MapReduce Job本地提交过程源码跟踪及分析
2017-06-08 23:42
387 查看
MapReduce Job作业的提交过程可以分为本地提交模式与集群模式提交,这两种提交模式与org.apache.hadoop.mapred.LocalJobRunner、org.apache.hadoop.mapred.YARNRunner这两个类相关。在本篇文章中,将剖析Job作业本地的提交过程。用到了JVM的远程调试,具体操作请见这篇 “eclipse中远程调试JVM(以启动namenode进程为例)”
所写的MapReduce程序、debug的操作步骤以及本文中涉及到的内容均以整理好打包上传,下载地址。
submit()方法
connect()方法
JobSubmitter类中的copyAndConfigureFiles()方法
LocalJobRunner类中的内部类Job
在Job类中涉及到了run、runTasks以及Job的内部类MapTaskRunnable与ReduceTaskRunnable
Job类中的run()方法
Job类中的runTasks()方法
Job的内部类MapTaskRunnable
Job的内部类ReduceTaskRunnable
注:图片不清晰,右键图片在新标签页中显示图片即可,可以放大观看。对于图片格式调整,不太在行。。抱歉
所写的MapReduce程序、debug的操作步骤以及本文中涉及到的内容均以整理好打包上传,下载地址。
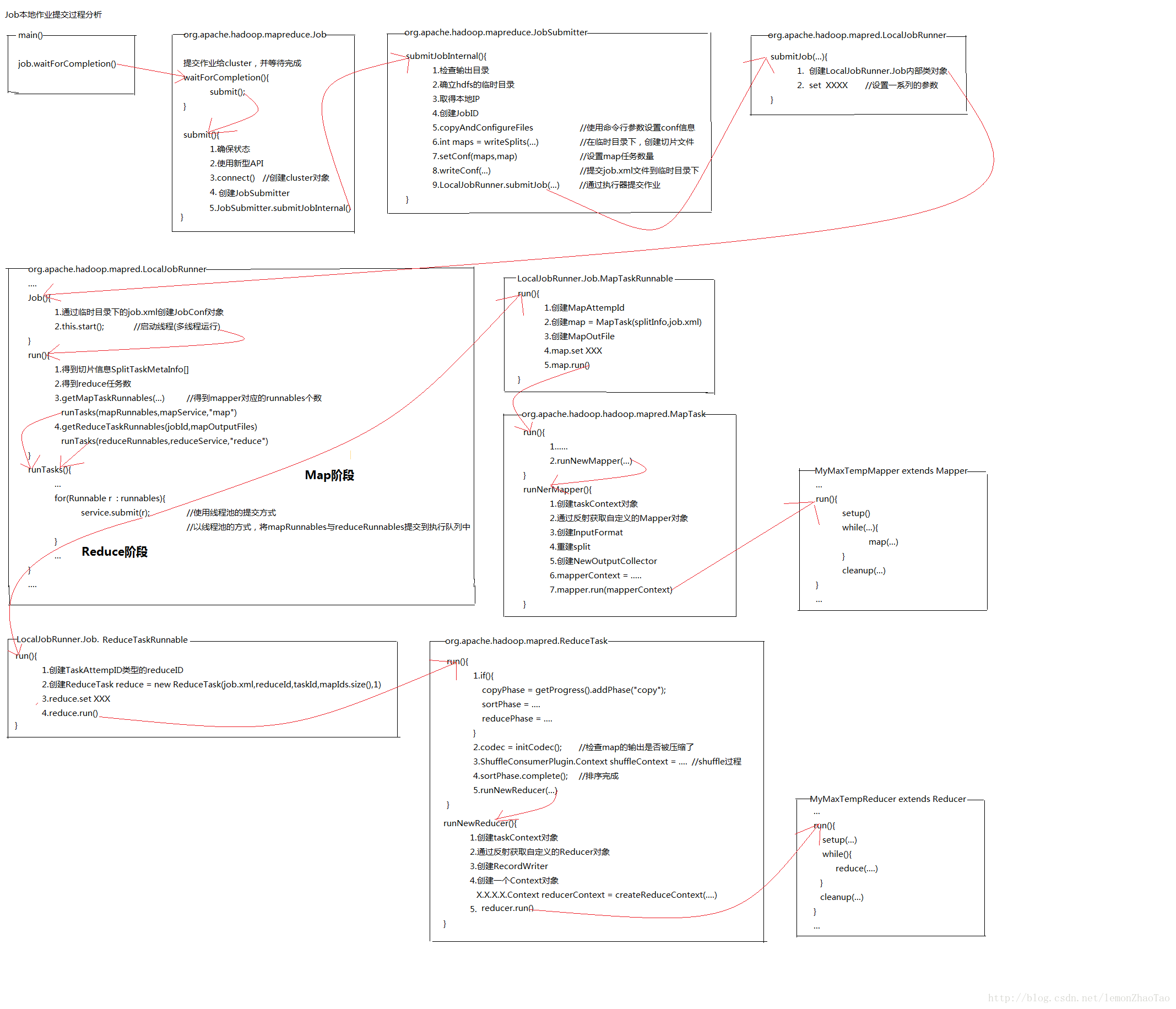
Job作业本地提交过程简略表示
先将整理得出的提交过程简略标示图,以方便阅读后文所写的关键代码解析job.submit()
--> JobSubmitter.submitJobInternal()
--> LocalJobRunner.submitJob(..)
