【初码干货】记一次分布式B站爬虫任务系统的完整设计和实施
2017-06-05 12:36
351 查看
| 【初码文章推荐】 | 程序员的自我修养 Azure系列文章 阿里云系列文章 爬虫系列文章 |
| 【初码产品推荐】 | AlphaMS开发模式 闪送达城市中央厨房 |
这个小玩意源于上周在研究Azure的时候,发现云服务厂商都在推荐轻量级的存储队列服务,用来取代原有的比较重的消息队列服务,具体来说,比如阿里云就推荐使用消息服务替代消息队列,在Azure中,就有一个轻量级的存储队列(Storage Queue)可以替代服务总线(Service Bus),简单试用了一下Azure的Storage Queue后,发现这玩意很好用,于是决定全面的深入研究一下,再将公司电商系统内的相关任务处理均重构成使用存储队列服务,而深入研究得找个案例呀,于是就想到了做个分布式爬虫,此类应用会出现大量的任务场景,而正好前段时间下载B站视频时,找到一个网站,叫唧唧下载(搞二次元的都是色情狂吗?),但又不太好用,于是决定就做个比较全面的B站视频爬虫。一方面可以方便的下载视频,另一方面还可以当做公司开发人员的教学案例
老规矩,还是先看下最终的使用效果,应用入口:https://www.alphams.cn/LT,(为了防止滥用下载以及记录下载,所以还麻烦注册一下啦)
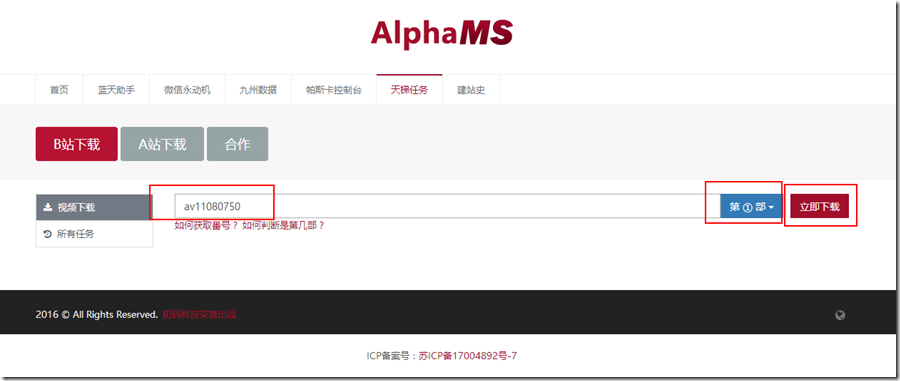
输入视频番号,点击下载,就进入任务界面
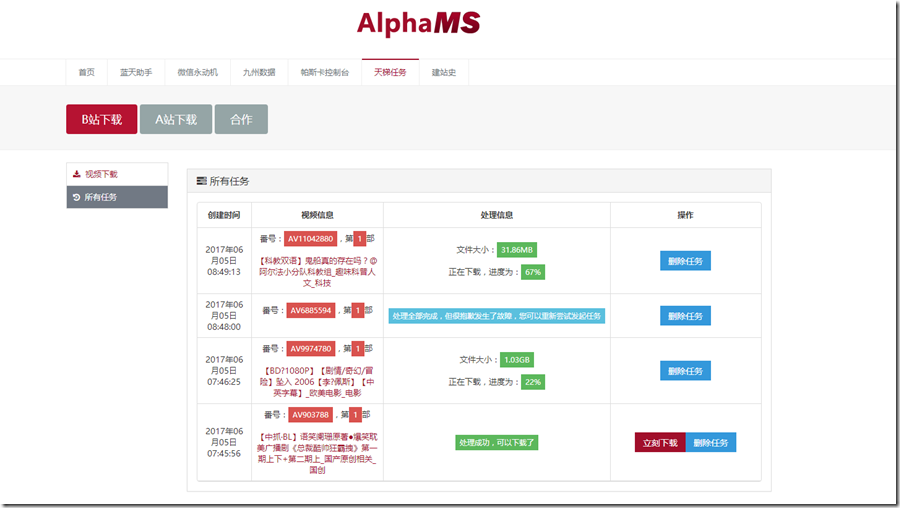
任务界面可以看到视频信息,实时下载信息,和错误信息
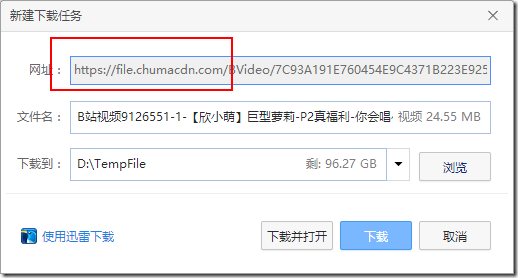
任务处理完成后,点击立即下载,从一个CDN加速的地址得到了视频
那么下面就把本次的开发和实施流水账记录一下
1、首先是准备工作和可行性调研
想要对B站进行爬虫,首先要准备好技术手段和相关工具,对B站的网站结构和数据流向进行一些分析,进行可行性的调研
首先打开B站任意一个视频,可以看到地址都是这样的格式

