Kafka学习笔记——Kafka原理与使用详解
2017-06-08 23:29
489 查看
Kafka 是一个消息系统,原本开发自 LinkedIn,用作 LinkedIn 的活动流(Activity Stream)和运营数据处理管道(Pipeline)的基础。现在它已被多家公司作为多种类型的数据管道和消息系统使用。活动流数据是几乎所有站点在对其网站使用情况做报表时都要用到的数据中最常规的部分。活动数据包括页面访问量(Page View)、被查看内容方面的信息以及搜索情况等内容。这种数据通常的处理方式是先把各种活动以日志的形式写入某种文件,然后周期性地对这些文件进行统计分析。运营数据指的是服务器的性能数据(CPU、IO 使用率、请求时间、服务日志等等数据),总的来说,运营数据的统计方法种类繁多。
高吞吐量:即使是非常普通的硬件kafka也可以支持每秒数十万的消息。
支持通过kafka服务器和消费机集群来分区消息。
支持Hadoop并行数据加载。
Topic:每条发布到 Kafka 集群的消息都有一个类别,这个类别被称为 Topic。(物理上不同 Topic 的消息分开存储,逻辑上一个 Topic 的消息虽然保存于一个或多个 broker 上,但用户只需指定消息的 Topic 即可生产或消费数据而不必关心数据存于何处)。
**Partition:**Partition 是物理上的概念,每个 Topic 包含一个或多个 Partition。为了实现扩展性,一个非常大的topic可以分布到多个broker(即服务器)上。kafka只保证按一个partition中的顺序将消息发给consumer,不保证一个topic的整体(多个partition间)的顺序。
Producer:负责发布消息到 Kafka broker。
Consumer:消息消费者,向 Kafka broker 读取消息的客户端。
Consumer Group:每个 Consumer 属于一个特定的 Consumer Group(可为每个 Consumer 指定 group name,若不指定 group name 则属于默认的 group)。这是kafka用来实现一个topic消息的广播(发给所有的consumer)和单播(发给任意一个consumer)的手段。一个 topic可以有多个CG。topic的消息会复制(不是真的复制,是概念上的)到所有的CG,但每个CG只会把消息发给该CG中的一个 consumer。如果需要实现广播,只要每个consumer有一个独立的CG就可以了。要实现单播只要所有的consumer在同一个CG。用CG还 可以将consumer进行自由的分组而不需要多次发送消息到不同的topic。
信息是一个字节数组,程序员可以在这些字节数组中存储任何对象,支持的数据格式包括 String、JSON、Avro。Kafka 通过给每一个消息绑定一个键值的方式来保证生产者可以把所有的消息发送到指定位置。属于某一个消费者群组的消费者订阅了一个主题,通过该订阅消费者可以跨节点地接收所有与该主题相关的消息,每一个消息只会发送给群组中的一个消费者,所有拥有相同键值的消息都会被确保发给这一个消费者。
Kafka 设计中将每一个主题分区当作一个具有顺序排列的日志。同处于一个分区中的消息都被设置了一个唯一的偏移量。Kafka 只会保持跟踪未读消息,一旦消息被置为已读状态,Kafka 就不会再去管理它了。Kafka 的生产者负责在消息队列中对生产出来的消息保证一定时间的占有,消费者负责追踪每一个主题 (可以理解为一个日志通道) 的消息并及时获取它们。基于这样的设计,Kafka 可以在消息队列中保存大量的开销很小的数据,并且支持大量的消费者订阅。
kafka 将每个 partition 数据复制到多个 server 上,任何一个partition有一个leader和多个follower(可以没有);备份的个数可以通过 broker 配置文件来设定。 leader 处理所有的 read-write 请求,follower 需要和 leader 保持同步。 Follower 和 consumer 一样,消费消息并保存在本地日志中;leader 负责跟踪所有的 follower 状态,如果follower”落后”太多或者失效,leader将会把它从replicas同步列表中删除。当所有的 follower 都将一条消息保存成功,此消息才被认为是”committed”,那么此时 consumer 才能消费它。 即使只有一个 replicas 实例存活,仍然可以保证消息的正常发送和接收,只要zookeeper 集群存活即可。 (不同于其他分布式存储,比如 hbase 需要”多数派”存活才行)当leader失效时,需在followers中选取出新的leader,可能此时 follower 落后于 leader,因此需要选择一个”up-to-date”的follower。选择follower时需要兼顾一个问题,就是新leader server上所已经承载的 partition leader 的个数,如果一个 server 上有过多的 partition leader,意味着此 server 将承受着更多的IO 压力。在选举新 leader,需要考虑到”负载均衡”
kafka的producer有一种异步发送的操作。这是为提高性能提供的。producer先将消息放在内存中,就返回。这样调用者(应用程序) 就不需要等网络传输结束就可以继续了。内存中的消息会在后台批量的发送到broker。由于消息会在内存呆一段时间,这段时间是有消息丢失的风险的。所以 使用该操作时需要仔细评估这一点。因此Kafka不像传统的MQ难以实现EIP,并且只有partition内的消息才能保证传递顺序。
另外,在最新的版本中,还实现了broker间的消息复制机制,去除了broker的单点故障(SPOF)。
下面开始看下代码示例,现在pom文件中添加jar依赖
看下生产者的代码:
kafka 提供了两套 API 给 Consumer:
The high-level Consumer API
The SimpleConsumer API
第一种高度抽象的 Consumer API, 它使用起来简单、 方便,但是对于某些特殊的需求我们可能要用到第二种更底层的API。
High Level Consumer
在某些应用场景, 我们希望通过多线程读取消息, 而我们并不关心从 Kafka 消费消息的顺序,我们仅仅关心数据能被消费就行。High Level 就是用于抽象这类消费动作的。消息消费以 Consumer Group 为单位,每个 Consumer Group 中可以有多个 consumer, 每个 consumer 是一个线程, topic 的每个
partition 同时只能被某一个 consumer 读取, Consumer Group对应的每个 partition 都有一个最新的 offset 的值,存储在zookeeper 上的。所以不会出现重复消费的情况。High Level Consumer 可以并且应该被使用在多线程的环境,线程模型中线程的数量(也代表group中consumer的数量)和topic的
partition数量有关,下面列举一些规则:
1、当提供的线程数量多于partition的数量,则部分线程将不会接收到消息;
2、当提供的线程数量少于partition的数量,则部分线程将从多个partition接收消息;
3、当某个线程从多个partition 接收消息时,不保证接收消息的顺序;可能出现从partition3接收5条消息,从partition4接收6条消息,接着又从partition3接收10条消息;
4、当添加更多线程时,会引起kafka做re-balance, 可能改变partition和线程的对应关系
high level Consumer消费者代码如下