--> 转换Job为LocalJobRunner.Job的对象(线程,并启动)
new LocalJobRunner(){
...
this.start(); //启动job线程
}
--> LocalJobRunner.run()
1.创建mapRunnables集合 //map数量取决于切片的数量
2.runTasks(mapRunnable集合)
3.创建reduceRunnables集合 //reduce数量需要手动进行设置
4.runTasks(reduceRunnable集合)
--> runTasks(...)
for(Runnable r : runnables){
service.submit(r);
}
--> MapTaskRunnable.run() \ ReduceTaskRunnable.run()
{
MapTask task = new MapTask(); \ ReduceTask task = new ReduceTask();
task.run();
}
--> MapTask.run(){
MyMaxTempMapper.run(){
setup();
while(){
map(...);
}
cleanup();
}
}
ReduceTask.run(){
MyMaxTempMapper.run(){
setup();
while(){
reduce(...);
}
cleanup();
}
}源码解析
org.apache.hadoop.mapreduce.Job类
waitForCompletion()方法/**
* 提交作业给集群并等待完成
* Submit the job to the cluster and wait for it to finish.
* @param verbose print the progress to the user
* @return true if the job succeeded
* @throws IOException thrown if the communication with the
* <code>JobTracker</code> is lost
*/
public boolean waitForCompletion(boolean verbose
) throws IOException, InterruptedException,
ClassNotFoundException {
//状态的提取
if (state == JobState.DEFINE) {
//调用自己的提交方法
submit();
}
if (verbose) {
monitorAndPrintJob();
} else {
// get the completion poll interval from the client.
int completionPollIntervalMillis =
Job.getCompletionPollInterval(cluster.getConf());
while (!isComplete()) {
try {
Thread.sleep(completionPollIntervalMillis);
} catch (InterruptedException ie) {
}
}
}
return isSuccessful();
}submit()方法
/**
* 提交作业给集群立即返回
* Submit the job to the cluster and return immediately.
* @throws IOException
*/
public void submit()
throws IOException, InterruptedException, ClassNotFoundException {
//确认状态
ensureState(JobState.DEFINE);
//设置新型API
setUseNewAPI();
//连接,连接到集群
connect();
//创建了一个作业提交器,从集群中取出文件系统和Client,得到文件系统和客户端的值;通过集群的文件系统和集群的客户端,从而得到作业提交器
final JobSubmitter submitter =
getJobSubmitter(cluster.getFileSystem(), cluster.getClient());
//匿名内部类new PrivilegedExceptionAction<JobStatus>()
status = ugi.doAs(new PrivilegedExceptionAction<JobStatus>() {
public JobStatus run() throws IOException, InterruptedException,
ClassNotFoundException {
//调用了JobSubmitter的submitJobInternal()方法(内部的提交方法) 最重要一步
return submitter.submitJobInternal(Job.this, cluster);
}
});
state = JobState.RUNNING;
LOG.info("The url to track the job: " + getTrackingURL());
}connect()方法
//使用了匿名内部类对象new PrivilegedExceptionAction<Cluster>()
//目的就是创建集群对象,通过匿名内部类创建出一个集群对象,返回给cluster(cluster是Job类的成员变量)
private synchronized void connect()
throws IOException, InterruptedException, ClassNotFoundException {
if (cluster == null) {
cluster =
ugi.doAs(new PrivilegedExceptionAction<Cluster>() {
public Cluster run()
throws IOException, InterruptedException,
ClassNotFoundException {
//通过getConfiguration()方法将配置传给集群
return new Cluster(getConfiguration());
}
});
}
}org.apache.hadoop.mapreduce.JobSubmitter类
JobSubmitter类中的submitJobInternal()方法JobSubmitter.submitJobInternal(){
...