于是我们把AV后面的号码叫做番号(此番号非老司机番号)
而有些视频不止一段,如果是第二段视频,则是这个地址:

而如果把Index后面的2换成1,也可以达到和第一个地址一样的效果
然后用Fidder工具,分析一下网页,可以看到有如下一些资源

剔除基本的JS文件、CSS文件、图像文件后,剩下来的就是一些有用的信息了,而在有用的信息中最终筛选出如下几个信息
1、AID是视频的番号,也就是网址URL后面的那串唯一数字
2、CID是弹幕的番号,每个视频AID会对应一个CID
3、弹幕的信息存储在了这样的URL中:http://comment.bilibili.com/15075110.xml
4、视频的信息存储在了这样的URL中:https://interface.bilibili.com/playurl?cid=15075110&appkey=84956560bc028eb7&otype=json&type=&quality=3&sign=c070bfd93a84cab542e7c874add6839e
因为本次主要是下载视频,所以就着重看一下视频存储的信息,打开上面的URL后发现了最终视频的地址

太好了,一下子就给了视频尺寸和视频最终的下载地址,那么我们用浏览器打开一下这个URL看一下,可以成功下载!
注:以上相关分析实际上是经过了1-2个小时的反复尝试和模拟得出的,有2个细节补充一下,1、B站的服务器会根据HTTP头信息的不同返回FLV格式或者MP4格式,2、B站的视频可能用了不同厂商的CDN服务,有些视频地址无法直接下载,会判断refer信息和浏览器信息)
接下来继续分析,注意看这个URL可以发现,尾部有一个sign,说明做了客户端和服务端的签名验证,并不是很傻瓜的有直接通过AID或者CID关联的下载地址,分析进入到这一步后,我很快的就打了自己的脸,我曾在文章《关于.NET玩爬虫这些事》中说过,一切网站行为都可以分析出HTTP+Javascript来,只要分析得当,根本不需要用浏览器来进行爬虫模拟,但这尼玛B站鬼的Web结构(忍不住想骂人,典型的垃圾Python、PHP向的开发人员做出来的鬼东西,代码逻辑混乱、随便一看就是到处修补修改的痕迹,生成出来的HTML、JS的逻辑和层次毫无美感),看了2个小时,眼睛都看疼了,楞是没分析出签名方法,也许再看看会有结果,但是我等不及了,所以这时候祭出爬虫神器-无头浏览器