The SimpleConsumer API
作用:
1、一个消息读取多次
2、在一个处理过程中只消费 Partition 其中的一部分消息
3、添加事务管理机制以保证消息被处理且仅被处理一次
缺点:
1、必须在程序中跟踪 offset 值
2、必须找出指定 Topic Partition 中的 lead broker
3、必须处理 broker 的变动
使用步骤:
1、从所有活跃的 broker 中找出哪个是指定 Topic Partition中的 leader broker
2、找出指定 Topic Partition 中的所有备份 broker
3、构造请求
4、发送请求查询数据
5、处理 leader broker 变
代码如下:
1、at most once: 最多一次,发送一次,无论成败,将不会重发。 消费者 fetch 消息,然后保存 offset,然后处理消息;当 client 保存offset之后,但是在消息处理过程中出现了异常,导致部分消息未能继续处理。那么此后”未处理”的消息将不能被fetch 到,这就是”at most once”。
2、at least once: 消息至少发送一次,如果消息未能接受成功,可能会重发,直到接收成功。消费者 fetch 消息,然后处理消息,然后保存 offset。如果消息处理成功之后,但是在保存 offset 阶段zookeeper异常导致保存操作未能执行成功,这就导致接下来再次fetch时可能获得上次已经处理过的消息,这就是”at least
once”, 原因 offset 没有及时的提交给zookeeper, zookeeper 恢复正常还是之前offset 状态。
3、exactly once: 消息只会发送一次。 kafka 中并没有严格的去实现(基于 2 阶段提交,事务),我们认为这种策略在 kafka 中是没有
必要的。通常情况下”at-least-once”是我们首选。 (相比 at most once而言,重复接收数据总比丢失数据要好)
志都有一个offset来唯一的标记一条消息,offset的值为8个字节的数字,表示此消息在此 partition 中所处的起始位置。 每个partition在物理存储层面,有多个log file组成(称为segment)。segment file 的命名为 ” 最小 offset”.kafka 。 例如”00000000000.kafka”;其中”最小offset”表示此segment中起始消息的offset
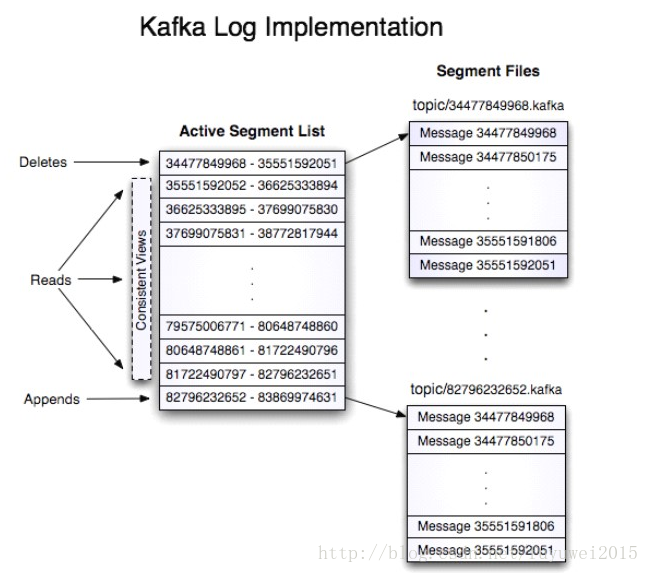
其中每个 partiton 中所持有的 segments 列表信息会存储在zookeeper中。当segment文件尺寸达到一定阀值时(可以通过配置文件设定,默认1G),将会创建一个新的文件;当buffer中消息的条数达到阀值时将会触发日志信息flush到日志文件中,同时如果”距离最近一次flush的时间差”达到阀值时,也会触发flush到日志文件。 如果broker失效,极有可能会丢失那些尚未flush到文件的消息。 因为server意外实现,仍然会导致log文件格式的破坏(文件尾部),那么就要求当server启动时需要检测最后一个segment的文件结构是否合法并进行必要的修复。获取消息时,需要指定offset和最大chunk尺寸,offset用来表示消息的起始位置,chunk size用来表示最大获取消息的总长度(间接的表示消息的条数)。 根据offset,可以找到此消息所在segment文件,然后根据segment的最小offset取差值,得到它在file中的相对位置,直接读取输出即可。日志文件的删除策略非常简单:启动一个后台线程定期扫描log file列表,把保存时间超过阀值的文件直接删除(根据文件的创建时间)。 为了避免删除文件时仍然有read操作(consumer消费),采取copy-on-write方式。
Broker node registry:
当一个kafka broker启动后,首先会向 zookeeper 注册自己的节点信息(临时 znode),同时当 broker 和zookeeper断开连接时,此znode 也会被删除。
格式:
/brokers/ids/[0。。。 N], 其中[0。。 N]表示broker id,每个 broker 的配置文件中都需要指定一个数字类型的 id(全局不可重复),znode的值为此broker的host:port信息。
Broker Topic Registry:
当一个 broker 启动时 , 会 向zookeeper注册自己持有的topic和partitions信息,仍然是一个临时znode。
格式:
/brokers/topics/[topic]/partitions/[0。。。 N] 其中[0。。 N]表示partition索引号。
Consumer and Consumer group:
每个consumer客户端被创建时,会向zookeeper注册自己的信息;此作用主要是为了”负载均衡”。一个 group 中的多个consumer 可以交错的消费一个 topic 的所有partitions;简而言之,保证此topic的所有partitions都能被此group所消费,且消费时为了性能考虑,让partition相对均衡的分散到每个consumer上。
Consumer id Registry:
每个 consumer 都有一个唯一的ID(host:uuid,可以通过配置文件指定,也可以由系统生成),此id 用来标记消费者信息。
格式:
/consumers/[group_id]/ids/[consumer_id]仍然是一个临时的 znode, 此节点的值为{“topic_name”:#streams。。。 },即表示此 consumer 目前所消费的topic + partitions列表。
Consumer offset Tracking:
用来跟踪每个 consumer 目前所消费的partition中最大的offset。
格式:
/consumers/[group_id]/offsets/[topic]/[broker_id-partition_id]–>offset_value此znode为持久节点,可以看出offset跟group_id有关,以表明当group中一个消费者失效,其他consumer可以继续消费。
Partition Owner registry:
用来标记 partition 被哪个consumer消费。 临时znode。
格式:
/consumers/[group_id]/owners/[topic]/[broker_id-partition_id] –>consumer_node_id
当consumer启动时,所触发的操作:
1、首先进行”Consumer id Registry”;
2、然后在”Consumer id Registry”节点下注册一个 watch用来监听当前 group 中其他 consumer 的”leave”和”join”;只要此 znodepath下节点列表变更,都会触发此group下consumer的负载均衡。比如一个consumer失效,那么其他consumer接管partitions)。
3、在”Brokeridregistry”节点下,注册一个watch用来监听broker的存活情况;如果broker列表变更,将会触发所有的groups下的consumer重新balance。
4、producer端使用zookeeper用来”发现”broker列表,以及和Topic下每个partition leader 建立socket连接并发送消息。
5、Broker 端使用 zookeeper 用来注册 broker 信息,已经监测partition leader存活性。