JobStatus submitJobInternal(Job job, Cluster cluster)
throws ClassNotFoundException, InterruptedException, IOException {
//validate the jobs output specs 检查空间,如果输出目录存在就会抛出异常
checkSpecs(job);
//拿到job的配置
Configuration conf = job.getConfiguration();
//把conf放入分布式缓存(可以先不管)
addMRFrameworkToDistributedCache(conf);
//进入作业的阶段性区域(hdfs的临时目录)
Path jobStagingArea = JobSubmissionFiles.getStagingDir(cluster, conf);
//取得本地客户IP(作业提交客户端的ip地址,即在哪一台机子上进行提交)
InetAddress ip = InetAddress.getLocalHost();
if (ip != null) {
//得到本机的提交地址
submitHostAddress = ip.getHostAddress();
//得到本机的主机名字
submitHostName = ip.getHostName();
//获取之后,在配置文件中进行submitHostName和submitHostAddress的设置
conf.set(MRJobConfig.JOB_SUBMITHOST,submitHostName);
conf.set(MRJobConfig.JOB_SUBMITHOSTADDR,submitHostAddress);
//创建一个新的作业ID(每个Job作业都有一个唯一的ID)
JobID jobId = submitClient.getNewJobID();
//对JobID进行设置
job.setJobID(jobId);
//通过jobid和临时目录构造出一个新的路径
Path submitJobDir = new Path(jobStagingArea, jobId.toString());
//作业状态
JobStatus status = null;
try{
//设置用户名称
conf.set(MRJobConfig.USER_NAME,
UserGroupInformation.getCurrentUser().getShortUserName());
//设置过滤器初始化
conf.set("hadoop.http.filter.initializers",
"org.apache.hadoop.yarn.server.webproxy.amfilter.AmFilterInitializer");
//设置作业目录
//submitJobDir的值发生了改变,
值为file:/tmp/hadoop-陶/mapred/staging/ì635285396/.staging/job_local635285396_0001
//说明在./.staging/目录下还要创造一个子文件夹来存放作业
conf.set(MRJobConfig.MAPREDUCE_JOB_DIR, submitJobDir.toString());
...
//接下来的一长串操作是进行安全性控制,进行安全认证(hadoop可以加入安全认证的插件)
// generate a secret to authenticate shuffle transfers
if (TokenCache.getShuffleSecretKey(job.getCredentials()) == null) {
KeyGenerator keyGen;
try {
keyGen = KeyGenerator.getInstance(SHUFFLE_KEYGEN_ALGORITHM);
keyGen.init(SHUFFLE_KEY_LENGTH);
} catch (NoSuchAlgorithmException e) {
throw new IOException("Error generating shuffle secret key", e);
}
SecretKey shuffleKey = keyGen.generateKey();
TokenCache.setShuffleSecretKey(shuffleKey.getEncoded(),
job.getCredentials());
}
if (CryptoUtils.isEncryptedSpillEnabled(conf)) {
conf.setInt(MRJobConfig.MR_AM_MAX_ATTEMPTS, 1);
LOG.warn("Max job attempts set to 1 since encrypted intermediate" +
"data spill is enabled");
}
//拷贝并配置文件
copyAndConfigureFiles(job, submitJobDir);
Path submitJobFile = JobSubmissionFiles.getJobConfPath(submitJobDir);
// Create the splits for the job 为作业创建切片(map任务的个数取决于切片的个数)
LOG.debug("Creating splits at " + jtFs.makeQualified(submitJobDir));
int maps = writeSplits(job, submitJobDir);
//执行完writeSplits()方法(该方法就是创建切片的过程)之后,在./.staging/job_local635285396_0001/目录下生成了四个文件
//.job.split.crc、.job.splitmetainfo.crc校验和文件
//job.split切片文件 job.splitmetainfo切片元信息文件
//设置MapReduce的map任务数
conf.setInt(MRJobConfig.NUM_MAPS, maps);
//打印map信息
LOG.info("number of splits:" + maps);
//作业提交到作业队列中去,由作业队列进行管理
// write "queue admins of the queue to which job is being submitted"
// to job file.
String queue = conf.get(MRJobConfig.QUEUE_NAME,
JobConf.DEFAULT_QUEUE_NAME);
AccessControlList acl = submitClient.getQueueAdmins(queue);
conf.set(toFullPropertyName(queue,
QueueACL.ADMINISTER_JOBS.getAclName()), acl.getAclString());
...
//写入job file到提交目录中(提交job.xml到提交目录)
//job.xml文件里包含了四个配置文件里面所设置的所有参数
writeConf(conf, submitJobFile);
...
//submitClient=LocalJobRunner
//LocalJobRunner.submitJob() 通过执行器提交作业
status = submitClient.submitJob(
jobId, submitJobDir.toString(), job.getCredentials());
}
}
}
...
}JobSubmitter类中的copyAndConfigureFiles()方法
JobSubmitter{
...
//使用命令行参数设置conf信息
private void copyAndConfigureFiles(Job job, Path jobSubmitDir)
throws IOException {
JobResourceUploader rUploader = new JobResourceUploader(jtFs);
rUploader.uploadFiles(job, jobSubmitDir);
// Get the working directory. If not set, sets it to filesystem working dir
// This code has been added so that working directory reset before running
// the job. This is necessary for backward compatibility as other systems
// might use the public API JobConf#setWorkingDirectory to reset the working
// directory.
job.getWorkingDirectory();
}
...
