消息队列说明(阿里开源消息中间件Rocketmq)
2017-06-15 00:00
239 查看
1.topic如何做到系统间隔离?
通过topic命名规范控制2.消息如何确定被成功消费了?
消息的处理逻辑会做异常处理,如果消费失败会被捕获到,这时我们可以在catch中做一些处理通用的做法是重试两三次以后返回消费成功,并记录日志并持久化该消息如下图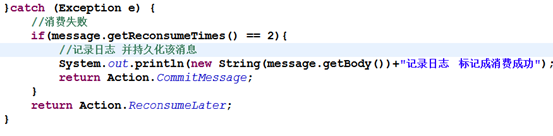
重试两三次以后返回消费成功的原因:如果不人工干预框架会永无休止的进行重试,这样对性能是一大影响。
备注:
消息消费会返回消费状态(CONSUME_SUCCESS和RECONSUME_LATER),如果返回CONSUME_SUCCESS会继续消费,如果返回RECONSUME_LATER则会自动重试。下图为重试次数以及每次重试间隔的时间。
| 第几次重试 | 每次重试间隔时间 |
| 1 | 10秒 |
| 2 | 10秒 |
| 3 | 1分钟 |
| 4 | 2分钟 |
| 5 | 3分钟 |
| 6 | 4分钟 |
| ... | ... |
3.如何实现一个消息被多次订阅消费?
3.1实现方式:
在配置文件中需要配置多个Consumer(其实是指定了不同的分组);3.2原理:
下图是不同消费者分组的消费情况(分组A跟分组B都能拿到队列中的全量数据)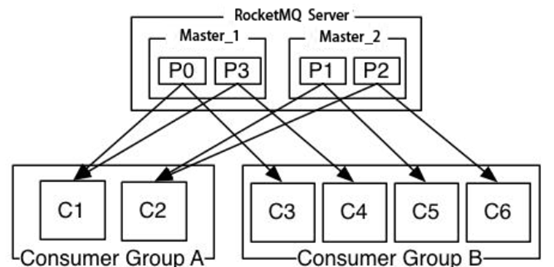
4.消费端程序断开后重连如何保证从断开节点开始消费?
由框架实现保证从断开节点开始消费,原理如下:拉取消息之前会先读取本地偏移量,读到偏移量后会去Broker拿取相应的数据,在消费的同时会更新本地的偏移量,为下次去Broker拉取数据做准备。
5.消息滞留的最长等待时间是多久,超时后如何处理?
默认超时时间是三天,超时后broker会删除三天之前的数据,在删除数据之前会监控到堆积的数据,处理方法参考 6.26.消息积压后是否有预警提示,如何应对?
有监控应对:
6.1集群支持横向扩展,增加broker数量
6.2适当增大并发数
6.2.1增加ConsumerGroup中的consumer实例
可以通过增加机器,或者在已有的机器启动多个进程的方式6.2.2提高单个Consumer的消费并行线程
6.3 批量方式消费
某些业务流程如果支持批量方式消费,则可以很大程度上提高消费吞吐量,例如订单扣款类应用,一次处理一个订单耗时1秒中,一次处理10个订单可能也只耗时2秒,这样即可大幅度提高消费的吞吐量6.4 跳过非重要消息
发生消息堆积时,如果消费速度一直追不上发送速度,可以选择丢弃不重要的消息6.5 优化每条消息消费过程
7.如果消息框架服务器宕机多久能够恢复,会丢失多少数据
数据的可靠性与发送方式和集群部署方式密切相关7.1消息的发送模式
7.1.1可靠同步发送
Producer的send方法本身支持内部重试,重试逻辑如下:1.至多重试3次
2.如果发送失败,则轮转到下一个Broker。
3.这个方法的总耗时时间不超过sendMsgTimeout设置的值,默认10s。
以上策略仍然不能保证消息一定发送成功,为保证消息一定成功,建议应用这样做
如果调用send同步方法发送失败,则尝试将消息存储到db,由后台线程定时重试,保证消息一定到达Broker。
上述db重试方式为什么没有集成到Mq客户端内部做,而是要求应用自己去完成,我们基于以下几点考虑
1.MQ的客户端设计为无状态模式,方便任意的水平扩展,而且对机器资源的消耗仅仅是cpu,内存,网络
2.如果MQ客户端内部集成一个kv存储模块,那么数据只有同步落盘才能可靠,而同步落盘本身性能开销交大,所以通常会采用异步落盘,又由于应用关闭过程不受MQ运维人员控制,可能会发生kill -9 这样暴力方式关闭,造成数据没有及时落盘而丢失。
3.Producer所在机器的可靠性比较低,一般为虚拟机,不适合存储重要数据。
综上,建议重试过程由应用来控制。
7.1.2 Oneway方式发送
一个RPC调用,通常是这样一个过程1.客户端发送请求到服务器
2.服务器处理该请求
3.服务器向客户端返回应答