6、Consumer 端使用 zookeeper 用来注册 consumer 信息,其中包括consumer消费的partition列表等,同时也用来发现broker列表,并和partition leader建立socket连接,并获取消息。
下篇文章我们介绍kakfa在实际生产环境中的应用实例。
参考资料:
http://kafka.apache.org/ 、《kafka学习文档》
优势
通过O(1)的磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳定性能。高吞吐量:即使是非常普通的硬件kafka也可以支持每秒数十万的消息。
支持通过kafka服务器和消费机集群来分区消息。
支持Hadoop并行数据加载。
关键词
**Broker:**Kafka 集群包含一个或多个服务器,这种服务器被称为 broker。Topic:每条发布到 Kafka 集群的消息都有一个类别,这个类别被称为 Topic。(物理上不同 Topic 的消息分开存储,逻辑上一个 Topic 的消息虽然保存于一个或多个 broker 上,但用户只需指定消息的 Topic 即可生产或消费数据而不必关心数据存于何处)。
**Partition:**Partition 是物理上的概念,每个 Topic 包含一个或多个 Partition。为了实现扩展性,一个非常大的topic可以分布到多个broker(即服务器)上。kafka只保证按一个partition中的顺序将消息发给consumer,不保证一个topic的整体(多个partition间)的顺序。
Producer:负责发布消息到 Kafka broker。
Consumer:消息消费者,向 Kafka broker 读取消息的客户端。
Consumer Group:每个 Consumer 属于一个特定的 Consumer Group(可为每个 Consumer 指定 group name,若不指定 group name 则属于默认的 group)。这是kafka用来实现一个topic消息的广播(发给所有的consumer)和单播(发给任意一个consumer)的手段。一个 topic可以有多个CG。topic的消息会复制(不是真的复制,是概念上的)到所有的CG,但每个CG只会把消息发给该CG中的一个 consumer。如果需要实现广播,只要每个consumer有一个独立的CG就可以了。要实现单播只要所有的consumer在同一个CG。用CG还 可以将consumer进行自由的分组而不需要多次发送消息到不同的topic。
交互流程
Kafka 是一个基于分布式的消息发布-订阅系统,它被设计成快速、可扩展的、持久的。与其他消息发布-订阅系统类似,Kafka 在主题当中保存消息的信息。生产者向主题写入数据,消费者从主题读取数据。由于 Kafka 的特性是支持分布式,同时也是基于分布式的,所以主题也是可以在多个节点上被分区和覆盖的。信息是一个字节数组,程序员可以在这些字节数组中存储任何对象,支持的数据格式包括 String、JSON、Avro。Kafka 通过给每一个消息绑定一个键值的方式来保证生产者可以把所有的消息发送到指定位置。属于某一个消费者群组的消费者订阅了一个主题,通过该订阅消费者可以跨节点地接收所有与该主题相关的消息,每一个消息只会发送给群组中的一个消费者,所有拥有相同键值的消息都会被确保发给这一个消费者。
Kafka 设计中将每一个主题分区当作一个具有顺序排列的日志。同处于一个分区中的消息都被设置了一个唯一的偏移量。Kafka 只会保持跟踪未读消息,一旦消息被置为已读状态,Kafka 就不会再去管理它了。Kafka 的生产者负责在消息队列中对生产出来的消息保证一定时间的占有,消费者负责追踪每一个主题 (可以理解为一个日志通道) 的消息并及时获取它们。基于这样的设计,Kafka 可以在消息队列中保存大量的开销很小的数据,并且支持大量的消费者订阅。
备份
消息以partition为单位分配到多个server,并以partition为单位进行备份。备份策略为:1个leader和N个followers,leader接受读写请求,followers被动复制leader。leader和followers会在集群中打散,保证partition高可用。kafka 将每个 partition 数据复制到多个 server 上,任何一个partition有一个leader和多个follower(可以没有);备份的个数可以通过 broker 配置文件来设定。 leader 处理所有的 read-write 请求,follower 需要和 leader 保持同步。 Follower 和 consumer 一样,消费消息并保存在本地日志中;leader 负责跟踪所有的 follower 状态,如果follower”落后”太多或者失效,leader将会把它从replicas同步列表中删除。当所有的 follower 都将一条消息保存成功,此消息才被认为是”committed”,那么此时 consumer 才能消费它。 即使只有一个 replicas 实例存活,仍然可以保证消息的正常发送和接收,只要zookeeper 集群存活即可。 (不同于其他分布式存储,比如 hbase 需要”多数派”存活才行)当leader失效时,需在followers中选取出新的leader,可能此时 follower 落后于 leader,因此需要选择一个”up-to-date”的follower。选择follower时需要兼顾一个问题,就是新leader server上所已经承载的 partition leader 的个数,如果一个 server 上有过多的 partition leader,意味着此 server 将承受着更多的IO 压力。在选举新 leader,需要考虑到”负载均衡”
可靠性
MQ要实现从producer到consumer之间的可靠的消息传送和分发。传统的MQ系统通常都是通过broker和consumer间的确认 (ack)机制实现的,并在broker保存消息分发的状态。即使这样一致性也是很难保证的(参考原文)。kafka的做法是由consumer自己保存 状态,也不要任何确认。这样虽然consumer负担更重,但其实更灵活了。因为不管consumer上任何原因导致需要重新处理消息,都可以再次从 broker获得。kafka的producer有一种异步发送的操作。这是为提高性能提供的。producer先将消息放在内存中,就返回。这样调用者(应用程序) 就不需要等网络传输结束就可以继续了。内存中的消息会在后台批量的发送到broker。由于消息会在内存呆一段时间,这段时间是有消息丢失的风险的。所以 使用该操作时需要仔细评估这一点。因此Kafka不像传统的MQ难以实现EIP,并且只有partition内的消息才能保证传递顺序。
另外,在最新的版本中,还实现了broker间的消息复制机制,去除了broker的单点故障(SPOF)。
持久性
kafka使用文件存储消息,这就直接决定kafka在性能上严重依赖文件系统的本身特性。且无论任何 OS 下,对文件系统本身的优化几乎没有可能。文件缓存/直接内存映射等是常用的手段。 因为 kafka 是对日志文件进行 append 操作,因此磁盘检索的开支是较小的;同时为了减少磁盘写入的次数,broker会将消息暂时buffer起来,当消息的个数(或尺寸)达到一定阀值时,再flush到磁盘,这样减少了磁盘IO调用的次数。性能
