python基础之一——数据类型和内存管理
2017-06-08 10:05
525 查看
本博客所有文章仅仅是博主做笔记之用,博客内容并不详细(以后有空会修改完善),思维也有跳跃之处,想详细学习博客内容可参考文章后面的参考链接,祝学习快乐。
本节要点:
数据类型
内存管理
深浅copy
学习Python一定要记住的一点:一切皆对象!
和其他语言不同,Python所能表示的整数大小只受限于机器内存,并无固定的字节数。
bool类型
False和0表示假,其他的都为真。
浮点数
注意两点:
浮点数的精度依赖于解释器,不同的IDE下可能不同
比较两个浮点数不能用 a==b,而要用abs(a-b)<=sys.float_info.epsilon来判断。
字符串
字符串常用方法:
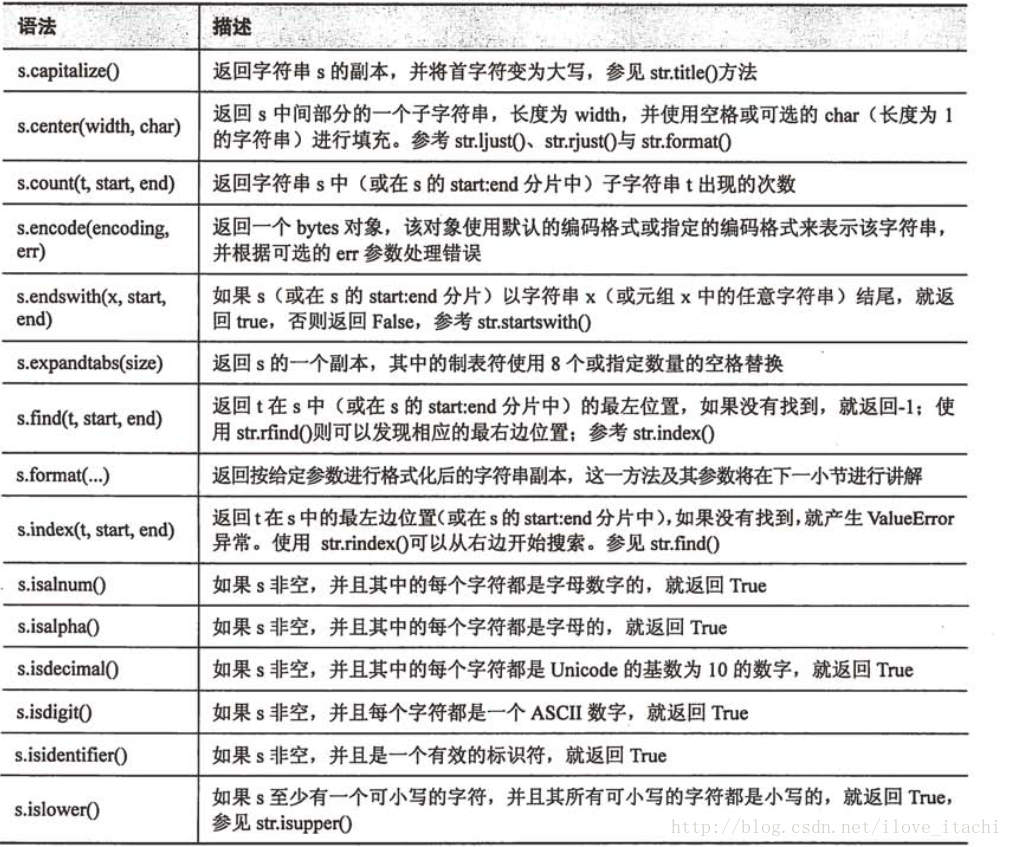


字符串格式规约

语法格式:
[fill][align][sign][#][0][width][.][.precision][type]
参数解析:
fill: any character except ‘}’, 填充字符
align: ”<“left,“ >”right, “^”center 对齐方式, “=”用于在符号与数字之间进行填充(.format(int))
sign: “+” | “-” | ” ” 数字是否带正负标识,“+”表示必须输出符号,“-”表示只输出负数符号,“ ”空格表示为正数输出空格,为负数输出“-”
#: 整数前缀为 0b, 0o, 0x
width: 最小宽度
precision: 浮点型小数位数或字符串的最大长度
type: “b” | “c” | “d” | “e” | “E” | “f” | “g” | “G” | “n” | “o” | “x” | “X” | “%” 类型
字符串格式规约是使用冒号(:)引入的,其后跟随可选的字符——一个填充字符(也可没有)与一个对齐字符(<用于左对齐,>用于右对齐,^用于中间对齐),之后跟随的是可选的最小宽度(整数),若需要指定最大宽度,就在其后使用句点,句点后跟随一个整数。
注意:如果我们指定了一个填充字符,就必须同时指定对齐字符。
列表
元组
字典
bytes和bytearray类型(Python 3新增类型)
set和frozenset
只有可哈希运算的对象才可以添加到集合中。所有内置的固定数据类型(int,str,tuple,float,frozeset)都是可哈希运算的,可以添加到集合中,内置的可变数据类型(list,dict,set)都是不可哈希运算的,因为其哈希值会随着数据项的变化而变化,所以不能添加到集合中。
Python有个特别的机制,它会在解释器启动的时候事先分配好一些缓冲区,这些缓冲区部分是固定好取值,例如整数[-5,256]的内存地址是固定的(这里的固定指这一次程序启动之后,这些数字在这个程序中的内存地址就不变了,但是启动新的python程序,两次的内存地址不一样)。
另外,Python在启动的时候还会有一块可重复利用的缓冲区。
对于列表和元组,存储的其实并不是数据项,而是每个元素的引用。
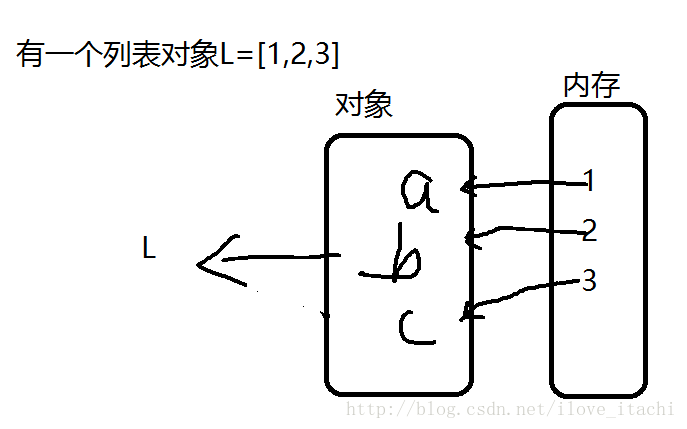
