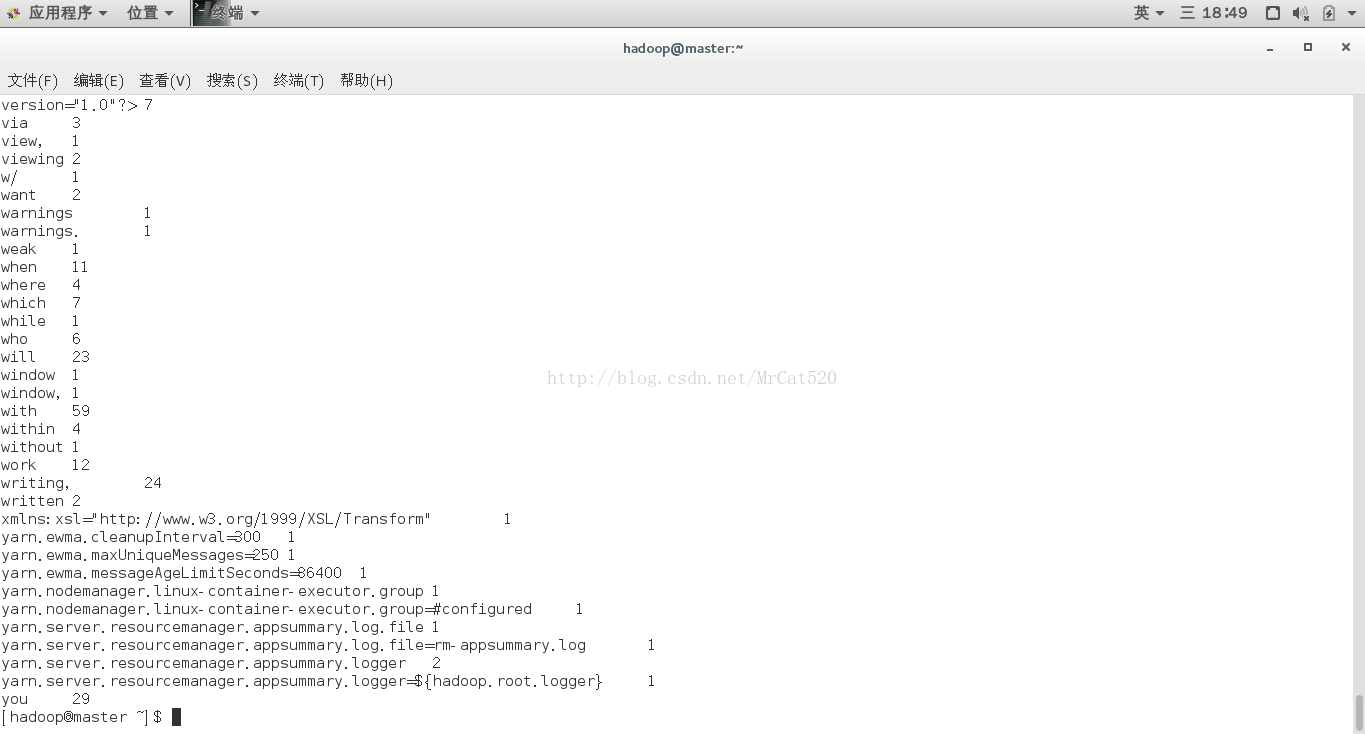
10.3结果查看(hdfs
dfs -cat/mydir/output/part-r-00000)
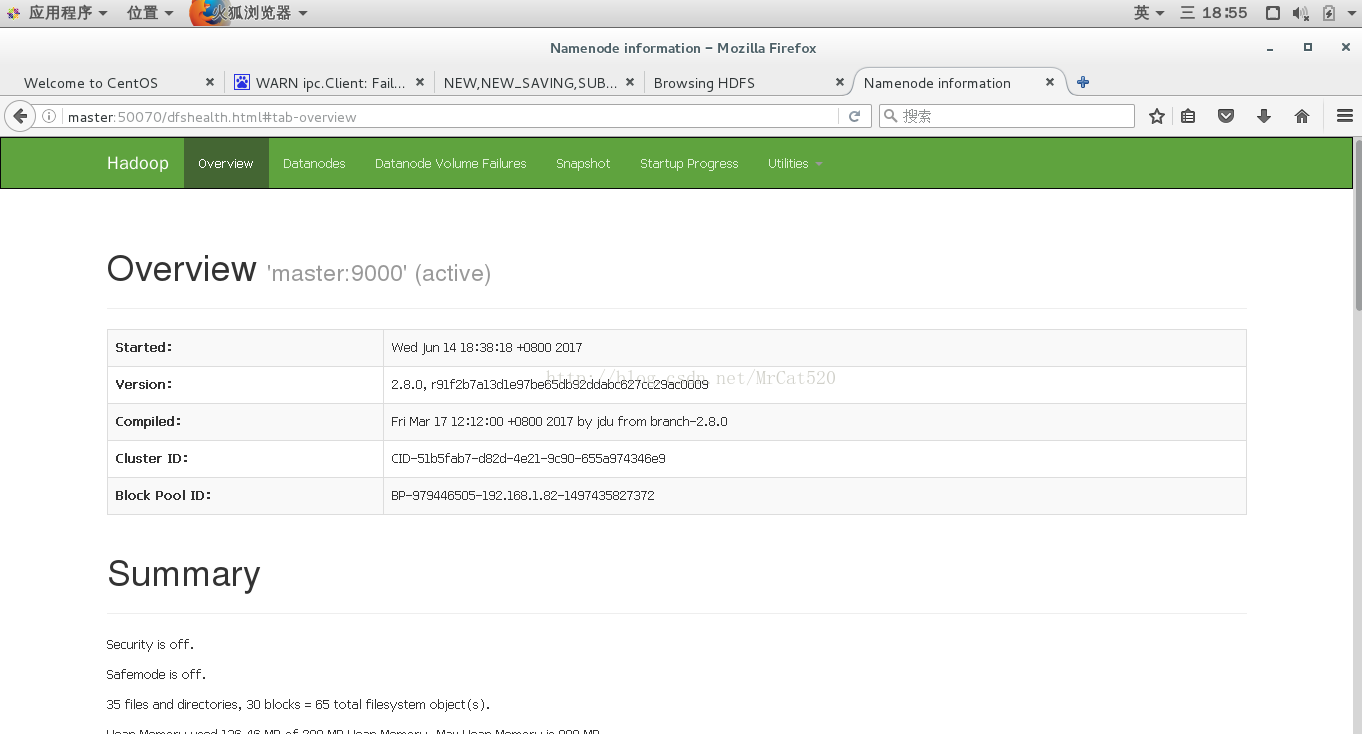
11 hadoop的Web方式查询
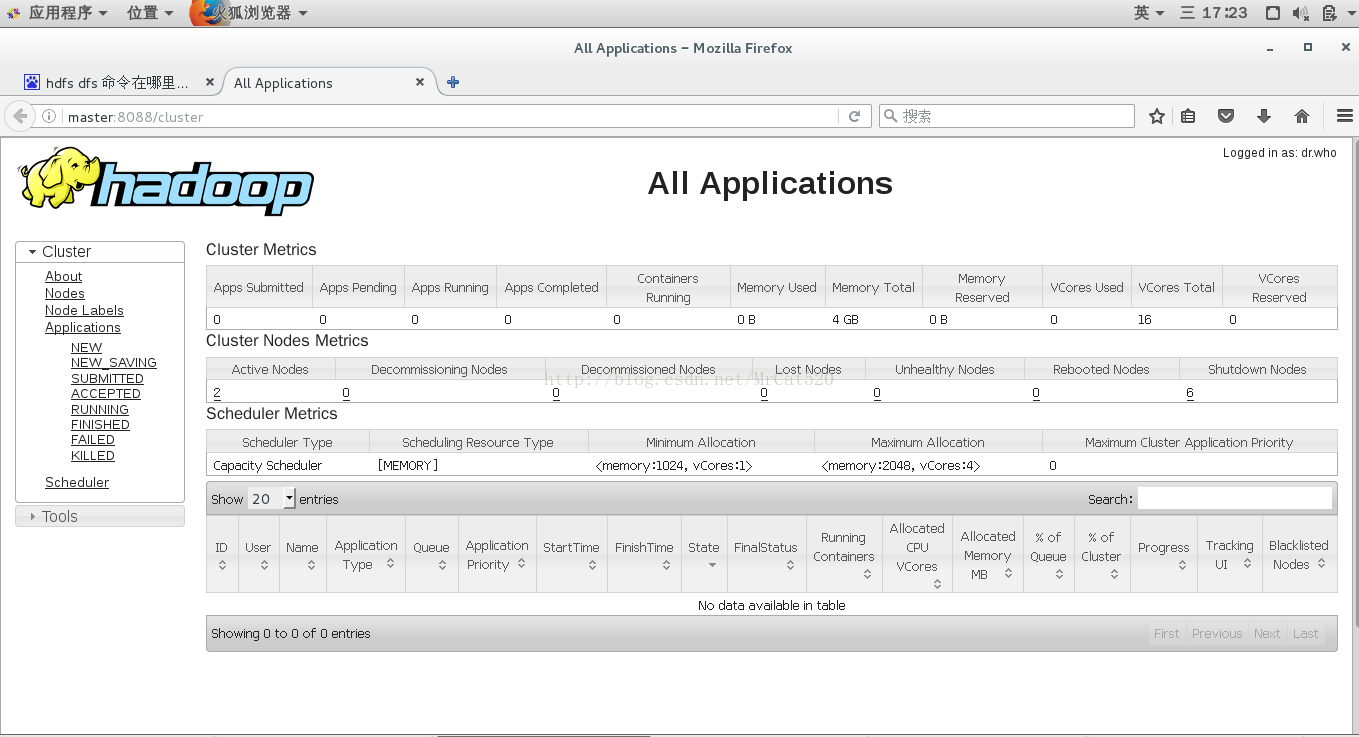
hadoop内置了tomcat应用服务器,安装运行后可以通过浏览器浏览运行
hadoop的hdfs系统的观察端口是50070
应用程序的观察端口是8088
构建由3台PC机构成的hadoop环境,安装完成后使用HDFS、Mapreduce、Hbase等完成一些小例子。
二、硬件需求:
3台Centos
7.0 系统PC机,每台PC机4G内存,500G硬盘,双核CPU。
三、软件需求:
每台PC机装有Centos
7.0系统,其中一台namenode,安装系统时命名master;另外两台为datanode,安装系统时分别命名为slave1、slave2。
四、Hadoop集群模式安装过程:
1 修改3台主机上的/etc/hosts,主机名和IP地址分配:master、slave1、slave2。
