PostgreSQL分区表的探究与开发(二):基于PostgreSQL10语法引擎分区表的开发
2017-06-05 22:16
459 查看
背景
前面一篇讲了基于“继承表+约束+触发器或规则”创建的分区表。但这种方式不但管理分区比较繁琐,性能也比较差。在PostgreSQL10 Beta版本发布之前,社区人员已经把分区表的补丁提交到邮件列表中。因为对分区表功能的需求,把补丁下载下来patch到PostgreSQL9.5上形成有分区表特性的数据库。但社区提供的分区表功能只提供范围分区(Range Partition)和列表分区(List Partition),后来又添加了哈希分区(Hash Partitioin)特性。
原理
添加的分区表功能同样是在继承表的基础上实现。但这次改动深化了分区表特性,不仅把表对象区分成table和partitioned table,而且把分区特性配置到系统表中。在数据插入方面,完全摒弃了触发器而在内核中实现,性能有了很大提高。
下图是PostgreSQL源码中记录表对象的结构体Relation,在增加分区表功能后,Relation结构体中增加了分区表的参数信息:
ParitionKeyData结构体主要用来存储主表的信息,包括分区类型、分区KEY的信息以及操作符等。
PartitionDescData结构体主要用来存储分区信息,包括分区OID,分区边界值等。
下图是创建分区表的一个原理流程图。

在创建分区表的过程中,创建主表和创建分区分是开操作的(不同于Oracle、MySQL等分区表语法)。创建主表时,系统把分区表KEY的信息写到系统表pg_partitioned中,然后对记录分区表KEY值信息的Relation结构体相应参数进行初始化;同样创建分区时,系统会把分区的信息写到系统表pg_partition,然后对记录分区信息的Relation结构体的相应参数进行初始化。这样记录表信息的Relation完全可以记录分区表的信息。
在数据插入方面,添加的分区表特性也做了比较深的改动。下面是一个执行INSERT操作的原理逻辑图:

其中ModifyTableState结构体是执行插入操作时存储表结构的一些信息,这其中也增加了表分区的一些参数:
执行INSERT前,会先对ModifyTableState结构体中的表分区参数有一个初始化的过程,参数信息都是从Relation缓存中获取。这样在做INSERT操作时,才能根据这些参数信息快速作出判断获取目标分区进行插入操作。所以相比较触发器实现的数据插入,在内核中实现的数据插入不仅节省了语法分析和优化的过程,而且分区信息都是加载到缓存中,节省了I/O时间,写入性能大幅提高。
不同于范围分区和列表分区,哈希分区没有潜在的约束条件来划分分区,那么向哈希分区主表中插入数据时,数据是怎么分配的呢?

上图是哈希分区实现的一个原理流程图。哈希分区虽然没有潜在的约束条件,但是系统会给每一个分区分配了一个序号(序号是随新建分区递增的),这些序号值也都是写在系统表中并加载到缓存结构体中。那么在INSERT数据时,系统根据提取的KEY值,对其进行哈希运算然后结果值对分区数取余,所得余数值和分区序号对比,相等的就是目标分区。
做SELECT查询也是走相同的流程。但是这里还存在一个问题,像范围分区和列表分区都存在约束条件,所以在constraint_exclusion=ON的状态下,对分区做条件查询时,查询优化器会定位到目标分区进行扫描。而哈希分区不存在约束条件,那么在对哈希分区做条件查询时,没有查询优化,只能是做全表分区扫描。所以要做哈希分区,还有针对其查询优化做处理。

PostgreSQL的继承表在没有约束条件的情况下,对其进行条件查询,默认是走全表顺序扫描的。哈希分区是在继承表的基础上实现的,对其进行条件查询时,同样是全表顺序扫描。所以要想做哈希分区的优化处理,首先要去掉哈希分区场景下的执行计划,剩下的就是根据KEY VALUE获取目标分区,然后形成新的执行计划。
应用
1. 范围分区
a) 语法
第一条语句是创建分区表主表,范围分区支持多列组合作为KEY;第二个语句是创建分区。FROM...TO ... 表示范围分区约束的起始值和结束值;UNBOUNDED关键字表示无限大或无限小;INCLUSIVE关键字表示约束范围包括上下限值,EXCLUSIVE表示不包括。创建分区时,FROM默认是INCLUSIVE,TO默认是EXCLUSIVE。
b) 示例
2. 列表分区
a) 语法
列表分区的KEY只支持一个字段。
b) 示例
3. 哈希分区
a)语法
b)示例
4. 系统表
a) pg_partitioned系统表
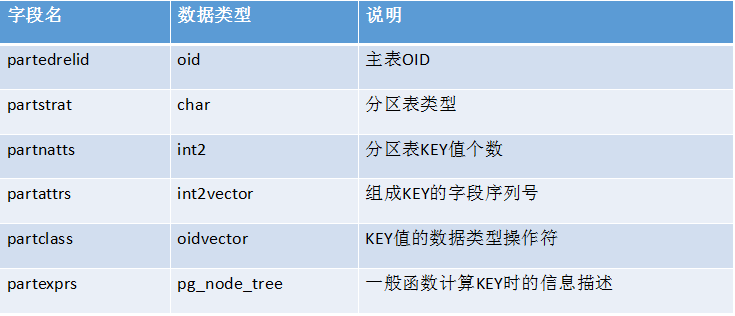
pg_partitioned系统表用来记录主表信息。
b) pg_partition系统表