要考虑的影响性能点很多,除磁盘IO之外,我们还需要考虑网络IO,这直接关系到kafka的吞吐量问题。 kafka并没有提供太多高超的技巧;对于producer端,可以将消息buffer起来,当消息的条数达到一定阀值时,批量发送给broker;对于consumer端也是一样,批量fetch多条消息。 不过消息量的大小可以通过配置文件来指定。对于kafka broker端,似乎有个sendfile系统调用可以潜在的提升网络IO的性能:将文件的数据映射到系统内存中,socket直接读取相应的内存区域即可,而无需进程再次 copy 和交换。 其实对于producer/consumer/broker三者而言,CPU的开支应该都不大,因此启用消息压缩机制是一个良好的策略;压缩需要消耗少量的CPU资源,不过对于kafka而言,网络IO更应该需要考虑。可以将任何在网络上传输的消息都经过压缩。 kafka支持gzip/snappy等多种压缩方式。代码示例
producer
producer将会和Topic下所有partition leader保持socket连接;消息由producer直接通过socket发送到broker,中间不会经过任何”路由层”。事实上,消息被路由到哪个partition上,由producer客户端决定。 比如可以采用”random”“key-hash”“轮询”等,如果一个topic中有多个partitions,那么在producer端实现”消息均衡分发”是必要的。其中 partition leader的位置(host:port)注册在 zookeeper中,producer作为zookeeper的client,已经注册了watch用来监听partition leader的变更事件。异步发送: 将多条消息暂且在客户端buffer起来, 并将他们批量的发送到broker, 小数据IO太多, 会拖慢整体的网络延迟, 批量延迟发送事实上提升了网络效率。不过这也有一定的隐患,比如说当producer失效时,那些尚未发送的消息将会丢失。下面开始看下代码示例,现在pom文件中添加jar依赖
<dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka_2.10</artifactId> <version>0.10.2.0</version> </dependency> <dependency> <groupId>com.google.protobuf</groupId> <artifactId>protobuf-java</artifactId> <version>3.2.0</version> </dependency>
看下生产者的代码:
import java.util.Properties;
import scala.collection.Seq;
import kafka.producer.KeyedMessage;
import kafka.producer.Partitioner;
import kafka.producer.Producer;
import kafka.producer.ProducerConfig;
import kafka.utils.VerifiableProperties;
/**
* 消息生产者,这里先演示功能,先不讲究代码优雅性
* @author fuyuwei
* 2017年6月8日 下午9:06:30
*/
public class ProducerTest {
public static void send(){
String topic = "sunwukong";
String messageId = String.valueOf(System.currentTimeMillis());
String message = "this is a kafka test message";
Producer<String, String> producer = getConfig();
for(int i=0;i<100;i++){
Seq<KeyedMessage<String, String>> data = (Seq<KeyedMessage<String, String>>) new KeyedMessage<String,String>(topic, messageId, message);
producer.send(data);
}
}
public static Producer<String, String> getConfig(){
// 初始化producer相关配置
Properties prop = new Properties();
// 消费者获取消息元信息(topics, partitions and replicas)的地址,配置格式是:host1:port1,host2:port2,也可以在外面设置一个vip
// metadata.broker.list传入boker和分区的静态信息,这里有两台server
prop.put("metadata.broker.list", "127.0.0.1:9092,127.0.0.1:9093");
// key的序列化方式
prop.put("key.serializer.class", "kafka.serializer.StringEncoder");
// 设置分区策略,默认时取模,或者自己根据key写路由算法
prop.put("partitioner.class", "kafka.producer.DefaultPartitioner");
// 设置消息确认模式
// 0:不保证消息的到达确认,只管发送,低延迟但是会出现消息的丢失,在某个server失败的情况下,有点像TCP
// 1:发送消息,并会等待leader 收到确认后,一定的可靠性
// 2:发送消息,等待leader收到确认,并进行复制操作后,才返回,最高的可靠性
prop.put("request.required.acks", 1);
ProducerConfig config = new ProducerConfig(prop);
return new Producer<String, String>(config);
}
/**
* 根据key判断发送到哪个分区
* @author fuyuwei
* 2017年6月8日 下午10:33:22
* @param <T>
*/
public class JasonPartitioner<T> implements Partitioner {
public JasonPartitioner(VerifiableProperties verifiableProperties) {}
@Override
public int partition(Object key, int numPartitions) {
try {
int partitionNum = Integer.parseInt((String) key);
return Math.abs(Integer.parseInt((String) key) % numPartitions);
} catch (Exception e) {
return Math.abs(key.hashCode() % numPartitions);
}
}
}
}consumer
consumer 端向 broker 发送”fetch”请求,并告知其获取消息的offset;此后consumer将会获得一定条数的消息;consumer端也可以重置 offset 来重新消费消息。在 kafka 中,producers 将消息推送给broker 端, consumer 在和broker 建立连接之后,主动去 pull(或者说 fetch)消息;这中模式有些优点,首先consumer端可以根据自己的消费能力适时的去fetch消息并处理,且可以控制消息消费的进度(offset);此外,消费者可以良好的控制消息消费的数量,batch fetch。在 kafka 中,partition 中的消息只有一个 consumer 在消费,且不存在消息状态的控制,也没有复杂的消息确认机制,可见 kafkabroker 端是相当轻量级的。 当消息被 consumer 接收之后,consumer可以在本地保存最后消息的 offset,并间歇性的向 zookeeper 注册offset。 由此可见,consumer 客户端也很轻量级kafka 提供了两套 API 给 Consumer:
The high-level Consumer API
The SimpleConsumer API
第一种高度抽象的 Consumer API, 它使用起来简单、 方便,但是对于某些特殊的需求我们可能要用到第二种更底层的API。
High Level Consumer
在某些应用场景, 我们希望通过多线程读取消息, 而我们并不关心从 Kafka 消费消息的顺序,我们仅仅关心数据能被消费就行。High Level 就是用于抽象这类消费动作的。消息消费以 Consumer Group 为单位,每个 Consumer Group 中可以有多个 consumer, 每个 consumer 是一个线程, topic 的每个
partition 同时只能被某一个 consumer 读取, Consumer Group对应的每个 partition 都有一个最新的 offset 的值,存储在zookeeper 上的。所以不会出现重复消费的情况。High Level Consumer 可以并且应该被使用在多线程的环境,线程模型中线程的数量(也代表group中consumer的数量)和topic的
partition数量有关,下面列举一些规则:
1、当提供的线程数量多于partition的数量,则部分线程将不会接收到消息;
2、当提供的线程数量少于partition的数量,则部分线程将从多个partition接收消息;
3、当某个线程从多个partition 接收消息时,不保证接收消息的顺序;可能出现从partition3接收5条消息,从partition4接收6条消息,接着又从partition3接收10条消息;
4、当添加更多线程时,会引起kafka做re-balance, 可能改变partition和线程的对应关系
high level Consumer消费者代码如下
package com.swk.kafka;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Properties;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import kafka.consumer.ConsumerConfig;
import kafka.consumer.ConsumerIterator;
import kafka.consumer.KafkaStream;
import kafka.javaapi.consumer.ConsumerConnector;
public class ConsumerGroupTest{
public ConsumerConnector consumer;
public String topic;
public ExecutorService executor;
public ConsumerGroupTest(String a_zookeeper, String a_groupId,
String a_topic) {
consumer = kafka.consumer.Consumer.createJavaConsumerConnector(createConsumerConfig(a_zookeeper,a_groupId));
this.topic = a_topic;
}
public void shutdown() {
if (consumer != null)
consumer.shutdown();
if (executor != null)
executor.shutdown();
}
public void run(int a_numThreads) {
Map<String, Integer> topicCountMap = new HashMap<String, Integer>();
topicCountMap.put(topic, new Integer(a_numThreads));
Map<String, List<KafkaStream<byte[], byte[]>>> consumerMap = consumer.createMessageStreams(topicCountMap);
List<KafkaStream<byte[], byte[]>> streams = consumerMap.get(topic);
// 启动一个固定线程数的线程池
executor = Executors.newFixedThreadPool(a_numThreads);
int threadNumber = 0;
for (final KafkaStream<byte[], byte[]> stream : streams) {
executor.submit(new ConsumerTest(stream, threadNumber));
threadNumber++;
}
}
private ConsumerConfig createConsumerConfig(String a_zookeeper,
String a_groupId) {
Properties props = new Properties();
// 对于zookeeper集群的指定,可以是多个 hostname1:port1,hostname2:port2,hostname3:port3 必须和broker使用同样的zk配置
props.put("zookeeper.connect", a_zookeeper);
// Consumer归属的组ID,broker是根据group.id来判断是队列模式还是发布订阅模式,非常重要
props.put("group.id", a_groupId);
// zookeeper的心跳超时时间,查过这个时间就认为是dead消费者
props.put("zookeeper.session.timeout.ms", "400");
// zookeeper的follower同leader的同步时间
props.put("zookeeper.sync.time.ms", "200");
// 是否在消费消息后将offset同步到zookeeper,当Consumer失败后就能从zookeeper获取最新的offset
props.put("auto.commit.interval.ms", "1000");
return new ConsumerConfig(props);
}
public static void main(String[] args) {
String zooKeeper = args[0];
String groupId = args[1];
String topic = args[2];
int threads = Integer.parseInt(args[3]);
ConsumerGroupTest example = new ConsumerGroupTest(zooKeeper, groupId,
topic);
example.run(threads);
try {
Thread.sleep(10000);
} catch (InterruptedException ie) {
}
example.shutdown();
}
public class ConsumerTest implements Runnable {
private KafkaStream<byte[], byte[]> m_stream;