}org.apache.hadoop.mapred.LocalJobRunner类
LocalJobRunner类中的submitJob方法LocalJobRunner{
...
public org.apache.hadoop.mapreduce.JobStatus submitJob(
org.apache.hadoop.mapreduce.JobID jobid, String jobSubmitDir,
Credentials credentials) throws IOException {
//创建LocalJobRunner.job的内部类对象
Job job = new Job(JobID.downgrade(jobid), jobSubmitDir);
job.job.setCredentials(credentials);
return job.status;
}
...
}LocalJobRunner类中的内部类Job
在Job类中涉及到了run、runTasks以及Job的内部类MapTaskRunnable与ReduceTaskRunnable
LocalJobRunner.Job extends Thread implements TaskUmbilicalProtocol{
...
public Job(JobID jobid, String jobSubmitDir) throws IOException {
//通过临时目录下的job.xml创建JobConf对象
this.systemJobDir = new Path(jobSubmitDir);
this.systemJobFile = new Path(systemJobDir, "job.xml");
this.id = jobid;
JobConf conf = new JobConf(systemJobFile);
//得到本地文件系统
this.localFs = FileSystem.getLocal(conf);
String user = UserGroupInformation.getCurrentUser().getShortUserName();
//得到本地目录
this.localJobDir = localFs.makeQualified(new Path(
new Path(conf.getLocalPath(jobDir), user), jobid.toString()));
//得到本地文件
this.localJobFile = new Path(this.localJobDir, id + ".xml");
// Manage the distributed cache. If there are files to be copied,
// this will trigger localFile to be re-written again.
localDistributedCacheManager = new LocalDistributedCacheManager();
localDistributedCacheManager.setup(conf);
//通过流写入一个配置文件
// Write out configuration file. Instead of copying it from
// systemJobFile, we re-write it, since setup(), above, may have
// updated it.
OutputStream out = localFs.create(localJobFile);
try {
//写入流。 写入job_local2086240933_0001.xml
conf.writeXml(out);
} finally {
//写入成功 生成job_local2086240933_0001.xml.crc文件和job_local2086240933_0001.xml文件
out.close();
}
//上述一大段代码都是在准备目录、配置文件、配置空间,至此还没有执行任何的任务
//通过localJobFile创建一个文件
this.job = new JobConf(localJobFile);
...
//最终目的:启动线程
this.start();
...Job类中的run()方法
@Override
public void run() {
//得到作业的ID
JobID jobId = profile.getJobID();
//拿到作业的上下文
JobContext jContext = new JobContextImpl(job, jobId);
org.apache.hadoop.mapreduce.OutputCommitter outputCommitter = null;
try {
outputCommitter = createOutputCommitter(conf.getUseNewMapper(), jobId, conf);
} catch (Exception e) {
LOG.info("Failed to createOutputCommitter", e);
return;
}
try {
//任务切片元信息,得到切片信息
TaskSplitMetaInfo[] taskSplitMetaInfos =
SplitMetaInfoReader.readSplitMetaInfo(jobId, localFs, conf, systemJobDir);
//得到Reduce任务数
int numReduceTasks = job.getNumReduceTasks();
//安装作业 设置作业
outputCommitter.setupJob(jContext);
//设置作业进度
status.setSetupProgress(1.0f);
//输出文件
Map<TaskAttemptID, MapOutputFile> mapOutputFiles =
Collections.synchronizedMap(new HashMap<TaskAttemptID, MapOutputFile>());
//得到mappper对应的runnable个数(Runner.Job.MapTaskRunnable) org.apache.hadoop.mapred.LocalJobRunner$Job$MapTaskRunnable
List<RunnableWithThrowable> mapRunnables = getMapTaskRunnables(
taskSplitMetaInfos, jobId, mapOutputFiles);
//初始化计数器
initCounters(mapRunnables.size(), numReduceTasks);
//创建一个map的线程池的执行器
ExecutorService mapService = createMapExecutor();
//开始运行map任务任务
//注意:mapreduce的运行过程中,使用了线程池的技术(放到队列当中,在将来的某个时刻进行执行)
runTasks(mapRunnables, mapService, "map");
try {
//如果reduce的个数大于0,再去执行reduce阶段
if (numReduceTasks > 0) {
//计算reduce对应的runnable个数
List<RunnableWithThrowable> reduceRunnables = getReduceTaskRunnables(
jobId, mapOutputFiles);
ExecutorService reduceService = createReduceExecutor();
//开始运行reduce任务
runTasks(reduceRunnables, reduceService, "reduce");
}
} finally {
for (MapOutputFile output : mapOutputFiles.values()) {
output.removeAll();
}
}
// delete the temporary directory in output directory
outputCommitter.commitJob(jContext);
status.setCleanupProgress(1.0f);
if (killed) {
this.status.setRunState(JobStatus.KILLED);
} else {
this.status.setRunState(JobStatus.SUCCEEDED);
}
JobEndNotifier.localRunnerNotification(job, status);
} catch (Throwable t) {
try {
outputCommitter.abortJob(jContext,
org.apache.hadoop.mapreduce.JobStatus.State.FAILED);
} catch (IOException ioe) {
LOG.info("Error cleaning up job:" + id);
}
status.setCleanupProgress(1.0f);
if (killed) {
this.status.setRunState(JobStatus.KILLED);
} else {
this.status.setRunState(JobStatus.FAILED);
}
LOG.warn(id, t);
JobEndNotifier.localRunnerNotification(job, status);
} finally {
try {
fs.delete(systemJobFile.getParent(), true); // delete submit dir
localFs.delete(localJobFile, true); // delete local copy
// Cleanup distributed cache
localDistributedCacheManager.close();
} catch (IOException e) {
LOG.warn("Error cleaning up "+id+": "+e);
}
}
}Job类中的runTasks()方法
...