pg_partition系统表用来记录表分区信息。
字段partbound表示KEY的属性信息。constype表示数据类型,consttymod表示域的基本类型,-1表示该类行不是域。constcollid排序规则,0表示该类型不支持排序规则。constlen表示数据类型长度,-1表示该类型为变长类型。constbyval表示是数值传递还是引用传递。true表示传递值,false表示引用传递。 constisnull表示数值可否为NULL值。constvalue表示数值的物理表示形式。
5. 其他操作
a) 增加分区
由于创建分区是单独的SQL操作,所以增加分区就是新建分区。
对于哈希分区需要特别说明的是,如果原来的分区中存有数据,那么再增加新的分区时,原有的数据会有一个重新分配的过程(后台自动完成),为什么会这样? 因为前面提到过哈希分区的分区规则和哈希算法以及分区数有关,而INSERT和SELECT操作要追寻相同的分区规则,那么再增加新分区后,分区数有变,原有的数据再做SELECT时将会导致和INSERT分区规则不一致。所以再增加一个新的分区后,原来的数据要有一个重新分配的过程。
b) ATTACH普通表
ATTACH操作是把普通表转变成分区表子分区的操作。对于ATTACH操作,目前只有范围分区和列表分区支持,哈希分区不支持该操作。
<1> 范围分区
语法为:
VALIDATE关键字表示是否校验ATTACH普通表中的数据。NO VALIDATE是不校验。默认操作是VALIDATE。
以前面创建的stu分区表为例:
<2> 列表分区
语法为:
以前面创建的sales分区表为例:
c) DETACH分区
DETACH操作可以看成是ATTACH的反操作,把表分区转变成普通表。
语法:
示例:
d) 删除分区
目前分区表不支持直接删除分区的操作。对于范围分区和列表分区,需要先进行DETACH操作把要删除的子分区变为一个普通表的形式,然后再以普通表的形式删除。哈希分区不支持删除分区的操作,只能对整个分区表删除。
6. 性能
前面提到了由于PostgreSQL10的分区功能在插入方面摒弃了触发器的实现形式,而且分区信息完全是cache到缓存中的,节省了语法分析、优化和I/O的时间。所以插入性能有了很大提高。下面就从读写两个方面比较两个实现分区功能方式的性能。
测试场景为范围分区(Range Partition),分区数为10,数据量100万。
a) 插入性能
首先测试以“继承表+约束+规则”形式创建的分区表的性能:
接下来测试patch PostgreSQL10补丁的的分区表性能。
插入性能测试数据对比
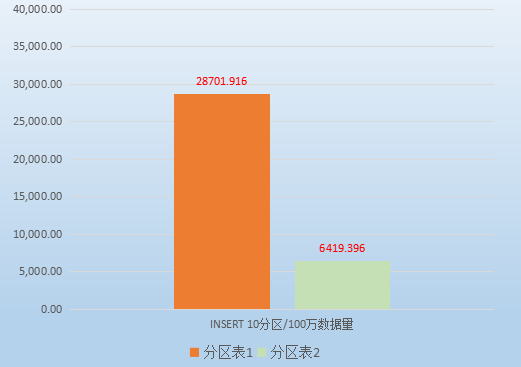
从表格中可以看出,改在内核中实现的数据插入比触发器实现的性能提高还是很明显的。
b) 检索性能
对两个版本的分区表做相同的条件查询。
首先以“继承表+约束+规则”形式创建的分区表。
然后patch PostgreSQL10补丁的的分区表。
检索性能测试数据对比:
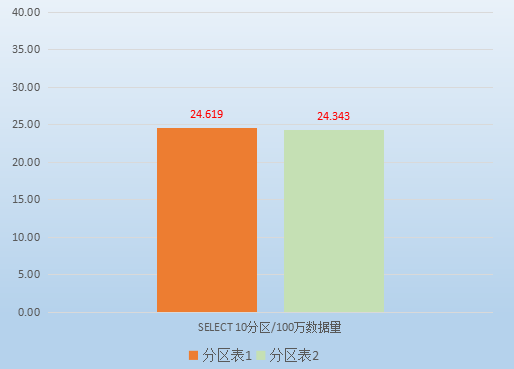
从表格可以看出,检索性能基本差不多。
7. 小结
分区表除了方便数据管理,提高检索效率才是其主要应用的地方。现在分区表基本上都是在继承表的基础上实现的,要做到条件检索时只对目标分区的扫描,而不是全表分区的顺序扫描,constraint_exclusion配置参数一定要设置为ON的状态。
关于提高分区表性能,除了从开发上考虑,我们还可以从应用场景上去考虑一下。比如创建一个范围分区,其检索频率很高,而写的频率不大,那么在一定数据量的情况下,创建的分区数越多,检索效率则会越大。
前面一篇讲了基于“继承表+约束+触发器或规则”创建的分区表。但这种方式不但管理分区比较繁琐,性能也比较差。在PostgreSQL10 Beta版本发布之前,社区人员已经把分区表的补丁提交到邮件列表中。因为对分区表功能的需求,把补丁下载下来patch到PostgreSQL9.5上形成有分区表特性的数据库。但社区提供的分区表功能只提供范围分区(Range Partition)和列表分区(List Partition),后来又添加了哈希分区(Hash Partitioin)特性。
原理
添加的分区表功能同样是在继承表的基础上实现。但这次改动深化了分区表特性,不仅把表对象区分成table和partitioned table,而且把分区特性配置到系统表中。在数据插入方面,完全摒弃了触发器而在内核中实现,性能有了很大提高。
下图是PostgreSQL源码中记录表对象的结构体Relation,在增加分区表功能后,Relation结构体中增加了分区表的参数信息:
typedef struct Relation
{
Form_pg_class rd_rel;
TupleDesc rd_att;
...