如图,对于列表,L是这个列表对象的引用,对象里面存的是每个元素的引用,而不是直接存储数据。
当把一个list变量赋值给另外一个变量时,这两个变量是等价的,它们都是原来对象的一个引用。
但是实际使用中,可能需要的是将里面的内容给复制出来到一个新的地址空间,这里可以使用python的copy模块,copy模块分为两种拷贝,一种是浅拷贝,一种是深拷贝。
二者唯一的区别在于对复合类型对象的处理上,比如列表和类实例。
假设处理一个list对象,浅拷贝调用函数copy.copy(),产生了一块新的内存来存放list中的每个元素引用,也就是说每个元素的跟原来list中元素地址是一样的。而深复制copy.deepcopy(),会开辟一块新的内存来存放复合类型。
参考资料
http://blog.csdn.net/sinat_20791575/article/details/52957758
http://www.cnblogs.com/alex3714/articles/5465198.html
http://chenrudan.github.io/blog/2016/04/23/pythonmemorycontrol.html
本节要点:
数据类型
内存管理
深浅copy
学习Python一定要记住的一点:一切皆对象!
数据类型
整数和其他语言不同,Python所能表示的整数大小只受限于机器内存,并无固定的字节数。
bool类型
False和0表示假,其他的都为真。
浮点数
注意两点:
浮点数的精度依赖于解释器,不同的IDE下可能不同
比较两个浮点数不能用 a==b,而要用abs(a-b)<=sys.float_info.epsilon来判断。
字符串
字符串常用方法:
| capitalize(...)
| S.capitalize() -> str
|
| Return a capitalized version of S, i.e. make the first character
| have upper case and the rest lower case.
|
| casefold(...)
| S.casefold() -> str
|
| Return a version of S suitable for caseless comparisons.
|
| center(...)
| S.center(width[, fillchar]) -> str
|
| Return S centered in a string of length width. Padding is
| done using the specified fill character (default is a space)
|
| count(...)
| S.count(sub[, start[, end]]) -> int
|
| Return the number of non-overlapping occurrences of substring sub in
| string S[start:end]. Optional arguments start and end are
| interpreted as in slice notation.