一个RPC的耗时时间是上述三个步骤的总和,某些场景要求耗时非常短,但是对可靠性要求并不高,例如日志收集类应用,此类应用可以采用oneway方式调用,只发送请求不等待应答。
7.2 RocketMQ推荐了三种不同的broker集群部署方式
7.2.1多Master模式
一个集群无Slave,全是Master,例如2个Master或3个Master优点:配置简单,单个Master宕机或重启对应用无影响,在磁盘配置为RAID10时。即使机器宕机不可恢复情况下,由于RAID10磁盘非常可靠,消息也不会丢失(异步刷盘丢失少量消息,同步刷盘一条不丢)。性能最高。
缺点:单台机器宕机期间,这台机器上未被消费的消息在机器恢复之前不可订阅,消息实时性会受到影响。
7.2.2多Master多Slave模式,异步复制
每个Master配置一个Slave,有多对Master-Slave,HA采用异步复制方式,主备有短暂消息延迟,毫秒级。优点:即使磁盘损坏,消息丢失的非常少,且消息实时性不会受影响,因为Master宕机后,消费者仍然可以从Slave消费,此过程对应用透明。不需人工干预,性能同Master模式几乎一样。
缺点:Master宕机,磁盘损坏情况,会丢失少量消息。
7.2.3多Master多Slave模式,同步双写
每个Master配置一个Slave,有多对Master-Slaver,HA采用同步双写方式,主备都写成功,向应用返回成功。优点:数据与服务都无单点,Master宕机情况下,消息无延迟,服务可用性与数据可用性都非常高
缺点:性能比异步复制模式略低,大约低10%左右,发送单个消息的RT会略高。
8.消费者在消费消息时最慢要在多长时间内处理完成
从服务端拉取消息的超时时间可配,具体处理完成需要多长时间要看业务代码的复杂程度9.消息框架能否实现顺序消费,对性能是否有影响
框架提供了顺序消费的模式,需要注意的是如果框架保证了消息的顺序消费那么就意味着要牺牲框架的性能。10.消息框架是否支持横向扩容
支持11.消息框架能否支持在线监控
支持12.消息框架如果出现性能问题,如何确定是哪个系统引起的问题
框架包括发送系统,接收系统,消息存储系统,通用的办法是监控消息队列的IO性能状态,网络通信信息,网卡的使用情况等。如果io性能瓶颈基本确定是存储系统性能,如果是网络框架后期会跟进消息的运行轨迹。13.topic数据量和tag数据是否有限制
软件层面是没限制的,硬件层面有限制,具体看服务器资源(cpu,内存,硬盘)
相关文章推荐
- 阿里开源消息中间件RocketMQ的前世今生-转自阿里中间件
- 阿里开源消息中间件MetaQ(RocketMQ)简介
- 阿里消息队列中间件 RocketMQ 源码分析 —— Message 拉取与消费(上)
- 一个C#写的开源分布式消息队列(类RocketMQ)
- Kafka、RabbitMQ、RocketMQ消息中间件的对比 —— 消息发送性能-转自阿里中间件
- RocketMQ:一个纯java的开源消息中间件--开发测试环境搭建
- RocketMQ:一个纯java的开源消息中间件--开发测试环境搭建
- Kafka、RabbitMQ、RocketMQ消息中间件的对比 —— 消息发送性能-转自阿里中间件
- 【linux】RocketMQ:一个纯java的开源消息中间件--开发测试环境搭建
- Kafka、RabbitMQ、RocketMQ消息中间件的对比 —— 消息发送性能-转自阿里中间件
- Kafka、RabbitMQ、RocketMQ消息中间件的对比 —— 消息发送性能 (阿里中间件团队博客)
- 启动RocketMQ消息队列的中间件Broker的时候报错
- 阿里云消息队列 RocketMQ-常见使用方式说明-消息重试
- 转:Kafka、RabbitMQ、RocketMQ消息中间件的对比 —— 消息发送性能 (阿里中间件团队博客)
- RocketMQ:一个纯java的开源消息中间件--开发测试环境搭建
- 基于条件变量的消息队列 说明介绍
- C#之消息队列的简要说明----自学笔记
- 开源稳定的消息队列 RabbitMQ
- RabbitMQ开源企业级消息队列系统实现方案(单机版)
- 浅议消息中间件技术标准与开源实现