Mel-Filter banks/MFCC特征提取(基于python)
2017-06-07 10:38
369 查看
最近开始上手语音相关的课题,第一步当然是了解并提取语音相关的特征及其提取,纵览paper,使用最多的莫过于Filter banks和MFCC了,因此就开始上手自己编写代码提取。(当然不是白手起家,参考在http://haythamfayek.com/2016/04/21/speech-processing-for-machine-learning.html)
1.概述
Filter banks和MFCC语音特征提取,整体是相似的,MFCC只是多了一步DCT(离散余弦变换)罢了。整体过程主要包含以下步骤:
1)预加重,作用就是为了消除发声过程中,声带和嘴唇造成的效应,来补偿语音信号受到发音系统所压抑的高频部分。并且能突显
高频的共振峰。(参考博客,自己没太理解,而且不同博客有不同的解释,暂且放在这)
2)分帧,将语音信号分为帧,通常帧长=20~40ms,帧移=10ms(具体视情况而定)
3)加窗,对每帧信号加一个hamming/hanning窗,使每帧信号两端衰减至接近0
4)STFT,得到向量特征,并将能量(幅值)谱转化为功率谱(通过平方)
5)Mel滤波,通过Mel滤波器组进行滤波,以得到符合人耳听觉习惯的声谱,最后通常取对数将单位转换成db
6)DCT,离散余弦变换,得到倒谱系数,也就是MFCC,通常保留1~13维,然后可以加上delta,delat-delta,和每帧能量
2.操作
具体操作请参看外文博客(不是我要吐槽,很多中文博客是个坑呀, 复制黏贴个公式,然后瞎解释)。我再这里主要给出几点注意事项以及原文没有的内容。
1.原文中使用的Mel滤波器组,其赋值是一样的,都是1,并不随宽的增加而改变,这样就导致了三角形的面积变化;所以还有一种Mel滤波器的设计就是随着宽的增加而改变高度,保证其面积不变,公式如下:
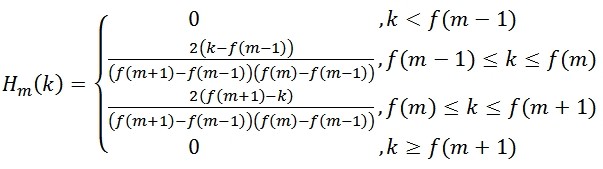
式中m代表第m个滤波器;k代表横轴坐标,也就是自变量;f(m)代表第m个滤波器的中心点的横坐标值。其效果图如下:
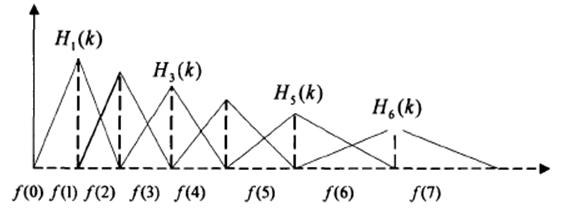
2.在HTK(C/C++版的语言处理库)中,预处理的过程是先分帧,再进行减均值(最后还是一样的有一次减均值操作)、预加重、加窗,和这里的区别主要在于初始的减均值操作,感兴趣的高人可以自行实验一下,时间关系就不多做测试了。(测试结果,视觉效果并不明显,没有什么差别)
3.求差分(相对时间,也就是帧的差分)。吐槽一下,看到好几篇博客人与亦云的写成了相对特征阶数求差分,而且分母还加了根号(真是看见平方和就想加根号,看见女人就想上呀),然后我还屁颠屁颠的实践了一下,真是吐出一口老血。主要公式如下:
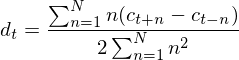
式中t就代表帧,至于首尾几帧的处理就见仁见智了。
4.郑重提示:自己编程熟悉熟悉练练手就行了,真想上手用来做课题,还是用现成库靠谱,速度快不说,还经受了时间的检验,因此放上python上的语音处理库:librosa
1.概述
Filter banks和MFCC语音特征提取,整体是相似的,MFCC只是多了一步DCT(离散余弦变换)罢了。整体过程主要包含以下步骤:
1)预加重,作用就是为了消除发声过程中,声带和嘴唇造成的效应,来补偿语音信号受到发音系统所压抑的高频部分。并且能突显
