Mysql 并发引起的死锁问题(INSERT ... ON DUPLICATE KEY UPDATE 死锁)
2017-06-14 19:05
141 查看
背景:
平台的某个数据库上面有近千个连接,每个连接对应一个爬虫,爬虫将爬来的数据放到cdb里供后期分析查询使用。前段时间经常出现cdb查询缓慢,cpu占有率高的现象。通过show
processlist后发现,大量的连接卡在了执行INSERT ... ON DUPLICATE KEY UPDATE这样的语句上面。难道并发执行INSERT ... ON DUPLICATE KEY UPDATE会导致cpu负荷直线上升吗,下面我们做一个实验。
实验:
先创建一张表TestA:
再编写一个压测测试脚本,分别在并发为1、2、5、10,20,50,100,125,200的情况下测试执行1000次 INSERT INTO
(1,1) ON DUPLICATE KEY UPDATE num=num+1语句。
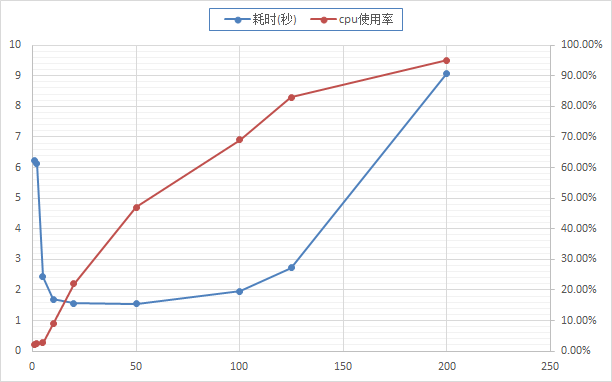
运行结果如下图,随着并发数的增加执行sql语句耗时呈现先下降后增加的趋势,与之相对应的是cpu使用率随着并发数增加不断增加。可以看出,当并发数大于一定125的时候,系统发生了雪崩,性能急剧下降。而在图上没有标出来的是,当并发数大于200的时候,mysql直接返回了Deadlock found when trying to get lock; try restarting transaction错误,已经无法正常执行语句了。
分析:
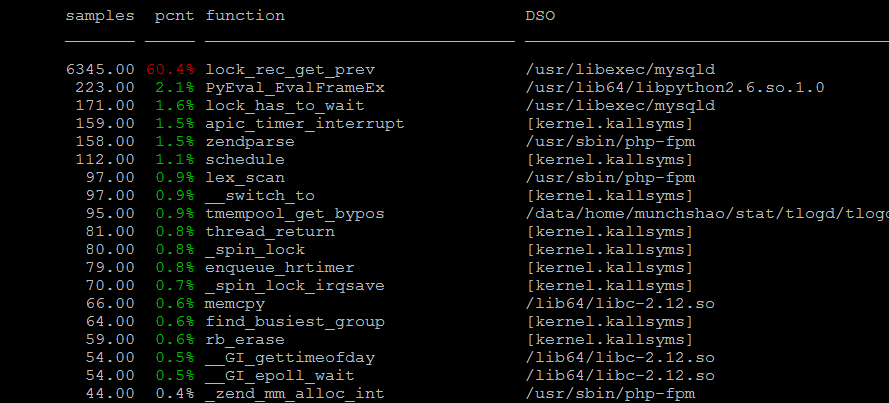
通过perf来分析造成上述雪崩的原因,发现是卡在了lock_rec_get_prev函数上面。
INSERT INTO
解决方案:
其实最好的解决方案就是不要将这些爬虫直接连到mysql上面,通过一个中间层维护一个mysql的连接池,这样既能满足实际业务需求,也不会造成死锁。当然对于这个具体场景也是有简单的优化方案的。造成死锁的原因是大量连接对行锁进行争夺。既然这个行锁是性能瓶颈,那我们可以通过增加行锁来减少争夺的成本。
我们稍微改造一下表结构,添加一个联合主键(id、thread_id),每个连接都执行 INSERT INTO
ON DUPLICATE KEY UPDATE num=num+1。这样每个连接都有了属于自己的行锁,不会互相争夺而产生死锁了。最后只需要执行一下sum就可以获取最终结果了。
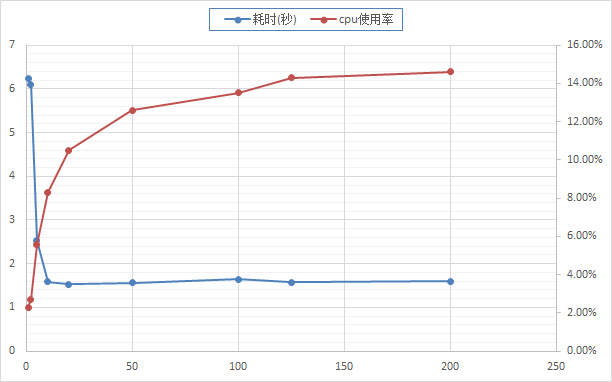
压测测试结果如图,随着连接数的增加,耗时减少至稳定,cpu使用率增加至稳定。
原文: https://www.qcloud.com/community/article/752832
平台的某个数据库上面有近千个连接,每个连接对应一个爬虫,爬虫将爬来的数据放到cdb里供后期分析查询使用。前段时间经常出现cdb查询缓慢,cpu占有率高的现象。通过show
processlist后发现,大量的连接卡在了执行INSERT ... ON DUPLICATE KEY UPDATE这样的语句上面。难道并发执行INSERT ... ON DUPLICATE KEY UPDATE会导致cpu负荷直线上升吗,下面我们做一个实验。
实验:
先创建一张表TestA:
CREATE TABLE `TestA` ( `id` int(11) NOT NULL, `num` int(1) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
再编写一个压测测试脚本,分别在并发为1、2、5、10,20,50,100,125,200的情况下测试执行1000次 INSERT INTO
TestAVALUES
(1,1) ON DUPLICATE KEY UPDATE num=num+1语句。
import gevent,time from gevent import monkey gevent.monkey.patch_socket() import pymysql total=1000 def TestSql(num): start=time.time() def goodquery(sql,i): db = pymysql.connect(host = 'localhost', user = 'root',passwd='root', db= 'test',autocommit=True) cursor = db.cursor() cnt=total/num sql=sql.format(thread_id=i) for i in xrange(cnt): cursor.execute(sql) cursor.close() db.close() sql='INSERT INTO `TestA` VALUES (1,1) ON DUPLICATE KEY UPDATE num=num+1;' jobs = [gevent.spawn(goodquery, sql,i) for i in range(num)] gevent.joinall(jobs) res= time.time()-start return res sample=[1,2,5,10,20,50,100,125,200] x=[TestSql(x) for x in sample] print x