|
| encode(...)
| S.encode(encoding='utf-8', errors='strict') -> bytes
|
| Encode S using the codec registered for encoding. Default encoding
| is 'utf-8'. errors may be given to set a different error
| handling scheme. Default is 'strict' meaning that encoding errors raise
| a UnicodeEncodeError. Other possible values are 'ignore', 'replace' and
| 'xmlcharrefreplace' as well as any other name registered with
| codecs.register_error that can handle UnicodeEncodeErrors.
|
| endswith(...)
| S.endswith(suffix[, start[, end]]) -> bool
|
| Return True if S ends with the specified suffix, False otherwise.
| With optional start, test S beginning at that position.
| With optional end, stop comparing S at that position.
| suffix can also be a tuple of strings to try.
|
| expandtabs(...)
| S.expandtabs(tabsize=8) -> str
|
| Return a copy of S where all tab characters are expanded using spaces.
| If tabsize is not given, a tab size of 8 characters is assumed.
|
| find(...)
| S.find(sub[, start[, end]]) -> int
|
| Return the lowest index in S where substring sub is found,
| such that sub is contained within S[start:end]. Optional
| arguments start and end are interpreted as in slice notation.
|
| Return -1 on failure.
|
| format(...)
| S.format(*args, **kwargs) -> str
|
| Return a formatted version of S, using substitutions from args and kwargs.
| The substitutions are identified by braces ('{' and '}').
|
| format_map(...)
| S.format_map(mapping) -> str
|
| Return a formatted version of S, using substitutions from mapping.
| The substitutions are identified by braces ('{' and '}').
|
| index(...)
| S.index(sub[, start[, end]]) -> int
|
| Like S.find() but raise ValueError when the substring is not found.
|
| isalnum(...)
| S.isalnum() -> bool
|
| Return True if all characters in S are alphanumeric
| and there is at least one character in S, False otherwise.
|
| isalpha(...)
| S.isalpha() -> bool
|
| Return True if all characters in S are alphabetic
| and there is at least one character in S, False otherwise.
|
| isdecimal(...)
| S.isdecimal() -> bool
|
| Return True if there are only decimal characters in S,
| False otherwise.
|
| isdigit(...)
| S.isdigit() -> bool
|
| Return True if all characters in S are digits
| and there is at least one character in S, False otherwise.
|
| isidentifier(...)
| S.isidentifier() -> bool
|
| Return True if S is a valid identifier according
| to the language definition.
|
| Use keyword.iskeyword() to test for reserved identifiers
| such as "def" and "class".
|
| islower(...)
| S.islower() -> bool
|
| Return True if all cased characters in S are lowercase and there is
| at least one cased character in S, False otherwise.
|
| isnumeric(...)
| S.isnumeric() -> bool
|
| Return True if there are only numeric characters in S,
| False otherwise.
|
| isprintable(...)
| S.isprintable() -> bool
|
| Return True if all characters in S are considered
| printable in repr() or S is empty, False otherwise.
|
| isspace(...)
| S.isspace() -> bool
|
| Return True if all characters in S are whitespace
| and there is at least one character in S, False otherwise.
|
| istitle(...)
| S.istitle() -> bool
|
| Return True if S is a titlecased string and there is at least one
| character in S, i.e. upper- and titlecase characters may only
| follow uncased characters and lowercase characters only cased ones.
|
4000
Return False otherwise.
|
| isupper(...)
| S.isupper() -> bool
|
| Return True if all cased characters in S are uppercase and there is
| at least one cased character in S, False otherwise.
|
| join(...)
| S.join(iterable) -> str
|
| Return a string which is the concatenation of the strings in the
| iterable. The separator between elements is S.
|
| ljust(...)
| S.ljust(width[, fillchar]) -> str
|
| Return S left-justified in a Unicode string of length width. Padding is
| done using the specified fill character (default is a space).
|
| lower(...)
| S.lower() -> str
|
| Return a copy of the string S converted to lowercase.
|
| lstrip(...)
| S.lstrip([chars]) -> str
|
| Return a copy of the string S with leading whitespace removed.
| If chars is given and not None, remove characters in chars instead.
|
| partition(...)
| S.partition(sep) -> (head, sep, tail)
|
| Search for the separator sep in S, and return the part before it,
| the separator itself, and the part after it. If the separator is not
| found, return S and two empty strings.