首先、以root身份在master主机上修改/etc/hosts文件的内容:(注意,修改IP时以3台真实联网的IP为准)
2 将master主机上的/etc/hosts复制到其它2台主机上(复制过程需要输入root认证密码)
3 因为Hadoop集群中所有节点主机上都以hadoop账户安装、配置、加载运行,所以首先需要以root身份在3个节点上创建一个hadoop账户,默认情况下所有主机的/home目录下创建一个hadoop的目录为hadoop账户的宿主目录。
4
设置主机间无密码信任连接:
4.1 在master主机上以hadoop账户身份使用ssh-keygen命令生成master主机hadoop账户密钥对。此时在master节点主机的~/.ssh目录生成密钥对id_rsa和di_rsa.pub,可以通过ls命令列表查看。
4.2 再分别用ssh命令操作slave1、slave2主机生成2台节点的密钥对。
4.3
将刚刚生成的密钥对中的公钥复制到master节点的~/.ssh/目录之下
4.4 将master、slave1、slave2主机的公钥写入master主机~/.ssh目录的认证文件authorized_keys中
4.5 用chmod命令修改认证文件authorized_keys的属性为600
4.6
将~/.ssh/authorized_keys认证文件复制到所有节点主机的~/.ssh/目录中,并进行密码连接测试。
5 hadoop目录结构的创建
5.1 chadoop目录创建:mkdir
~/chadoop
5.2 tmp目录创建:mkdir
~/chadoop/tmp
5.3 dfs目录以及其下name和data目录的创建:mkdir
-p~/chadoop/dfs/name ~/chadoop/dfs/data
6
Java SDK安装与配置
6.1 Java SDK下载(wget http://202.118.69.111/res/jdk-8u121-linux-x64.tar.gz),并对其移动改名。
6.2 Java SDK环境变量的设置,将~/.bash_profile加入JAVA——HOME,CLASSPATH和PATH
(配置环境变量命令 vi
~/.bash_profile,配置完后需用命令生效 .
~/.bash_profile)并可用(java-version查看环境变量是否生效)
注意:配置环境变量时一定要填写到安装目录bin之前的目录,否则不会成功。
7 hadoop下载与安装
7.1 hadoop下载解压并移动
7.2环境变量的配置
(配置环境变量命令 vi~/.bash_profile,配置完后需用命令生效 .