struct PartitionKeyData *rd_partkey; //存储分区表的key信息
struct PartitionDescData *rd_partdesc; //存储分区信息
}ParitionKeyData结构体主要用来存储主表的信息,包括分区类型、分区KEY的信息以及操作符等。
PartitionDescData结构体主要用来存储分区信息,包括分区OID,分区边界值等。
下图是创建分区表的一个原理流程图。
在创建分区表的过程中,创建主表和创建分区分是开操作的(不同于Oracle、MySQL等分区表语法)。创建主表时,系统把分区表KEY的信息写到系统表pg_partitioned中,然后对记录分区表KEY值信息的Relation结构体相应参数进行初始化;同样创建分区时,系统会把分区的信息写到系统表pg_partition,然后对记录分区信息的Relation结构体的相应参数进行初始化。这样记录表信息的Relation完全可以记录分区表的信息。
在数据插入方面,添加的分区表特性也做了比较深的改动。下面是一个执行INSERT操作的原理逻辑图:
其中ModifyTableState结构体是执行插入操作时存储表结构的一些信息,这其中也增加了表分区的一些参数:
typedef struct ModifyTableState
{
ResultRelInfo *resultRelInfo;
...
...
...
struct PartitionDescNodeData *mt_partition_node; //分区表节点信息
ResultRelInfo *mt_partitions; //分区数组
int mt_num_partitions; //分区数
} ModifyTableState;执行INSERT前,会先对ModifyTableState结构体中的表分区参数有一个初始化的过程,参数信息都是从Relation缓存中获取。这样在做INSERT操作时,才能根据这些参数信息快速作出判断获取目标分区进行插入操作。所以相比较触发器实现的数据插入,在内核中实现的数据插入不仅节省了语法分析和优化的过程,而且分区信息都是加载到缓存中,节省了I/O时间,写入性能大幅提高。
不同于范围分区和列表分区,哈希分区没有潜在的约束条件来划分分区,那么向哈希分区主表中插入数据时,数据是怎么分配的呢?
上图是哈希分区实现的一个原理流程图。哈希分区虽然没有潜在的约束条件,但是系统会给每一个分区分配了一个序号(序号是随新建分区递增的),这些序号值也都是写在系统表中并加载到缓存结构体中。那么在INSERT数据时,系统根据提取的KEY值,对其进行哈希运算然后结果值对分区数取余,所得余数值和分区序号对比,相等的就是目标分区。
做SELECT查询也是走相同的流程。但是这里还存在一个问题,像范围分区和列表分区都存在约束条件,所以在constraint_exclusion=ON的状态下,对分区做条件查询时,查询优化器会定位到目标分区进行扫描。而哈希分区不存在约束条件,那么在对哈希分区做条件查询时,没有查询优化,只能是做全表分区扫描。所以要做哈希分区,还有针对其查询优化做处理。
PostgreSQL的继承表在没有约束条件的情况下,对其进行条件查询,默认是走全表顺序扫描的。哈希分区是在继承表的基础上实现的,对其进行条件查询时,同样是全表顺序扫描。所以要想做哈希分区的优化处理,首先要去掉哈希分区场景下的执行计划,剩下的就是根据KEY VALUE获取目标分区,然后形成新的执行计划。
应用
1. 范围分区
a) 语法
CREATE TABLE 表名 ( [{ 列名称 数据_类型} [, ... ] ] )
PARTITION BY RANGE ( [{ 列名称 } [, ...] ] );
CREATE TABLE 表名 PARTITION OF 父表 FOR VALUES
FROM{ ( 表达式 [, ...] ) | UNBOUNDED } [ INCLUSIVE | EXCLUSIVE ]
TO { ( 表达式 [, ...] ) | UNBOUNDED } [ INCLUSIVE | EXCLUSIVE ]
[ TABLESPACE 表空间名 ];第一条语句是创建分区表主表,范围分区支持多列组合作为KEY;第二个语句是创建分区。FROM...TO ... 表示范围分区约束的起始值和结束值;UNBOUNDED关键字表示无限大或无限小;INCLUSIVE关键字表示约束范围包括上下限值,EXCLUSIVE表示不包括。创建分区时,FROM默认是INCLUSIVE,TO默认是EXCLUSIVE。
b) 示例
highgo=# CREATE TABLE stu (stu_id int, stu_name name, stu_score int) PARTITION BY RANGE(stu_score); CREATE TABLE highgo=# CREATE TABLE stu_1 PARTITION OF stu FOR VALUES FROM (60) TO (70); CREATE TABLE highgo=# CREATE TABLE stu_2 PARTITION OF stu FOR VALUES FROM (70) TO (80); CREATE TABLE highgo=# CREATE TABLE stu_3 PARTITION OF stu FOR VALUES FROM (80) TO (90); CREATE TABLE highgo=# CREATE TABLE stu_4 PARTITION OF stu FOR VALUES FROM (90) TO (100) INCLUSIVE; CREATE TABLE highgo=# INSERT INTO stu SELECT generate_series(60,100), 'stu'||generate_series(60,100), generate_series(60,100); INSERT 0 41 highgo=# explain analyze select * from stu; QUERY PLAN --------------------------------------------------------------------------------------------------------- - Append (cost=0.00..72.40 rows=3241 width=72) (actual time=0.019..0.071 rows=41 loops=1) -> Seq Scan on stu (cost=0.00..0.00 rows=1 width=72) (actual time=0.002..0.002 rows=0 loops=1) -> Seq Scan on stu_1 (cost=0.00..18.10 rows=810 width=72) (actual time=0.013..0.017 rows=10 loops=1) -> Seq Scan on stu_2 (cost=0.00..18.10 rows=810 width=72) (actual time=0.005..0.010 rows=10 loops=1) -> Seq Scan on stu_3 (cost=0.00..18.10 rows=810 width=72) (actual time=0.005..0.009 rows=10 loops=1) -> Seq Scan on stu_4 (cost=0.00..18.10 rows=810 width=72) (actual time=0.005..0.009 rows=11 loops=1) Planning time: 1.680 ms Execution time: 0.235 ms (8 行记录) highgo=# explain analyze select * from stu where stu_score = 72; QUERY PLAN ------------------------------------------------------------------------------------------------------- Append (cost=0.00..20.12 rows=5 width=72) (actual time=0.016..0.021 rows=1 loops=1) -> Seq Scan on stu (cost=0.00..0.00 rows=1 width=72) (actual time=0.002..0.002 rows=0 loops=1) Filter: (stu_score = 72) -> Seq Scan on stu_2 (cost=0.00..20.12 rows=4 width=72) (actual time=0.012..0.016 rows=1 loops=1) Filter: (stu_score = 72) Rows Removed by Filter: 9 Planning time: 0.753 ms Execution time: 0.085 ms (8 行记录)
