HeadFirstPython---------(三)第五章(推倒数据__处理数据)
2017-06-07 22:43
519 查看
1、str.strip(),是返回为字符串。
str.split(),返回的是列表list
readline()返回的是字符串。
readlines()返回的是字符串列表list。
任务:生成每个选手的3次最快时间。并且,当然你的输出中不该有任何重复的时间。
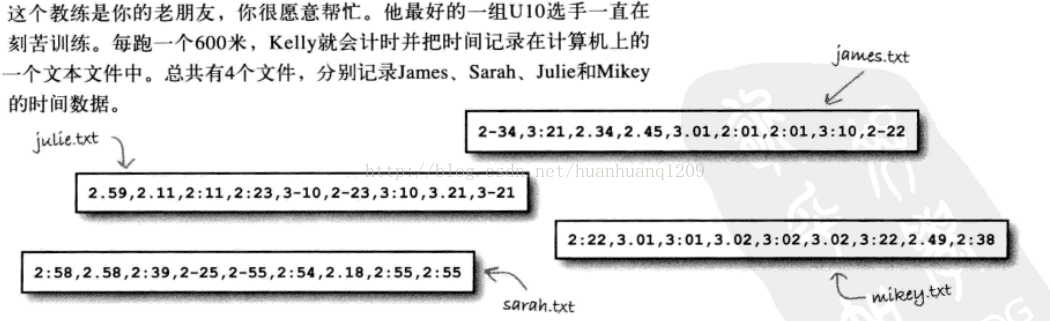

自己写的代码如下:
实验结果为:

修改后:for each_line in james_data:#each_line为2-34,3:21,2.34,2.45,3.01,2:01,2:01,3:10,2-22
if not each_line.find(",")==-1:
try:
each_line=each_line.strip();
james=each_line.split(",");#split()返回的就是列表。
#james.append(time_);
except ValueError as err:
print("Context of file is:"+str(err));
else:
continue;
实验结果为:

书给的代码:
依次打开各个数据文件,从文件读取数据行,由数据行创建一个列表。
实验结果为:

2、排序有两种方式:
原地排序:按你指定的顺序排列数据,然后用排序后的数据替换原来的数据。原来的顺序会丢失。对于列表,sort()方法会提供原地排序。
复制排序:指按你指定的顺序排列数据,然后返回原数据的一个有序副本。原数据的顺序依然保留,只是对一个副本排序。在Python中,sorted()支持复制排序。

知识:函数串链是从右往左读;方法串链是从左往右读。
函数串链:允许对数据应用一系列函数,每个函数会取得数据,对他完成某个操作,然后把转换后的数据继续向下传递到下一个函数。
从文件读入的数据会作为文本传入程序。

使用“in”操作符检查字符串是否包含一个短横线或冒号。
3、对时间数据进行的处理
sanitize1.py代码如下:
等同于:
fca2
read.py代码如下:(对数据处理,并且输出排序后的列表):

到此为止:以上代码的缺点就是,重复的代码太多。改善可以用列表推导(设计列表推导是为了减少将一个列表转为另一个列表时所需编写的代码量)。
4、

等价于下面的列表推导:



利用列表推导:代码如下:
运行结果为:

5、迭代删除重复项
任务:生成每个选手的3次最快时间。并且,当然你的输出中不该有任何重复的时间。
代码如下:

6、用集合删除重复项;
Python中集合最突出的特性是集合中的数据项是无序的,而且不允许重复。如果试图向一个集合增加一个数据项,而该集合中已经包含有这个数据项,Python就会将其忽略。
工厂函数:工厂函数用于创建某种类型 的新的数据项。在真实世界中,工厂会生产产品,这个概念因此而得名。
set()是工厂函数的一个例子;set()BIF创建一个空集合,可以一步完成集合的创建和填充,可在大括号之间提供一个数据列表,或者指定一个现有列表作为set()BIF的参数。
改善5、中的代码如下:
等价于:
7、总结:
最佳代码:(结合集合、sorted()、列表推导)
read.py中的代码如下:
get_coach_data1.py中的代码为:
str.split(),返回的是列表list
readline()返回的是字符串。
readlines()返回的是字符串列表list。
任务:生成每个选手的3次最快时间。并且,当然你的输出中不该有任何重复的时间。
自己写的代码如下:
import os
os.chdir('D:/pythontest/HeadFirstPython/chapter5/');
james=[];
julie=[];
mikey=[];
sarah=[];
try:
with open("james.txt") as james_data,open("julie.txt") as julie_data,open("mikey.txt") as mikey_data,open("sarah.txt") as sarah_data:
for each_line in james_data:
if not each_line.find(",")==-1:
try:
each_line=each_line.strip();
time_=each_line.split(",");
james.append(time_);
except ValueError as err:
print("Context of file is:"+str(err));
else:
continue;
for each_line in julie_data:
if not each_line.find(",")==-1:
try:
each_line=each_line.strip();
time_=each_line.split(",");
julie.append(time_);
except ValueError as err:
print("Context of file is:"+str(err));
else:
continue;
for each_line in mikey_data:
if not each_line.find(",")==-1:
try:
each_line=each_line.strip();
time_=each_line.split(",");
mikey.append(time_);
except ValueError as err:
print("Context of file is:"+str(err));
else:
continue;
for each_line in sarah_data:
if not each_line.find(",")==-1:
try:
each_line=each_line.strip();
time_=each_line.split(",");
sarah.append(time_);
except ValueError as err:
print("Context of file is:"+str(err));
else:
continue;
except IOError as err:
print("File error"+str(err));
print(james);
print(julie);
print(mikey);
print(sarah);实验结果为:
修改后:for each_line in james_data:#each_line为2-34,3:21,2.34,2.45,3.01,2:01,2:01,3:10,2-22
if not each_line.find(",")==-1:
try:
each_line=each_line.strip();
james=each_line.split(",");#split()返回的就是列表。
#james.append(time_);
except ValueError as err:
print("Context of file is:"+str(err));
else:
continue;
import os
os.chdir('D:/pythontest/HeadFirstPython/chapter5/');
james=[];
julie=[];
mikey=[];
sarah=[];
try:
with open("james.txt") as james_data,open("julie.txt") as julie_data,open("mikey.txt") as mikey_data,open("sarah.txt") as sarah_data:
for each_line in james_data:#each_line为2-34,3:21,2.34,2.45,3.01,2:01,2:01,3:10,2-22
if not each_line.find(",")==-1:
try:
each_line=each_line.strip();
james=each_line.split(",");#split()返回的就是列表。
#james.append(time_);
except ValueError as err:
print("Context of file is:"+str(err));
else:
continue;
for each_line in julie_data:
if not each_line.find(",")==-1:
try:
each_line=each_line.strip();
julie=each_line.split(",");
#julie.append(time_);
except ValueError as err:
print("Context of file is:"+str(err));
else:
continue;
for each_line in mikey_data:
if not each_line.find(",")==-1:
try:
each_line=each_line.strip();
mikey=each_line.split(",");
#mikey.append(time_);
except ValueError as err:
print("Context of file is:"+str(err));
else:
continue;
for each_line in sarah_data:
if not each_line.find(",")==-1:
try:
each_line=each_line.strip();
sarah=each_line.split(",");
#sarah.append(time_);
except ValueError as err:
print("Context of file is:"+str(err));
else:
continue;
except IOError as err:
print("File error"+str(err));
print(james);
print(julie);
print(mikey);
print(sarah);实验结果为:
书给的代码:
依次打开各个数据文件,从文件读取数据行,由数据行创建一个列表。
import os
os.chdir("D:/pythontest/HeadFirstPython/chapter5");
james=[];#下面4个列表的声明,可以不预先定义,并设为空列表。
julie=[];
mikey=[];
sarah=[];
try:
with open("james.txt") as jaf,open ("julie.txt") as juf,open("mikey.txt")as mif,open("sarah.txt") as saf:
data=jaf.readline();#读取数据行
james=data.strip().split(',');#将数据转换为一个列表。
data=juf.readline();
julie=data.strip().split(',');
data=mif.readline();
mikey=data.strip().split(',');
data=saf.readline();
sarah=data.strip().split(',');
except IOError as err:
print("File error"+str(err));
print(james);
print(julie);
print(mikey);
print(sarah);实验结果为:
2、排序有两种方式:
原地排序:按你指定的顺序排列数据,然后用排序后的数据替换原来的数据。原来的顺序会丢失。对于列表,sort()方法会提供原地排序。
复制排序:指按你指定的顺序排列数据,然后返回原数据的一个有序副本。原数据的顺序依然保留,只是对一个副本排序。在Python中,sorted()支持复制排序。
知识:函数串链是从右往左读;方法串链是从左往右读。
函数串链:允许对数据应用一系列函数,每个函数会取得数据,对他完成某个操作,然后把转换后的数据继续向下传递到下一个函数。
从文件读入的数据会作为文本传入程序。
使用“in”操作符检查字符串是否包含一个短横线或冒号。
3、对时间数据进行的处理
sanitize1.py代码如下:
import os
os.chdir("D:/pythontest/HeadFirstPython/chapter5");
def sanitize(time_string):
if '-' in time_string:
splitter='-';
elif ':' in time_string:
splitter=':';
else:
return(time_string);
(mins,secs)=time_string.split(splitter);
return (mins+'.'+secs);等同于:
import os
os.chdir("D:/pythontest/HeadFirstPython/chapter5");
def sanitize(time_string):#time_string是列表中的元素
if time_string.find('-')!=-1:
(mins,secs)=time_string.split('-',1);
elif time_string.find(':')!=-1:
(mins,secs)=time_string.split(':',1);
else:
return(time_string);
return (mins+'.'+secs);fca2
read.py代码如下:(对数据处理,并且输出排序后的列表):
import os
import sanitize1
os.chdir("D:/pythontest/HeadFirstPython/chapter5");
james1=[];
julie1=[];
mikey1=[];
sarah1=[];
try:
with open("james.txt") as jaf,open ("julie.txt") as juf,open("mikey.txt")as mif,open("sarah.txt") as saf:
data=jaf.readline();#读取数据行
james=data.strip().split(',');#将数据转换为一个列表。
data=juf.readline();
julie=data.strip().split(',');
data=mif.readline();
mikey=data.strip().split(',');
data=saf.readline();
sarah=data.strip().split(',');
except IOError as err:
print("File error"+str(err));
for time_string in james:
time_string=sanitize1.sanitize(time_string);
james1.append(time_string);
for time_string in julie:
time_string=sanitize1.sanitize(time_string);
julie1.append(time_string);
for time_string in mikey:
time_string=sanitize1.sanitize(time_string);
mikey1.append(time_string);
for time_string in sarah:
time_string=sanitize1.sanitize(time_string);
sarah1.append(time_string);
print(sorted(james1));
print(sorted(julie1));
print(sorted(mikey1));
print(sorted(sarah1));运行结果为:到此为止:以上代码的缺点就是,重复的代码太多。改善可以用列表推导(设计列表推导是为了减少将一个列表转为另一个列表时所需编写的代码量)。
4、
等价于下面的列表推导:
利用列表推导:代码如下:
import os
import sanitize
os.chdir("D:/pythontest/HeadFirstPython/chapter5");
try:
with open("james.txt") as jaf,open ("julie.txt") as juf,open("mikey.txt")as mif,open("sarah.txt") as saf:
data=jaf.readline();#读取数据行
james=data.strip().split(',');#将数据转换为一个列表。
data=juf.readline();
julie=data.strip().split(',');
data=mif.readline();
mikey=data.strip().split(',');
data=saf.readline();
sarah=data.strip().split(',');
except IOError as err:
print("File error"+str(err));
james1=[sanitize.sanitize(time_string) for time_string in james];
julie1=[sanitize.sanitize(time_string) for time_string in julie];
mikey1=[sanitize.sanitize(time_string) for time_string in mikey];
sarah1=[sanitize.sanitize(time_string) for time_string in sarah];
print(sorted(james1));
print(sorted(julie1));
print(sorted(mikey1));
print(sorted(sarah1));运行结果为:
5、迭代删除重复项
任务:生成每个选手的3次最快时间。并且,当然你的输出中不该有任何重复的时间。
代码如下:
import os
import sanitize
os.chdir("D:/pythontest/HeadFirstPython/chapter5");
try:
with open("james.txt") as jaf,open ("julie.txt") as juf,open("mikey.txt")as mif,open("sarah.txt") as saf:
data=jaf.readline();#读取数据行
james=data.strip().split(',');#将数据转换为一个列表。
data=juf.readline();
julie=data.strip().split(',');