运行结果如下图,随着并发数的增加执行sql语句耗时呈现先下降后增加的趋势,与之相对应的是cpu使用率随着并发数增加不断增加。可以看出,当并发数大于一定125的时候,系统发生了雪崩,性能急剧下降。而在图上没有标出来的是,当并发数大于200的时候,mysql直接返回了Deadlock found when trying to get lock; try restarting transaction错误,已经无法正常执行语句了。
分析:
通过perf来分析造成上述雪崩的原因,发现是卡在了lock_rec_get_prev函数上面。
INSERT INTO
TestAVALUES (1,1) ON DUPLICATE KEY UPDATE num=num+1 这个语句先在表TestA中找到是否存在id=1的行,因为id是主键,所以很快就定位到这一行上面。接下来需要执行update操作,在执行update之前需要获取该行的X锁。由于大量的连接都在执行这个操作,因此在抢夺行锁上产生了大量的竞争,因为行锁的分配也涉及了自旋锁。很多连接就卡在了自旋锁上面,白白的消耗了cpu资源。
解决方案:
其实最好的解决方案就是不要将这些爬虫直接连到mysql上面,通过一个中间层维护一个mysql的连接池,这样既能满足实际业务需求,也不会造成死锁。当然对于这个具体场景也是有简单的优化方案的。造成死锁的原因是大量连接对行锁进行争夺。既然这个行锁是性能瓶颈,那我们可以通过增加行锁来减少争夺的成本。
我们稍微改造一下表结构,添加一个联合主键(id、thread_id),每个连接都执行 INSERT INTO
TestBVALUES (1,{thread_id},1)
ON DUPLICATE KEY UPDATE num=num+1。这样每个连接都有了属于自己的行锁,不会互相争夺而产生死锁了。最后只需要执行一下sum就可以获取最终结果了。
CREATE TABLE `TestB` ( `id` int(11) NOT NULL, `thread_id` int(11) NOT NULL, `num` int(1) DEFAULT NULL, PRIMARY KEY (`id`,`thread_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
压测测试结果如图,随着连接数的增加,耗时减少至稳定,cpu使用率增加至稳定。
原文: https://www.qcloud.com/community/article/752832

相关文章推荐
- mysql insert into on duplicate key update timestamp类型 (近期遇到问题)
- Mysql中Insert into xxx on duplicate key update问题
- Mysql中“Insert into xxx on duplicate key update”问题
- Mysql中Insert into xxx on duplicate key update问题
- Mysql中Insert into xxx on duplicate key update问题
- Mysql replace into 与 insert into on duplicate key update 的区别
- mysql INSERT ... ON DUPLICATE KEY UPDATE语句在perl下的使用
- mysql 批量更新语句 INSERT ON DUPLICATE KEY UPDATE
- 【转】mysql insert的几点操作(DELAYED 、IGNORE、ON DUPLICATE KEY UPDATE )
- MYSQL的REPLACE和ON DUPLICATE KEY UPDATE语句介绍解决问题实例
- MySQL的Replace into 与Insert into ..... on duplicate key update ...真正的不同之处
- MYSQL的REPLACE和ON DUPLICATE KEY UPDATE语句介绍解决问题实例
- mysql insert的几点操作(DELAYED 、IGNORE、ON DUPLICATE KEY UPDATE )
- (转载)[MySQL技巧]INSERT INTO… ON DUPLICATE KEY UPDATE
- MySQL的Replace into 与Insert into ..... on duplicate key update ...真正的不同之处
- mysql 中使用INSERT ... ON DUPLICATE KEY UPDATE(insert ignore)
- Mysql中Insert into xxx on duplicate key update和REPLACE INTO使用
- mysql insert的几点操作(DELAYED,IGNORE,ON DUPLICATE KEY UPDATE )
- [mysql 语法]INSERT ... ON DUPLICATE KEY UPDATE
- MySQL的Replace into 与Insert into on duplicate key update真正的不同之处