/** Run a set of tasks and waits for them to complete. */
private void runTasks(List<RunnableWithThrowable> runnables,
ExecutorService service, String taskType) throws Exception {
// Start populating the executor with work units.
// They may begin running immediately (in other threads).
for (Runnable r : runnables) {
//进行提交 是一个线程池,执行map和reduce
service.submit(r);
}
...
}Job的内部类MapTaskRunnable
MapTaskRunnable{
...
public void run() {
try {
//生成一个maptask的ID
TaskAttemptID mapId = new TaskAttemptID(new TaskID(
jobId, TaskType.MAP, taskId), 0);
LOG.info("Starting task: " + mapId);
//将mapID加入到mapIds这个集合里来
mapIds.add(mapId);
//作业文件(实质上是一个job.xml文件,可通过watch查看),mapid,任务id,切片信息 去构造一个MapTask类型的对象
MapTask map = new MapTask(systemJobFile.toString(), mapId, taskId,
info.getSplitIndex(), 1);
map.setUser(UserGroupInformation.getCurrentUser().
getShortUserName());
//设置目录
//map为MapTask类型的一个值,例如本次调试中所获取的值为:attempt_local335618588_0001_m_000000_0
//localConf()加载配置文件的信息
setupChildMapredLocalDirs(map, localConf);
//创建一个map输出文件
MapOutputFile mapOutput = new MROutputFiles();
//设置配置信息
mapOutput.setConf(localConf);
mapOutputFiles.put(mapId, mapOutput);
//localJobFile.toString()的值为file:/tmp/hadoop-陶/mapred/local/localRunner/ì?/job_local335618588_0001/job_local335618588_0001.xml
//实质上是一个job_local335618588_0001.xml文件
map.setJobFile(localJobFile.toString());
localConf.setUser(map.getUser());
map.localizeConfiguration(localConf);
map.setConf(localConf);
try {
map_tasks.getAndIncrement();
//launchMap()方法,进行启动map
myMetrics.launchMap(mapId);
map.run(localConf, Job.this);
myMetrics.completeMap(mapId);
} finally {
map_tasks.getAndDecrement();
}
LOG.info("Finishing task: " + mapId);
} catch (Throwable e) {
this.storedException = e;
}
}
...
}
}Job的内部类ReduceTaskRunnable
ReduceTaskRunnable{
...
public void run() {
try {
TaskAttemptID reduceId = new TaskAttemptID(new TaskID(
jobId, TaskType.REDUCE, taskId), 0);
LOG.info("Starting task: " + reduceId);
ReduceTask reduce = new ReduceTask(systemJobFile.toString(),
reduceId, taskId, mapIds.size(), 1);
reduce.setUser(UserGroupInformation.getCurrentUser().
getShortUserName());
setupChildMapredLocalDirs(reduce, localConf);
reduce.setLocalMapFiles(mapOutputFiles);
if (!Job.this.isInterrupted()) {
reduce.setJobFile(localJobFile.toString());
localConf.setUser(reduce.getUser());
reduce.localizeConfiguration(localConf);
reduce.setConf(localConf);
try {
reduce_tasks.getAndIncrement();
// 进行启动reduce
myMetrics.launchReduce(reduce.getTaskID());
// 开始运行reduce任务
reduce.run(localConf, Job.this);
myMetrics.completeReduce(reduce.getTaskID());
} finally {
reduce_tasks.getAndDecrement();
}
LOG.info("Finishing task: " + reduceId);
...
}
}
}
...
}
}org.apache.hadoop.mapred.MapTask
MapTask{
...
@Override
public void run(final JobConf job, final TaskUmbilicalProtocol umbilical)
throws IOException, ClassNotFoundException, InterruptedException {
this.umbilical = umbilical;
//判断是否是map任务
if (isMapTask()) {
// If there are no reducers then there won't be any sort. Hence the map
// phase will govern the entire attempt's progress.