这里我选择了PhantomJS这个无头浏览器,具体的使用过程就不详述了,有兴趣可以到官网了解一下,写了如下分析代码
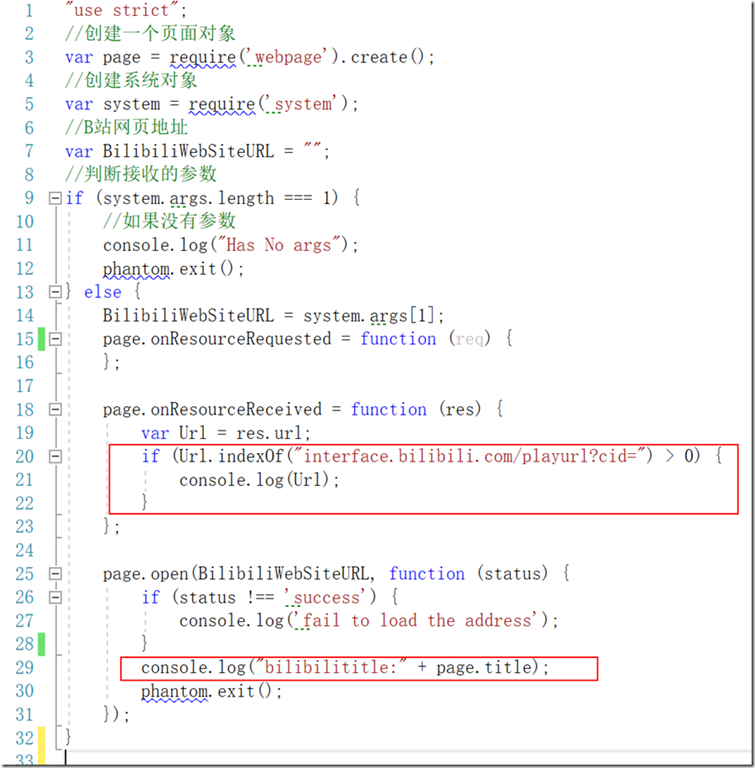
通过代码我们可以很清楚的看到,主要是两个目的,输出包含interface.bilibili.com的URL以及本次视频的标题
测试一下,确实可以得到URL和标题,这里有个要注意的是,B站默认是GB2312编码,所以PhantomJS要加一个参数,就是输出编码改为GB2312

到此为止,可以说完成了整个爬虫部分的调研,至少是有完整的可行性了。
2、然后进行业务功能的设计
有了可行性后,就可以天马行空的进行业务功能的设计了,既然上面说到那个鸡鸡网站特别不好用,那么我们就来重新设计一下这个爬虫的功能
一、用户端功能
1、用户可以输入视频番号和序号提交视频下载(注:干净清爽的提交界面)
最终界面如下:

2、用户可以在提交视频下载后,可以看到实时的处理进度,并且能够看到自己以前提交的任务(注:需要设计任务机制,做好状态控制,这里采用Azure的存储队列)
最终界面如下

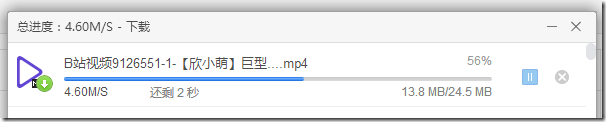
3、用户最终的下载速度特别快(注:使用CDN和网络存储技术,这里采用阿里云的CDN和OSS)
最终效果如下:
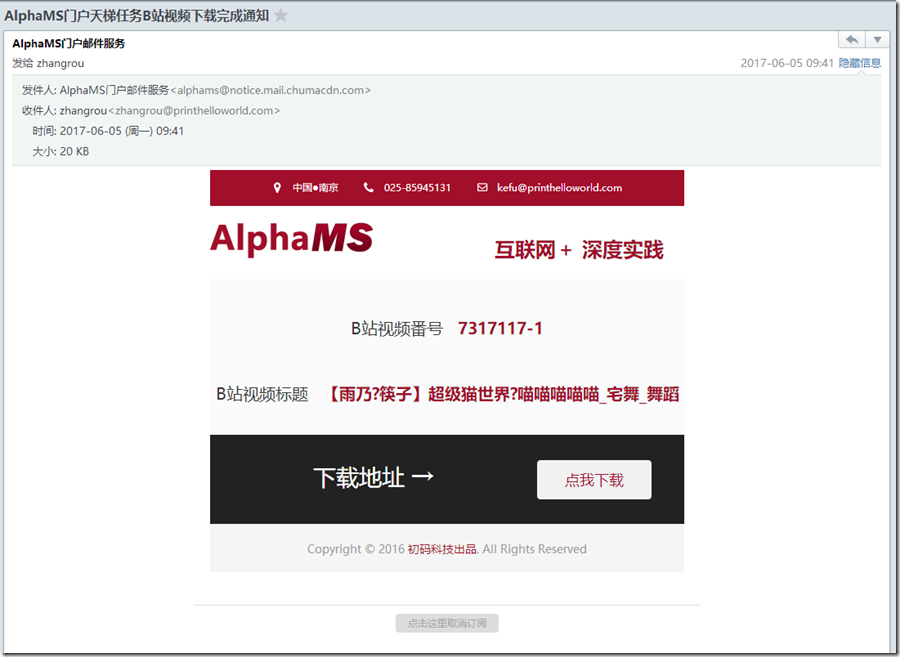
4、下载进度能够通过邮件进行视频信息的推送(注:使用邮件模板技术,详见:《使用阿里云邮件推送服务架设自己邮件验证与推送体系》,这里采用SendCloud云服务)
最终效果如下:
二、服务端功能
1、考虑到B站CDN可能会限制IP地址使用,需要使用分布式的爬虫设计(注:这里使用Windows Console Application程序)
