ITSM运维监控解决方案介绍和运维系统需求
2017-06-06 10:17
477 查看
一、日常巡检
1、每个维护点按天进行日常巡检,巡检内容按基础巡检表单进行填写。巡检表单在系统中可以按维护点维护内容不同进行灵活配置。
2、巡检预警:每天各维护点定时巡检时间点,超过时间点巡检内容没有上传时则关闭当天的上传功能,将没有上传的信息通知相关主管,并做为维护点当天考核内容进行考核。
3、月度服务总结报表:配置月度服务表单,维护点按时间点填写月度服务总结报表单。可以按月度报表生成对维护点及维护人员的当月考核结果。
4、维护表单统计功能:各维护点的维护表单按月进行统计分析,做为对维护人员当月的考核分析。
二、故障处理
1、故障提交:系统发生故障后维护人员根据故障表单及时填写故障表单内容,提交服务支持中心,并能够提示相应的人员。
2、故障分析:服务中心接到提交的问题单,要组织相应人员对问题单中描述的问题进行分析研判,确定问题的类型(技术问题、业务问题或者操作问题)。属于技术问题,提交服务中心技术人员对存在的问题提出具体的处理意见和建议;属于业务问题,提交服务中心业务员进行处理;属于操作问题,可安排相关人员对问题提出人进行解释,并将系统缺陷类问题提交单转为系统咨询类问题提交单。
3、故障确认、解决:服务中心的技术人员和业务人员收到系统缺陷类问题提交单后,对提交的问题进行归类汇总和分析、确认。可以解决的,明确问题解决的具体处理建议和措施,经主管领导签字同意后,交实施人员进行解决方案的实施。服务人员确认是否解决,并将解决方法提交至知识库模块。
4、故障回复:问题解决后及时向问题提交单位或问题交办单位作出回复,并将分析过程和问题产生原因一并提交。
三、设备资源管理
针对中心设备资源进行账目管理,包括计算机设备、网络设备、一卡通终端设备、耗材、配件等,包括编码、名称、位置、负责人、采购日期、登记时间、安装使用时间、状态等。——it资产管理
四、知识库
运维知识库是IT服务商进行运维工作的重要资源。故障处理后所有的解决方式必须提交至知识库中。——统一信息共享平台
五、绩效管理
自动从服务过程中采集绩效数据,可帮助管理者可从以下几个方面进行人员绩效分析:其一、分析对象从项目、部门、岗位到个人;其二、考核指标从满意度、工作量。
直接上干货《IT运维监控解决方案介绍》
现状
•小公司/ 创业团队< 500台服务器规模
开源方案:Zabbix、Nagios、Cacti…
云服务提供商:监控宝、oneAlert等
•BAT级别> 10万台服务器
投入大量的人力,内部自研,与业务严重耦合没法作为产品推出
•中间阶层
无从可选
早期,选用Zabbix
•Zabbix是一款开源的企业级监控系统
•对其进行二次开发、封装、调优...