private int m_threadNumber;
public ConsumerTest(KafkaStream<byte[], byte[]> a_stream, int a_threadNumber) {
m_threadNumber = a_threadNumber;
m_stream = a_stream;
}
public void run() {
ConsumerIterator<byte[], byte[]> it = m_stream.iterator();
while (it.hasNext())
System.out.println("Thread " + m_threadNumber + ": "
+ new String(it.next().message()));
System.out.println("Shutting down Thread: " + m_threadNumber);
}
}
}The SimpleConsumer API
作用:
1、一个消息读取多次
2、在一个处理过程中只消费 Partition 其中的一部分消息
3、添加事务管理机制以保证消息被处理且仅被处理一次
缺点:
1、必须在程序中跟踪 offset 值
2、必须找出指定 Topic Partition 中的 lead broker
3、必须处理 broker 的变动
使用步骤:
1、从所有活跃的 broker 中找出哪个是指定 Topic Partition中的 leader broker
2、找出指定 Topic Partition 中的所有备份 broker
3、构造请求
4、发送请求查询数据
5、处理 leader broker 变
代码如下:
package com.swk.kafka;
import kafka.api.FetchRequest;
import kafka.api.FetchRequestBuilder;
import kafka.api.PartitionOffsetRequestInfo;
import kafka.cluster.BrokerEndPoint;
import kafka.common.ErrorMapping;
import kafka.common.TopicAndPartition;
import kafka.javaapi.FetchResponse;
import kafka.javaapi.OffsetResponse;
import kafka.javaapi.PartitionMetadata;
import kafka.javaapi.TopicMetadata;
import kafka.javaapi.TopicMetadataRequest;
import kafka.javaapi.consumer.SimpleConsumer;
import kafka.message.MessageAndOffset;
import java.nio.ByteBuffer;
import java.util.ArrayList;
import java.util.Collections;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public class SimpleConsumerTest {
public static void main(String args[]) {
SimpleConsumerTest example = new SimpleConsumerTest();
long maxReads = Long.parseLong(args[0]);
String topic = args[1];
int partition = Integer.parseInt(args[2]);
List<String> seeds = new ArrayList<String>();
seeds.add(args[3]);
int port = Integer.parseInt(args[4]);
try {
example.run(maxReads, topic, partition, seeds, port);
} catch (Exception e) {
System.out.println("Oops:" + e);
e.printStackTrace();
}
}
private List<String> m_replicaBrokers = new ArrayList<String>();
public SimpleConsumerTest() {
m_replicaBrokers = new ArrayList<String>();
}
public void run(long a_maxReads, String a_topic, int a_partition,
List<String> a_seedBrokers, int a_port) throws Exception {
// find the meta data about the topic and partition we are interested in
PartitionMetadata metadata = findLeader(a_seedBrokers, a_port, a_topic,
a_partition);
if (metadata == null) {
System.out
.println("Can't find metadata for Topic and Partition. Exiting");
return;
}
if (metadata.leader() == null) {
System.out
.println("Can't find Leader for Topic and Partition. Exiting");
return;
}
String leadBroker = metadata.leader().host();
String clientName = "Client_" + a_topic + "_" + a_partition;
SimpleConsumer consumer = new SimpleConsumer(leadBroker, a_port,
100000, 64 * 1024, clientName);
long readOffset = getLastOffset(consumer, a_topic, a_partition,
kafka.api.OffsetRequest.EarliestTime(), clientName);
int numErrors = 0;
while (a_maxReads > 0) {
if (consumer == null) {
consumer = new SimpleConsumer(leadBroker, a_port, 100000,
64 * 1024, clientName);
}
FetchRequest req = new FetchRequestBuilder().clientId(clientName)
.addFetch(a_topic, a_partition, readOffset, 100000).build();
// Note: this fetchSize of 100000 might need to be increased if
// large batchesare written to Kafka
FetchResponse fetchResponse = consumer.fetch(req);
if (fetchResponse.hasError()) {
numErrors++;
// Something went wrong!