2. 列表分区
a) 语法
CREATE TABLE 表名 ( [{ 列名称 数据_类型} [, ... ] ] )
PARTITION BY LIST( { 列名称 } );
CREATE TABLE 表名 PARTITION OF 父表 FOR VALUES
IN ( 表达式 [, ...] ) [ TABLESPACE 表空间名 ];列表分区的KEY只支持一个字段。
b) 示例
highgo=# CREATE TABLE sales (product_id int, saleroom int, province text) PARTITION BY LIST(province);
CREATE TABLE
highgo=# CREATE TABLE sales_east PARTITION OF sales FOR VALUES IN ('山东','江苏','上海');
CREATE TABLE
highgo=# CREATE TABLE sales_west PARTITION OF sales FOR VALUES IN ('山西','陕西','四川');
CREATE TABLE
highgo=# CREATE TABLE sales_north PARTITION OF sales FOR VALUES IN ('北京','河北','辽宁');
CREATE TABLE
highgo=# CREATE TABLE sales_south PARTITION OF sales FOR VALUES IN ('广东','福建');
CREATE TABLE
highgo=# INSERT INTO sales VALUES (101,1000000,'山东');
INSERT 0 1
highgo=# INSERT INTO sales VALUES (101,2000000,'江苏');
INSERT 0 1
highgo=# INSERT INTO sales VALUES (102,4000000,'上海');
INSERT 0 1
highgo=# INSERT INTO sales VALUES (101,1000000,'山东');
INSERT 0 1
highgo=# INSERT INTO sales VALUES (102,2000000,'山西');
INSERT 0 1
highgo=# INSERT INTO sales VALUES (101,1000000,'四川');
INSERT 0 1
highgo=# INSERT INTO sales VALUES (102,3000000,'北京');
INSERT 0 1
highgo=# INSERT INTO sales VALUES (101,1000000,'辽宁');
INSERT 0 1
highgo=# INSERT INTO sales VALUES (101,3000000,'广东');
INSERT 0 1
highgo=# explain analyze select * from sales;
QUERY PLAN
---------------------------------------------------------------------------------------------------------
-------
Append (cost=0.00..88.00 rows=4801 width=40) (actual time=0.015..0.037 rows=9 loops=1)
-> Seq Scan on sales (cost=0.00..0.00 rows=1 width=40) (actual time=0.001..0.001 rows=0 loops=1)
-> Seq Scan on sales_east (cost=0.00..22.00 rows=1200 width=40) (actual time=0.012..0.015 rows=4 loo
ps=1)
-> Seq Scan on sales_west (cost=0.00..22.00 rows=1200 width=40) (actual time=0.004..0.005 rows=2 loo
ps=1)
-> Seq Scan on sales_north (cost=0.00..22.00 rows=1200 width=40) (actual time=0.002..0.003 rows=2 lo
ops=1)
-> Seq Scan on sales_south (cost=0.00..22.00 rows=1200 width=40) (actual time=0.002..0.002 rows=1 lo
ops=1)
Planning time: 1.178 ms
Execution time: 0.163 ms
(8 行记录)
highgo=# explain analyze select * from sales where province = '山东';
QUERY PLAN
---------------------------------------------------------------------------------------------------------
---
Append (cost=0.00..25.00 rows=7 width=40) (actual time=0.014..0.019 rows=2 loops=1)
-> Seq Scan on sales (cost=0.00..0.00 rows=1 width=40) (actual time=0.002..0.002 rows=0 loops=1)
Filter: (province = '山东'::text)
-> Seq Scan on sales_east (cost=0.00..25.00 rows=6 width=40) (actual time=0.010..0.013 rows=2 loops=
1)
Filter: (province = '山东'::text)
Rows Removed by Filter: 2
Planning time: 0.605 ms
Execution time: 0.073 ms3. 哈希分区
a)语法
CREATE TABLE 表名 ( [{ 列名称 数据_类型} [, ... ] ] )
PARTITION BY HASH( { 列名称 } );
CREATE TABLE 表名 PARTITION OF 父表 [ TABLESPACE 表空间名 ];b)示例
highgo=# CREATE TABLE employee(employee_id text, employee_name name, department int) PARTITION BY HASH(employee_id);
CREATE TABLE
highgo=# CREATE TABLE employee_1 PARTITION OF employee;
CREATE TABLE
highgo=# CREATE TABLE employee_2 PARTITION OF employee;
CREATE TABLE
highgo=# CREATE TABLE employee_3 PARTITION OF employee;
CREATE TABLE
highgo=# CREATE TABLE employee_4 PARTITION OF employee;
CREATE TABLE
highgo=# INSERT INTO employee VALUES ('1000','aaa',101);
INSERT 0 1
highgo=# INSERT INTO employee VALUES ('1001','bbb',101);
INSERT 0 1