•为什么选择Zabbix
•Cacti
•Collectd
•RRDtool
•Nagios
•openTSDB
Zabbix实践思路
•测试ZabbixNode
•Zabbix代码优化
•使用模式优化
•独立部署多套Zabbix,通过API整合
Zabbix遇到的问题
•随着公司业务规模的快速发展
•用户“使用效率”低下,学习成本很高
•不具备水平扩展能力,无法支撑业务需求
•告警策略的维护、变更代价太大,导致运维人员深陷其中,无法自拔
•不利于自动化,不利于与运维平台等基础设施整合
------------------------------------------------------------------------------------------------
Open-Falcon
Open-Falcon是小米运维团队设计开发的一款互联网企业级监控系统
•提供最好用、最人性化的互联网企业级监控解决方案
•项目主页:http://open-falcon.com
•Github: https://github.com/xiaomi/open-falcon
•QQ讨论组:373249123
•微信公众号:OpenFalcon
社区贡献
•交换机监控
•https://github.com/gaochao1/swcollector
•Windows监控
https://github.com/freedomkk-qfeng/falcon-scripts/tree/master/windows_collect
•Agent宕机监控
https://github.com/freedomkk-qfeng/falcon-scripts/tree/master/agent_monitor
•Redis/memcached/rabbitmq监控
https://github.com/iambocai/falcon-monit-scripts
•MySQL 监控方案
https://github.com/open-falcon/mymon
典型案例
美团
•生产环境广泛应用,1万+agent
•集成服务树、支持ping监控、多机房架构支持、报警第二接收人支持
•正在开发openTSDB接口、query增加正则功能
赶集
•深度定制,用于大数据部门平台服务监控与自动运维,生产环境已上线
京东金融
•深度调研open-falcon
•正在开发测试drrs(一种分布式的time series data 存储组件)并适配falcon
内部
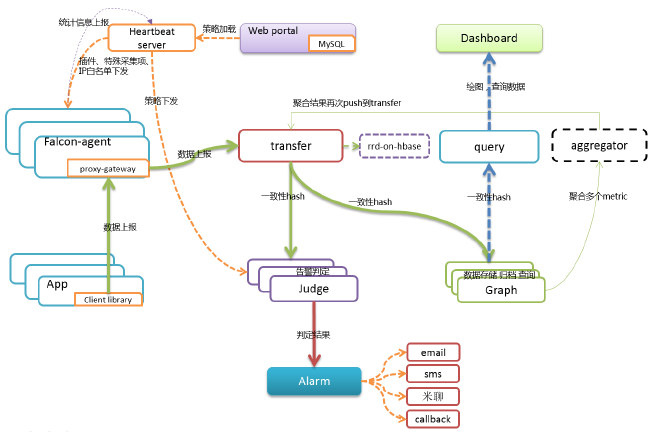
agent
•负责机器数据采集
•自发现各项监控指标
•发送数据给transfer
•发送心跳信息给hbs
•执行自定义插件
•业务数据不要用插件采集!
•数据收集采用推还是拉的方式?
transfer
•对接收到的数据做合法性校验
•转发数据给graph和judge
•为什么要做这个统一的接入端?
•为什么要对数据做分片?
•数据分片方案,用一致性hash还是路由表?
judge
•对接收到的数据按照阈值进行判定
•达到阈值的数据产生相应的event
•触发式判定or 轮询?
•为什么要使用内存?
graph
•操作rrd文件,对数据进行存储和查询
•将多次操作合并后再flush磁盘
•将要flush到磁盘的数据,打散到每个时间片,降低IO消耗
•为什么用rrd而不是opentsdb之类的?
hbs
•提供接口给agent查询机器所需监控的端口、进程、要执行的插件列表等信息
•接收agent汇报的状态信息并写入数据库
•缓存用户配置的告警策略
•为什么要用hbs缓存策略列表?
query
•利用一致性hash算法,查询多个graph的数据并汇聚
•需要使用与transfer相同的hash算法及配置
各web端
•Dashboard负责绘图、展示、仪表盘等
•Uic负责管理组合人的对应关系
•Alarm-dashboard负责展示当前未恢复的告警
•用户在portal中配置告警策略
•Portal中的hostgroup一般是从CMDB中同步过来的!