//如果没有reduce就不做任何排序
if (conf.getNumReduceTasks() == 0) {
mapPhase = getProgress().addPhase("map", 1.0f);
} else {
// If there are reducers then the entire attempt's progress will be
// split between the map phase (67%) and the sort phase (33%).
mapPhase = getProgress().addPhase("map", 0.667f);
//进行排序
sortPhase = getProgress().addPhase("sort", 0.333f);
}
}
//启动一个汇报
TaskReporter reporter = startReporter(umbilical);
boolean useNewApi = job.getUseNewMapper();
//进行初始化工作
initialize(job, getJobID(), reporter, useNewApi);
// check if it is a cleanupJobTask
if (jobCleanup) {
runJobCleanupTask(umbilical, reporter);
return;
}
if (jobSetup) {
runJobSetupTask(umbilical, reporter);
return;
}
if (taskCleanup) {
runTaskCleanupTask(umbilical, reporter);
return;
}
//判断是否是新型Api
if (useNewApi) {
//调用自己所写的mapper类
//作业信息,切片元信息,,报告
runNewMapper(job, splitMetaInfo, umbilical, reporter);
} else {
//调用自己所写的mapper类
runOldMapper(job, splitMetaInfo, umbilical, reporter);
}
done(umbilical, reporter);
}
...
@SuppressWarnings("unchecked")
private <INKEY,INVALUE,OUTKEY,OUTVALUE>
void runNewMapper(final JobConf job,
final TaskSplitIndex splitIndex,
final TaskUmbilicalProtocol umbilical,
TaskReporter reporter
) throws IOException, ClassNotFoundException,
InterruptedException {
// make a task context so we can get the classes
// 通过创建任务的上下文对象,获取类的对象
org.apache.hadoop.mapreduce.TaskAttemptContext taskContext =
new org.apache.hadoop.mapreduce.task.TaskAttemptContextImpl(job,
getTaskID(),
reporter);
// make a mapper
// 创建一个mapper,通过反射的方式得到mapper(值为class com.zhaotao.hadoop.mr.MyMaxTempMapper)
// taskContext.getMapperClass()的值为class com.zhaotao.hadoop.mr.MyMaxTempMapper
org.apache.hadoop.mapreduce.Mapper<INKEY,INVALUE,OUTKEY,OUTVALUE> mapper =
(org.apache.hadoop.mapreduce.Mapper<INKEY,INVALUE,OUTKEY,OUTVALUE>)
ReflectionUtils.newInstance(taskContext.getMapperClass(), job);
// make the input format
// 通过反射获取输入格式的对象
org.apache.hadoop.mapreduce.InputFormat<INKEY,INVALUE> inputFormat =
(org.apache.hadoop.mapreduce.InputFormat<INKEY,INVALUE>)
ReflectionUtils.newInstance(taskContext.getInputFormatClass(), job);
// rebuild the input split
// 重建输入的切片
org.apache.hadoop.mapreduce.InputSplit split = null;
split = getSplitDetails(new Path(splitIndex.getSplitLocation()),
splitIndex.getStartOffset());
LOG.info("Processing split: " + split);
org.apache.hadoop.mapreduce.RecordReader<INKEY,INVALUE> input =
new NewTrackingRecordReader<INKEY,INVALUE>
(split, inputFormat, reporter, taskContext);
job.setBoolean(JobContext.SKIP_RECORDS, isSkipping());
org.apache.hadoop.mapreduce.RecordWriter output = null;
// get an output object
// 判断是否有reduce
if (job.getNumReduceTasks() == 0) {
output =
new NewDirectOutputCollector(taskContext, job, umbilical, reporter);
} else {
// 新建一个输出收集器(与自己重写的mapper方法种Context对象相关)===>等价于Context对象
output = new NewOutputCollector(taskContext, job, umbilical, reporter);
}
// 将新建的输出收集器对象output放入MapContextImpl中,以此得到MapContext对象
org.apache.hadoop.mapreduce.MapContext<INKEY, INVALUE, OUTKEY, OUTVALUE>
mapContext =
new MapContextImpl<INKEY, INVALUE, OUTKEY, OUTVALUE>(job, getTaskID(),
input, output,
committer,
reporter, split);
// 对mapContext进行包装,得到定义的Context类型的mapperContext
org.apache.hadoop.mapreduce.Mapper<INKEY,INVALUE,OUTKEY,OUTVALUE>.Context
mapperContext =
new WrappedMapper<INKEY, INVALUE, OUTKEY, OUTVALUE>().getMapContext(
mapContext);
try {
// 先做初始化
input.initialize(split, mapperContext);
//具体内容看Mapper类中的run()方法
mapper.run(mapperContext);
mapPhase.complete();
setPhase(TaskStatus.Phase.SORT);
statusUpdate(umbilical);
input.close();
input = null;
output.close(mapperContext);
output = null;
} finally {
closeQuietly(input);
closeQuietly(output, mapperContext);
}
}
...