highgo=# INSERT INTO employee VALUES ('1002','ccc',102);
INSERT 0 1
highgo=# INSERT INTO employee VALUES ('1003','ddd',101);
INSERT 0 1
highgo=# INSERT INTO employee VALUES ('1004','eee',101);
INSERT 0 1
highgo=# INSERT INTO employee VALUES ('1005','fff',102);
INSERT 0 1
highgo=# INSERT INTO employee VALUES ('1006','ggg',101);
INSERT 0 1
highgo=# INSERT INTO employee VALUES ('1007','hhh',101);
INSERT 0 1
highgo=# INSERT INTO employee VALUES ('1008','iii',103);
INS
3fe9
ERT 0 1
highgo=# INSERT INTO employee VALUES ('1009','jjj',102);
INSERT 0 1
highgo=# INSERT INTO employee VALUES ('1010','kkk',101);
INSERT 0 1
highgo=# INSERT INTO employee VALUES ('1011','lll',103);
INSERT 0 1
highgo=# INSERT INTO employee VALUES ('1012','mmm',102);
INSERT 0 1
highgo=# INSERT INTO employee VALUES ('1013','nnn',101);
INSERT 0 1
highgo=# explain analyze select * from employee;
QUERY PLAN
---------------------------------------------------------------------------------------------------------
------
Append (cost=0.00..65.20 rows=2520 width=100) (actual time=0.017..0.065 rows=14 loops=1)
-> Seq Scan on employee_1 (cost=0.00..16.30 rows=630 width=100) (actual time=0.015..0.017 rows=5 loo
ps=1)
-> Seq Scan on employee_2 (cost=0.00..16.30 rows=630 width=100) (actual time=0.010..0.012 rows=7 loo
ps=1)
-> Seq Scan on employee_3 (cost=0.00..16.30 rows=630 width=100) (actual time=0.002..0.018 rows=1 loo
ps=1)
-> Seq Scan on employee_4 (cost=0.00..16.30 rows=630 width=100) (actual time=0.003..0.004 rows=1 loo
ps=1)
Planning time: 0.439 ms
Execution time: 0.149 ms
(7 行记录)
highgo=# explain analyze select * from employee where employee_id = '1006';
QUERY PLAN
---------------------------------------------------------------------------------------------------------
----
Append (cost=0.00..17.88 rows=3 width=100) (actual time=0.021..0.024 rows=1 loops=1)
-> Seq Scan on employee_2 (cost=0.00..17.88 rows=3 width=100) (actual time=0.019..0.021 rows=1 loops
=1)
Filter: (employee_id = '1006'::text)
Rows Removed by Filter: 6
Planning time: 0.151 ms
Execution time: 0.074 ms4. 系统表
a) pg_partitioned系统表
pg_partitioned系统表用来记录主表信息。
highgo=# select partedrelid::regclass as partitioned_name,* from pg_partitioned; partitioned_name | partedrelid | partstrat | partnatts | partattrs | partclass | partexprs ------------------+-------------+-----------+-----------+-----------+-----------+----------- stu | 16387 | r | 1 | 3 | 1978 | sales | 16402 | l | 1 | 3 | 3126 | employee | 16432 | h | 1 | 1 | 3126 | (3 行记录)
b) pg_partition系统表
pg_partition系统表用来记录表分区信息。
highgo=# select partrelid::regclass, * from pg_partition;
partrelid | partrelid |
partbound
-------------+-----------+-------------------------------------------------------------------------------
---------------------------------------------------------------------------------------------------------
---------------------------------------------------------------------------------------------------------
---------------------------------------------------------------------------------------------------------
---------------------------------------------------------------------------------------------------------
-------------------------------------------------
stu_1 | 16390 | {PARTITIONRANGE :lowerinc true :lower ({CONST :consttype 23 :consttypmod -1 :c
onstcollid 0 :constlen 4 :constbyval true :constisnull false :location 53 :constvalue 4 [ 60 0 0 0 0 0 0
0 ]}) :upperinc false :upper ({CONST :consttype 23 :consttypmod -1 :constcollid 0 :constlen 4 :constbyval
true :constisnull false :location 62 :constvalue 4 [ 70 0 0 0 0 0 0 0 ]})}
stu_2 | 16393 | {PARTITIONRANGE :lowerinc true :lower ({CONST :consttype 23 :consttypmod -1 :c