data=mif.readline();
mikey=data.strip().split(',');
data=saf.readline();
sarah=data.strip().split(',');
except IOError as err:
print("File error"+str(err));
james=sorted([sanitize.sanitize(time_string) for time_string in james]);
julie=sorted([sanitize.sanitize(time_string) for time_string in julie]);
mikey=sorted([sanitize.sanitize(time_string) for time_string in mikey]);
sarah=sorted([sanitize.sanitize(time_string) for time_string in sarah]);
unique_james=[];
unique_julie=[];
unique_mikey=[];
unique_sarah=[];
for each_item in james:
if each_item not in unique_james:
unique_james.append(each_item);
#unique_james.sort(reverse=True);
for each_item in julie:
if each_item not in unique_julie:
unique_julie.append(each_item);
#unique_julie.sort(reverse=True);
for each_item in mikey:
if each_item not in unique_mikey:
unique_mikey.append(each_item);
#unique_mikey.sort(reverse=True);
for each_item in sarah:
if each_item not in unique_sarah:
unique_sarah.append(each_item);
#unique_sarah.sort(reverse=True);
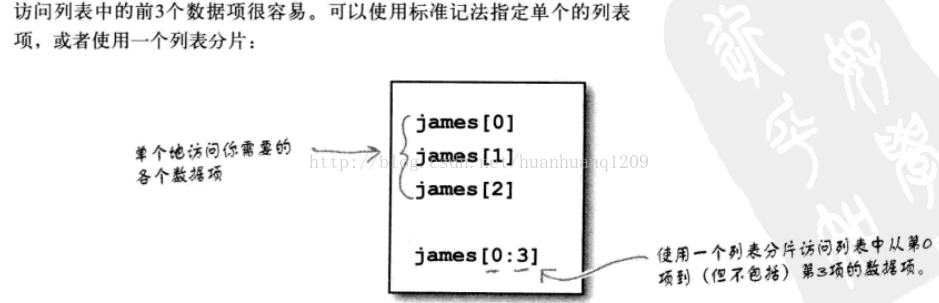
print(unique_james[0:3]);
print(unique_julie[0:3]);
print(unique_mikey[0:3]);
print(unique_sarah[0:3]);实验结果为:6、用集合删除重复项;
Python中集合最突出的特性是集合中的数据项是无序的,而且不允许重复。如果试图向一个集合增加一个数据项,而该集合中已经包含有这个数据项,Python就会将其忽略。
工厂函数:工厂函数用于创建某种类型 的新的数据项。在真实世界中,工厂会生产产品,这个概念因此而得名。
set()是工厂函数的一个例子;set()BIF创建一个空集合,可以一步完成集合的创建和填充,可在大括号之间提供一个数据列表,或者指定一个现有列表作为set()BIF的参数。
改善5、中的代码如下:
print(sorted(set(james))[0:3]); print(sorted(set(julie))[0:3]); print(sorted(set(mikey))[0:3]); print(sorted(set(sarah))[0:3]);或者用列表推导:
print(sorted(set(sorted([sanitize.sanitize(time_string) for time_string in james])))[0:3]); print(sorted(set(sorted([sanitize.sanitize(time_string) for time_string in julie])))[0:3]); print(sorted(set(sorted([sanitize.sanitize(time_string) for time_string in mikey])))[0:3]); print(sorted(set(sorted([sanitize.sanitize(time_string) for time_string in sarah])))[0:3]);
等价于:
unique_james=[]; unique_julie=[]; unique_mikey=[]; unique_sarah=[]; for each_item in james: if each_item not in unique_james: unique_james.append(each_item); #unique_james.sort(reverse=True); for each_item in julie: if each_item not in unique_julie: unique_julie.append(each_item); #unique_julie.sort(reverse=True); for each_item in mikey: if each_item not in unique_mikey: unique_mikey.append(each_item); #unique_mikey.sort(reverse=True); for each_item in sarah: if each_item not in unique_sarah: unique_sarah.append(each_item); #unique_sarah.sort(reverse=True); print(unique_james[0:3]); print(unique_julie[0:3]); print(unique_mikey[0:3]); print(unique_sarah[0:3]);
7、总结:
最佳代码:(结合集合、sorted()、列表推导)
read.py中的代码如下:
import os
import sanitize
import get_coach_data1
os.chdir("D:/pythontest/HeadFirstPython/chapter5");
try:
james=get_coach_data1.get_coach_data('james.txt');
julie=get_coach_data1.get_coach_data('julie.txt');
mikey=get_coach_data1.get_coach_data('mikey.txt');
sarah=get_coach_data1.get_coach_data('sarah.txt');
except IOError as err:
print("File error"+str(err));
print(sorted(set(sorted([sanitize.sanitize(time_string) for time_string in james])))[0:3]); print(sorted(set(sorted([sanitize.sanitize(time_string) for time_string in julie])))[0:3]); print(sorted(set(sorted([sanitize.sanitize(time_string) for time_string in mikey])))[0:3]); print(sorted(set(sorted([sanitize.sanitize(time_string) for time_string in sarah])))[0:3]);
get_coach_data1.py中的代码为:
def get_coach_data(filename):
try:
with open(filename) as f:
data=f.readline();
return(data.strip().split(','));
except IOError as ioerr:
print('File error:'+str(ioerr));
return(None);