}org.apache.hadoop.mapreduce.Mapper
Mapper{
...
// map的执行过程中分为三个阶段
// a.安装阶段
// b.循环调用map()阶段 (只有该阶段是自己定义的) 在Java中,这是一个典型的回调机制(只有在重写方法的时候进行回调机制)
// c.清除阶段
// 传入了Context类型的参数
public void run(Context context) throws IOException, InterruptedException {
setup(context);
try {
// 使用循环,不断调用map方法(实质上就是自己重写的map方法,对其不断的调用,用于处理文本行)
// 判断是否存在下一个Key - Value
while (context.nextKeyValue()) {
// 存在,取出Key值、Value值,并传入上下文context
map(context.getCurrentKey(), context.getCurrentValue(), context);
}
} finally {
// 最后对其进行清理
cleanup(context);
}
}
...
}org.apache.hadoop.mapreduce.lib.map.WrappedMapper
WrappedMapper{
...
@Override
public boolean nextKeyValue() throws IOException, InterruptedException {
// 返回Key值
return mapContext.nextKeyValue();
}
@Override
public Counter getCounter(Enum<?> counterName) {
// 返回Value值
return mapContext.getCounter(counterName);
}
...
}org.apache.hadoop.mapred.ReduceTask
ReduceTask{
...
@Override
@SuppressWarnings("unchecked")
public void run(JobConf job, final TaskUmbilicalProtocol umbilical)
throws IOException, InterruptedException, ClassNotFoundException {
job.setBoolean(JobContext.SKIP_RECORDS, isSkipping());
// 判断是Map或者Reduce
if (isMapOrReduce()) {
// 添加一个拷贝阶段
copyPhase = getProgress().addPhase("copy");
// 增加一个排序阶段
sortPhase = getProgress().addPhase("sort");
// 增加一个reduce化简阶段
reducePhase = getProgress().addPhase("reduce");
}
// start thread that will handle communication with parent
TaskReporter reporter = startReporter(umbilical);
// 判断是否使用了新的Reducer Api
boolean useNewApi = job.getUseNewReducer();
// 利用上述值进行初始化操作
initialize(job, getJobID(), reporter, useNewApi);
// check if it is a cleanupJobTask
if (jobCleanup) {
runJobCleanupTask(umbilical, reporter);
return;
}
if (jobSetup) {
runJobSetupTask(umbilical, reporter);
return;
}
if (taskCleanup) {
runTaskCleanupTask(umbilical, reporter);
return;
}
// Initialize the codec
// 检查map的输出是否被压缩了
codec = initCodec();
// 一个迭代器
RawKeyValueIterator rIter = null;
// shuffle洗牌
ShuffleConsumerPlugin shuffleConsumerPlugin = null;
Class combinerClass = conf.getCombinerClass();
CombineOutputCollector combineCollector =
(null != combinerClass) ?
new CombineOutputCollector(reduceCombineOutputCounter, reporter, conf) : null;
Class<? extends ShuffleConsumerPlugin> clazz =
job.getClass(MRConfig.SHUFFLE_CONSUMER_PLUGIN, Shuffle.class, ShuffleConsumerPlugin.class);
shuffleConsumerPlugin = ReflectionUtils.newInstance(clazz, job);
LOG.info("Using ShuffleConsumerPlugin: " + shuffleConsumerPlugin);
// 正式开启reduce之前的shuffle过程
ShuffleConsumerPlugin.Context shuffleContext =
new ShuffleConsumerPlugin.Context(getTaskID(), job, FileSystem.getLocal(job), umbilical,
super.lDirAlloc, reporter, codec,
combinerClass, combineCollector,
spilledRecordsCounter, reduceCombineInputCounter,
shuffledMapsCounter,
reduceShuffleBytes, failedShuffleCounter,
mergedMapOutputsCounter,
taskStatus, copyPhase, sortPhase, this,
mapOutputFile, localMapFiles);
// shuffle完成
shuffleConsumerPlugin.init(shuffleContext);
// rIter是一个MergeQueue合并队列
rIter = shuffleConsumerPlugin.run();
// free up the data structures
mapOutputFilesOnDisk.clear();
// 排序已经完成
sortPhase.complete(); // sort is complete
setPhase(TaskStatus.Phase.REDUCE);
statusUpdate(umbilical);
Class keyClass = job.getMapOutputKeyClass();
Class valueClass = job.getMapOutputValueClass();
RawComparator comparator = job.getOutputValueGroupingComparator();
// 判断reduce的Api是否为新版本
if (useNewApi) {
// 开始运行reduce任务
runNewReducer(job, umbilical, reporter, rIter, comparator,
keyClass, valueClass);
} else {
runOldReducer(job, umbilical, reporter, rIter, comparator,
keyClass, valueClass);
}
shuffleConsumerPlugin.close();
done(umbilical, reporter);
}
...
