使用Faster-Rcnn进行目标检测的原理
2017-06-07 15:36
537 查看
源:http://blog.csdn.net/Gavin__Zhou/article/details/52052915
Object Detection发展介绍
Faster rcnn是用来解决计算机视觉(CV)领域中
Object Detection的问题的。经典的解决方案是使用:
SS(selective search)产生
proposal,之后使用像
SVM之类的
classifier进行分类,得到所有可能的目标.
使用
SS的一个重要的弊端就是:特别耗时,而且使用像传统的
SVM之类的浅层分类器,效果不佳。
鉴于神经网络(NN)的强大的
feature extraction特征,可以将目标检测的任务放到NN上面来做,使用这一思想的目标检测的代表是:
RCNN Fast-RCNN到
Faster-RCNN YOLO等
简单点说就是:
RCNN 解决的是,“为什么不用CNN做detection呢?”
Fast-RCNN 解决的是,“为什么不一起输出bounding box和label呢?”
Faster-RCNN 解决的是,“为什么还要用selective search呢?”
Faster-Rcnn原理简介
鉴于之上的分析,想要在时间上有所突破就要在如何更快的产生proposal上做工夫。
Faster使用NN来做
region proposal,在
Fast-rcnn的基础上使用共享卷积层的方式。作者提出,卷积后的特征图同样也是可以用来生成 region proposals 的。通过增加两个卷积层来实现
Region Proposal Networks (RPNs), 一个用来将每个特征图 的位置编码成一个向量,另一个则是对每一个位置输出一个 objectness score 和 regressed bounds for
k region proposals.
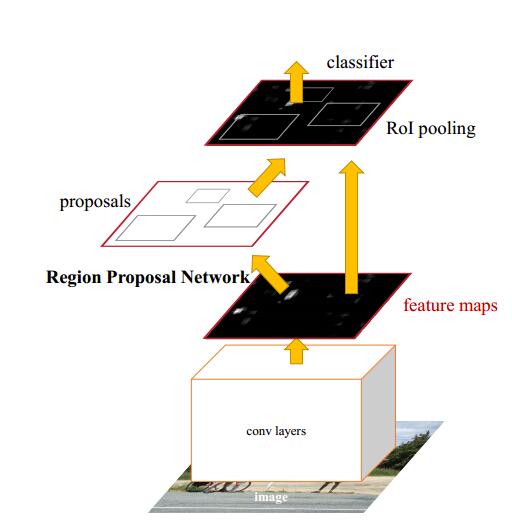
RPN
RPN的作用有以下几个:
(1) 输出proposal的位置(坐标)和score
(2) 将不同scale和ratio的proposal映射为低维的feature vector
(3) 输出是否是前景的classification和进行位置的regression
这里论文提到了一个叫做
Anchor的概念,作者给出的定义是:
The k proposals are parameterized relative to k reference boxes, which we call anchors
我的理解是:不同ratio和scale的box集合就是anchor, 对最后一层卷积生成的feature map将其分为n*n的区域,进行不同ratio和scale的采样.
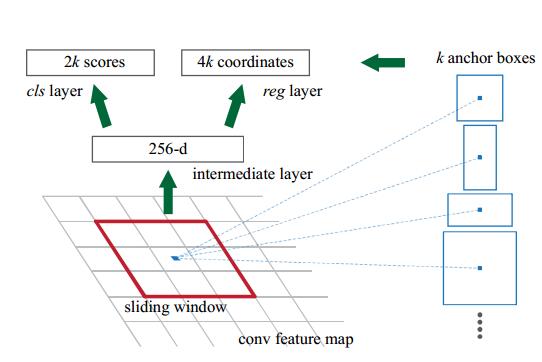
RPN的cls和reg
RPN输出对于某个proposal,其是属于前景或者背景的概率(0 or 1),具体的标准论文里给出的是:和所有的ground-truth的IoU(Intersection-over-union)小于0.3视为negative(背景)
和任意的ground-truth的IoU大于0.7视为positive(前景)
不属于以上两种情况的proposal直接丢掉,不进行训练使用
对于regression,作用是进行proposal位置的修正:
学习k个bounding-box-regressors
每个regresso负责一个scale和ratio的proposal,k个regressor之间不共享权值
RPN Training
两种训练方式:joint training和
alternating training
两种训练的方式都是在预先训练好的model上进行fine-tunning,比如使用VGG16、ZF等,对于新加的layer初始化使用random initiation,使用SGD和BP在caffe上进行训练
alternating training
首先训练RPN, 之后使用RPN产生的proposal来训练Fast-RCNN, 使用被Fast-RCNN tuned的网络初始化RPN,如此交替进行joint training
首先产生region proposal,之后直接使用产生的proposal训练Faster-RCNN,对于BP过程,共享的层需要combine RPN loss和Faster-RCNN lossResult
结果自然不用说,肯定是state-of-art,大家自己感受下吧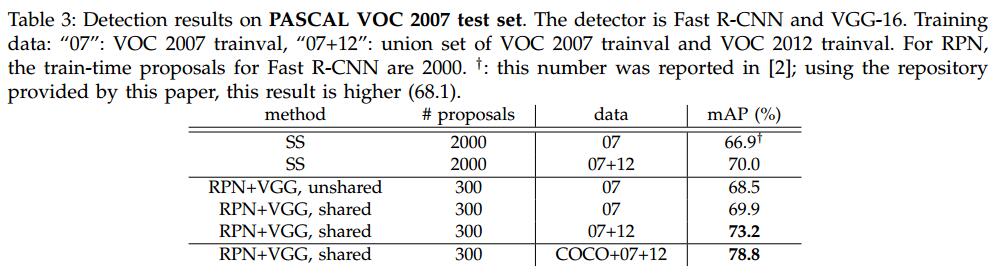

相关文章推荐
- 使用Faster-Rcnn进行目标检测的原理
- 使用Faster-Rcnn进行目标检测的原理
- 使用Faster-Rcnn进行目标检测的原理
- 使用Faster-Rcnn进行目标检测的原理
- 使用Faster-Rcnn进行目标检测的原理
- 使用Faster-Rcnn进行目标检测的原理
- 使用Faster-Rcnn进行目标检测的原理
- 使用Faster-Rcnn进行目标检测的原理
- 使用Faster-Rcnn进行目标检测的原理
- 使用Faster-Rcnn进行目标检测的原理
- Caffe学习系列——6使用Faster-RCNN进行目标检测
- 深度学习笔记之使用Faster-Rcnn进行目标检测 (原理篇)
- 深度学习笔记之使用Faster-Rcnn进行目标检测 (实践篇)
- 使用Faster-Rcnn进行目标检测(实践篇)
- 使用Faster-Rcnn进行目标检测(实践篇)
- 使用Faster-Rcnn进行目标检测(实践篇)
- 深度学习笔记之使用Faster-Rcnn进行目标检测 (实践篇)
- 使用Faster-Rcnn进行目标检测
- 使用Faster-Rcnn进行目标检测
- 使用Faster-Rcnn进行目标检测(实践篇)