|
| replace(...)
| S.replace(old, new[, count]) -> str
|
| Return a copy of S with all occurrences of substring
| old replaced by new. If the optional argument count is
| given, only the first count occurrences are replaced.
|
| rfind(...)
| S.rfind(sub[, start[, end]]) -> int
|
| Return the highest index in S where substring sub is found,
| such that sub is contained within S[start:end]. Optional
| arguments start and end are interpreted as in slice notation.
|
| Return -1 on failure.
|
| rindex(...)
| S.rindex(sub[, start[, end]]) -> int
|
| Like S.rfind() but raise ValueError when the substring is not found.
|
| rjust(...)
| S.rjust(width[, fillchar]) -> str
|
| Return S right-justified in a string of length width. Padding is
| done using the specified fill character (default is a space).
|
| rpartition(...)
| S.rpartition(sep) -> (head, sep, tail)
|
| Search for the separator sep in S, starting at the end of S, and return
| the part before it, the separator itself, and the part after it. If the
| separator is not found, return two empty strings and S.
|
| rsplit(...)
| S.rsplit(sep=None, maxsplit=-1) -> list of strings
|
| Return a list of the words in S, using sep as the
| delimiter string, starting at the end of the string and
| working to the front. If maxsplit is given, at most maxsplit
| splits are done. If sep is not specified, any whitespace string
| is a separator.
|
| rstrip(...)
| S.rstrip([chars]) -> str
|
| Return a copy of the string S with trailing whitespace removed.
| If chars is given and not None, remove characters in chars instead.
|
| split(...)
| S.split(sep=None, maxsplit=-1) -> list of strings
|
| Return a list of the words in S, using sep as the
| delimiter string. If maxsplit is given, at most maxsplit
| splits are done. If sep is not specified or is None, any
| whitespace string is a separator and empty strings are
| removed from the result.
|
| splitlines(...)
| S.splitlines([keepends]) -> list of strings
|
| Return a list of the lines in S, breaking at line boundaries.
| Line breaks are not included in the resulting list unless keepends
| is given and true.
|
| startswith(...)
| S.startswith(prefix[, start[, end]]) -> bool
|
| Return True if S starts with the specified prefix, False otherwise.
| With optional start, test S beginning at that position.
| With optional end, stop comparing S at that position.
| prefix can also be a tuple of strings to try.
|
| strip(...)
| S.strip([chars]) -> str
|
| Return a copy of the string S with leading and trailing
| whitespace removed.
| If chars is given and not None, remove characters in chars instead.
|
| swapcase(...)
| S.swapcase() -> str
|
| Return a copy of S with uppercase characters converted to lowercase
| and vice versa.
|
| title(...)
| S.title() -> str
|
| Return a titlecased version of S, i.e. words start with title case
| characters, all remaining cased characters have lower case.
|
| translate(...)
| S.translate(table) -> str
|
| Return a copy of the string S in which each character has been mapped
| through the given translation table. The table must implement
| lookup/indexing via __getitem__, for instance a dictionary or list,
| mapping Unicode ordinals to Unicode ordinals, strings, or None. If
| this operation raises LookupError, the character is left untouched.
| Characters mapped to None are deleted.
|
| upper(...)
| S.upper() -> str
|
| Return a copy of S converted to uppercase.
|
| zfill(...)
| S.zfill(width) -> str
|
| Pad a numeric string S with zeros on the left, to fill a field
| of the specified width. The string S is never truncated.字符串格式规约
语法格式:
[fill][align][sign][#][0][width][.][.precision][type]
参数解析:
fill: any character except ‘}’, 填充字符
align: ”<“left,“ >”right, “^”center 对齐方式, “=”用于在符号与数字之间进行填充(.format(int))
sign: “+” | “-” | ” ” 数字是否带正负标识,“+”表示必须输出符号,“-”表示只输出负数符号,“ ”空格表示为正数输出空格,为负数输出“-”
#: 整数前缀为 0b, 0o, 0x
width: 最小宽度
precision: 浮点型小数位数或字符串的最大长度
type: “b” | “c” | “d” | “e” | “E” | “f” | “g” | “G” | “n” | “o” | “x” | “X” | “%” 类型
字符串格式规约是使用冒号(:)引入的,其后跟随可选的字符——一个填充字符(也可没有)与一个对齐字符(<用于左对齐,>用于右对齐,^用于中间对齐),之后跟随的是可选的最小宽度(整数),若需要指定最大宽度,就在其后使用句点,句点后跟随一个整数。
注意:如果我们指定了一个填充字符,就必须同时指定对齐字符。
>>> s="Simple is better than complex."