@SuppressWarnings("unchecked")
private <INKEY,INVALUE,OUTKEY,OUTVALUE>
void runNewReducer(JobConf job,
final TaskUmbilicalProtocol umbilical,
final TaskReporter reporter,
RawKeyValueIterator rIter,
RawComparator<INKEY> comparator,
Class<INKEY> keyClass,
Class<INVALUE> valueClass
) throws IOException,InterruptedException,
ClassNotFoundException {
// wrap value iterator to report progress.
final RawKeyValueIterator rawIter = rIter;
rIter = new RawKeyValueIterator() {
public void close() throws IOException {
rawIter.close();
}
public DataInputBuffer getKey() throws IOException {
return rawIter.getKey();
}
public Progress getProgress() {
return rawIter.getProgress();
}
public DataInputBuffer getValue() throws IOException {
return rawIter.getValue();
}
public boolean next() throws IOException {
boolean ret = rawIter.next();
reporter.setProgress(rawIter.getProgress().getProgress());
return ret;
}
};
// make a task context so we can get the classes
// 创建一个任务上下文来获取class
org.apache.hadoop.mapreduce.TaskAttemptContext taskContext =
new org.apache.hadoop.mapreduce.task.TaskAttemptContextImpl(job,
getTaskID(), reporter);
// make a reducer
// 通过反射的方式获取reducer对象
// taskContext.getReducerClass()的值为com.zhaotao.hadoop.mr.MyMaxTempReducer
org.apache.hadoop.mapreduce.Reducer<INKEY,INVALUE,OUTKEY,OUTVALUE> reducer =
(org.apache.hadoop.mapreduce.Reducer<INKEY,INVALUE,OUTKEY,OUTVALUE>)
ReflectionUtils.newInstance(taskContext.getReducerClass(), job);
org.apache.hadoop.mapreduce.RecordWriter<OUTKEY,OUTVALUE> trackedRW =
new NewTrackingRecordWriter<OUTKEY, OUTVALUE>(this, taskContext);
job.setBoolean("mapred.skip.on", isSkipping());
job.setBoolean(JobContext.SKIP_RECORDS, isSkipping());
org.apache.hadoop.mapreduce.Reducer.Context
reducerContext = createReduceContext(reducer, job, getTaskID(),
rIter, reduceInputKeyCounter,
reduceInputValueCounter,
trackedRW,
committer,
reporter, comparator, keyClass,
valueClass);
try {
// 进入并开始reduce的运行
reducer.run(reducerContext);
} finally {
trackedRW.close(reducerContext);
}
}
...
}org.apache.hadoop.mapreduce.Reducer
Reducer{
...
// 分三阶段运行,与mapper的run()方法运行的一样
public void run(Context context) throws IOException, InterruptedException {
setup(context);
try {
while (context.nextKey()) {
reduce(context.getCurrentKey(), context.getValues(), context);
// If a back up store is used, reset it
Iterator<VALUEIN> iter = context.getValues().iterator();
if(iter instanceof ReduceContext.ValueIterator) {
((ReduceContext.ValueIterator<VALUEIN>)iter).resetBackupStore();
}
}
} finally {
cleanup(context);
}
}
...
}Job作业本地提交流程分析图
注:图片不清晰,右键图片在新标签页中显示图片即可,可以放大观看。对于图片格式调整,不太在行。。抱歉

相关文章推荐
- Hadoop源码分析23:MapReduce的Job提交过程
- MapReduce执行过程源码分析(一)——Job任务的提交
- Hadoop源码分析--MapReduce作业(job)提交源码跟踪
- [hadoop源码阅读][9]-mapreduce-job提交过程
- mapreduce源码分析作业提交、初始化、分配、计算过程之初始化篇
- Hadoop源码分析(三)--------------job提交过程分析(3)之job的split过程
- spark源码分析之DAGScheduler提交作业(job)过程、stage阶段说明
- mapreduce提交job源码分析
- mapreduce源码分析作业提交、初始化、分配、计算过程之提交篇
- Hama框架学习(一) 从源码角度分析job的提交和运行过程
- Hahoop源码分析(一)-----------job提交过程分析(1)
- Hadoop-2.7.3源码分析:MapReduce作业提交源码跟踪
- MapReduce Job集群提交过程源码跟踪及分析
- hadoop2提交到Yarn: Mapreduce执行过程分析
- MapReduce job在JobTracker初始化源码级分析
- MapReduce源码解读系列之——作业如何提交到JobTracker
- spark源码分析只: job 全过程
- 通过jobtracker、tasktraker的log分析mapreduce的过程
- job的提交过程源代码分析
- storm源码分析之topology提交过程