2、增加下载效率,使用多线程技术(注:因为使用.NET做爬虫,多线程控制还算比较稳定和齐全)
3、对无头浏览器进行精准的控制(注:这里是Windows环境,考虑使用.NET里面的Process类进行控制)
有了业务功能做指导,下面就可以进行完整的系统设计了
3、系统设计与技术细节
老规矩,先放出整体设计图

其中具体的技术细节和代码如下:
一、分布式架构的核心
1、分布式Win32控制台程序需要有账号体系,这样可以进行节点的实施状态管理和记录
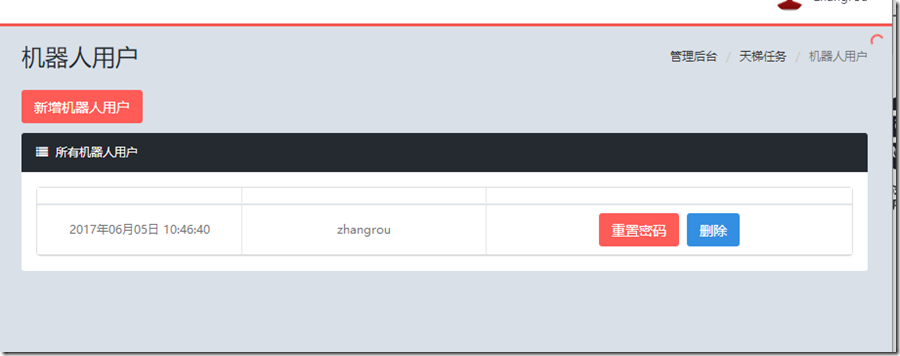
2、任务的新增、获取、核销等,需要精准的控制,不能出现并发冲突,所以这里使用了消息队列,也就是上面所说的Azure存储队列服务
任务的新增和分配主要代码如下:
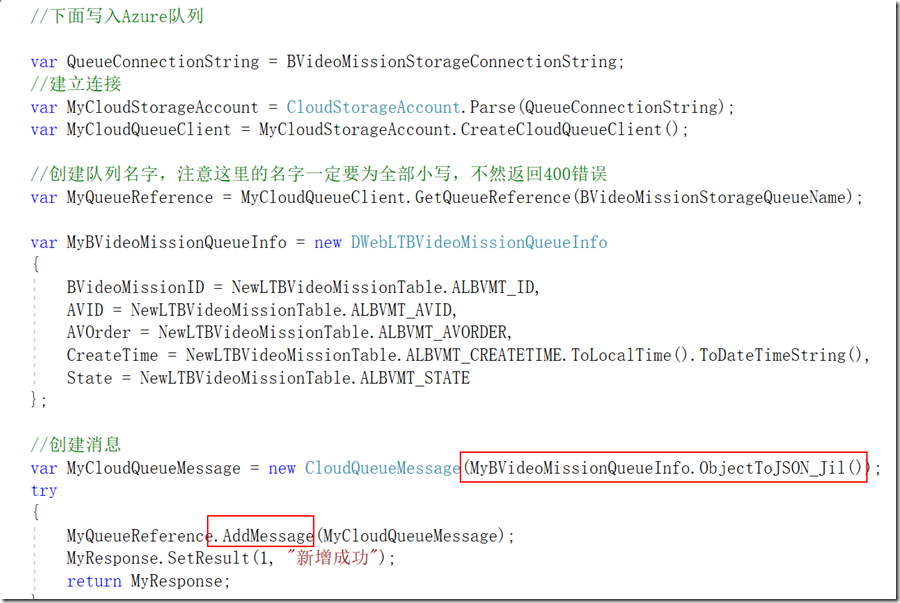
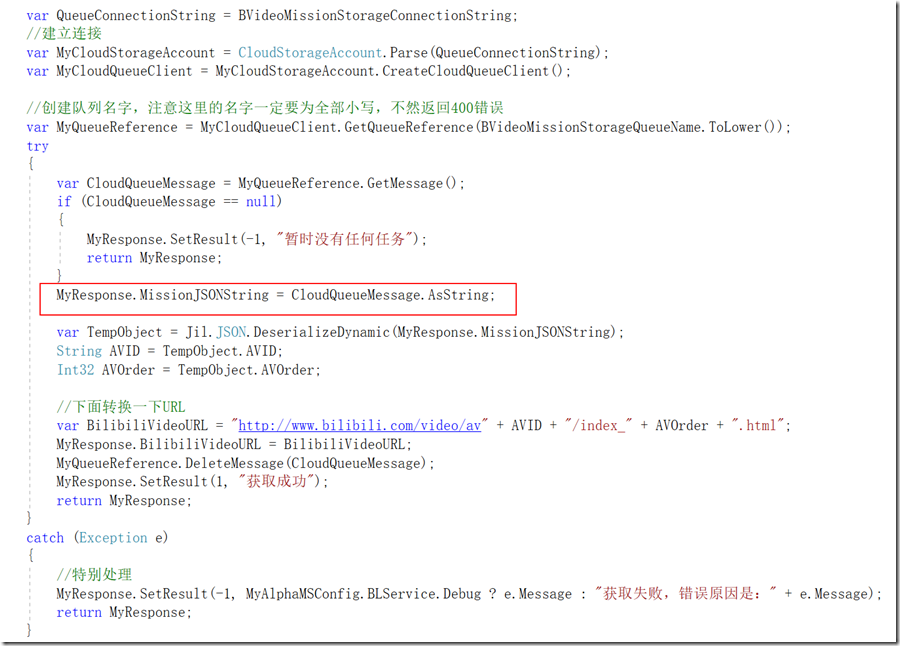
3、丰富的日志和错误处理机制
因为会一直执行,分布式节点的稳定性非常重要,Windows Console Application程序本身是非常稳定,因此在具体的代码里面,内存控制与对象释放、死循环的避免、多线程优化、异常的捕捉和处理等都非常重要,这里不一一洗漱,都是开发的基本功,做类似的应用的话,大家也需要多注意。另外因为无头浏览器的执行,是放在分布式的客户端里面进行的,因此也需要对无头浏览器进行精准控制,下面会详细说到
二、爬虫任务的数据结构
本案例中由于只对单一URL进行分析和爬虫,业务逻辑并不复杂,考虑到需要支持进度查询、状态控制等,数据结构设计如下,就2个表
1、爬虫任务表(记录爬虫任务,控制状态、记录过程参数等)
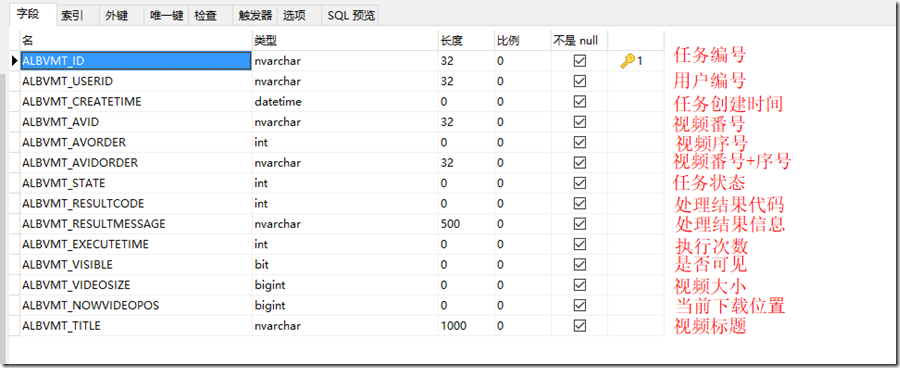
2、视频存储表
任务完成后,就把CDN加速好的视频信息存储下来,一方面进行冗余查询,另一方面也用于其他用户下载可以秒下
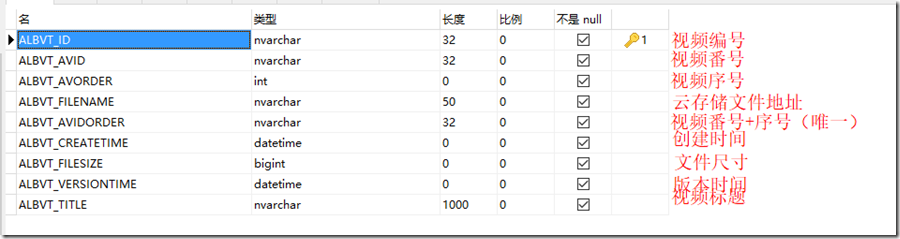
三、无头浏览器的精准控制