short code = fetchResponse.errorCode(a_topic, a_partition);
System.out.println("Error fetching data from the Broker:"
+ leadBroker + " Reason: " + code);
if (numErrors > 5)
break;
if (code == ErrorMapping.OffsetOutOfRangeCode()) {
// We asked for an invalid offset. For simple case ask for
// the last element to reset
readOffset = getLastOffset(consumer, a_topic, a_partition,
kafka.api.OffsetRequest.LatestTime(), clientName);
continue;
}
consumer.close();
consumer = null;
leadBroker = findNewLeader(leadBroker, a_topic, a_partition,
a_port);
continue;
}
numErrors = 0;
long numRead = 0;
for (MessageAndOffset messageAndOffset : fetchResponse.messageSet(
a_topic, a_partition)) {
long currentOffset = messageAndOffset.offset();
if (currentOffset < readOffset) {
System.out.println("Found an old offset: " + currentOffset
+ " Expecting: " + readOffset);
continue;
}
readOffset = messageAndOffset.nextOffset();
ByteBuffer payload = messageAndOffset.message().payload();
byte[] bytes = new byte[payload.limit()];
payload.get(bytes);
System.out.println(String.valueOf(messageAndOffset.offset())
+ ": " + new String(bytes, "UTF-8"));
numRead++;
a_maxReads--;
}
if (numRead == 0) {
try {
Thread.sleep(1000);
} catch (InterruptedException ie) {
}
}
}
if (consumer != null)
consumer.close();
}
public static long getLastOffset(SimpleConsumer consumer, String topic,
int partition, long whichTime, String clientName) {
TopicAndPartition topicAndPartition = new TopicAndPartition(topic,
partition);
Map<TopicAndPartition, PartitionOffsetRequestInfo> requestInfo = new HashMap<TopicAndPartition, PartitionOffsetRequestInfo>();
requestInfo.put(topicAndPartition, new PartitionOffsetRequestInfo(
whichTime, 1));
kafka.javaapi.OffsetRequest request = new kafka.javaapi.OffsetRequest(
requestInfo, kafka.api.OffsetRequest.CurrentVersion(),
clientName);
OffsetResponse response = consumer.getOffsetsBefore(request);
if (response.hasError()) {
System.out
.println("Error fetching data Offset Data the Broker. Reason: "
+ response.errorCode(topic, partition));
return 0;
}
long[] offsets = response.offsets(topic, partition);
return offsets[0];
}
private String findNewLeader(String a_oldLeader, String a_topic,
int a_partition, int a_port) throws Exception {
for (int i = 0; i < 3; i++) {
boolean goToSleep = false;
PartitionMetadata metadata = findLeader(m_replicaBrokers, a_port,
a_topic, a_partition);
if (metadata == null) {
goToSleep = true;
} else if (metadata.leader() == null) {
goToSleep = true;
} else if (a_oldLeader.equalsIgnoreCase(metadata.leader().host())
&& i == 0) {
// first time through if the leader hasn't changed give
// ZooKeeper a second to recover
// second time, assume the broker did recover before failover,
// or it was a non-Broker issue
goToSleep = true;
} else {
return metadata.leader().host();
}
if (goToSleep) {
try {
Thread.sleep(1000);
} catch (InterruptedException ie) {
}
}
}
System.out
.println("Unable to find new leader after Broker failure. Exiting");
throw new Exception(
"Unable to find new leader after Broker failure. Exiting");
}
private PartitionMetadata findLeader(List<String> a_seedBrokers,
int a_port, String a_topic, int a_partition) {
PartitionMetadata returnMetaData = null;
loop: for (String seed : a_seedBrokers) {
SimpleConsumer consumer = null;
try {
consumer = new SimpleConsumer(seed, a_port, 100000, 64 * 1024,
"leaderLookup");
List<String> topics = Collections.singletonList(a_topic);
TopicMetadataRequest req = new TopicMetadataRequest(topics);
kafka.javaapi.TopicMetadataResponse resp = consumer.send(req);
List<TopicMetadata> metaData = resp.topicsMetadata();
for (TopicMetadata item : metaData) {
for (PartitionMetadata part : item.partitionsMetadata()) {
if (part.partitionId() == a_partition) {
returnMetaData = part;
break loop;
}
}
}
} catch (Exception e) {
System.out.println("Error communicating with Broker [" + seed
+ "] to find Leader for [" + a_topic + ", "
+ a_partition + "] Reason: " + e);
} finally {
if (consumer != null)
consumer.close();
}
}
if (returnMetaData != null) {
m_replicaBrokers.clear();
for (BrokerEndPoint replica : returnMetaData.replicas()) {
m_replicaBrokers.add(replica.host());
}
}
return returnMetaData;
}
}消息的传输机制