>>> "{}".format(s) #一般格式
'Simple is better than complex.'
>>> "{:40}".format(s) #最小40个字符
'Simple is better than complex. '
>>> "{:>40}".format(s)
' Simple is better than complex.'
>>> "{:^40}".format(s)
' Simple is better than complex. '
>>> "{:-^40}".format(s)
'-----Simple is better than complex.-----'
>>> "{:.<40}".format(s) #指定了一个填充字符,就必须同时指定对齐字符。
'Simple is better than complex...........'
>>> "{:.10}".format(s) #最长10个字符
'Simple is '
>>> "{:#=40}".format("-34546")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: '=' alignment not allowed in string format specifier
>>> "{:#=40}".format(34546)
'###################################34546'
>>> "{: }".format(12345)
' 12345'
>>> "{:*^ 15}".format(1234)
'***** 1234*****'
>>> "{:*^-15}".format(1234)
'*****1234******'
>>> "{:*^-15}".format(-1234)
'*****-1234*****'
>>> "{:*^+15}".format(1234)
'*****+1234*****'
>>> "{:*^#15x}".format(1234)
'*****0x4d2*****'
>>> "{:*^#15b}".format(34)
'***0b100010****'列表
| append(...) | L.append(object) -> None -- append object to end | | clear(...) | L.clear() -> None -- remove all items from L | | copy(...) | L.copy() -> list -- a shallow copy of L | | count(...) | L.count(value) -> integer -- return number of occurrences of value | | extend(...) | L.extend(iterable) -> None -- extend list by appending elements from the iterable | | index(...) | L.index(value, [start, [stop]]) -> integer -- return first index of value. | Raises ValueError if the value is not present. | | insert(...) | L.insert(index, object) -- insert object before index | | pop(...) | L.pop([index]) -> item -- remove and return item at index (default last). | Raises IndexError if list is empty or index is out of range. | | remove(...) | L.remove(value) -> None -- remove first occurrence of value. | Raises ValueError if the value is not present. | | reverse(...) | L.reverse() -- reverse *IN PLACE* | | sort(...) | L.sort(key=None, reverse=False) -> None -- stable sort *IN PLACE*
元组
| count(...) | T.count(value) -> integer -- return number of occurrences of value | | index(...) | T.index(value, [start, [stop]]) -> integer -- return first index of value. | Raises ValueError if the value is not present.
字典
| clear(...) | D.clear() -> None. Remove all items from D. | | copy(...) | D.copy() -> a shallow copy of D | | fromkeys(iterable, value=None, /) from builtins.type | Returns a new dict with keys from iterable and values equal to value. | | get(...) | D.get(k[,d]) -> D[k] if k in D, else d. d defaults to None. | | items(...) | D.items() -> a set-like object providing a view on D's items | | keys(...) | D.keys() -> a set-like object providing a view on D's keys | | pop(...) | D.pop(k[,d]) -> v, remove specified key and return the corresponding value. | If key is not found, d is returned if given, otherwise KeyError is raised | | popitem(...) | D.popitem() -> (k, v), remove and return some (key, value) pair as a | 2-tuple; but raise KeyError if D is empty. | | setdefault(...) | D.setdefault(k[,d]) -> D.get(k,d), also set D[k]=d if k not in D | | update(...) | D.update([E, ]**F) -> None. Update D from dict/iterable E and F. | If E is present and has a .keys() method, then does: for k in E: D[k] = E[k] | If E is present and lacks a .keys() method, then does: for k, v in E: D[k] = v | In either case, this is followed by: for k in F: D[k] = F[k] | | values(...) | D.values() -> an object providing a view on D's values