1、.NET里面的Process类
上面提到了,无头浏览器毕竟有一个浏览器内核的执行,而在任务处理的高峰,可能会不断的调用、销毁这个浏览器,而Web行为又是非常不稳定的,所以想要分布式的稳定,就一定要进行无头浏览器的精准控制。这里用到了.NET里面Process来控制无头浏览器的执行,主要的技术点有:
不显示命令窗口,重定向输入输出

监听数据接收

这里可以看到,我们之前在PhantomJS里面写的JS代码,主要就输出了两点,一个是包含下载地址JSON数据的URL地址,另一个是视频的标题,这里都做了记录
差错处理以及任务的关闭和结束
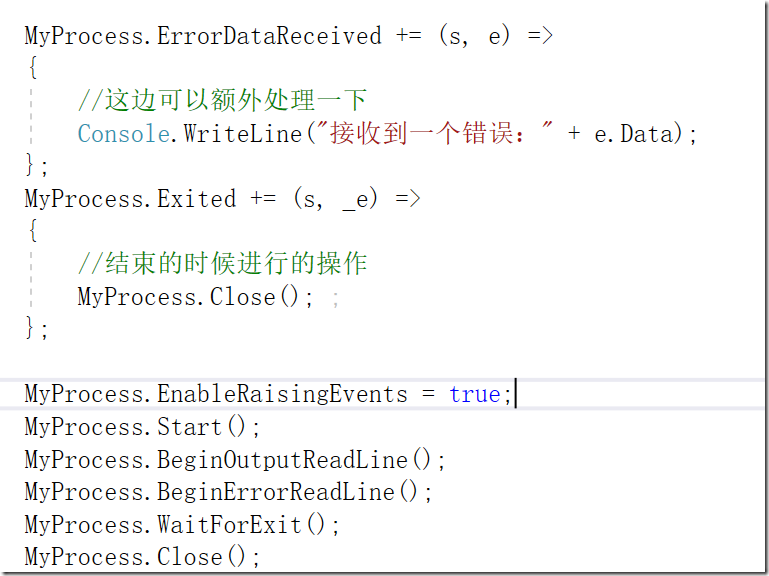
2、重试的机制
实测中发现,无头浏览器的失败率和出错率还是挺高的,因此在数据结构设计的时候,就预留了重试机制,当分布式客户端处理视频失败时,服务端重新提交消息队列,超过一定的次数再宣告任务失败
三、CDN的加速处理
1、之前在这篇文章《使用阿里云对Web开发中的资源文件进行CDN加速的深入研究和实践》中,提出了一种非常好的资源管理和加速方式,核心思路包括三点
文件资源的信息管理和目录结构在本地数据表中,GUID化
文件的数据存储在阿里云OSS中,无目录结构的扁平化记录
对OSS绑定域名,对CDN服务也绑定域名
反馈给客户端的文件信息,直接使用CDN地址,从而回源到OSS中或者直接命中缓存
2、同样的,在本次案例中,也使用了这样的处理方式,最终给用户的下载地址是CDN下载地址,具体的处理流程可以看上面的设计图,应该能一目了然
3、关于对上传到OSS的处理
在最初的设计方案中,分布式客户端完全下载到视频文件的内容后,是上传到服务端,由服务端统一进行上传,后来评估这样的方式,对服务端的压力和带宽占用都明显提升了,既然是分布式系统,应当充分利用分布式客户端的资源,所以改为分布式客户端直接上传文件到阿里云OSS中,这样做唯一的弊端是分布式客户端会获取明文的阿里云管理密钥,于是又加入了阿里云RAM权限管理,加入了OSS子权限的控制,问题就迎刃而解了。
四、邮件推送的处理