~/.bash_profile)
7.3因为时hadoop集群模式,所以我们还要修改~/chadoop/hadoop/hadoop-2.8.0/etc/hadoop目录下的文件(core-site.xml,hdfs-site.xml,
mapred-site.xml, yarn-site.xml,hadoop-env.sh, mapred-env.sh,yarn-env.sh 和
slaves)
core-site.xml
hdfs-site.xml
mapred-site.xml
yarn-site.xml
hadoop-env.sh
mapred-env.sh
yarn-env.sh
slaves
8 master主节点克隆到slave1、slave2节点
8.1克隆“画像”文件
scp ~/.bash_profilehadoop@slave1:~/
scp ~/.bash_profilehadoop@slave2:~/
8.2画像文件生效
ssh hadoop@slave1 . ~/.bash_profile
ssh hadoop@slave2 . ~/.bash_profile
8.3 chadoop目录克隆到slave1、slave2
scp -r chadoop/hadoop@slave1:~
scp -r chadoop/hadoop@slave2:~
9在master节点主机上格式化hdfs文件系统
9.1 hdfs namenode -format
9.2启动hadoop(启动前关闭所有节点主机的防火墙,开放所有端口号)
service firewalld stop(会提示输入root用户密码)
chkconfig firewalld off
(首先关闭主节点,再分别利用ssh命令进入slave1与slave2关闭其余节点防火墙)
9.3 hadoop的启动
启动命令:start-all.sh
检验hadoop进程:jps(master节点有4个ResourceManager,
Jps, NameNode, SecondaryNamenode,slave1与slave2有3个NodeManager,
DataNode, Jps)
9.4 hadoop的停止
命令:stop-all.sh
10 hadoop的操作
10.1在hdfs文件系统里面操作。首先,用-mkdir命令在hdfs中创建一个mydir目录,然后用-put命令上载文件,步骤如下:
hdfs dfs -mkdir /mydir
hdfs dfs -put ~/chadoop/hadoop/hadoop-2.8.0/etc/hadoop/*/mydir
hdfs dfs -ls /mydir
10.2利用hadoop平台上Mapreduce程序运行(统计所给例子词频)
命令:hadoop jar~/chadoop/hadoop/hadoop-2.8.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.0.jarwordcount
/mydir/* /mydir/output
注意:hadoop jar(算法包位置)(例子输入文件夹)(例子结果输出文件夹)
10.3结果查看(hdfs
dfs -cat/mydir/output/part-r-00000)
11 hadoop的Web方式查询
hadoop内置了tomcat应用服务器,安装运行后可以通过浏览器浏览运行
hadoop的hdfs系统的观察端口是50070
应用程序的观察端口是8088

相关文章推荐
- Centos 7.0 下hadoop集群模式安装(以3个节点为例,master,slave1,slave2)超详细
- Hadoop 三节点集群安装配置详细实例
- (自总结详细资料)如何在CentOS7下安装hadoop2.8分布式集群
- Centos中Hadoop多节点集群配置 & Zookeeper安装
- Hadoop-2.6.4集群(三个节点)安装(详细图文)
- hadoop 三节点集群安装配置详细实例
- 虚拟机下32位CentOs版本的linux下hadoop2.4.1集群搭建(3个节点版本)
- 完全分布模式hadoop集群安装配置之一安装第一个节点
- 搭建3个节点的hadoop集群(完全分布式部署)--3 zookeeper与hbase安装
- 全网最详细Apache Kylin1.5安装(单节点)和测试案例 ---> 现在看来 kylin 需要 安装到Hadoop Master 节点上
- Centos中安装配置local/standalone模式和伪分布式模式hadoop集群
- MySQL数据库集群Master-Slave模式安装摘要
- 完全分布模式hadoop集群安装配置之二 添加新节点组成分布式集群
- 搭建3个节点的hadoop集群(完全分布式部署)--2安装mysql及hive
- Centos 6.4安装bind 9.8.2 master、slave相关详细配置 part1
- MySQL数据库集群Master-Slave模式安装摘要
- Mysql集群安装部署,Slave-Mater-Master-Slave模式
- 搭建3个节点的hadoop集群(完全分布式部署)5 flume安装及flume导数据到hdfs
- Spark standalone模式的安装(spark-1.6.1-bin-hadoop2.6.tgz)(master、slave1和slave2)
- 完全分布模式hadoop集群安装配置之二 添加新节点组成分布式集群