Aggregator
目标:集群监控
•针对某个hostgroup的多个counter进行计算
•分子:$(c1) + $(c2) -$(c3)
•分母:可以是$# 或者数字或者$(d1) + $(d2) -$(d3)
计算结果
•封装成一个metricItem,再次push回open-falcon
为什么这么实现
•归一化的问题解决方案
•复用整个open-falcon的绘图展现、告警逻辑
Gateway——跨数据中心
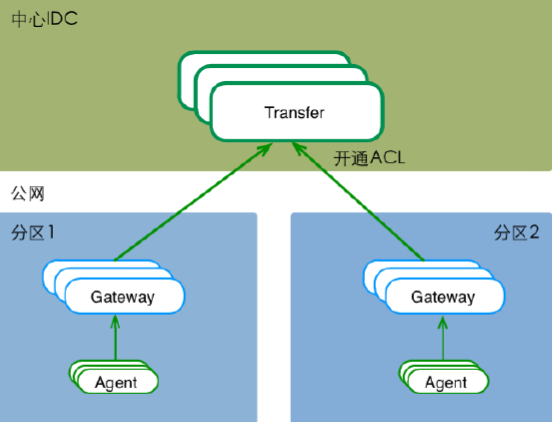
接驳服务树(CMDB)
•开源服务器管理组件(服务树)
•监控对象通过服务树来管理
•服务器进出节点、监控自动变更
历史数据高可用
rrd-on-hbase
•绘图数据存储在hbase中,解决高可用的问题
•历史数据提供更详细粒度的查看
drrs(@京东金融)
•Distributed Round Robin Server
•面向中心公司,轻量级的历史数据存储方案,解决数据扩容的问题
智能告警
同比、环比
•Dashboard数据展示支持同比、环比
•告警判定引入同比、环比作为参考
动态阈值
•通过对历史数据的学习,生成动态的告警阈值
关联分析
•精准告警
•故障定位
SDK
七层
•Nginx
•统计cps、200、5xx、4xx、latency、availability、throughput
语言支持Java/C++/PHP/Python
•内置统计每个接口的cps、latency
•内置统计业务关注的指标的能力
框架支持
•resin、spring、flask…
统计类型
•Gauge/ Meter / Timer / Counter / Histogram
云监控
•服务端Host在公有云上
•无需客户安装、运维服务端
•支持namespace隔离、quota限额
•从根本上对不同用户的数据进行隔离
•优化监控的添加、管理、查看流程
•提升用户体验、提高用户使用效率
其他
•Callback功能增强,推进故障自动处理
•插件的管理支持多种方式(不仅限于git)
•Dashboard 增加用户登录认证
•告警排班/ 告警升级(@金山云)
Open-Falcon部署实践
•初始阶段
•所有的组件部署在一台物理机上即可
机器量级~ 500
•graph、judge、transfer三个组件拆分出来部署在1台服务器上
机器量级~ 1000
•graph、judge、transfer 增加到2~3个实例
•query拆分出来,部署2个实例
•dashboard 拆分出来部署
机器量级~ 10K
•graph、judge、transfer 增加到20个实例,graph尽量使用ssd磁盘
•query增加到5个实例
•dashboard 拆分出来,增加到3个实例
希望对您运维管理有帮助。
以上内容部分来自网络, 希望对您系统架构设计,软件研发有帮助。 其它您可能感兴趣的文章:
构建高效的研发与自动化运维
互联网数据库架构设计思路
移动开发一站式解决方案
某大型电商云平台实践
企业级应用架构模式N-Tier多层架构
某企业社交应用网络拓扑架构图
IT基础架构规划方案一(网络系统规划)
餐饮连锁公司IT信息化解决方案一
如有想了解更多软件研发 , 系统 IT集成 , 企业信息化,项目管理 等资讯,请关注我的微信订阅号:
1、每个维护点按天进行日常巡检,巡检内容按基础巡检表单进行填写。巡检表单在系统中可以按维护点维护内容不同进行灵活配置。
2、巡检预警:每天各维护点定时巡检时间点,超过时间点巡检内容没有上传时则关闭当天的上传功能,将没有上传的信息通知相关主管,并做为维护点当天考核内容进行考核。
3、月度服务总结报表:配置月度服务表单,维护点按时间点填写月度服务总结报表单。可以按月度报表生成对维护点及维护人员的当月考核结果。
4、维护表单统计功能:各维护点的维护表单按月进行统计分析,做为对维护人员当月的考核分析。
二、故障处理
1、故障提交:系统发生故障后维护人员根据故障表单及时填写故障表单内容,提交服务支持中心,并能够提示相应的人员。
2、故障分析:服务中心接到提交的问题单,要组织相应人员对问题单中描述的问题进行分析研判,确定问题的类型(技术问题、业务问题或者操作问题)。属于技术问题,提交服务中心技术人员对存在的问题提出具体的处理意见和建议;属于业务问题,提交服务中心业务员进行处理;属于操作问题,可安排相关人员对问题提出人进行解释,并将系统缺陷类问题提交单转为系统咨询类问题提交单。