在上面的功能设计中,加入了邮件推送的功能,详细的设计思路参见这篇文章《使用阿里云邮件推送服务架设自己邮件验证与推送体系》,邮件模板就是HTML代码,这里就不多说了,但有一个小插曲,就是阿里云的邮件推送服务,实在是太烂了,特别是QQ邮箱的到达率奇差无比,因此最终的实施部分换成了搜狐的SendCloud解决方案。
好啦,整个实施到这里基本上就差不多了,老规矩,还是要总结和思考一下:
1、技术改进。因为整个程序就做了2天不到,很多技术细节点并未很到位,还有大量可以改进的地方:
比如对于PhantomJS更多细节参数的研究,是不是可以提升效率,是不是可以减少出错率
又比如任务表的设计,耦合的地方还是很多,应该还可以优化设计
又比如在用户界面上,没有做太多H5的美工,应该还可以加强一下
又比如分布式客户端Windows Console Application是不是可以强化为Windows Service,并且加入监控和守护进程
又比如经过研究发现,B站用了大厂商(蓝汛)的CDN服务,非常智能,在快速的加载30%以后就进行限速,那么对于这样的瓶颈的处理是不是还可以更细致一些
这些工作在后续我会慢慢完善
2、功能改进。今天只是为了测试存储队列的这个服务,所以简单的进行了B站视频的爬虫,事实上还有很多后续功能可以拓展
比如加入微信扫码就可以在微信上下载视频、观看视频
比如可以绑定微信公众号,在微信公众号上也可以视频番号发起下载,并通过微信模板消息推送处理结果
比如可以加入对弹幕的处理
比如可以加入一些经营性的功能,例如广告、收费高速下载、加入存储广告站的下载地址等等
3、其他思考
还是老生常谈的话题,坚决的反对前端向开发人员进行大型系统的架构,做出来除了垃圾就是垃圾
目前个人信息的保护是非常严格的,如果下载并存储电影和综艺节目,一定是非法的甚至触犯刑法,而这种个人发布的视频的爬虫下载,不知道上传时有没有和B站签署版权协议或者电子协议,如果是直接下载地址给到用户还好,但在本案例中,加入了中转存储,那么这样的行为,是不是涉嫌违法呢?我认为暂时法律风险不大,但从长远看,不太合适!