高频的共振峰。(参考博客,自己没太理解,而且不同博客有不同的解释,暂且放在这)
2)分帧,将语音信号分为帧,通常帧长=20~40ms,帧移=10ms(具体视情况而定)
3)加窗,对每帧信号加一个hamming/hanning窗,使每帧信号两端衰减至接近0
4)STFT,得到向量特征,并将能量(幅值)谱转化为功率谱(通过平方)
5)Mel滤波,通过Mel滤波器组进行滤波,以得到符合人耳听觉习惯的声谱,最后通常取对数将单位转换成db
6)DCT,离散余弦变换,得到倒谱系数,也就是MFCC,通常保留1~13维,然后可以加上delta,delat-delta,和每帧能量
2.操作
具体操作请参看外文博客(不是我要吐槽,很多中文博客是个坑呀, 复制黏贴个公式,然后瞎解释)。我再这里主要给出几点注意事项以及原文没有的内容。
1.原文中使用的Mel滤波器组,其赋值是一样的,都是1,并不随宽的增加而改变,这样就导致了三角形的面积变化;所以还有一种Mel滤波器的设计就是随着宽的增加而改变高度,保证其面积不变,公式如下:
式中m代表第m个滤波器;k代表横轴坐标,也就是自变量;f(m)代表第m个滤波器的中心点的横坐标值。其效果图如下:
2.在HTK(C/C++版的语言处理库)中,预处理的过程是先分帧,再进行减均值(最后还是一样的有一次减均值操作)、预加重、加窗,和这里的区别主要在于初始的减均值操作,感兴趣的高人可以自行实验一下,时间关系就不多做测试了。(测试结果,视觉效果并不明显,没有什么差别)
3.求差分(相对时间,也就是帧的差分)。吐槽一下,看到好几篇博客人与亦云的写成了相对特征阶数求差分,而且分母还加了根号(真是看见平方和就想加根号,看见女人就想上呀),然后我还屁颠屁颠的实践了一下,真是吐出一口老血。主要公式如下:
式中t就代表帧,至于首尾几帧的处理就见仁见智了。
4.郑重提示:自己编程熟悉熟悉练练手就行了,真想上手用来做课题,还是用现成库靠谱,速度快不说,还经受了时间的检验,因此放上python上的语音处理库:librosa

相关文章推荐
- 短文本分析----基于python的TF-IDF特征词标签自动化提取
- 基于Python的卷积神经网络和特征提取
- 短文本分析----基于python的TF-IDF特征词标签自动化提取
- 基于Python的卷积神经网络和特征提取
- opencv教程(基于python)----图象的特征与提取
- 基于Python的卷积神经网络和特征提取
- 基于ORB特征提取算法图像匹配 python实现
- 基于python 的分类算法模板 -- 数据库索引、特征提取、分类、分类结果查看
- 短文本分析----基于python的TF-IDF特征词标签自动化提取
- 基于Python的卷积神经网络和特征提取
- OpenCV Using Python——基于SURF特征提取和金字塔LK光流法的单目视觉三维重建
- 基于Python的卷积神经网络和特征提取(Theano)
- 语音信号MFCC的特征提取Matlab源码
- 基于PCA的人脸特征提取1
- MFCC特征提取详细计算过程
- OpenCV Using Python——调整基于HAAR特征的AdaBoost级联分类器的物体识别的参数
- 用python进行图片处理和特征提取
- 语音信号MFCC的特征提取Matlab源码
- MFCC特征提取(C语言版本)
- 【分享】基于Gabor特征提取和人工智能神经网络的人脸检测matlab代码