3、故障确认、解决:服务中心的技术人员和业务人员收到系统缺陷类问题提交单后,对提交的问题进行归类汇总和分析、确认。可以解决的,明确问题解决的具体处理建议和措施,经主管领导签字同意后,交实施人员进行解决方案的实施。服务人员确认是否解决,并将解决方法提交至知识库模块。
4、故障回复:问题解决后及时向问题提交单位或问题交办单位作出回复,并将分析过程和问题产生原因一并提交。
三、设备资源管理
针对中心设备资源进行账目管理,包括计算机设备、网络设备、一卡通终端设备、耗材、配件等,包括编码、名称、位置、负责人、采购日期、登记时间、安装使用时间、状态等。——it资产管理
四、知识库
运维知识库是IT服务商进行运维工作的重要资源。故障处理后所有的解决方式必须提交至知识库中。——统一信息共享平台
五、绩效管理
自动从服务过程中采集绩效数据,可帮助管理者可从以下几个方面进行人员绩效分析:其一、分析对象从项目、部门、岗位到个人;其二、考核指标从满意度、工作量。
直接上干货《IT运维监控解决方案介绍》
现状
•小公司/ 创业团队< 500台服务器规模
开源方案:Zabbix、Nagios、Cacti…
云服务提供商:监控宝、oneAlert等
•BAT级别> 10万台服务器
投入大量的人力,内部自研,与业务严重耦合没法作为产品推出
•中间阶层
无从可选
早期,选用Zabbix
•Zabbix是一款开源的企业级监控系统
•对其进行二次开发、封装、调优...
•为什么选择Zabbix
•Cacti
•Collectd
•RRDtool
•Nagios
•openTSDB
Zabbix实践思路
•测试ZabbixNode
•Zabbix代码优化
•使用模式优化
•独立部署多套Zabbix,通过API整合
Zabbix遇到的问题
•随着公司业务规模的快速发展
•用户“使用效率”低下,学习成本很高
•不具备水平扩展能力,无法支撑业务需求
•告警策略的维护、变更代价太大,导致运维人员深陷其中,无法自拔
•不利于自动化,不利于与运维平台等基础设施整合
------------------------------------------------------------------------------------------------
Open-Falcon
Open-Falcon是小米运维团队设计开发的一款互联网企业级监控系统
•提供最好用、最人性化的互联网企业级监控解决方案
•项目主页:http://open-falcon.com
•Github: https://github.com/xiaomi/open-falcon
•QQ讨论组:373249123
•微信公众号:OpenFalcon
社区贡献
•交换机监控
•https://github.com/gaochao1/swcollector
•Windows监控
https://github.com/freedomkk-qfeng/falcon-scripts/tree/master/windows_collect
•Agent宕机监控
https://github.com/freedomkk-qfeng/falcon-scripts/tree/master/agent_monitor
•Redis/memcached/rabbitmq监控
https://github.com/iambocai/falcon-monit-scripts
•MySQL 监控方案
https://github.com/open-falcon/mymon
典型案例
美团
•生产环境广泛应用,1万+agent
•集成服务树、支持ping监控、多机房架构支持、报警第二接收人支持
•正在开发openTSDB接口、query增加正则功能
赶集
•深度定制,用于大数据部门平台服务监控与自动运维,生产环境已上线
京东金融
•深度调研open-falcon
•正在开发测试drrs(一种分布式的time series data 存储组件)并适配falcon
内部
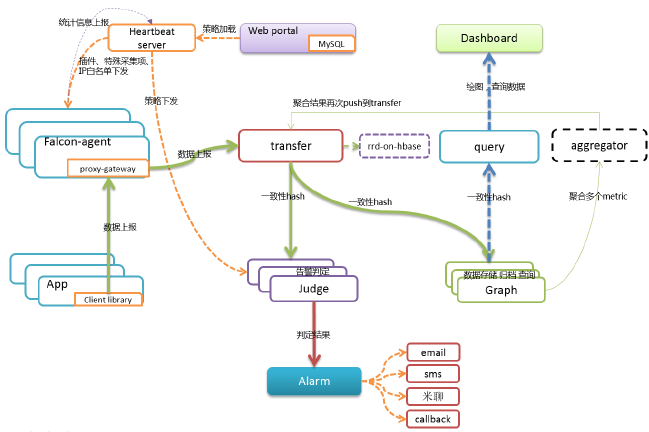
agent
•负责机器数据采集
•自发现各项监控指标
•发送数据给transfer
•发送心跳信息给hbs
•执行自定义插件
•业务数据不要用插件采集!