作者:张柔,发布于 博客园 与 张柔的博客
转载请注明出处,欢迎邮件交流:zhangrou@printhelloworld.com,或者加QQ群:11444444

相关文章推荐
- 记一次分布式B站爬虫任务系统的完整设计和实施
- java分布式系统定时任务,如何保证多台服务只执行一次
- 系统架构 之 高效分布式爬虫系统的架构设计[申请专利]
- 分布式任务队列与任务调度系统Celery进阶——分布式爬虫
- 腾讯资深架构师干货总结:一文读懂大型分布式系统设计的方方面面
- 分布式爬虫系统设计、实现与实战:爬取京东、苏宁易购全网手机商品数据+MySQL、HBase存储
- 系统架构-设计模式(适配器、观察者、代理、抽象工厂等)及架构模式(C/S、B/S、分布式、SOA、SaaS)(干货)
- [导入]从架构设计到系统实施——基于.NET 3.0的全新企业应用系列课程(3):设计基于WF的工作流.zip(11.65 MB)
- 分布式网管系统中SNMP Agent的设计和实现
- VSTS用Visio中UML工具进行分析设计与分布式系统设计器、类设计器的关系?
- [导入]从架构设计到系统实施——基于.NET 3.0的全新企业应用系列课程(5):设计基于WPF的客户端.zip(6.98 MB)
- 如何使用.Net来设计一个爬虫系统
- 一次运用设计模式对现有系统进行重构的尝试(一)
- 毕业设计中怎样用python写一个搜索引擎的分布式爬虫---异样的美感
- [导入]从架构设计到系统实施——基于.NET 3.0的全新企业应用系列课程(8):为Vista用户设计Gadget.zip(8.67 MB)
- [导入]从架构设计到系统实施——基于.NET 3.0的全新企业应用系列课程(7):设计基于MMC 3.0的管理工具.zip(8.70 MB)
- VisualStudio 2010从分析到实施(3)——使用Use Case Diagram设计系统交互
- 基于AVR单片机的多任务嵌入式Internet系统设计
- 一次运用设计模式对现有系统进行重构的尝试(二)
- 分布式电子邮件系统设计