onstcollid 0 :constlen 4 :constbyval true :constisnull false :location 53 :constvalue 4 [ 70 0 0 0 0 0 0
0 ]}) :upperinc false :upper ({CONST :consttype 23 :consttypmod -1 :constcollid 0 :constlen 4 :constbyval
true :constisnull false :location 62 :constvalue 4 [ 80 0 0 0 0 0 0 0 ]})}
stu_3 | 16396 | {PARTITIONRANGE :lowerinc true :lower ({CONST :consttype 23 :consttypmod -1 :c
onstcollid 0 :constlen 4 :constbyval true :constisnull false :location 53 :constvalue 4 [ 80 0 0 0 0 0 0
0 ]}) :upperinc false :upper ({CONST :consttype 23 :consttypmod -1 :constcollid 0 :constlen 4 :constbyval
true :constisnull false :location 62 :constvalue 4 [ 90 0 0 0 0 0 0 0 ]})}
stu_4 | 16399 | {PARTITIONRANGE :lowerinc true :lower ({CONST :consttype 23 :consttypmod -1 :c
onstcollid 0 :constlen 4 :constbyval true :constisnull false :location 53 :constvalue 4 [ 90 0 0 0 0 0 0
0 ]}) :upperinc true :upper ({CONST :consttype 23 :consttypmod -1 :constcollid 0 :constlen 4 :constbyval
true :constisnull false :location 62 :constvalue 4 [ 100 0 0 0 0 0 0 0 ]})}
sales_east | 16408 | {PARTITIONLISTVALUES :values ({CONST :consttype 25 :consttypmod -1 :constcolli
d 100 :constlen -1 :constbyval false :constisnull false :location 58 :constvalue 10 [ 40 0 0 0 -27 -79 -7
9 -28 -72 -100 ]} {CONST :consttype 25 :consttypmod -1 :constcollid 100 :constlen -1 :constbyval false :c
onstisnull false :location 67 :constvalue 10 [ 40 0 0 0 -26 -79 -97 -24 -117 -113 ]} {CONST :consttype 25
:consttypmod -1 :constcollid 100 :constlen -1 :constbyval false :constisnull false :location 76 :constva
lue 10 [ 40 0 0 0 -28 -72 -118 -26 -75 -73 ]})}
sales_west | 16414 | {PARTITIONLISTVALUES :values ({CONST :consttype 25 :consttypmod -1 :constcolli
d 100 :constlen -1 :constbyval false :constisnull false :location 58 :constvalue 10 [ 40 0 0 0 -27 -79 -7
9 -24 -91 -65 ]} {CONST :consttype 25 :consttypmod -1 :constcollid 100 :constlen -1 :constbyval false :co
nstisnull false :location 67 :constvalue 10 [ 40 0 0 0 -23 -103 -107 -24 -91 -65 ]} {CONST :consttype 25
:consttypmod -1 :constcollid 100 :constlen -1 :constbyval false :constisnull false :location 76 :constval
ue 10 [ 40 0 0 0 -27 -101 -101 -27 -73 -99 ]})}
sales_north | 16420 | {PARTITIONLISTVALUES :values ({CONST :consttype 25 :consttypmod -1 :constcolli
d 100 :constlen -1 :constbyval false :constisnull false :location 59 :constvalue 10 [ 40 0 0 0 -27 -116 -
105 -28 -70 -84 ]} {CONST :consttype 25 :consttypmod -1 :constcollid 100 :constlen -1 :constbyval false :
constisnull false :location 68 :constvalue 10 [ 40 0 0 0 -26 -78 -77 -27 -116 -105 ]} {CONST :consttype 2
5 :consttypmod -1 :constcollid 100 :constlen -1 :constbyval false :constisnull false :location 77 :constv
alue 10 [ 40 0 0 0 -24 -66 -67 -27 -82 -127 ]})}
sales_south | 16426 | {PARTITIONLISTVALUES :values ({CONST :consttype 25 :consttypmod -1 :constcolli
d 100 :constlen -1 :constbyval false :constisnull false :location 59 :constvalue 10 [ 40 0 0 0 -27 -71 -6
5 -28 -72 -100 ]} {CONST :consttype 25 :consttypmod -1 :constcollid 100 :constlen -1 :constbyval false :c
onstisnull false :location 68 :constvalue 10 [ 40 0 0 0 -25 -90 -113 -27 -69 -70 ]})}
employee_1 | 16438 | {PARTITIONHASH :values 0}
employee_2 | 16444 | {PARTITIONHASH :values 1}
employee_3 | 16450 | {PARTITIONHASH :values 2}
employee_4 | 16456 | {PARTITIONHASH :values 3}
(12 行记录)字段partbound表示KEY的属性信息。constype表示数据类型,consttymod表示域的基本类型,-1表示该类行不是域。constcollid排序规则,0表示该类型不支持排序规则。constlen表示数据类型长度,-1表示该类型为变长类型。constbyval表示是数值传递还是引用传递。true表示传递值,false表示引用传递。 constisnull表示数值可否为NULL值。constvalue表示数值的物理表示形式。
5. 其他操作
a) 增加分区
由于创建分区是单独的SQL操作,所以增加分区就是新建分区。
对于哈希分区需要特别说明的是,如果原来的分区中存有数据,那么再增加新的分区时,原有的数据会有一个重新分配的过程(后台自动完成),为什么会这样? 因为前面提到过哈希分区的分区规则和哈希算法以及分区数有关,而INSERT和SELECT操作要追寻相同的分区规则,那么再增加新分区后,分区数有变,原有的数据再做SELECT时将会导致和INSERT分区规则不一致。所以再增加一个新的分区后,原来的数据要有一个重新分配的过程。