相关文章推荐
- Python初入门(五)(Head First Python 第五章 处理数据)
- Head First Python 第二章 函数模块&第三章 文件与异常&第四章 持久存储&第五章 处理数据
- [Head First Python]5. 推导数据:处理数据
- Head Frist Python 读书笔记 第五章 处理数据
- Head First Python(管理你的数据)
- CGI-Web服务器接收并显示数据 《Head First Python》第九章
- HeadFirstPython---------(四)第六章(定制数据对象__打包代码与数据)
- 《Head_First_Python》 5推导数据
- 《Head First Programming》---python 2_文本数据
- Head First Python 学习笔记-Chapter6:自定义数据对象:字典与类
- Head First Python---------(一)第一章(初识Python__人人都爱列表)、第二章(共享你的代码__函数模块)、第三章(文件与异常__处理错误)
- HeadFirstPython---------(二)第四章,持久存储,数据保存到文件
- [Head First Python]3. 文件与异常:处理错误
- Head First Python(推导数据)
- cgi.FieldStorage()获取网页间提交的数据《Head First Python》第七章
- 《Head First Python》笔记 第六章 定制数据对象
- [Head First Python]6. 定制数据对象:打包代码与数据
- 【head First python】之递归处理嵌套列表
- Head First Python(处理复杂性)
- Head First Python ch_6 定制数据对象