于 JMS 实现,消息传输担保非常直接:有且只有一次(exactly once)。 在 kafka 中稍有不同:1、at most once: 最多一次,发送一次,无论成败,将不会重发。 消费者 fetch 消息,然后保存 offset,然后处理消息;当 client 保存offset之后,但是在消息处理过程中出现了异常,导致部分消息未能继续处理。那么此后”未处理”的消息将不能被fetch 到,这就是”at most once”。
2、at least once: 消息至少发送一次,如果消息未能接受成功,可能会重发,直到接收成功。消费者 fetch 消息,然后处理消息,然后保存 offset。如果消息处理成功之后,但是在保存 offset 阶段zookeeper异常导致保存操作未能执行成功,这就导致接下来再次fetch时可能获得上次已经处理过的消息,这就是”at least
once”, 原因 offset 没有及时的提交给zookeeper, zookeeper 恢复正常还是之前offset 状态。
3、exactly once: 消息只会发送一次。 kafka 中并没有严格的去实现(基于 2 阶段提交,事务),我们认为这种策略在 kafka 中是没有
必要的。通常情况下”at-least-once”是我们首选。 (相比 at most once而言,重复接收数据总比丢失数据要好)
日志
如果一个 topic 的名称为”my_topic”,它有 2 个 partitions,那么日志将会保存在 my_topic_0 和 my_topic_1两个目录中;日志文件中保存了一序列”logentries”(日志条目),每个logentry格式为”4个字节的数字N表示消息的长度” + “N个字节的消息内容”;每个日志都有一个offset来唯一的标记一条消息,offset的值为8个字节的数字,表示此消息在此 partition 中所处的起始位置。 每个partition在物理存储层面,有多个log file组成(称为segment)。segment file 的命名为 ” 最小 offset”.kafka 。 例如”00000000000.kafka”;其中”最小offset”表示此segment中起始消息的offset
其中每个 partiton 中所持有的 segments 列表信息会存储在zookeeper中。当segment文件尺寸达到一定阀值时(可以通过配置文件设定,默认1G),将会创建一个新的文件;当buffer中消息的条数达到阀值时将会触发日志信息flush到日志文件中,同时如果”距离最近一次flush的时间差”达到阀值时,也会触发flush到日志文件。 如果broker失效,极有可能会丢失那些尚未flush到文件的消息。 因为server意外实现,仍然会导致log文件格式的破坏(文件尾部),那么就要求当server启动时需要检测最后一个segment的文件结构是否合法并进行必要的修复。获取消息时,需要指定offset和最大chunk尺寸,offset用来表示消息的起始位置,chunk size用来表示最大获取消息的总长度(间接的表示消息的条数)。 根据offset,可以找到此消息所在segment文件,然后根据segment的最小offset取差值,得到它在file中的相对位置,直接读取输出即可。日志文件的删除策略非常简单:启动一个后台线程定期扫描log file列表,把保存时间超过阀值的文件直接删除(根据文件的创建时间)。 为了避免删除文件时仍然有read操作(consumer消费),采取copy-on-write方式。
zookeeper
kafka使用zookeeper来存储一些meta信息,并使用了zookeeper watch机制来发现meta信息的变更并作出相应的动作(比如consumer失效,触发负载均衡等)Broker node registry:
当一个kafka broker启动后,首先会向 zookeeper 注册自己的节点信息(临时 znode),同时当 broker 和zookeeper断开连接时,此znode 也会被删除。
格式:
/brokers/ids/[0。。。 N], 其中[0。。 N]表示broker id,每个 broker 的配置文件中都需要指定一个数字类型的 id(全局不可重复),znode的值为此broker的host:port信息。
Broker Topic Registry:
当一个 broker 启动时 , 会 向zookeeper注册自己持有的topic和partitions信息,仍然是一个临时znode。
格式:
/brokers/topics/[topic]/partitions/[0。。。 N] 其中[0。。 N]表示partition索引号。
Consumer and Consumer group:
每个consumer客户端被创建时,会向zookeeper注册自己的信息;此作用主要是为了”负载均衡”。一个 group 中的多个consumer 可以交错的消费一个 topic 的所有partitions;简而言之,保证此topic的所有partitions都能被此group所消费,且消费时为了性能考虑,让partition相对均衡的分散到每个consumer上。
Consumer id Registry:
每个 consumer 都有一个唯一的ID(host:uuid,可以通过配置文件指定,也可以由系统生成),此id 用来标记消费者信息。
格式:
/consumers/[group_id]/ids/[consumer_id]仍然是一个临时的 znode, 此节点的值为{“topic_name”:#streams。。。 },即表示此 consumer 目前所消费的topic + partitions列表。
Consumer offset Tracking:
用来跟踪每个 consumer 目前所消费的partition中最大的offset。
格式:
/consumers/[group_id]/offsets/[topic]/[broker_id-partition_id]–>offset_value此znode为持久节点,可以看出offset跟group_id有关,以表明当group中一个消费者失效,其他consumer可以继续消费。
Partition Owner registry:
用来标记 partition 被哪个consumer消费。 临时znode。
格式:
/consumers/[group_id]/owners/[topic]/[broker_id-partition_id] –>consumer_node_id
当consumer启动时,所触发的操作:
1、首先进行”Consumer id Registry”;
2、然后在”Consumer id Registry”节点下注册一个 watch用来监听当前 group 中其他 consumer 的”leave”和”join”;只要此 znodepath下节点列表变更,都会触发此group下consumer的负载均衡。比如一个consumer失效,那么其他consumer接管partitions)。
3、在”Brokeridregistry”节点下,注册一个watch用来监听broker的存活情况;如果broker列表变更,将会触发所有的groups下的consumer重新balance。
4、producer端使用zookeeper用来”发现”broker列表,以及和Topic下每个partition leader 建立socket连接并发送消息。
5、Broker 端使用 zookeeper 用来注册 broker 信息,已经监测partition leader存活性。
6、Consumer 端使用 zookeeper 用来注册 consumer 信息,其中包括consumer消费的partition列表等,同时也用来发现broker列表,并和partition leader建立socket连接,并获取消息。
下篇文章我们介绍kakfa在实际生产环境中的应用实例。
参考资料:
http://kafka.apache.org/ 、《kafka学习文档》

相关文章推荐
- 遗传算法与直接搜索工具箱学习笔记 七-----模式搜索工作原理详解
- 学习笔记:UINavigationController使用详解
- block学习笔记——详解和使用
- Scala中隐式参数与隐式转换的联合使用实战详解及其在Spark中的应用源码解析之Scala学习笔记-51
- Android中handler的使用及原理---学习笔记
- MFC学习笔记之:ListCtrl控件使用详解
- IOS 学习笔记 —— tableView 使用详解(二)
- 学习笔记:UITabBarController使用详解
- C++学习笔记(七):string类用法及使用大全——在C++11下的使用详解
- 第97讲:使用SBT开发Akka第一个案例环境搭建详解学习笔记
- 学习笔记:UITabBarController使用详解
- FreeBSD学习笔记18-pureftpd使用详解(2)-用shell用户或虚拟用户登录pureftpd
- Liunx 命令行与shell脚本编程大全 第五章学习笔记(Vim 编辑器使用详解 解释+图示)
- ucos-ii学习笔记——消息邮箱的原理及使用
- ios 学习笔记 —— NSDate 使用详解(一)
- 树莓派学习笔记——wiringPi I2C设备使用详解
- JavaScript学习笔记8-jQuery简介、jQuery使用详解、DOM对象与jQuery对象的转换与区别
- 学习笔记:Tab Bar 控件使用详解
- 黑马程序员---struts2学习笔记之八(ognl原理及使用)
- ucos-ii学习笔记——消息队列的原理及使用