bytes和bytearray类型(Python 3新增类型)
set和frozenset
只有可哈希运算的对象才可以添加到集合中。所有内置的固定数据类型(int,str,tuple,float,frozeset)都是可哈希运算的,可以添加到集合中,内置的可变数据类型(list,dict,set)都是不可哈希运算的,因为其哈希值会随着数据项的变化而变化,所以不能添加到集合中。
内存管理
再次重复开头的一句话:一切皆对象1. Python变量、对象、引用、存储
python语言是一种解释性的编程语言,在运行的过程中,逐句将指令解释成机器码,所以造就了python语言一些特别的地方。Python有个特别的机制,它会在解释器启动的时候事先分配好一些缓冲区,这些缓冲区部分是固定好取值,例如整数[-5,256]的内存地址是固定的(这里的固定指这一次程序启动之后,这些数字在这个程序中的内存地址就不变了,但是启动新的python程序,两次的内存地址不一样)。
另外,Python在启动的时候还会有一块可重复利用的缓冲区。
#固定缓冲区 >>> a=-5 >>> b=-5 >>> id(-5) 505370256 >>> id(a) 505370256 >>> id(b) 505370256 >>> c=256 >>> d=256 >>> print(id(c),id(d),id(256)) 505374432 505374432 505374432 >>> e=257 >>> f=257 >>> print(id(e),id(f),id(257)) 54155072 54155104 54155120 #可重复利用缓冲区(不同电脑,不同编译器,有可能不一样) >>> id(10000) 2660846579440 >>> id(1000010) 2660846579440 >>> id(1000) 2660846579440 >>> id(1233) 2660846579440
对于列表和元组,存储的其实并不是数据项,而是每个元素的引用。
如图,对于列表,L是这个列表对象的引用,对象里面存的是每个元素的引用,而不是直接存储数据。
当把一个list变量赋值给另外一个变量时,这两个变量是等价的,它们都是原来对象的一个引用。
>>> a=[1,2,3,[1,2]] >>> b=a >>> print(id(a),id(b)) 56164304 56164304 >>> b[1]="hello" >>> a [1, 'hello', 3, [1, 2]] >>> b [1, 'hello', 3, [1, 2]] >>> b[3].append(9) >>> a [1, 'hello', 3, [1, 2, 9]] >>> b [1, 'hello', 3, [1, 2, 9]]
但是实际使用中,可能需要的是将里面的内容给复制出来到一个新的地址空间,这里可以使用python的copy模块,copy模块分为两种拷贝,一种是浅拷贝,一种是深拷贝。
二者唯一的区别在于对复合类型对象的处理上,比如列表和类实例。
假设处理一个list对象,浅拷贝调用函数copy.copy(),产生了一块新的内存来存放list中的每个元素引用,也就是说每个元素的跟原来list中元素地址是一样的。而深复制copy.deepcopy(),会开辟一块新的内存来存放复合类型。
>>> a=[1234,"123",[1,2,899]] >>> b=copy.copy(a) >>> c=copy.deepcopy(a) >>> print(id(a),id(b),id(c)) 52773272 52624680 52625320 #这是三个不同的对象 >>> print(id(a[0]),id(b[0]),id(c[0])) 52320176 52320176 52320176 #对于简单数据类型的处理是一样的 >>> print(id(a[2]),id(b[2]),id(c[2])) 52774512 52774512 52625160 # 注意啦,区别就在这
参考资料
http://blog.csdn.net/sinat_20791575/article/details/52957758
http://www.cnblogs.com/alex3714/articles/5465198.html
http://chenrudan.github.io/blog/2016/04/23/pythonmemorycontrol.html

相关文章推荐
- J2SE基础篇——数据类型、运算符、语句、程序执行时内存分配、进制、编码
- Python基础(1):数据类型
- C#基础数据类型与字节数组(内存中的数据格式)相互转换(BitConverter 类)
- Python基础(2) - 动态数据类型
- Python的系统管理_02python和Ipython数据类型
- Python基础知识(五)--数据类型
- Python 基础编程 数据类型(一)
- C#的数据类型以及内存管理机制剖析(2)
- 闲聊之Python的数据类型 - 零基础入门学习Python005
- C#的数据类型以及内存管理机制剖析(1)
- python基础学习-1(数据类型)
- chapter1:python 基础(数据类型,运算符,常用内置函数,模型,strings等)
- 函数名function是一个数据类型,可以赋值 分类: python基础学习 2013-09-12 11:01 366人阅读 评论(0) 收藏
- python OS/pdb 模块及数据类型基础
- Python基础02 基本数据类型
- C#的数据类型以及内存管理机制剖析(2)
- python基础学习-1(数据类型)
- java 笔记(1)-—— JVM基础,内存数据,内存释放,垃圾回收,即时编译技术JIT,高精度类型
- Python基础02 基本数据类型
- Python学习入门基础教程(learning Python)--6 Python下的list数据类型