b) ATTACH普通表
ATTACH操作是把普通表转变成分区表子分区的操作。对于ATTACH操作,目前只有范围分区和列表分区支持,哈希分区不支持该操作。
<1> 范围分区
语法为:
ALTER TABLE 分区表名 ATTACH PARTITION 表名 FOR VALUES
FROM{ ( 表达式 [, ...] ) | UNBOUNDED } [ INCLUSIVE | EXCLUSIVE ]
TO { ( 表达式 [, ...] ) | UNBOUNDED } [ INCLUSIVE | EXCLUSIVE ]
[ VALIDATE | NO VALIDATE ];VALIDATE关键字表示是否校验ATTACH普通表中的数据。NO VALIDATE是不校验。默认操作是VALIDATE。
以前面创建的stu分区表为例:
highgo=# CREATE TABLE stu_attach(stu_id int, stu_name name, stu_score int) ; CREATE TABLE highgo=# ALTER TABLE stu ATTACH PARTITION stu_attach FOR VALUES FROM (50) TO (60); ALTER TABLE
<2> 列表分区
语法为:
ALTER TABLE 分区表名 ATTACH PARTITION 表名 FOR VALUES IN ( 表达式 [, ...] ) [ VALIDATE | NO VALIDATE ];
以前面创建的sales分区表为例:
highgo=# CREATE TABLE sales_foreign (product_id int, saleroom int, province text) ;
CREATE TABLE
highgo=# ALTER TABLE sales ATTACH PARTITION sales_foreign FOR VALUES IN('美国','日本');
ALTER TABLEc) DETACH分区
DETACH操作可以看成是ATTACH的反操作,把表分区转变成普通表。
语法:
ALTER TABLE 分区表名 DETACH PARTITION 分区名;
示例:
highgo=# ALTER TABLE stu DETACH PARTITION stu_attach; ALTER TABLE highgo=# ALTER TABLE sales DETACH PARTITION sales_foreign; ALTER TABLE
d) 删除分区
目前分区表不支持直接删除分区的操作。对于范围分区和列表分区,需要先进行DETACH操作把要删除的子分区变为一个普通表的形式,然后再以普通表的形式删除。哈希分区不支持删除分区的操作,只能对整个分区表删除。
highgo=# ALTER TABLE stu DETACH PARTITION stu_4; ALTER TABLE highgo=# DROP TABLE stu_4; DROP TABLE
6. 性能
前面提到了由于PostgreSQL10的分区功能在插入方面摒弃了触发器的实现形式,而且分区信息完全是cache到缓存中的,节省了语法分析、优化和I/O的时间。所以插入性能有了很大提高。下面就从读写两个方面比较两个实现分区功能方式的性能。
测试场景为范围分区(Range Partition),分区数为10,数据量100万。
a) 插入性能
首先测试以“继承表+约束+规则”形式创建的分区表的性能:
highgo=# create table range_test(id int, tt text, tm timestamp); CREATE TABLE highgo=# create table range_test1 (check (id >= 0 AND id < 100000 )) INHERITS (range_test); CREATE TABLE highgo=# create table range_test2 (check (id >= 100000 AND id < 200000 )) INHERITS (range_test); CREATE TABLE highgo=# create table range_test3 (check (id >= 200000 AND id < 300000 )) INHERITS (range_test); CREATE TABLE highgo=# create table range_test4 (check (id >= 300000 AND id < 400000 )) INHERITS (range_test); CREATE TABLE highgo=# create table range_test5 (check (id >= 400000 AND id < 500000 )) INHERITS (range_test); CREATE TABLE highgo=# create table range_test6 (check (id >= 500000 AND id < 600000 )) INHERITS (range_test); CREATE TABLE highgo=# create table range_test7 (check (id >= 600000 AND id < 700000 )) INHERITS (range_test); CREATE TABLE highgo=# create table range_test8 (check (id >= 700000 AND id < 800000 )) INHERITS (range_test); CREATE TABLE highgo=# create table range_test9 (check (id >= 800000 AND id < 900000 )) INHERITS (range_test); CREATE TABLE highgo=# create table range_test10 (check (id >= 900000 AND id <= 1000000 )) INHERITS (range_test); CREATE TABLE highgo=# CREATE OR REPLACE RULE range_test1_rule AS ON INSERT TO range_test WHERE id >= 0 AND id < 100000 DO INSTEAD INSERT INTO range_test1 VALUES (NEW.*); CREATE RULE highgo=# CREATE OR REPLACE RULE range_test2_rule AS ON INSERT TO range_test WHERE id >= 100000 AND id < 200000 DO INSTEAD INSERT INTO range_test2 VALUES (NEW.*); CREATE RULE highgo=# CREATE OR REPLACE RULE range_test3_rule AS ON INSERT TO range_test WHERE id >= 200000 AND id < 300000 DO INSTEAD INSERT INTO range_test3 VALUES (NEW.*); CREATE RULE highgo=# CREATE OR REPLACE RULE range_test4_rule AS ON INSERT TO range_test WHERE id >= 300000 AND id < 400000 DO INSTEAD INSERT INTO range_test4 VALUES (NEW.*); CREATE RULE highgo=# CREATE OR REPLACE RULE range_test5_rule AS ON INSERT TO range_test WHERE id >= 400000 AND id < 500000 DO INSTEAD INSERT INTO range_test5 VALUES (NEW.