•数据收集采用推还是拉的方式?
transfer
•对接收到的数据做合法性校验
•转发数据给graph和judge
•为什么要做这个统一的接入端?
•为什么要对数据做分片?
•数据分片方案,用一致性hash还是路由表?
judge
•对接收到的数据按照阈值进行判定
•达到阈值的数据产生相应的event
•触发式判定or 轮询?
•为什么要使用内存?
graph
•操作rrd文件,对数据进行存储和查询
•将多次操作合并后再flush磁盘
•将要flush到磁盘的数据,打散到每个时间片,降低IO消耗
•为什么用rrd而不是opentsdb之类的?
hbs
•提供接口给agent查询机器所需监控的端口、进程、要执行的插件列表等信息
•接收agent汇报的状态信息并写入数据库
•缓存用户配置的告警策略
•为什么要用hbs缓存策略列表?
query
•利用一致性hash算法,查询多个graph的数据并汇聚
•需要使用与transfer相同的hash算法及配置
各web端
•Dashboard负责绘图、展示、仪表盘等
•Uic负责管理组合人的对应关系
•Alarm-dashboard负责展示当前未恢复的告警
•用户在portal中配置告警策略
•Portal中的hostgroup一般是从CMDB中同步过来的!
Aggregator
目标:集群监控
•针对某个hostgroup的多个counter进行计算
•分子:$(c1) + $(c2) -$(c3)
•分母:可以是$# 或者数字或者$(d1) + $(d2) -$(d3)
计算结果
•封装成一个metricItem,再次push回open-falcon
为什么这么实现
•归一化的问题解决方案
•复用整个open-falcon的绘图展现、告警逻辑
Gateway——跨数据中心
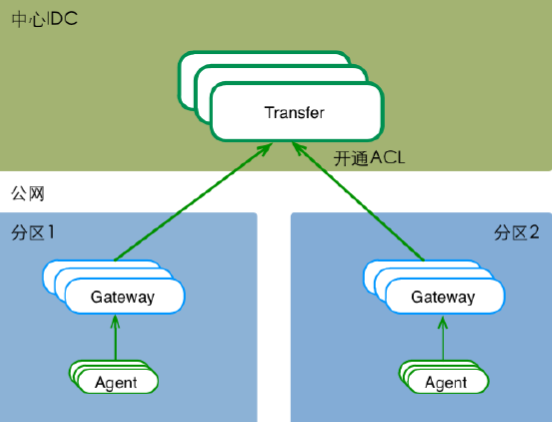
接驳服务树(CMDB)
•开源服务器管理组件(服务树)
•监控对象通过服务树来管理
•服务器进出节点、监控自动变更
历史数据高可用
rrd-on-hbase
•绘图数据存储在hbase中,解决高可用的问题
•历史数据提供更详细粒度的查看
drrs(@京东金融)
•Distributed Round Robin Server
•面向中心公司,轻量级的历史数据存储方案,解决数据扩容的问题
智能告警
同比、环比
•Dashboard数据展示支持同比、环比
•告警判定引入同比、环比作为参考
动态阈值
•通过对历史数据的学习,生成动态的告警阈值
关联分析
•精准告警
•故障定位
SDK
七层
•Nginx
•统计cps、200、5xx、4xx、latency、availability、throughput
语言支持Java/C++/PHP/Python
•内置统计每个接口的cps、latency
•内置统计业务关注的指标的能力
框架支持
•resin、spring、flask…
统计类型
•Gauge/ Meter / Timer / Counter / Histogram
云监控
•服务端Host在公有云上
•无需客户安装、运维服务端
•支持namespace隔离、quota限额
•从根本上对不同用户的数据进行隔离
•优化监控的添加、管理、查看流程
•提升用户体验、提高用户使用效率
其他
•Callback功能增强,推进故障自动处理
•插件的管理支持多种方式(不仅限于git)
•Dashboard 增加用户登录认证
•告警排班/ 告警升级(@金山云)
Open-Falcon部署实践
•初始阶段
•所有的组件部署在一台物理机上即可
机器量级~ 500
•graph、judge、transfer三个组件拆分出来部署在1台服务器上
机器量级~ 1000
•graph、judge、transfer 增加到2~3个实例
•query拆分出来,部署2个实例
•dashboard 拆分出来部署
机器量级~ 10K
•graph、judge、transfer 增加到20个实例,graph尽量使用ssd磁盘
•query增加到5个实例
•dashboard 拆分出来,增加到3个实例
希望对您运维管理有帮助。
以上内容部分来自网络, 希望对您系统架构设计,软件研发有帮助。 其它您可能感兴趣的文章:
构建高效的研发与自动化运维
互联网数据库架构设计思路
移动开发一站式解决方案
某大型电商云平台实践
企业级应用架构模式N-Tier多层架构
某企业社交应用网络拓扑架构图
IT基础架构规划方案一(网络系统规划)
餐饮连锁公司IT信息化解决方案一
如有想了解更多软件研发 , 系统 IT集成 , 企业信息化,项目管理 等资讯,请关注我的微信订阅号:

相关文章推荐
- iPhone企业应用实例分析之一:系统介绍和需求及主要用例
- 实时系统解决方案 TIBCO Rendezvous — 技术介绍(消息中间件|基于数据库的主动推送)
- 【案例实战】餐饮企业分店财务数据分析系统解决方案:业务需求
- 一个开发需求的解决方案 & Oracle临时表介绍
- [5]DevOps 自动化运维工具Chef---Unbuntu系统下,Chef Client 安装位置介绍
- 第三章 CHRAS系统简介及其备份恢复需求 --基于mkCDrec的核心网网络运维系统的备份和恢复的研究与实现
- 安卓系统的日历开发(项目报告1)【项目开发需求及功能介绍】
- 介绍如何辨别真假云计算ERP系统解决方案方法!
- 几个开源的运维管理系统介绍
- linux运维的认知及RHEL7 Unix/Linux 系统 介绍和安装
- 实时系统解决方案 TIBCO Rendezvous — 技术介绍(消息中间件|基于数据库的主动推送)
- 机房环境动力监控系统功能介绍及设计需求规划和选择
- OA系统需求功能介绍
- 【案例实战】餐饮企业分店财务数据分析系统解决方案:业务需求
- NW(New World)快速开发平台介绍(完整的中小型管理系统解决方案)
- iPhone企业应用实例分析之一:系统介绍和需求及主要用例
- 【系统运维】POSIX phtread介绍
- 运维系统,发现报错,打开文件句柄数太多解决方案
- 电力企业计量生产需求系统解决方案
- 2010中国嵌入式系统创新解决方案评选介绍