*); CREATE RULE highgo=# CREATE OR REPLACE RULE range_test6_rule AS ON INSERT TO range_test WHERE id >= 500000 AND id < 600000 DO INSTEAD INSERT INTO range_test6 VALUES (NEW.*); CREATE RULE highgo=# CREATE OR REPLACE RULE range_test7_rule AS ON INSERT TO range_test WHERE id >= 600000 AND id < 700000 DO INSTEAD INSERT INTO range_test7 VALUES (NEW.*); CREATE RULE highgo=# CREATE OR REPLACE RULE range_test8_rule AS ON INSERT TO range_test WHERE id >= 700000 AND id < 800000 DO INSTEAD INSERT INTO range_test8 VALUES (NEW.*); CREATE RULE highgo=# CREATE OR REPLACE RULE range_test9_rule AS ON INSERT TO range_test WHERE id >= 800000 AND id < 900000 DO INSTEAD INSERT INTO range_test9 VALUES (NEW.*); CREATE RULE highgo=# CREATE OR REPLACE RULE range_test10_rule AS ON INSERT TO range_test WHERE id >= 900000 AND id <= 1000000 DO INSTEAD INSERT INTO range_test10 VALUES (NEW.*); CREATE RULE highgo=# insert into range_test select generate_series(1, 1000000), generate_series(1, 1000000)||'highgo', clock_timestamp(); INSERT 0 0 时间:28701.916 ms
接下来测试patch PostgreSQL10补丁的的分区表性能。
highgo=# create table range_test(id int, tt 3ff0 text, tm timestamp) partition by range(id); CREATE TABLE highgo=# create table range_test1 partition of range_test for values from (0) to (100000); CREATE TABLE highgo=# create table range_test2 partition of range_test for values from (100000) to (200000); CREATE TABLE highgo=# create table range_test3 partition of range_test for values from (200000) to (300000); CREATE TABLE highgo=# create table range_test4 partition of range_test for values from (300000) to (400000); CREATE TABLE highgo=# create table range_test5 partition of range_test for values from (400000) to (500000); CREATE TABLE highgo=# create table range_test6 partition of range_test for values from (500000) to (600000); CREATE TABLE highgo=# create table range_test7 partition of range_test for values from (600000) to (700000); CREATE TABLE highgo=# create table range_test8 partition of range_test for values from (700000) to (800000); CREATE TABLE highgo=# create table range_test9 partition of range_test for values from (800000) to (900000); CREATE TABLE highgo=# create table range_test10 partition of range_test for values from (900000) to (1000000) INCLUSIVE; CREATE TABLE highgo=# insert into range_test select generate_series(1, 1000000), generate_series(1, 1000000)||'highgo', clock_timestamp(); INSERT 0 1000000 时间:6419.396 ms
插入性能测试数据对比
从表格中可以看出,改在内核中实现的数据插入比触发器实现的性能提高还是很明显的。
b) 检索性能
对两个版本的分区表做相同的条件查询。
首先以“继承表+约束+规则”形式创建的分区表。
highgo=# select * from range_test where id = 333333; id | tt | tm --------+--------------+---------------------------- 333333 | 333333highgo | 2017-06-19 11:23:27.649307 (1 行记录) 时间:24.619 ms
然后patch PostgreSQL10补丁的的分区表。
highgo=# select * from range_test where id = 333333; id | tt | tm --------+--------------+---------------------------- 333333 | 333333highgo | 2017-06-19 11:35:01.475478 (1 行记录) 时间:24.343 ms
检索性能测试数据对比:
从表格可以看出,检索性能基本差不多。
7. 小结
分区表除了方便数据管理,提高检索效率才是其主要应用的地方。现在分区表基本上都是在继承表的基础上实现的,要做到条件检索时只对目标分区的扫描,而不是全表分区的顺序扫描,constraint_exclusion配置参数一定要设置为ON的状态。
关于提高分区表性能,除了从开发上考虑,我们还可以从应用场景上去考虑一下。比如创建一个范围分区,其检索频率很高,而写的频率不大,那么在一定数据量的情况下,创建的分区数越多,检索效率则会越大。

相关文章推荐
- 首款国人开发的基于FLASH10的3D引擎——NewX3D
- 基于 Jboss Drools 规则引擎开发框架
- 分区表及分区索引(10)--交换分区
- 基于引擎开发HTML5游戏实战(四)---组织游戏逻辑
- 基于引擎开发HTML5游戏实战(三)---组织游戏元素
- 开发自己的脚本引擎(二)脚本语法的设计。
- 基于引擎开发HTML5游戏实战
- FLEX 下基于Molehill引擎和Flash player 11预览版的开发环境配置
- [转]自己开发的基于boost::asio的网络引擎
- 基于JBox2d物理引擎和canvas的游戏开发实例
- 上传了一个基于gdi的ui开发引擎,请各位朋友试用~
- 全面学习分区表及分区索引(10)--交换分区
- 开发一个实体引擎,基于springside
- 深入学习分区表及分区索引(10)--交换分区
- 基于silverlight GDE-X开发进展 - 游戏引擎状态机
- 基于八叉树空间划分的游戏引擎开发计划
- 浅析基于Web的多媒体CAI课件开发过程中若干新问题的探究和实践
- VC++基于微软语音引擎开发语音识别总结
- 基于引擎开发HTML5游戏实战(一)---游戏引擎
- 基于jQuery开发的javascript模板引擎-jTemplates